基于Word2Vec的藏文文本語義預測分析研究
2021-03-29 02:12:48丁海蘭
西北民族大學學報(自然科學版) 2021年1期
丁海蘭
(蘭州交通大學 文學與國際漢學院,甘肅 蘭州 730070)
0 引言
1 詞向量
介于計算機只能識別1和0進行自然語言處理,那么想讓計算機處理文本,就必須把文本轉(zhuǎn)化成計算機所能識別的語言,其最直接的方法就是把詞轉(zhuǎn)化成詞向量.詞的向量化是指把詞進行數(shù)學化表示,主要有one-hot representation、Distributed representation和word2vec模型訓練詞向量三種表示方式.第一種方式是用一個很長的向量來表示一個詞,其分量為1,其余全部為0,1,其缺憾是無法提供語義信息;第二種方式是由Hinton最早提出,他是將詞映射到一個低維且稠密的100~200大小的實數(shù)向量空間中,這樣使得詞義越相近的詞距離越近;第三種方式是借鑒Bengio提出的NNLM模型(Neural Network Language Model)以及Hinton的Log-Linear模型、Mikolov模型等,都提出了Word2Vec的語言模型,Word2vec可以高速有效地訓練詞向量[1].
2 Word2Vec工具

2.1 Word2Vec的兩種訓練模型
詞向量其實是將詞映射到一個語義空間,得到的向量.Word2Vec則是借用神經(jīng)網(wǎng)絡的方式實現(xiàn)的,考慮文本的上下文關系,Word2Vec有CBOW 和Skip-gram共兩種模型,這兩種模型在訓練的過程中類似.Skip-gram 模型是用一個詞語作為輸入,來預測它周圍的上下文,CBOW模型是拿一個詞語的上下文作為輸入,來預測這個詞語本身.
2.1.1 Skip-gram訓練模型
如果是用一個詞語作為輸入,來預測它周圍的上下文,那這個模型叫做Skip-gram 模型.首先確定窗口大小Window,對每個詞生成2*window個訓練樣本,(i,i-window),(i,i-window+1),…,(i,i+window-1),(i,i+window).緊接著確定batch_size,注意batch_size的大小必須是2*window的整數(shù)倍,這確保每個batch包含了一個詞匯對應的所有樣本.訓練算法有兩種:層次Softmax和 Negative Sampling[2].最后將神經(jīng)網(wǎng)絡迭代訓練一定次數(shù),得到輸入層到隱藏層的參數(shù)矩陣,矩陣中每一行的轉(zhuǎn)置即是對應詞的詞向量,具體模型如圖1.
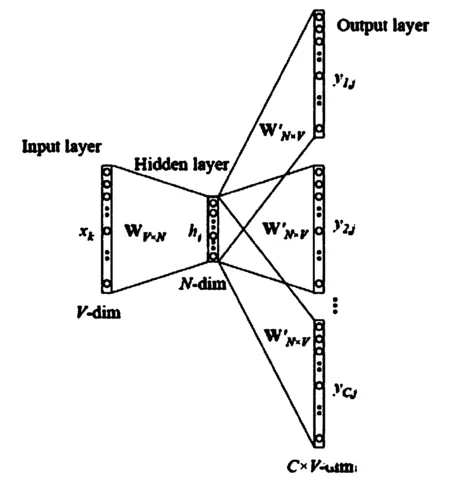
圖1 Skip-gram模型
2.1.2 CBOW訓練模型
CBOW(Bag-of-words model)模型是拿一個詞語的上下文作為輸入,來預測這個詞語本身.首先,確定窗口大小window,對每個詞生成2*window個訓練樣本,(i-window,i),(i-window+1,i),…,(i+window-1,i),(i+window,i).其次,確定batch_size,注意batch_size的大小必須是2*window的整數(shù)倍,這能確保每個batch包含了一個詞匯對應的所有樣本,訓練算法有兩種:層次Softmax和 Negative Sampling.最后是將神經(jīng)網(wǎng)絡迭代訓練一定次數(shù),得到輸入層到隱藏層的參數(shù)矩陣,矩陣中每一行的轉(zhuǎn)置即是對應詞的詞向量,具體模型如圖2.
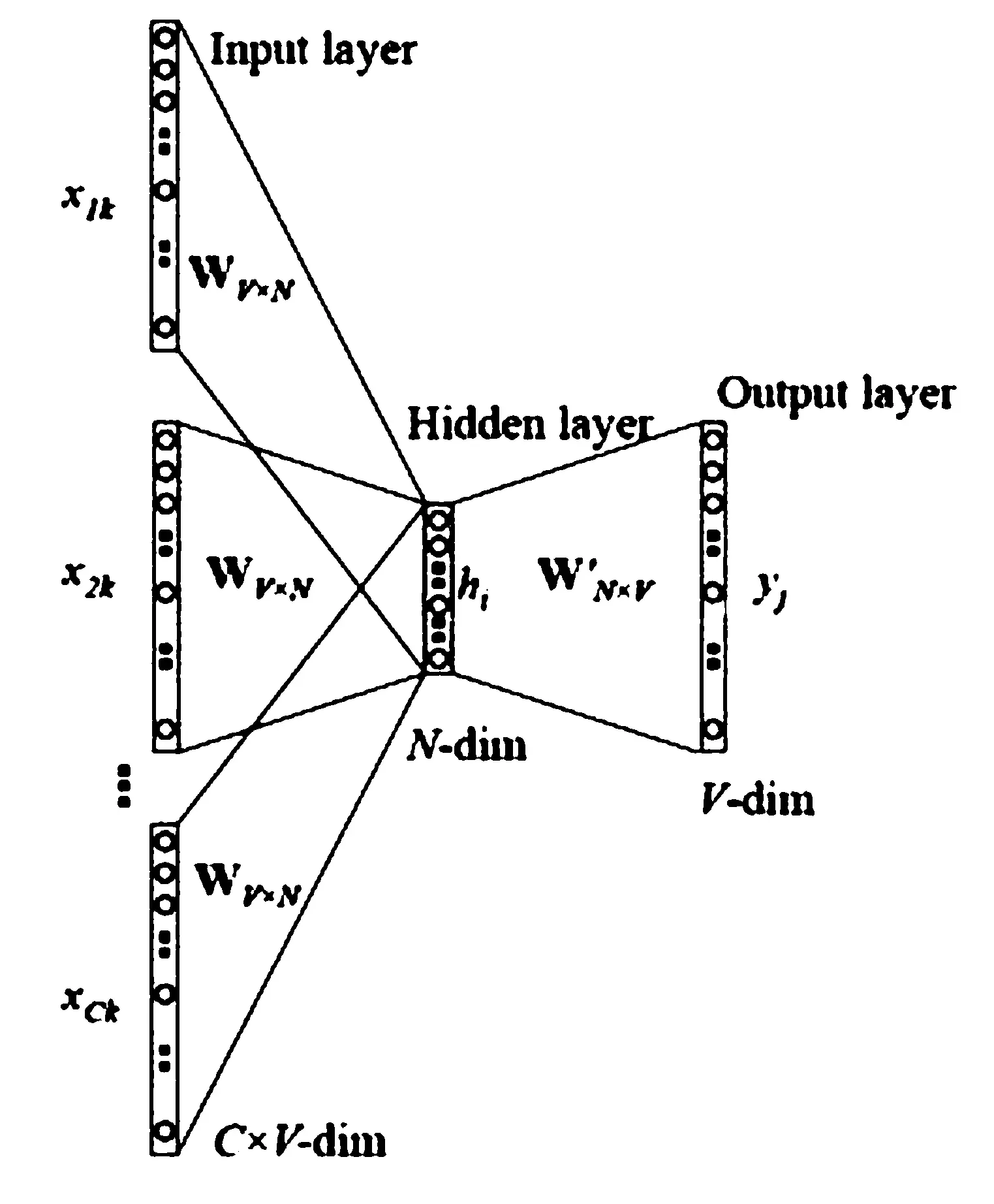
圖2 CBOW模型
Word2Vec的Skip-gram和CBOW兩種訓練模型中,訓練的語料較多時建議使用Skip-gram訓練模型去訓練,而語料相對較少時建議用CBOW訓練模型去訓練.總體來說,Word2Vec就可以利用訓練好的詞向量模型,通過輸入詞轉(zhuǎn)化成詞向量再經(jīng)過模型訓練,最后輸出按照距離遠近的詞類,將這些單詞變成了近義詞集.
3 實驗過程及結果分析
3.1 實驗步驟
終端搭建好環(huán)境變量后在Anaconda3的spyder開發(fā)環(huán)境中,使用python程序設計語言編寫詞向量測試代碼.調(diào)用Gensim工具包中的Word2Vec的CBOW模型算法去訓練,訓練的詞向量大小(size)為50,訓練窗口(window)為5,最小詞頻為5.首先,計算兩個詞的相似度,再計算一條詞的相關詞,最后再輸出與兩個詞在語義上距離最接近的詞集.使用python程序設計語言編寫的詞向量測試的核心代碼如下:
# genism modules
from genism.models import Word2Vec
from genism.models.word2vec import Text8Corpus
import os.path
import sys
import numpy as np
訓練的語料是經(jīng)過分詞核對后,批處理為每行一句,共有33244句,接著去除語料中的所有詞性標注并以空格代替詞性標注,每句保留藏文句子中的終結符號即單垂符作為句子的單位.最終,得到一篇文本的特征列表.在詞袋模型(CBOW)中,文檔的特征就是其包含的詞(word).具體步驟如圖3所示.
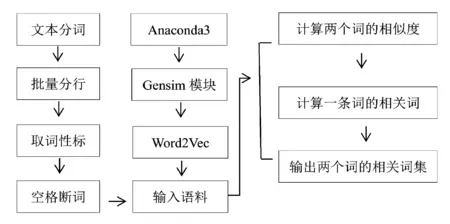
圖3 Word2Vec實驗步驟

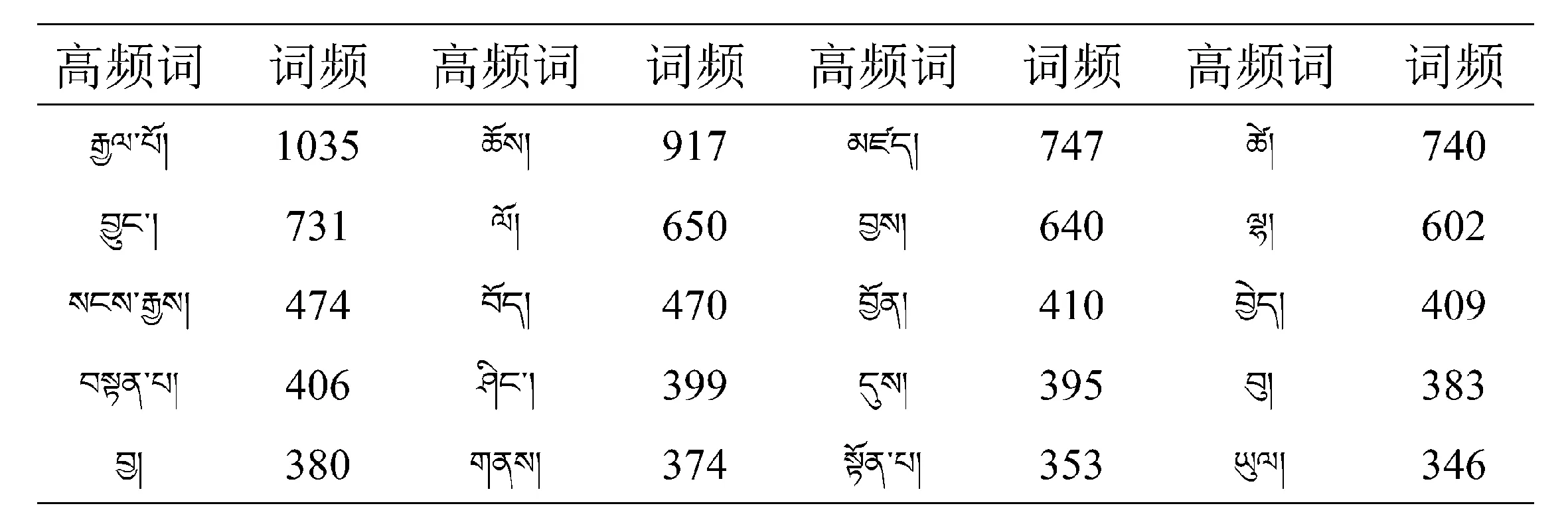
表1 文本《賢者喜宴》高頻詞匯表
以10組高頻詞匯作為訓練目標輸入Word2Vec model進行訓練,得出的訓練結果見表2~表5.
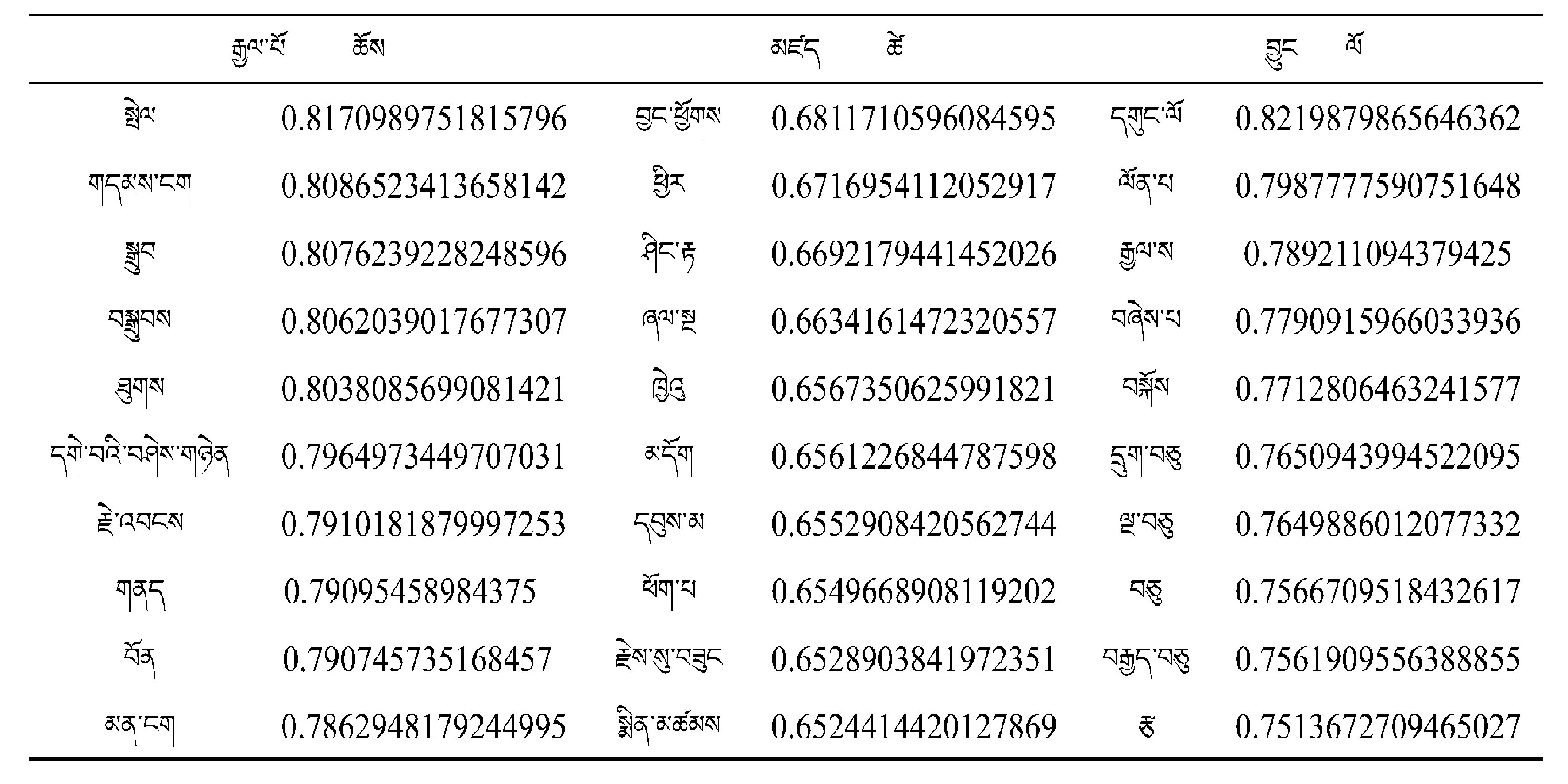
表2 Word2Vec模型訓練兩條詞的相關詞表
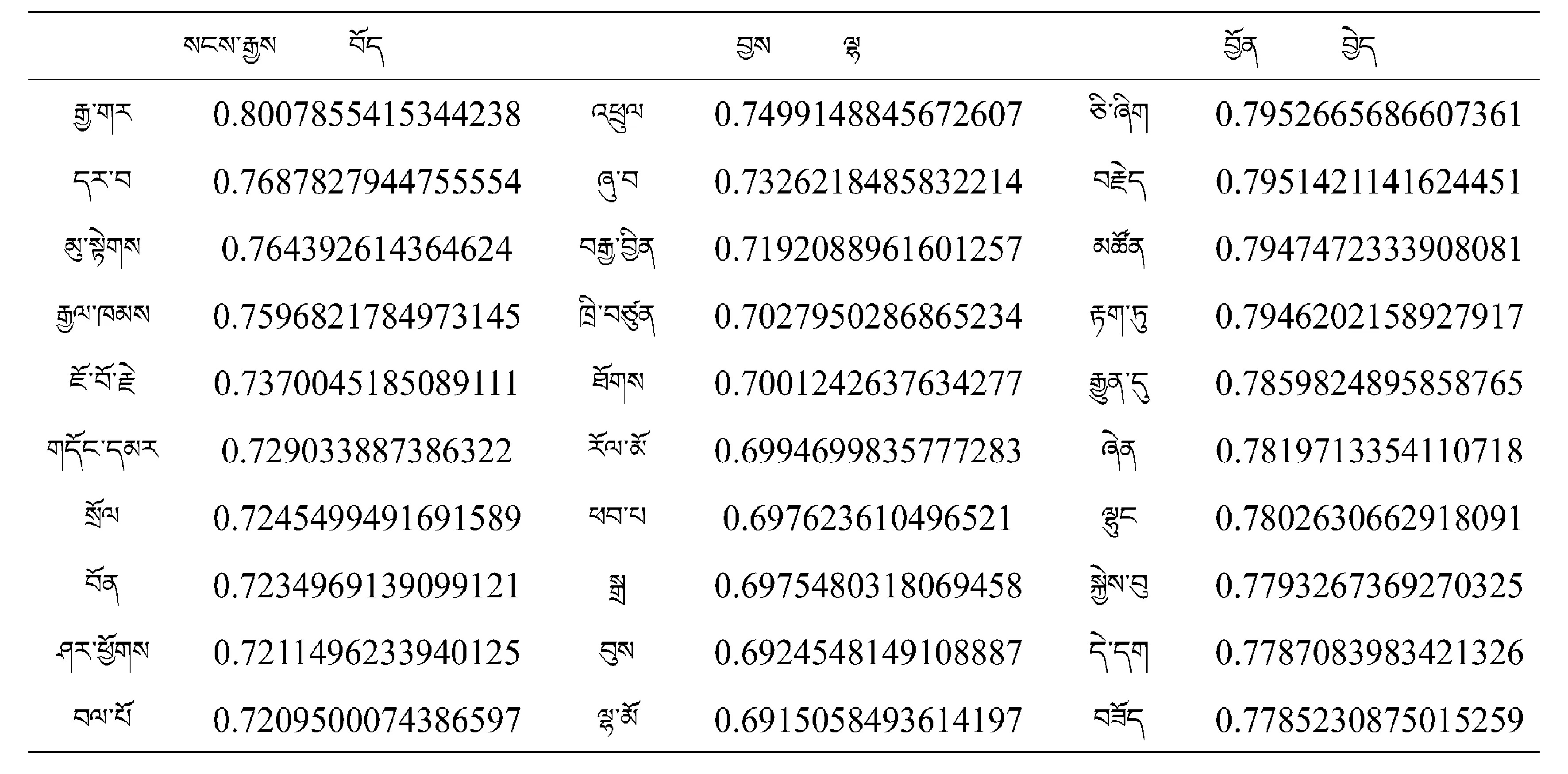
表3 Word2Vec模型訓練兩條詞的相關詞表
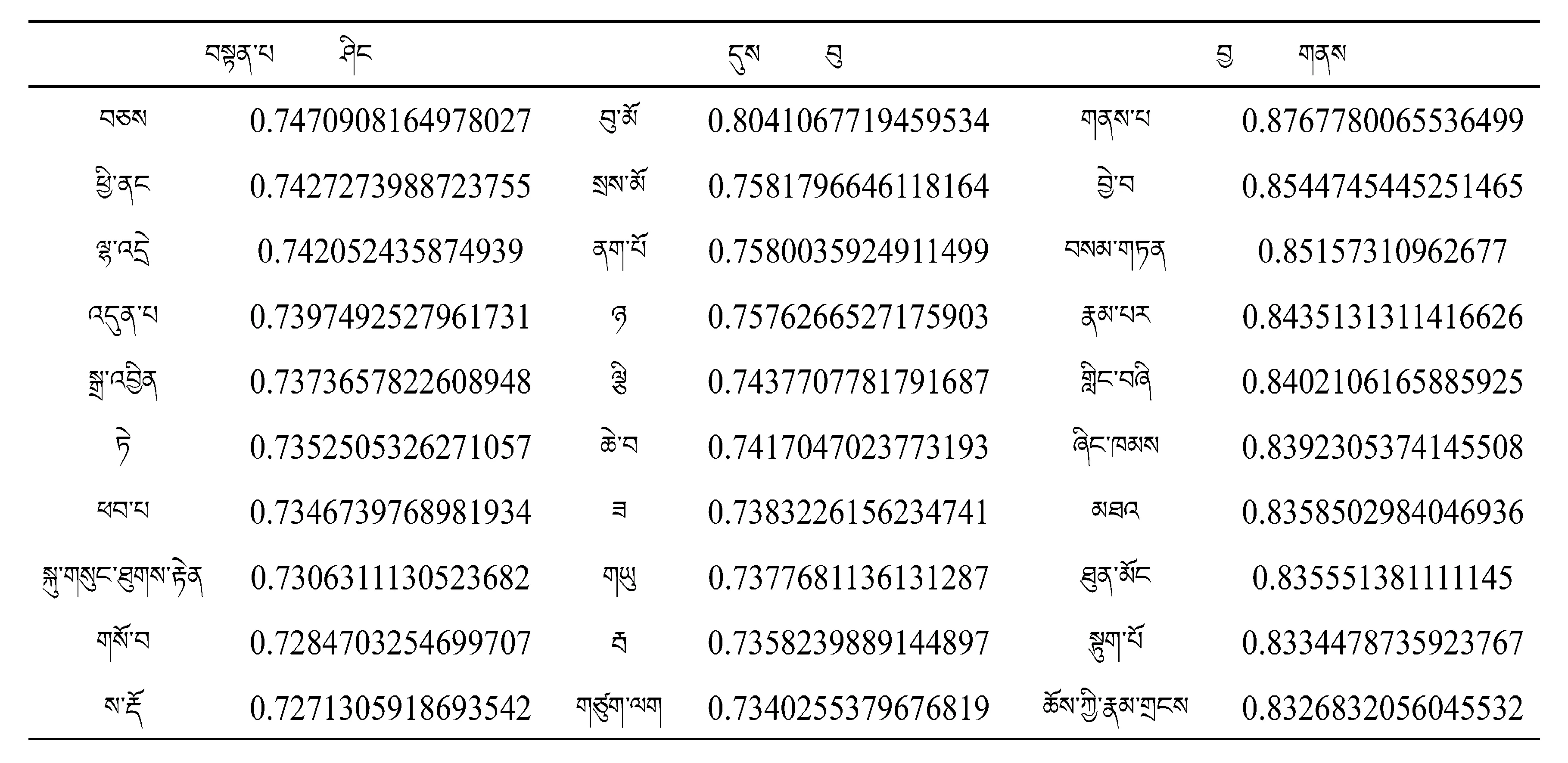
表4 Word2Vec模型訓練兩條詞的相關詞表


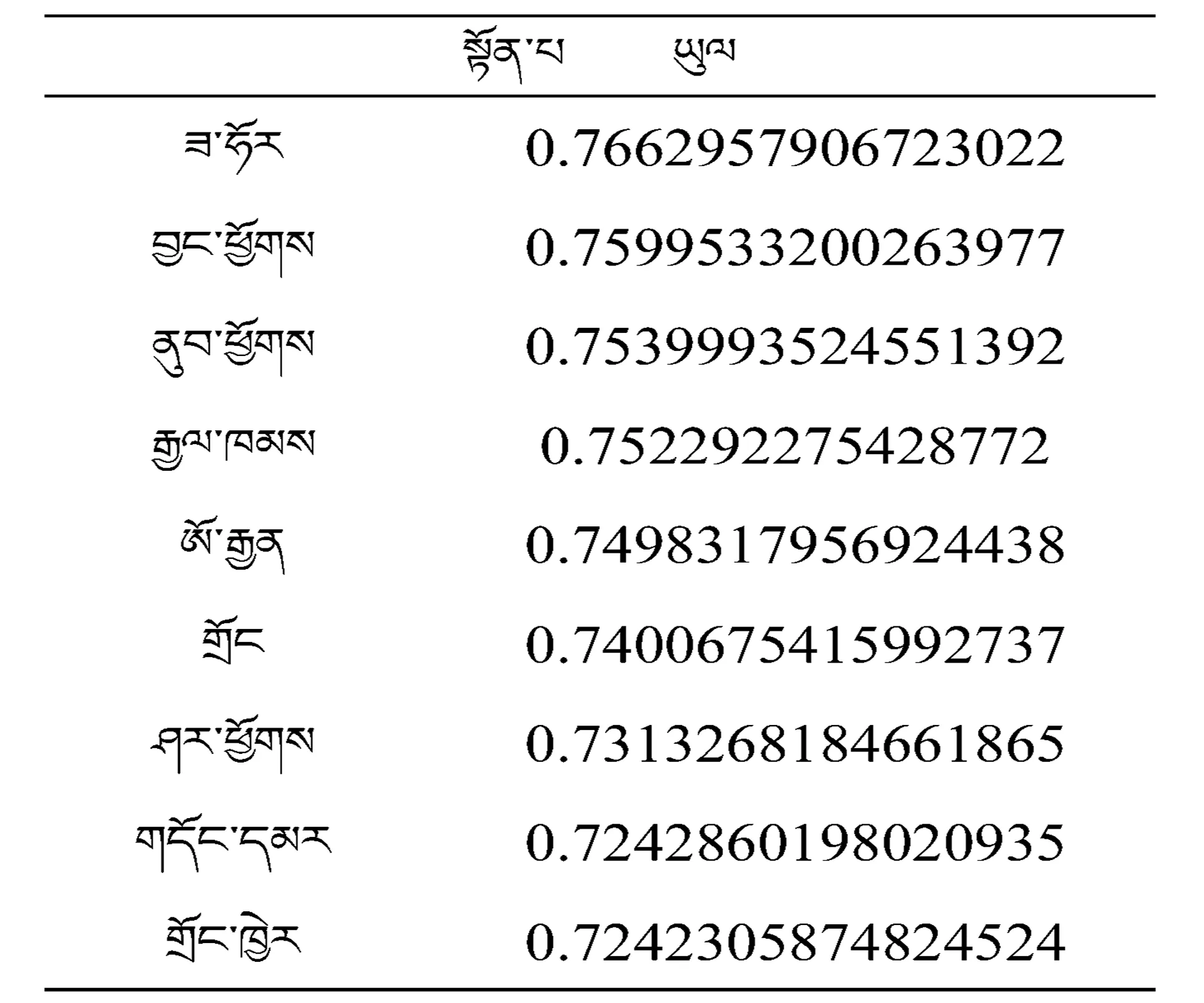
表5 Word2Vec模型訓練兩條詞的相關詞表

4 結束語
本文用GOOGLE下開源的Word2Vec工具把藏文文本作為語料進行輸入,將文本中的詞利用詞匯的上下文信息轉(zhuǎn)變?yōu)樵~向量,通過用Word2Vec中的CBOW模型算法模型訓練得到許多語言規(guī)律,從而得出詞與詞之間的距離即相似度.進一步通過高頻詞匯作為輸入,通過訓練即可輸出與高頻詞匯距離最近的詞匯,以高頻詞和與其相近的詞匯作為重要信息去預測文本的語義.此方法為快速掌握長篇語料中的主旨語義起到了快速且便捷的作用,同時通過訓練可以發(fā)現(xiàn)許多有趣的語言規(guī)律,避免了人工翻譯持續(xù)時間長和主觀判斷的問題.但是,在訓練中發(fā)現(xiàn)許多詞匯并未在語境中顯現(xiàn),這給語義預測帶來了些許誤差.總體來說,基于Word2Vec工具可以有效地預測文本語義.
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
