基于長短時記憶網絡的電商大數據同一性標定*
2021-04-06 10:48:18劉亞波吳秋軒
計算機工程與科學 2021年3期
劉亞波,吳秋軒
(杭州電子科技大學自動化學院,浙江 杭州 310018)
1 引言
在政府采購電子化的趨勢下,發揮基于機器學習的大數據分析優勢,對電商大數據進行同一性標定,即在政府采購海量電商大數據中找出同一種商品,對提升政府采購決策水平和效率具有重要意義[1]。同一性標定問題實質上是一個短文本相似度計算問題,但在有些實際應用場合,對標定準確率和標定速度均有較高要求。
在短文本相似度計算方面,Ho等[2]基于離散小波變換將文本轉換成DNA序列,利用歐幾里得距離計算已序列化文本之間的相似度。但是,文本向量化解釋性不強,Yao等[3]提出了基于改進長短時記憶網絡LSTM(Long Short-Term Memory)的短文本相似度計算方法,并通過其實現的歸一算法來避免梯度消失。僅通過余弦距離計算相似度無泛化能力,馬慧芳等[4]通過加權計算將不同詞項內外共現距離相關度與強類別特征相融合用于計算短文本相似度,但考慮的語義和語境信息有限。Wu等[5]將基于BTM(Biterm Topic Model)主題建模并采用JS(Jensen-Shannon)散度計算文本相似度和基于詞表征全局向量GloVe(Global Vectors for word representation)詞向量建模并用改進詞重WMD(Word Mover’ Distance)衡量文本相似度進行線性融合,作為距離函數實現K-means聚類,該方法在微博短文本上具有良好表現,但建模過程與計算相對復雜。Flisar等[6]基于DBpedia Spotlight框架來識別短文本中的相關概念進而實現短文本分類,但提取大量不相關特征降低了以相似度計算來實現分類任務的性能。Yang等[7]通過組合語料庫中單詞對的全局權重和在自身短文本中的局部權重來計算短文本相似度,對于全局和局部共現少的短文本,其樣本利用率低。Lee等[8]將詞嵌入模型運用于保險分析,提取索賠短文本描述特征,經詞嵌入模型處理后進行相似度計算進而分類,具有良好的效果,但面對較長文本描述以及一詞多義時有一定障礙。García-Méndez等[9]為實現個人銀行交易文本描述分類,經分詞、除去停詞等預處理,基于Jaccard距離計算的文本相似度結果來減少訓練樣本,進而使用SVM實現分類,相似度計算方法準確率低,而且訓練樣本數量大時SVM訓練速度慢。Maurya等[10]為降低不同發票文本描述處理成本和時間,針對在線反饋的格式不同但內容相同的文本描述,基于相似性進行排名,而針對不同內容文本描述,采用分類相似度計算,由于反饋次數多,導致并未顯著降低整體時間成本。
本文考慮到以上工作的不足,提出了一種電商大數據同一性標定新模型。該模型由文本分詞、重要性排序和相似度計算等3個子模型串聯組成,充分結合了級聯結構和深度循環神經網絡的優勢。與傳統的同一性標定相比,本文模型在重要性排序和相似度計算子模型中采用LSTM[11]作為分類器,不存在單獨的特征提取過程。另外,在模型中引入了分詞優化、GloVe詞向量[12]、二分查找和詞序列語義校驗等技術,確保了面對易混淆商品時能標定出同一商品,提升了標定速度、準確率和泛化能力。
本文的研究意義體現于:(1)嘗試構建3級級聯網絡模型,利用長短時記憶網絡特性,提高同一性標定的準確率。(2)采用GloVe詞向量技術進行每一級循環網絡模型的優化訓練,提高訓練樣本利用率。(3)引入二分查找和詞序列語義校驗等技術,提高模型的標定速度和泛化能力。
2 同一性標定模型構建
2.1 模型整體架構
本文提出一種基于LSTM的同一性標定模型。該模型分為3個子模型:分詞子模型、LSTM重要性排序子模型(LSTM importance sub-model)和LSTM相似度計算子模型(LSTM similarity sub-model),整體結構如圖1所示。
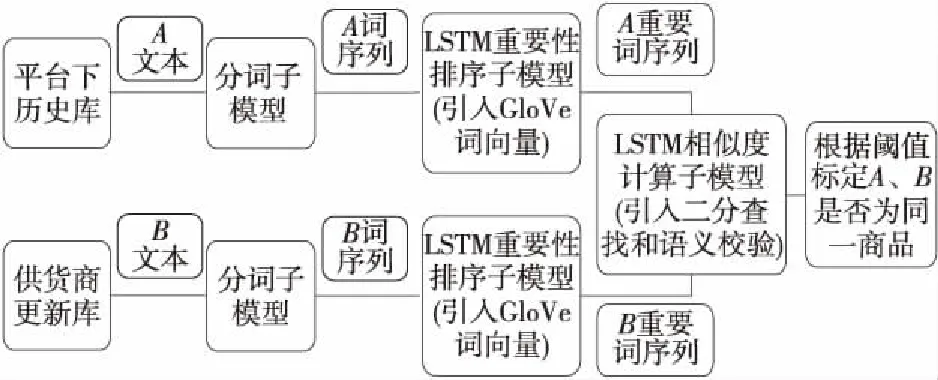
Figure 1 Structure of the identity calibration model based on LSTM
供貨商更新的商品B能否上架到政府采購平臺,取決于平臺下歷史庫中是否存在商品A,其具體參數與B一模一樣,若不相同則B無法上架。商品B的文本描述被分詞子模型處理成詞序列,通過LSTM重要性排序子模型篩選出B的重要詞序列。同時,商品A也完成了上述操作步驟,商品A和B的重要詞序列輸入到LSTM相似度計算子模型,輸出A和B的相似程度,根據閾值來標定二者是否為同一商品,進而決定B能否上架。
2.2 分詞子模型構建
分詞處理是本文同一性標定模型研究的基礎,它會直接影響文本向量化,影響模型訓練進而決定模型輸出結果。現語料庫規格龐大,人工進行分詞處理效率低下。為統一規范分詞,在語言技術平臺LTP(Language Technology Platform)[13]基礎上構建分詞子模型來完成此預處理過程。
主要思路如下:(1)將商品的文本描述分割成關鍵詞;(2)根據實際需求構建一個強制詞典;(3)從詞典生成正則表達式,基于模糊匹配算法快速查找切分后的詞;(4)如果不同詞以組合形式存在于強制詞典中,則將詞進行合并,否則跳過處理下一個商品。分詞子模型的優勢在于能將錯誤分割的詞進行合并,并保證同一文本多個不能拆分的詞也能正確合并。
表1僅展示了筆記本電腦、單反相機、復印機這3類商品的標題和LTP以及本文分詞模型的分詞結果。對“聯想(Lenovo)小新Pro13.3英寸全面屏超輕薄筆記本電腦(標壓銳龍R5-3550H 16G 512G 2.5K QHD 100%sRGB)銀”這條筆記本電腦商品標題而言,“小新Pro”顯然要比“小”和“新”這2個單獨的詞更符合分詞要求,而且本文分詞子模型將“Pro13.3”和“英寸”這種不太合理的分詞轉換成“小新Pro”和“13.3英寸”。對單反相機和復印機這2類商品標題來說,將“單反”和“相機”組合成的“單反相機”和“多”與“功能”合并成的“多功能”等關鍵詞更有表征能力。綜上,本文分詞子模型使各類商品的分詞結果更能準確表征商品信息,為后續LTSM重要性排序和相似度計算子模型研究提供良好的實驗數據。
2.3 LSTM重要性排序子模型構建
2.3.1 LSTM簡介
對商品文本描述而言,詞或短語順序不同,整個語義也會隨之改變。循環神經網絡RNN(Recurrent Neural Network)[14]能夠很好地處理此類序列信息。但是,RNN只有短期記憶,沒有長期記憶。深度學習專家Schmidhuber提出了LSTM,專門用于解決RNN的長期依賴問題。因而本文基于LSTM來構建重要性排序和相似度計算子模型。
2.3.2 GloVe詞向量化技術
考慮到無法直接輸入原始文本到神經網絡,此子模型采用詞表征全局向量GloVe實現文本向量化,實現步驟如下所示:
(1)建立共現矩陣X,矩陣中的Xij表示當前商品詞序列中的第i個詞與上下文詞序列中的第j個詞在特定大小的上下文窗口內共同出現的次數。
(2)詞向量和共現矩陣之間的近似關系可以用式(1)表示:
(1)
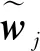
(3)為使詞向量wi,wj與共現次數Xij具有良好的一致性,即詞向量蘊含共現次數信息,針對上述的詞向量表達式構造損失函數,目的在于迭代訓練使二者盡可能接近:
(2)
其中,V表示詞序列中詞的個數。
此損失函數只是在最基本的均方損失的基礎上增加了一個權重函數f(Xij),采用了如式(3)所示的權重分段函數:

Table 1 Comparison of word segmentation sub-model results
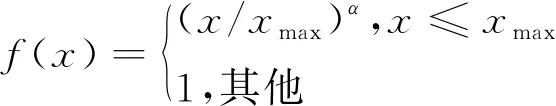
(3)
其中,α=0.75,xmax=100。當詞序列中詞i與詞j的共現次數Xij小于最大共現次數xmax時,f(Xij)遞增;當Xij大于xmax時,f(Xij)=1,不再變化,即保證詞序列中同時出現次數多的單詞的權重大于很少同時出現的單詞,且權重也不會過大。
2.3.3 在子模型中引入GloVe詞向量
將商品的文本描述被分詞子模型處理成的詞序列作為LSTM重要性排序子模型的輸入。圖2是LSTM重要性排序子模型的結構,商品詞序列中的wordi均被轉換成GloVe詞向量,以LSTM構建的分類器預測該詞是詞序列中重要詞的概率。
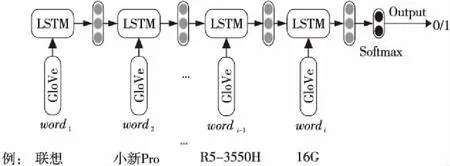
Figure 2 Structure of LSTM importance ranking sub-model
針對標題如“聯想(Lenovo)小新Pro13.3英寸全面屏超輕薄筆記本電腦(標壓銳龍R5-3550H 16G 512G 2.5K QHD 100%sRGB)銀”的商品,利用LSTM重要性排序子模型篩選出其重要詞序列的步驟如下所示:首先將分詞子模型處理得到的商品詞序列中的詞全轉換成GloVe詞向量;然后獲得詞序列中每一個詞的重要程度,例如針對“16G”一詞,依次輸入從詞序列開始到當前所有詞的向量,將其共同建模到同一數組,此數組充分包含該詞及其全部上文語義信息,能有效提高重要詞預測的準確率,并由Softmax層輸出“16G”為重要詞的概率,其它詞的處理方式類似;接下來通過概率對所有詞重要程度排序,根據事先設定的閾值,便可篩選出此商品中的重要性大的詞;最后將該商品的重要詞序列輸出到LSTM相似度計算子模型。
2.4 LSTM相似度計算子模型構建
2.4.1 LSTM相似度計算子模型概述
由LSTM重要性排序子模型得到了商品的重要詞序列后,只需對不同商品重要詞序列進行相似度計算,便可在電商大數據中標定出同一種商品。LSTM相似度計算子模型的結構如圖3所示。
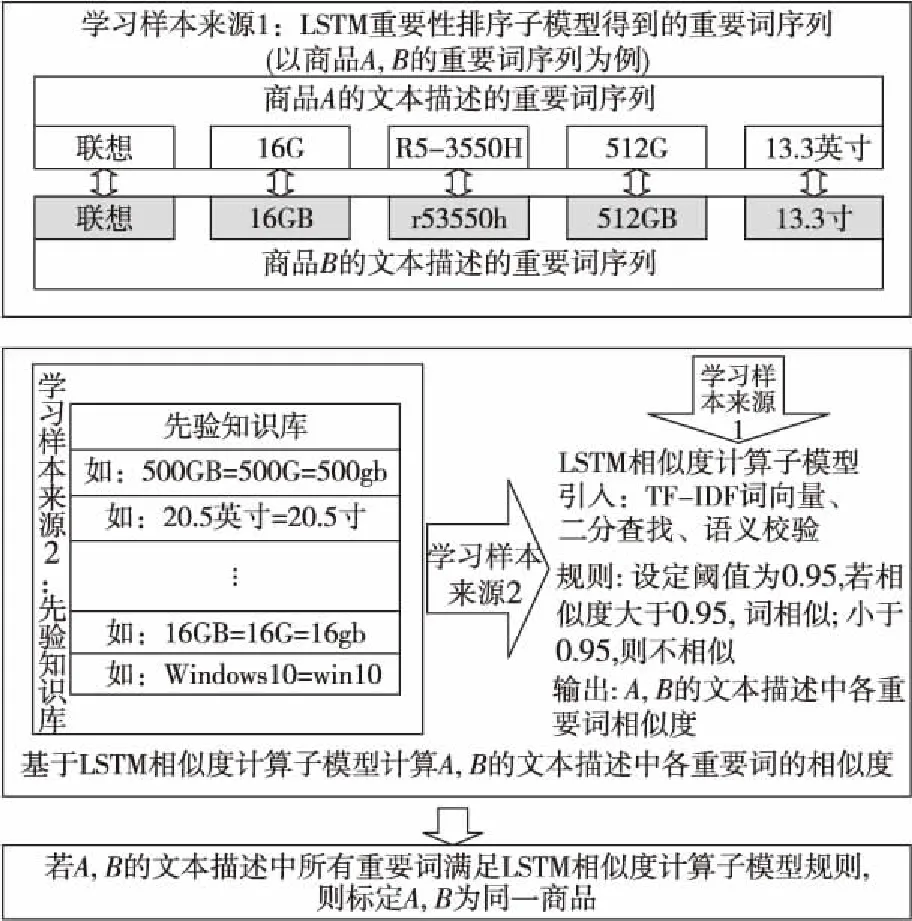
Figure 3 Structure of LSTM similarity calculation sub-model
LSTM相似度計算子模型的學習樣本,一部分來源于LSTM重要性排序子模型的輸出,另一部分來源已有的先驗知識。商品A、B的文本描述重要詞序列相似度計算步驟如下所示:
步驟1商品A、B的文本描述中重要詞數分別為na,nb,則最短序列長度n=min(na,nb);
步驟2對商品A、B的文本描述中重要詞依次進行相似度計算,將重要詞對輸入到LSTM分類器,分類器輸出該詞對相似的概率,進行計算的次數為M=na×nb;
步驟3若M次計算中有m1次LSTM分類器輸出概率大于或者等于事先設定的閾值,則商品A、B的文本描述中有m1對重要詞相似。若m1≥n,則可標定商品A、B為同一種商品。
經實驗發現,采用詞袋模型BOW(Bag Of Words)向量化重要詞序列,效果最為理想。由于BOW未考慮每個詞在序列中的重要程度,因此引入詞頻-逆文檔頻率TF-IDF(Term Frequency-Inverse Document Frequency)計算詞序列中每個詞的權重大小。詞序列總數為N,詞序列d中的詞t的TF-IDF權重估算公式如式(4)所示:
(4)
其中,tf(t,d)為詞t在詞序列d中的頻次,而df(d,t)為包含詞t的詞序列d的數量。
2.4.2 在子模型中引入詞序列語義校驗
雖然TF-IDF能彌補BOW未考慮詞序列中各詞的重要程度的不足,但對形如“ABBC”和“BBAC”這種二元詞組,其TF-IDF詞向量是相同的,導致LSTM相似度計算子模型的計算結果也相同,這是因為TF-IDF并未考慮詞序列中各詞的語義信息。
針對TF-IDF上述不足,本文引入了詞序列語義校驗。在向量化的詞序列后面加上一位語義校驗位,其作用在于判斷需要進行相似度計算的二元詞組的語義是否一致。語義校驗結果如表2所示,形如“ABBC”和“BBAC”這種二元詞組雖然詞向量相同,其語義檢驗位卻為“False”。若作為學習樣本,此二元詞組被判定為負樣本。形如“ABBC”和“ABC”這種二元詞組詞向量不相同,語義校驗位為“True”,作為學習樣本,根據先驗知識和電商大數據同一性標定任務需求,此二元詞組被判定為正樣本。

Table 2 Results of word sequence semantic verification
2.4.3 在子模型中引入二分法查找
政府采購平臺的歷史庫和供貨商更新庫中商品數量巨大,同一性標定計算量大。為提升在海量商品數據中標定出同一種商品的速度,本文在LSTM相似度計算子模型中引入了二分法查找。
假設供貨商更新庫中的商品均能在政采平臺的歷史庫中標定出來,利用二分法查找,則歷史庫中某一商品平均成功的查找次數為庫中所有商品查找次數和與查找概率的乘積,如式(5)所示:
(5)
其中,n表示商品總數,h表示當前商品的查找次數。Pi表示商品i的查找概率,Ci表示商品i的查找次數。
當查找次數最大時,即h=log2n+1,二分查找的時間復雜度為T(n)=O(lgn)。若不采用二分法查找,其計算時間復雜度為T(n)=O(n),二者相比可見二分查找法大幅降低了LSTM相似度計算子模型的計算時間復雜度。特別需要指出的是,此二分法查找法是針對政府采購平臺的歷史庫和供貨商更新庫中所有的商品,因此當商品總數量n巨大時,提升的查找速度是非常可觀的。
3 學習樣本制備及模型訓練
3.1 電商大數據采集與整理
電商網站具有不定時更新的特點,同時不同網站之間也存在差異,基于Python編寫的商品信息獲取程序,能避免網站差異性,定時獲取商品信息,從而保證商品信息實時性。本文一共獲取了筆記本電腦、單反相機和復印機這3種品類共8.5萬條商品標題和商品詳細參數,因而擁有了一定規模的電商領域語料庫。本文對商品的文本描述進行了去除無用標點符號等文本預處理,以方便在此基礎上進行模型的研究和實驗。
3.2 學習樣本制備
3.2.1 LSTM重要性排序子模型樣本制備
商品原始數據主要來源于商品信息獲取程序。將分詞子模型處理后得到的商品詞序列,作為LSTM重要性排序子模型學習樣本,根據先驗知識和對商品的深入了解,將最能表征此商品的詞標注為重要;大部分商品均包含的或不具表征能力的詞等標注為不重要。
2.2節提及的3類商品標題分詞處理得到的詞序列的標注結果如表3所示,其中樣本標簽為1表示重要,樣本標簽為0表示不重要。“筆記本電腦”是筆記本電腦類中的通用詞,因而不重要;“EOS 800D”是單反相機類中一特定商品的型號,故重要;而“新款標配”不具有表征復印機的能力,所以也不重要。

Table 3 Product segmentation
3.2.2 LSTM相似度計算子模型樣本制備
LSTM相似度計算子模型的學習樣本一部分來源于先驗知識庫,另外一部分是LSTM重要性排序子模型輸出組成的重要詞二元組。構建此子模型的學習樣本庫的方式如表4所示,其中Label為1代表相似,Label為0代表不相似。
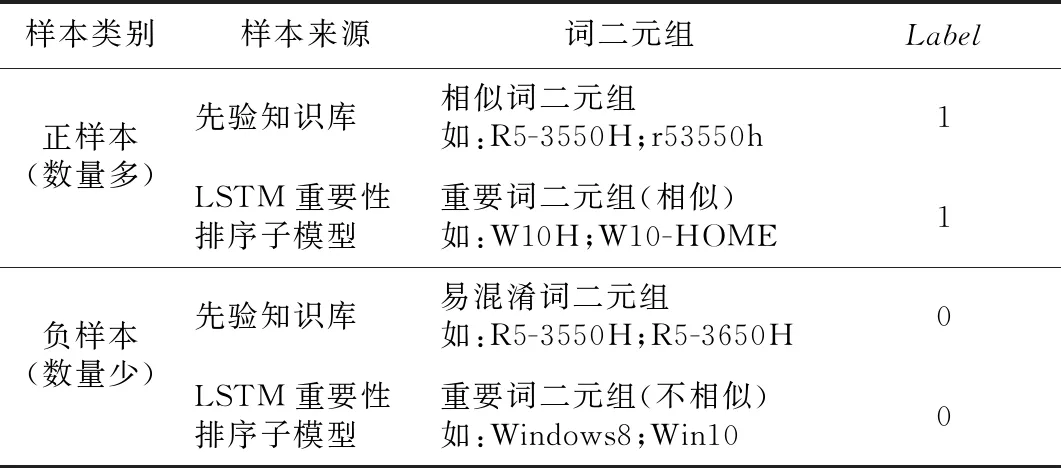
Table 4 Building LSTM similarity calculation sub-model learning sample library
正樣本包括先驗知識庫中的相似詞二元組和LSTM重要性排序子模型輸出的相似重要詞二元組,多是一些型號、操作系統和品牌等重要詞的簡寫或者別稱等,這些二元詞組的格式全然不相同且涉及種數繁多,因此本文采用監督學習來代替費時費力的人工判定方式。負樣本包括先驗知識庫中的易混淆詞二元組和LSTM重要性排序子模型輸出的不相似重要詞二元組,主要是同一系列下編號很相似的型號,如“R5-3550H”和“R5-3650H”;寫法大致統一卻不相同的操作系統,如“Windows8”和“Win10”等傳統方法難以區分開的二元組。
3.3 同一性標定模型訓練策略
考慮到基于LSTM的同一性標定模型包含了2個用法不同的神經網絡模型,樣本庫的量大而且還需要補充新樣本,完全靠本機訓練測試,過于耗時。本文采用如圖4所示的訓練測試策略。小型學習樣本庫采用本地訓練測試,大型樣本庫采用華為云訓練和本機測試。
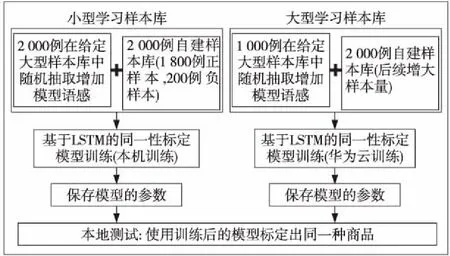
Figure 4 Two training methods of identity calibration model based on LSTM
3.3.1 LSTM重要性排序子模型訓練
LSTM重要性排序子模型采用監督學習訓練方式,所用的正負樣本的比例為3∶1,采用3萬條正樣本和1萬條負樣本進行優化訓練LSTM。所有的詞序列樣本均被表征成GloVe詞向量。此外,設定的目標函數為二元交叉熵BCE(Binary Cross Entropy)函數,表達式如式(6)所示:
lg(1-pk)]
(6)
其中,yk和pk分別表示第k個樣本對應的標簽和被預測成正樣本的概率;m表示每次訓練迭代樣例個數;激活函數全部采用ReLU激活函數[15],對應的表達式如式(7)所示:
f(z)=max(0,z)
(7)
ReLU可由f(z)=lg(1+ez)逼近,ReLU激活函數用于LSTM處理自然語言問題取得了良好效果。另外學習率從0.01開始下降,每訓練100次降為原來的1/10。由于訓練數據數量較大,訓練的迭代次數設為100次。最后訓練驗證集的準確率(Accuracy)曲線和損失(Loss)曲線如圖5所示。在LSTM重要性排序子模型訓練次數達到20次時,重要性排序準確率逐步上升,準確率在0.991~0.993波動;損失曲線在20次左右波動范圍縮小,雖未飽和但也在可接受范圍之內。
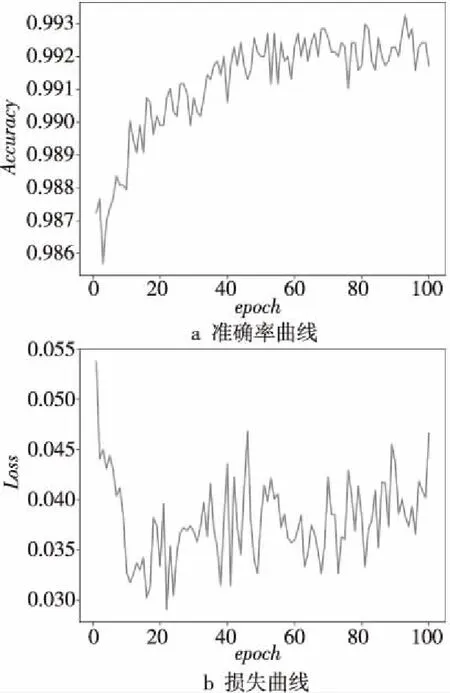
Figure 5 Training results curve of LSTM importance ranking sub-model
3.3.2 LSTM相似度計算子模型訓練
LSTM相似度計算子模型的訓練同樣采用監督學習方式,并且目標函數和激活函數均與重要性排序子模型一樣。此模型的輸入張量維度高于前者,因此訓練的各參變量有所改變,此模型還利用了帶有語義校驗位的IF-IDF詞向量來表征樣本詞序列。用正負樣本比例為3∶1的學習樣本訓練LSTM相似度計算子模型,訓練的迭代次數(epoch)為100次。最后訓練驗證集的準確率Accuracy曲線和損失Loss曲線如圖6所示。
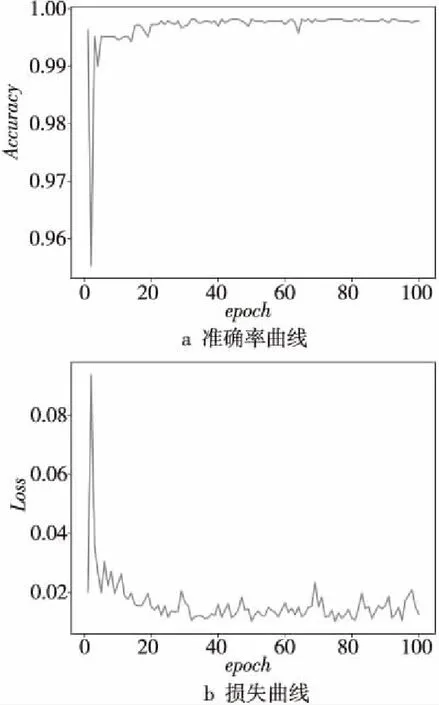
Figure 6 Training results curve of LSTM similarity calculation sub-model
由圖6可知:訓練次數在達到100次時,LSTM相似度計算子模型準確率曲線趨近飽和,此刻準確率達到最大值;損失曲線在100次左右就基本只在0.01~0.02小幅度波動。
4 實驗結果及分析
為了驗證本文基于LSTM同一性標定模型在電商大數據上的性能,特設置2組實驗進行測試分析。第1組為2個子模型與傳統模型的對比實驗;第2組實驗在測試集上驗證本文模型的性能。實驗在GPU 1.2 GHz、顯存12 GB的華為云服務器上進行訓練,在CPU 2.4 GHz、內存8 GB的Windows 10專業版64位操作系統的個人計算機上進行測試,深度學習框架為Keras+TensorFlow,軟件編程環境為Python 3.6.6。
4.1 實驗1:子模型與傳統模型對比實驗
本實驗的目的是測試和展現本文的同一性標定模型與傳統模型相比在標定準確率、速度和泛化能力方面的提升。測試數據來自不同電商網站上獲取的商品標題與詳細參數。實驗分別給出LSTM重要性排序子模型和傳統模型的準確率對比結果,LSTM相似度計算子模型與傳統模型相比,其準確率、標定速度和LSTM相似度計算子模型泛化能力的提升等。
在LSTM重要性排序子模型與傳統模型對比實驗中,將此子模型與RNN模型(RNN model)和未采用GloVe詞向量的LSTM基本模型(簡稱為No GloVe model)的準確率進行比較,結果如圖7a所示。類似地,在LSTM相似度計算子模型與傳統模型對比實驗中,與單LSTM相似度計算模型(single LSTM model)和未帶有語義校驗位LSTM相似度計算子模型(簡稱為no Parity model)的準確率對如圖7b所示。
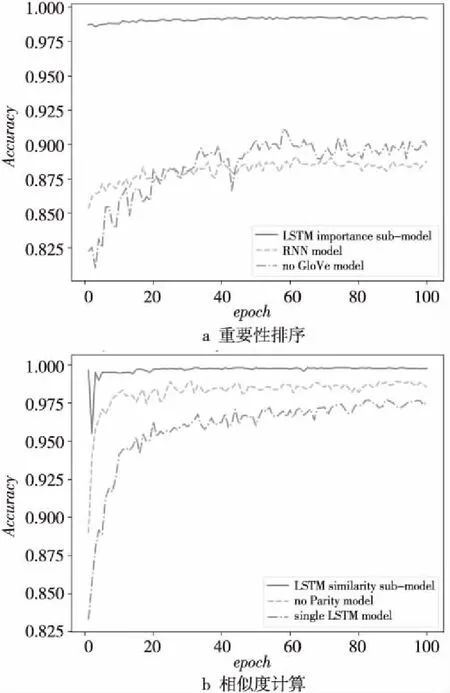
Figure 7 Accuracy comparison of the two sub-models and the traditional models
LSTM相似度計算子模型與傳統未帶有語義校驗位的子模型泛化能力對比如表5所示,LSTM相似度計算子模型與未引入二分法查找子模型的標定速度對比如表6所示。
由圖7a知,在處理不同網站上書寫格式不統一的商品詞序列時,本文LSTM重要性排序子模型的準確率遠高于RNN模型和未采用GloVe詞向量的基礎LSTM模型的準確率。由圖7b可知,本文LSTM相似度計算子模型的準確率遠高于單LSTM相似度計算模型的準確率。未加入語義校驗位的子模型準確率雖然略低于LSTM相似度計

Table 5 Comparison of generalization ability between LSTM similarity sub-model and traditional model
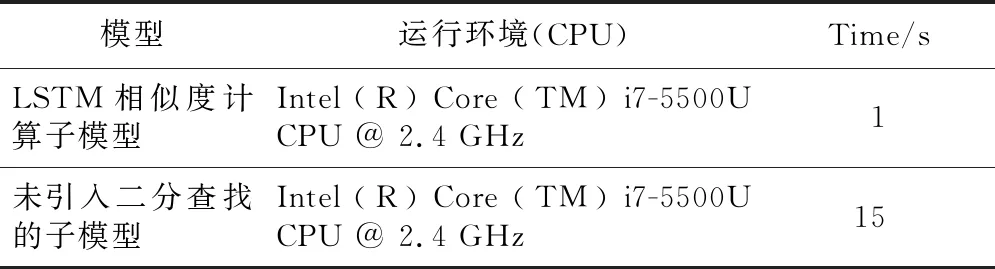
Table 6 Comparison of model calibration speed before and after introducing binary search
算子模型的準確率,但是由表5可知,未加入語義校驗位的子模型會將形如“R5-3550H”與“R3-5550H”的詞二元組誤判為相似,這是因為其并未考慮語義,識別不出二者實際上表示不同的型號。而本文的LSTM相似度計算子模型考慮了語義,不會出現上述誤判。
由表6可見,未引入二分法查找的子模型,計算出一對商品詞序列中所有詞組成的詞二元組相似度需要15 s,而引入二分法查找之后只需要1 s。LSTM相似度計算子模型在計算速度上有明顯的提升,因而本文提出的基于LSTM同一性標定模型在電商大數據中標定出同一種商品的速度也會隨之提高。
4.2 實驗2:模型性能測試
為進一步驗證本文模型性能,分別測試了LSTM重要性排序子模型和LSTM相似度計算子模型在測試集上的表現,測試結果如圖8所示。其中LSTM重要性排序子模型測試集由8 918種商品文本描述經分詞處理成的詞序列組成,重要性子模型能夠正確篩選8 751種商品文本描述中的重要詞,誤判的只有167種,預測結果與人工標注相同的有4 029對,準確率達到了97%。
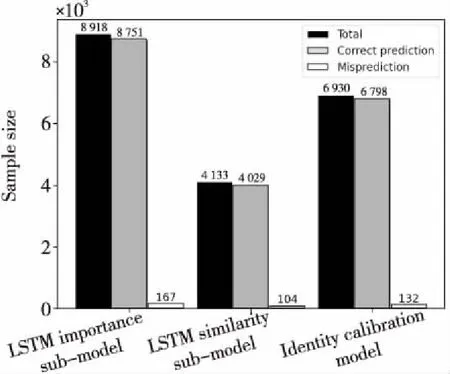
Figure 8 Performance of the proposed models on test sets
現對政府采購平臺的歷史庫中抽出的77條筆記本電腦數據,和供貨商更新庫取出的90條筆記本電腦數據組成的6 930例艱難樣本進行同一性標定。所謂艱難樣本是指同一品牌系列下型號只有微小差異而且配置參數非常接近的商品,或者是具體參數相同文本描述完全不一致的商品等,對艱難樣本的同一性標定難度比一般樣本要大。表7展示是以筆記本電腦商品為例,6 930例艱難樣本中的某一例正樣本和負樣本,其中標簽為1代表同一種商品,標簽為0代表非同一種商品。

Table 7 Examples of hard samples for laptops
表7中正樣本其實是同一種商品,但這對商品文本描述不相同,它們字符串排列順序不一致,字符串長度不相同,字母大小寫不統一,同一參數的格式不統一(包括縮寫、簡寫、人為可接受的誤寫、中文或英文表達但語義相同、由先驗知識才可判定)。如“聯想”與“Lenovo”和“1年保修”與“一年保修”語義一致,“14.0”與“14英寸”代表同一屏幕尺寸,“集成”與“集顯”代表集成顯卡,“I5-8250U”與“i58250u”代表同一CPU型號。負樣本不是同一種商品,但這對商品文本描述很相近,主機型號“ 440 G5-20014209059”與“ 440 G5-20014208159”只有細微差異,內存容量雖然都是8 GB但類型不相同,分別為“DDR4”和“DDR3”,“I5-8250U”和“I5-8250”雖然只有微小區別,但根據先驗知識二者的CPU型號并不相同。采用人為標定這些易混淆的艱難樣本也具有一定難度,但本文模型能正確標定。從圖8可以看出,本文模型(Identity calibration model)標定正確的艱難商品共有6 798例。
5 結束語
針對政府采購平臺品類繁雜且書寫格式無統一規范的電商大數據,本文提出了一種基于長短時記憶網絡(LSTM)的同一性標定新模型。該模型將深度學習循環神經網絡與級聯思想相結合,逐級進行分詞處理、重要性排序和相似度計算來標定出同一種商品。通過理論分析和實驗得到如下結論:(1)本模型采用二分法查找后,標定速度有一定的提升;(2)詞序列轉換成GloVe詞向量后,樣本利用率提高;(3)加入語義校驗后,標定泛化能力增強;(4)本模型對于政府采購平臺上筆記本電腦這一類商品的同一性標定具有較高的準確率;(5)本模型對于筆記本電腦這一類商品的艱難樣本標定準確率達98%。
下一步將會把此模型運用于復印機和單反相機等品類商品的同一性標定,以增強模型處理不同商品的通用性。另一方面擬利用哈希查找、雙向編碼器表征量BERT(Bidirectional Encoder Representations from Transformers)[16]文本向量化等,進一步提高模型的準確率、標定速度、樣本利用率和泛化能力等。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
電子制作(2018年18期)2018-11-14 01:48:06
兒童繪本(2018年5期)2018-04-12 16:45:32
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
