文本關鍵詞抽取方法及在幾種民族語言上的應用
2021-03-31 12:02:42白曙光李艷玲張樹鈞
內蒙古師范大學學報(自然科學漢文版) 2021年2期
白曙光, 林 民, 李艷玲, 張樹鈞
(內蒙古師范大學 計算機科學技術學院,內蒙古 呼和浩特 010022)
自然語言處理是人工智能的重要組成部分,在學術研究和實際應用等各個方面都有重要地位,關鍵詞抽取技術作為自然語言處理的基礎技術之一,其結果的優劣直接影響后續任務的性能。
關鍵詞抽取能夠幫助讀者獲取文章的中心思想,迅速了解一篇文章,或者從海量語料中快速獲得文章主題。在文本檢索、文本摘要等領域,關鍵詞抽取的準確程度對其他下游任務具有重要意義[1]。有效提取文本中關鍵詞有助于讀者快速、及時、高效、準確地獲取信息。文本關鍵詞可以提高文檔管理和檢索效率,還可為文本的分類、聚類、檢索、分析和主題搜索等文本挖掘任務提供豐富的語義信息。因此,關鍵詞抽取與其他下游任務是密切相關的。
1 文本關鍵詞抽取研究難點
關鍵詞抽取是自然語言處理領域的研究熱點,目前存在以下六個研究難點,嚴重制約了關鍵詞抽取技術的發展。
(1) 文本預處理不夠準確。近幾年文本表示學習、預訓練等技術的發展有了一定提升,但是在精度和深度上仍不能滿足研究需要,直接影響上層應用效果和智能水平。不能從語義上準確理解文本是關鍵詞抽取技術的一大難點。
(2) 效率低,復雜度高,尤其是融合方法的復雜度更高。目前許多自然語言處理任務為了達到較好效果,需要利用大量標注數據進行訓練,但是常會出現訓練語料不足的問題,而且標注數據費時費力[2],所以,當數據資源有限時,如何增強資源啟動和多語種場景的應用成為亟待解決的問題。
(3) 語義關聯關系的去重、歧義消解等問題。深度學習的應用雖然使眾多自然語言處理的任務性能得到提升,但是如何設計更好的語義表達方式仍未解決,而且中文存在語義歧義現象,如“郭德綱的粉絲想吃粉絲”這句話中,兩個“粉絲”代表不同的語義,但向量表示形式一致,所以語義歧義現象在一定程度上制約了關鍵詞抽取技術的發展,解決語義歧義問題可在一定程度上提高文本關鍵詞抽取任務的性能。
(4) 抽取得到的關鍵詞對文檔主題覆蓋性不高。在一個文檔中,經常有多個主題,現有方法沒有有效機制對主題進行較好的覆蓋[3]。
(5) 文檔與關鍵詞之間存在一定的差異性。很多關鍵詞在文檔中的頻率低,導致文檔和關鍵詞之間存在差異[4]。
(6) 少數民族語言文本的關鍵詞抽取存在自身的難點。如因文本自身的特征,預處理操作較為困難。
2 文本關鍵詞抽取技術和方法
關鍵詞抽取方法目前有三種: 有監督、半監督和無監督。其中,無監督方法包含基于統計特征、主題模型及圖網絡,其中被廣泛應用的有詞頻-逆文檔頻率(term frequency-inverse document frequency,TF-IDF)算法[5]、LDA (latent dirichlet allocation)主題模型[6]和TextRank等算法[7-10]。
2.1 有監督方法
有監督關鍵詞抽取方法的主要思想一般是先建立一個大規模標注好的關鍵詞訓練語料,然后利用訓練語料對關鍵詞抽取模型進行訓練。有監督的關鍵詞抽取方法常用的模型有樸素貝葉斯(naive bayesian,NB)[11]、決策樹(decision tree,DT)[12]、最大熵(maximum entropy,ME)[13]、支持向量機(support vector machine,SVM)[14]等。
有監督的方法中關鍵詞抽取問題被轉化為分類問題或標注問題,即判斷每個文檔與已構建好的詞表中每個詞的匹配程度,然后把文檔中的詞作為候選關鍵詞,通過分類學習方法或序列標注方法判斷這些候選詞是否為關鍵詞,進而實現關鍵詞抽取的效果。當將關鍵詞抽取任務看作是一個二分類任務時,需要在一個有標注的數據集上訓練分類器。當將關鍵詞抽取任務看作是標注問題時,研究人員需要從訓練集中建立一個語言模型,并選出符合關鍵詞特征的模型,再利用人工標注信息作為特征進行關鍵詞抽取。
有監督學習的關鍵詞抽取方法通常需要建立大規模訓練集合即語料庫(corpus),是由大量實際使用的語言信息組成,并需要針對通用或特定需求進行人工標注。訓練語料的質量對模型的準確性至關重要,直接影響模型的性能,從而影響關鍵詞抽取的結果。目前,已經標注好關鍵詞的語料有限,訓練集又需要大規模的語料,所以需要人工標注,帶有一定主觀性,易造成實驗數據的不真實[15]。因此,高質量的訓練集合對有監督學習方法的性能是至關重要的。有監督的學習方法具有較高的準確性和較強的穩定性,更加科學、有效,但存在人工標注工作量大、數據量激增、內容實時性強、耗時耗力等問題。如果將關鍵詞抽取問題視為一個二分類問題,那么對每個單詞的獨立處理忽略了文本的結構信息[16],對模型性能有一定影響。
2.2 無監督方法
無監督關鍵詞抽取方法無需人工標注語料,該方法根據詞匯的重要程度進行排序,抽取排名靠前的作為關鍵詞。無監督方法是近年來研究和應用的重點,常見的無監督關鍵詞抽取方法有三種: 基于統計特征[17]、基于主題模型[18]和基于網絡圖模型[19]的關鍵詞抽取。無監督的文本關鍵詞抽取流程如圖1所示。

圖1 無監督文本關鍵詞抽取方法流程圖Fig.1 Unsupervised keyword extraction method in text
2.2.1 基于統計特征的方法 基于統計特征的關鍵詞抽取方法是一種傳統機器學習方法,主要是利用文檔的統計學特征抽取關鍵詞。首先對文本進行預處理操作,去除不規范內容,獲得候選詞集,然后計算候選詞集中詞匯的統計學特征,根據特征值對詞匯進行排序,根據排序從候選集中抽取關鍵詞。常用的統計特征包括詞權重、詞位置、詞的關聯信息等[20]。
詞權重特征主要包括詞長度、詞性、詞頻、TF-IDF等。詞性是通過分詞、語法分析后得到的結果,一般為名詞或動詞,更能表達一篇文本的中心思想。詞頻一般可以認為文本中出現頻率越高的詞越有可能成為關鍵詞。但僅依靠詞頻得到的關鍵詞對長文本的不確定性很高,會有較大噪音; 而且,語句的位置也反映了其在文章中的重要性,文章標題、引言、段首句、段尾句均對文章有重要意義,這些詞作為關鍵詞可以表達整個文本的主題[21]。標題和摘要更能概括文本的中心思想,具有一定代表性,因受到作者寫作方式的影響,具有不確定性。基于詞的關聯信息的特征量化信息一般包含詞和詞、詞和文本之間的關聯程度,關聯信息通常包括互信息、HITS(hyperlink-induced topic search)值、貢獻度、依存度、TF-IDF值等。
TF-IDF算法是關鍵詞抽取方法中的一種基礎算法,因其簡單有效而被廣泛應用。TF-IDF值是指如果某個詞語在一篇文本中出現的頻率(term frequency,TF)高,而其他文本中較少出現,即逆文檔頻率(inverse document frequency,IDF)低,則認為該詞語能較好地代表當前文本的含義。TF-IDF算法主要用于評價一個詞對于一個文檔的重要程度。在TF-IDF算法中,字詞的重要性隨著該字詞在文檔中出現的次數呈正比,但同時也會隨著它在該文檔出現的頻率呈反比。TF-IDF算法的計算如公式(1)-公式(3),詞頻即一個詞在文檔中出現的頻率,一個詞的IDF表示這個詞在整個語料數據庫中出現的頻率。

(1)

(2)
It(i,j)=Iω(i,j)×Id(i,j),
(3)
其中:It(i,j)是指詞i相對于文檔j的重要性值;Iω(i,j)是指某一個字詞在該文檔中出現的次數占比,即給定的詞語在該文檔中出現的頻率,計算公式如(4);Id(i,j)是指詞i的逆文檔頻率,是用總文檔數目除以包含指定詞語的文檔數目,再將得到的商取對數,計算公式如(5)。
(4)
其中:ni,j表示詞i在文檔j中出現的次數;nk,j表示文檔j字詞出現的次數。
(5)
其中:D表示語料庫中文檔的總數; {j:ti∈dj}表示包含詞語ti的文檔數目。
TF-IDF算法存在如下不足: 一是對語料庫的質量要求較高,而且在跨領域語料上表現較差; 二是對一些在文本中出現頻率高并具有代表性的詞語不能很好表示; 三是精度不高,由于IDF有一種試圖抑制噪聲的加權,本身會傾向于文本中出現頻率較小的詞,從而導致TF-IDF算法精度不高; 四是對詞匯位置不敏感,沒有考慮不同位置上詞匯的不同重要性,例如在標題、句首和句尾等位置出現的字詞往往含有較重要的信息,應該賦予較高的權重[22]。可以通過將多個短文本歸并為一個文本的方法來改進TF-IDF算法,不僅可以增加TF值,而且可以增加IDF值,但同時也會增加模型的計算成本。此外,TF-IDF僅能考慮到詞自身的頻度,無法將其與語義語法相結合,影響了關鍵詞抽取的性能。
基于統計特征的關鍵詞抽取方法主要是通過詞權重、詞的文檔位置、詞的關聯信息等特征量化指標對關鍵詞按照其重要程度從高到低排序,獲取Top K個詞作為關鍵詞。
2.2.2 基于主題模型的方法 關鍵詞抽取與內容的主題相關,因此提取文本內容的主題至關重要。主題模型又稱文檔生成模型,它認為文檔是主題的概率分布,而主題是詞匯的概率分布[23]。LDA利用隱含主題模型發現文檔主題,然后再選取主題中具有代表性的詞作為該文檔的關鍵詞。
基于主題的關鍵詞抽取方法主要是利用主題模型中關于主題的分布性質進行關鍵詞抽取。首先從文本中獲取候選關鍵詞,然后利用有關鍵詞的語料訓練出一個主題模型,并得到主題分布和詞匯分布[24],最后在主題空間上計算候選關鍵詞和文本的相似度,根據相似度從大到小排序,選取前n個詞作為關鍵詞。具有代表性的是pLSA (probability latent semantic analysis)[25]模型、LDA模型等。pLSA將概率引入主題模型中,文檔主題之間、主題詞匯之間的隱含語義空間不再是一個抽象的概念空間,而是一個特定的概率分布空間,計算公式為
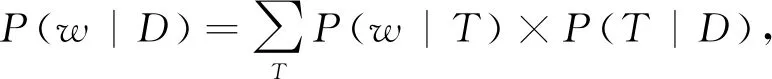
(6)
其中w表示詞語,D表示文檔,T表示主題。

圖2 LDA模型圖Fig.2 LDA model
2003年D.M.Blei提出了LDA主題模型[6],與pLSA相似,LDA也從文檔、主題、詞三個層面進行分析,并認為文檔有其主題概率分布,主題有其詞匯概率分布文檔可以在主題空間上進行表示,并根據主題的相似性進行文本聚類或者文本分類。LDA模型如圖2所示。LDA通過采用詞袋模型(bag-of-words,BOW)的方法簡化了問題的復雜性,認為一篇文檔是由一些詞組成的集合,詞與詞之間沒有先后關系。與pLSA分布不同的是,主題概率分布和詞匯概率分布的參數不是唯一的,這兩個分布的參數都符合Dirichlet分布。
在LDA模型中,包含詞、主題、文檔三層結構。該模型認為一篇文檔的生成過程是:先為一篇文檔選擇若干主題,然后為每個主題挑選若干詞語,最后將這些詞語組成一篇文章。所以主題對于文章以及單詞對于主題都服從多項分布。由此可以得到: 如果一個單詞w對于主題t很重要,而主題t對于文章d又很重要,那么可以推出單詞w對于文章d就非常重要,并在同主題的詞wi(i=1,2,3,…)中,詞w的權重也會較大。
根據上述,需計算以下概率。主題Tk下各個詞wi的權重計算公式為
(7)

文檔Dm下各個主題Tk的權重計算公式為
(8)
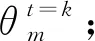
指定文檔下某個主題出現的概率,以及指定主題下某個單詞出現的概率計算公式為
(9)
由公式(9)可以得到單詞i對于文檔m主題的重要性。在LDA主題模型中,由于所有的詞都會以一定的概率出現在每個主題中,因此會導致最終計算的單詞對于文檔的主題重要性區分度受到影響。為避免該情況的出現,一般將單詞相對于主題低于一定閾值的概率設置為0。基于LDA的關鍵詞抽取方法,在主題層面上對文檔關鍵詞進行分析。這種方法不僅挖掘了文本的深層語義即文本的主題,而且可以將文檔集中的每篇文檔按照概率分布的形式表示,文檔的主題維度一般遠小于文檔的詞匯個數,所以也有研究者根據主題對文本進行分類。但基于主題模型提取到的關鍵詞比較寬泛,不能很好地表示文檔主題; LDA模型同樣耗時耗力; 在LDA中,主題的數目沒有固定的最優解[26]。模型訓練時,需事先設置主題數,訓練人員需要根據訓練出來的結果,手動調參,通過優化主題數目,進而優化文本分類結果。對此,可以借助知網、同義詞林等外部資源獲得更加準確的單詞語義關系。
在pLSA模型中,主題分布和詞分布的參數都是唯一確定的。而在LDA中,主題分布和詞分布的參數是變化的,LDA的研究人員采用貝葉斯派的思想,認為參數應服從某個分布。主題分布和詞分布呈多項式分布,因為多項式分布的共軛先驗分布是狄利克雷分布(Dirichlet distribution),所以在LDA中主題分布和詞分布的參數應服從Dirichlet分布。可以說LDA就是無監督的pLSA的貝葉斯化版本。
2.2.3 基于網絡圖的方法 TextRank是一種基于圖排序的算法。TF-IDF對于多段文本的關鍵詞抽取非常有效,但對單篇或者篇幅較長的文本效果一般。TF-IDF僅考慮詞語自身的頻度,而TextRank考慮了文檔內詞間語義關系,可以有效提取文本的關鍵詞。
TextRank基本思想來源于Google的PageRank[27]算法,通過把文本切分為若干組成單元(單詞、短語或者句子)建立圖模型。首先將文本中的詞作為節點,詞之間的關系作為邊,建立文本詞匯網絡圖,然后根據圖結構挖掘詞匯之間的關聯關系,找到整個網絡中具有重要地位的詞或短語,作為關鍵詞[28]。顧亦然[29]提出基于PageRank算法,利用詞頻特性,結合語言習慣特性定義位置權重系數,在新浪新聞語料上進行實驗,有效提升了新聞類文本關鍵詞提取的結果。隨機游走算法中具有代表性的是PageRank算法,它通過網頁之間的超鏈接來計算網頁重要性[30]。TextRank算法借鑒了這種重要性可傳遞的思想。
李航[31]為克服傳統TextRank的局限性,提出對詞語的平均信息熵、詞性、位置的特征進行自動優化的神經網絡算法,通過優化詞匯節點的初始權重以及概率轉移矩陣,進而提高關鍵詞抽取準確度。柳青林[32]通過引入馬爾可夫狀態轉移模型,對TextRank算法本身進行了完善,得到的單文本關鍵詞提取結果與人工提取結果更加一致。
TextRank算法對一段文本多次出現的詞賦予更大的權重,因為詞的共現關系即為邊,一個詞的共現詞越多,網絡中與這個詞相連的節點就越多,這樣會使類似于“的”“這”“那”等沒有特別含義的停用詞的權重增大[33]。對于這種情況,可在對文本進行切分時,去掉停用詞或其他符合一定規則的詞語。基于圖的算法,計算詞與詞之間的共現關系,結合其他特征為每個詞打分,從而找到關鍵詞。近年來,基于圖算法的模型有Top-icRank[34]、SalienceRank[35]、PositionRank[36]。
2.3 TF-IDF和TextRank融合方法
TF-IDF和TextRank算法各有不足。TextRank算法為每個節點賦予相等的初始權重,沒有考慮到節點本身不同的重要性,在計算過程中節點的分數也是平均分配到周圍節點,沒有考慮到被分配節點與分配節點的相關程度[37]。為解決這些問題,通常將多種方法進行組合來彌補單一算法的缺點。例如將TF-IDF和TextRank算法相結合,將其作為詞節點之間的特征權重,調整詞節點間的影響力,或者綜合TF-IDF與詞性得到關鍵詞等。
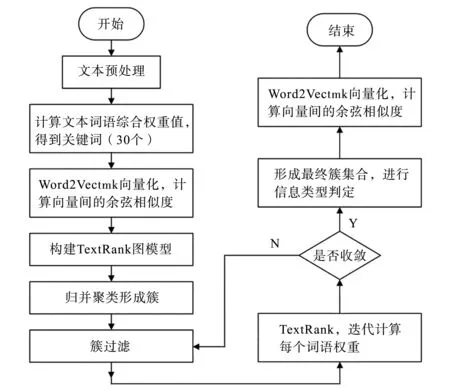
圖3 改進TextRank算法的關鍵詞抽取流程圖Fig.3 The keyword extraction flowchart of the improved TextRank algorithm
尤苡名等[38]提出融合TF-IDF與TextRank 算法的關鍵詞抽取方法,通過引入用戶瀏覽評論后的反饋,提高重要詞語的權重,對TF-IDF算法進行改進。將改進后的詞頻逆文檔頻率作為詞節點特征權重加入TextRank 算法中,提高有效評論中關鍵詞的權重。陳志泊[39]等通過改進TextRank算法,將計算的綜合權值作為詞語特征值,得到高品質的詞語集合,判定信息類型,然后將關鍵詞和信息類型相結合,實現對文本關鍵信息的抽取,最終形成的信息類型集合在緊密性、間隔性、綜合評價指標上均表現良好。改進的TextRank 算法關鍵詞抽取流程如圖3所示。
劉嘯劍等[23]提出一種結合LDA與TextRank 的關鍵詞抽取模型,并在Huth200和DUC2001數據集上驗證了該方法的有效性。張瑾[40]將特征詞位置及詞跨度權值引入到TF-IDF中,并在提取新聞情報關鍵詞實驗中證明了算法的有效性。謝瑋等[41]利用TF-IDF對詞語的位置進行加權,并采用TextRank實現關鍵詞抽取任務。
2.4 基于深度學習的文本關鍵詞抽取方法
隨著人工智能的不斷發展,深度學習方法被廣泛應用于文本關鍵詞抽取方法中。成彬等[42]利用條件隨機場(conditional random field,CRF)模型[43]處理序列標注問題的優勢,通過將詞性信息和CRF模型融入雙向長短時記憶(bidirectional long short term memory,BiLSTM)網絡[44],實現期刊關鍵詞的自動抽取。融合詞性與BiLSTM-CRF的關鍵詞抽取模型如圖4。首先需要對文本進行預處理操作,包括分詞、詞性標注和依存句法分析,然后使用word2vec[45]向量化表示文本,最后使用BiLSTM-CRF模型進行關鍵詞的自動抽取。基于融合詞性特征的BiLSTM-CRF期刊關鍵詞抽取方法,不僅實現了數據時序和語義信息挖掘,而且保證了單詞與單詞之間的關聯性。
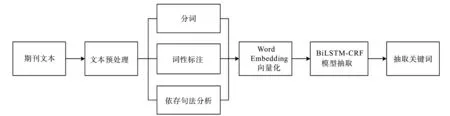
圖4 融合詞性與BiLSTM-CRF的關鍵詞抽取模型Fig.4 Keyword extraction model for journals based on part-of-speech and BiLSTM-CRF
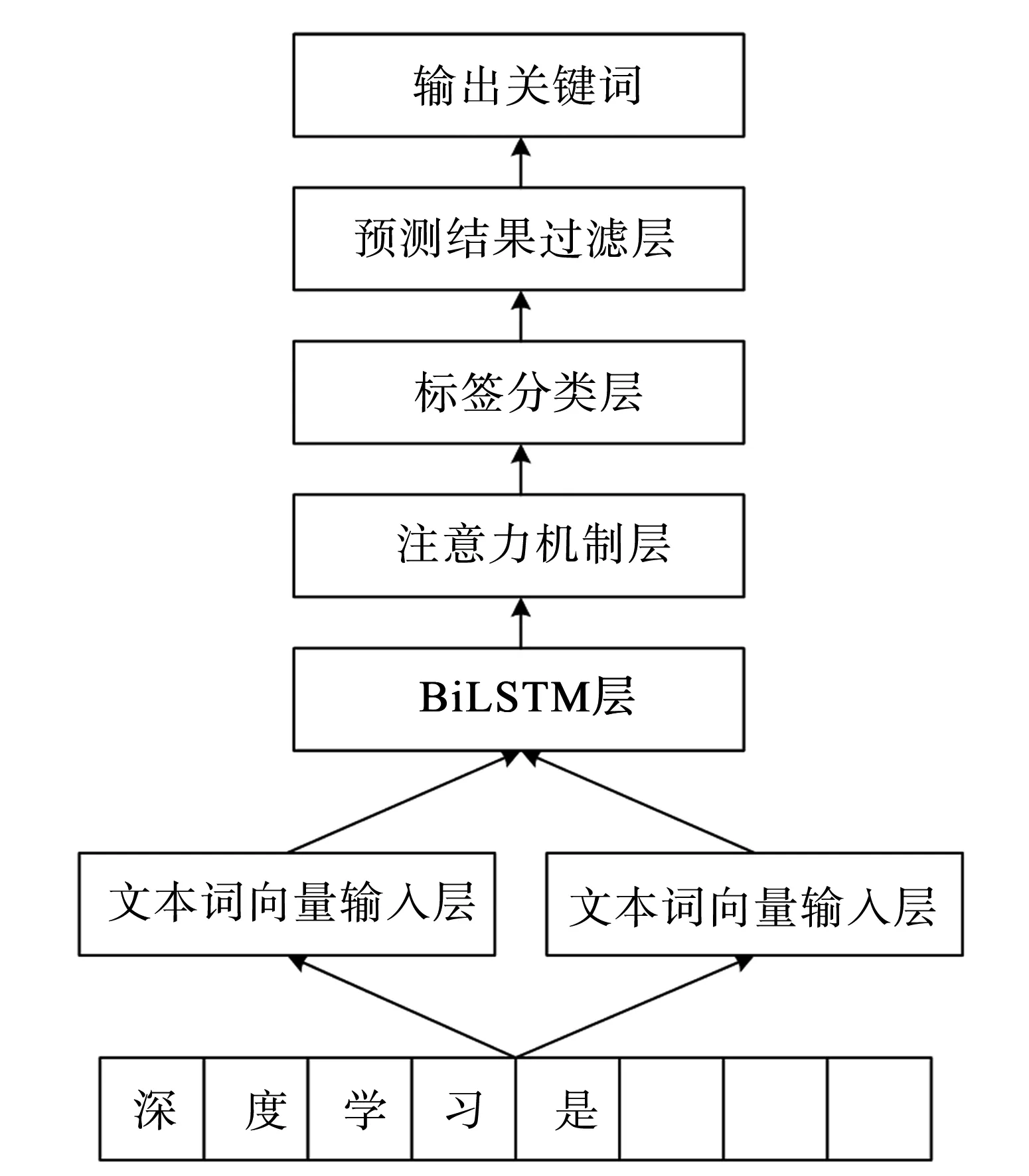
圖5 基于注意力機制的關鍵詞抽取結構圖Fig.5 Structure of keyword extraction based on attention mechanism
楊丹浩等[46]提出基于序列標注的關鍵詞抽取模型,該模型將BiLSTM與注意力機制相結合用于論文關鍵詞的提取。在實驗過程中,將字的向量表示與詞的向量表示作為模型的輸入,將不同顆粒度的向量表示相融合,相比于傳統的無監督模型TextRank,TF-IDF性能有明顯提升。該模型的結構框如圖5所示。
雖然基于序列標注的關鍵詞抽取模型有效利用了BiLSTM和注意力模型,但實驗仍存在兩點不足:一是該實驗僅將論文中的關鍵詞進行標注并訓練,沒有考慮該關鍵詞與文章內容的相關性; 二是沒有考慮論文標題與關鍵詞的關系,將論文標題有效結合提取關鍵詞有待進一步的研究。
考慮到詞向量的優勢,寧建飛等[47]使用Word2vec算法計算文本集詞向量,并構建文本層面的詞匯相似矩陣,同時改進TextRank 算法的初始權重分配方式和迭代計算過程中的概率轉移矩陣。周錦章等[48]針對單詞語義的差異性對TextRank算法的影響這一問題,提出一種基于詞向量與TextRank的關鍵詞抽取方法。同時利用FastText將文本集進行詞向量表示,基于隱含主題分布思想和利用單詞間語義的不同,構建TextRank轉移概率矩陣,最后進行詞圖的迭代計算和關鍵詞抽取。實驗結果表明,該方法的抽取效果優于傳統方法,同時證明了詞向量可以簡單有效地改善TextRank 算法性能。
2.5 幾種民族語言的文本關鍵詞抽取方法
多民族是我國的重要特征之一,結合現代技術研究少數民族語言對各民族歷史文化的傳承,增加我國社會人文內涵,具有重要作用。同時,利用現代信息技術結合大數據的優勢,可以更加深入挖掘分析民族語言文字中隱含的規律,提高民族語言文字數據的處理效率,為少數民族語言文字的研究提供有效幫助。目前研究中主要涉及的少數民族語言文字有藏文、維吾爾文、蒙古文、哈薩克文等,并采用例如LDA模型、深度神經網絡等方法進行研究。我國少數民族中,藏族、維吾爾族和蒙古族具有相對完整的民族語言文字,形成了相對成熟的民族教育體系,相關領域擁有相對較多的民族科學研究人員,因此本文主要研究藏文、維吾爾文和蒙古文三種少數民族語言文字。
2.5.1 蒙古語 蒙古文作為蒙古族通用語言文字,是目前世界上極少數豎向排列的文字之一,從上到下連寫,從左到右移行。回鶻式蒙古文是有記載以來最早的蒙古族文字,回鶻式蒙古文文獻對蒙古族歷史文化和蒙古語發展變化及蒙古文詞法、詞匯的研究具有重要學術價值。但由于蒙古文文字編碼不統一,導致難以制定蒙古文通用規則,而且相對于其他語言的研究相對起步較晚,所以目前蒙古文的研究還處于初級階段。
斯日古楞等[49]基于LDA模型建立蒙古文文本主題模型,分析隱藏在文檔內不同主題和詞之間的關系,通過實驗計算文本的主題分布和查詢語句主題之間的相似度,較好地實現了蒙古文文本主題語義的檢索效果。Hongxiwei等[50]通過在檢索時合成分詞后的蒙古文歷史文獻圖像序列,提取基于輪廓特征表示的文字圖像并進行固定長度的特征向量在線匹配,從而得到降序后的相似度排序結果,以此定位蒙古文歷史文獻圖像中的關鍵詞。白淑霞等[51]考慮到詞袋模型(Bag-of-words model)可能忽略單詞間的空間關系和語義信息問題,提出一種基于LDA的主題模型,用以解決蒙古文古籍的關鍵詞檢索。該方法的性能優于視覺詞袋模型(bag of visual word model)[52]。王玉榮等[53]設計并實現了一個基于云架構的分布式蒙古文碩士論文檢索系統,設計完成了滿足分布式要求的蒙古文分析器,作為系統核心模塊在分布式多節點上實現了蒙古文的索引和檢索功能; 使用BM25概率模型可對蒙古文論文檢索和排序,并具有關鍵詞或摘要的中文檢索功能。
2.5.2 藏語 藏語的主要表現形式是藏文,藏文分為輔音字母、元音符號和標點符號3個部分。其中有30個輔音字母,4個元音符號,以及5個反寫字母用以拼寫外來語。藏文采用上下疊寫的方法自左向右橫寫。目前藏文的關鍵詞研究大多基于藏文新聞網頁,為后續藏文古籍翻譯、藏文情感識別以及藏文輿情分析工作奠定了基礎。雖然藏文文字排序方面的研究取得一定進展,但藏文文字中的幾種特殊音節字母到目前還沒有標準處理方法。
通過對中文關鍵詞抽取方法的學習,對網頁模塊中智能識別后的藏文文本進行自動分詞,采用以此為基礎改進后的TF-IDF算法得到基礎詞集,根據詞向量特征擴展構建候選關鍵詞集,分析利用其語義相關度值并在一定程度上更高效率的提取藏文網頁關鍵詞[54]。艾金勇[55]為提升藏文文本關鍵詞的抽取效果,針對藏文文本特點,將藏文文本的多種特征和TextRank相結合,同時根據詞語之間的語法關系給出了候選關鍵詞的量化權值。與傳統方法相比,關鍵詞抽取效果明顯提升。洛桑嘎登等[56]結合藏文分詞標注研究并實現了一種基TextRank算法的藏文關鍵詞提取技術,該文在1 500句的藏文問句上進行了實驗研究,總體效果較好。才讓卓瑪等[57]通過借鑒中文關鍵詞抽取方法,提出一種基于語料庫的藏語高頻詞抽取算法,并提出對藏語文本的預處理方法,實驗結果表明,該算法的準確率達86.22%。徐濤等[58]針對藏文新聞網頁提出卡方統計量結合詞與詞推薦相結合的方法,并通過實驗得出該方法效果優于融入位置的TF-IDF算法。
2.5.3 維吾爾語 維吾爾文是新疆大多數人互相交流的語種之一。我國維吾爾族使用的是以阿拉伯字母為基礎的拼音文字。相對于通用語言文字的識別,維吾爾文的識別研究起步相對較晚,電子化維吾爾文本數據較少,語料規模較小,質量不高,為維吾爾文的研究帶來了困難。研究者們通過直接識別維吾爾文圖片、借鑒中文關鍵詞的語義分析等技術,試圖克服上述問題。
李靜靜等[59]提出并實現一種基于由粗到細層級匹配的關鍵詞文檔圖像檢索方法,通過支持向量機(SVM)分類器學習,從單詞圖像提取方向梯度直方圖(HOG)的特征向量,可以有效實現維吾爾文關鍵詞圖像檢索。阿力甫·阿不都克里木等[60]提出一種基于TextRank算法的維吾爾文關鍵詞提取方法,首先對輸入文本進行預處理,濾除非維吾爾語的字符和停用詞,然后利用詞語語義相似度、詞語位置和詞頻重要性加權的TextRank算法提取文本關鍵詞集合。實驗結果表明,該方法能夠提取出具有較高識別度的關鍵詞。熱依萊木·帕爾哈提[61]通過實驗對維吾爾文文本基于TextRank、TF-IDF、SDA(system display architecture)、SparseSVM四種方法分別進行關鍵詞提取和文本文本分類,實驗效果可滿足需求。買買提阿依甫等[62]通過對維吾爾文語言特殊性的分析,提出一種結合word2vec和LDA模型生成主題特征矩陣,獲取語義粒度層面特征信息,通過豐富卷積網絡池化層特征來提高情感分類的準確率,取得了比傳統機器學習方法更好的情感分類性能。
2.6 關鍵詞抽取技術總結
本文通過對各種關鍵詞抽取方法進行闡述,分別分析了無監督方法和有監督方法的技術特點、代表性模型及其優缺點,結果見表1。
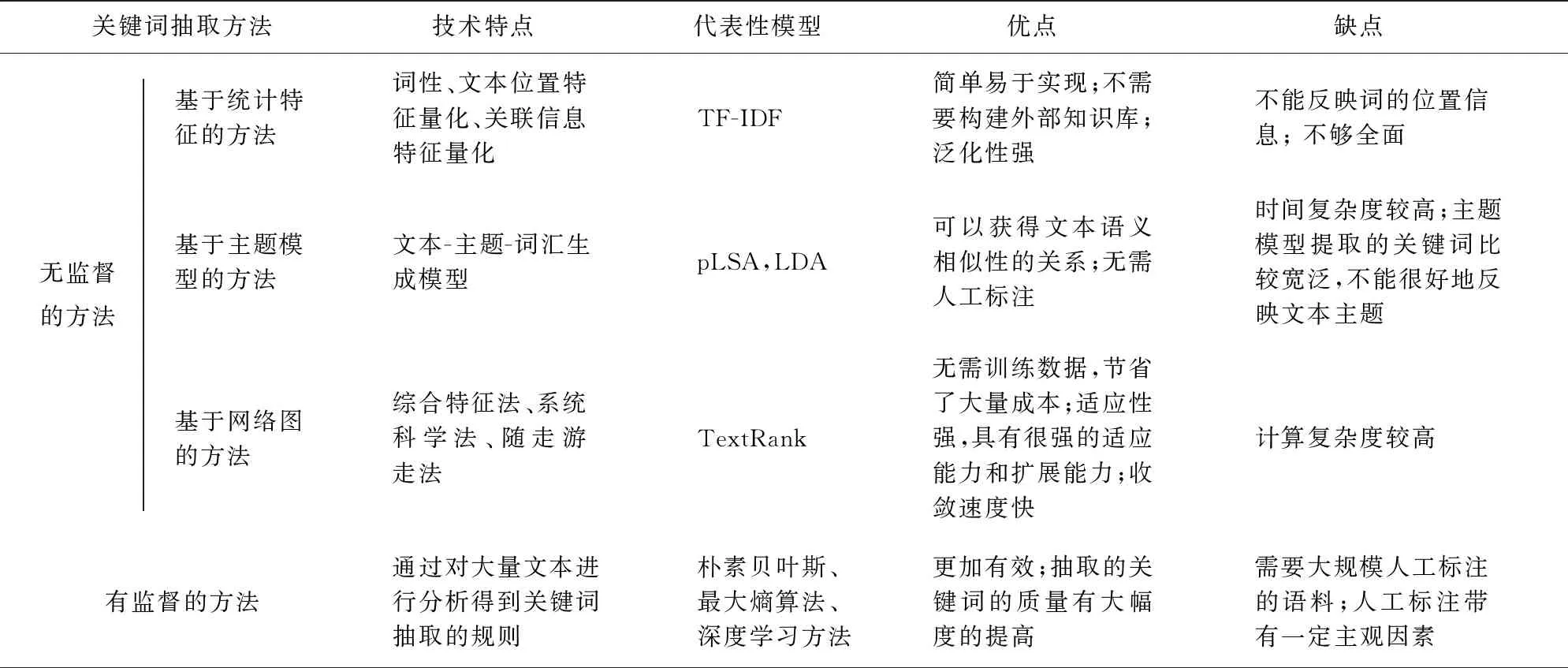
表1 文本關鍵詞抽取技術總結Tab.1 Summary of text keyword extraction technologies
3 關鍵詞抽取的評價方法
關鍵詞抽取質量優劣的評價標準是其符合文本的實際語義,高質量的關鍵詞應具備可讀性、相關性、覆蓋性和簡潔性等特質,即關鍵詞不僅具有實際意義,而且關鍵詞和文本主題保持一致,更能夠覆蓋文本的各個主題。此外,關鍵詞還應簡潔明了,各個關鍵詞之間也應相關聯。目前對關鍵詞抽取任務一般有兩種方法,一種是由領域專家進行人工評價,這種方式可操作性強但缺點也明顯,比如認識分歧、詞或短語的組合歧義等問題。另一種常用的評價指標是: 準確率P(precision)、召回率R(recall)和F值(F-measure)。
(10)
其中KP表示抽取出的正確關鍵詞條數,K表示抽取出的關鍵詞條數。
(11)
其中DK表示文檔中的關鍵詞條數。
(12)
其中: 準確率和召回率的取值范圍為[0,1],取值越接近1,分別表示抽取出的關鍵詞正確率越高和越多的關鍵詞被正確抽取;F值為準確率和召回率的調和平均值,能夠綜合準確率和召回率; ?為調節參數,當?=1時,表示為F1值,即
(13)
4 總結與展望
通過總結文本關鍵詞抽取的各種方法,考慮到應用環境復雜性的影響,對于不同類型的文本,例如長文本和短文本,通用語言文本和少數民族語言文本,采用同一種文本關鍵詞抽取方法得到的性能結果會有所不相同。所以,針對不同類型、不同民族語言的文本應采取不同的算法。針對目前文本關鍵詞抽取技術面臨的研究難點,提出以下需進一步研究內容:
(1) 多種方法的有效融合。使用傳統方法和基于深度學習的方法,或者其他的多種方法相融合的方式改進中文或少數民族語言文本關鍵詞抽取的性能。
(2) 結合語義的方法。隨著深度學習的發展,相較于傳統機器學習時代,自然語言處理技術發生了翻天覆地的變化。從word2vec模型,到Elmo模型,再到后來Google提出的BERT語言模型,大幅度提升了自然語言處理多種任務的性能,BERT能動態調整語義信息有效解決一詞多義的問題,將文本理解和語義表示推向了新高度。
(3) 借助外部知識庫改善關鍵詞抽取技術。神經網絡在大規模語料訓練過程中,并沒有顯式的將知識進行合理的結構化組織,從而導致模型領域泛化能力較弱。利用知識圖譜等形式進行組織并實現知識融合,可以幫助模型提高泛化能力,是未來值得探索的重要方向。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
