基于MSD-Vnet 的三維醫學圖像配準
2021-04-08 09:25:10李姍姍張娜娜張媛媛丁維奇
電視技術 2021年1期
李姍姍,張娜娜,張媛媛,丁維奇
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
0 引 言
圖像配準提供了對通過不同方式獲得圖像進行視覺分析的能力。醫學圖像配準的目的是建立兩個或多個三維醫學圖像之間的解剖對應關系,提高醫學AI 分類診斷和定量療效評價等。近年來,基于深度學習的圖像配準方法證實了神經網絡的能力,取得了不錯的成果。文獻[1-3]提出的醫學圖像配準方法在訓練過程中需要大量人工精確標注的真實變形場,然而獲取精確標注的真實變形場是個難題,且配準的精度受人工標注的影響。文獻[4-7]提出的醫學圖像配準方法解決了真實變形場方面的難題,但文獻[4-5]的部分方法只支持小的變換,意味著在配準任務中可能丟失解剖結構的位置信息。此外,上述方法的精度有待提高。因此,提出了一種新的醫學圖像配準方法,可變形配準網絡為編解碼結構,在沒有任何標注的真實變形場預測整個位移向量場。所提方法在訓練過程中不需要真實變形場等標注信息,且為了提高配準精度,在標準編解碼結構上做了多尺度跳過連接、選擇核注意力機制和深度監督3 方面改進。在ADNI 腦數據集上對所提出方法進行評估,驗證了所提方法的準確性。
1 方 法
所提配準方法的整體架構如圖1 所示。使用可變形配準網絡MSD-Vnet 端到端預測整個位移向量場,其中固定圖像F 和移動圖像M 作為可變形配準網絡的輸入,MSD-Vnet 對函數gθ(F,M)=φ 進行建模。
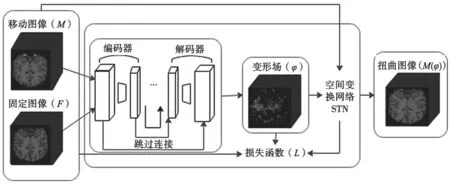
圖1 三維醫學圖像配準的整體架構
訓練過程中,通過空間變換網絡(Spatial Transformer Network,STN)將位移向量場φ 和移動圖像M 扭曲獲得扭曲圖像M(φ),通過最小化扭曲圖像M(φ)和固定圖像F 之間的相似性損失和位移向量場φ 的正則化損失來指導訓練找到最佳的參數θ,表示為:

式中,對于每個體素p ∈R3,φ(p)使F(p)和M(φ(p))定義相似的解剖位置。M(φ)為通過空間變換網絡(Spatial Transformer Network,STN)對移動圖像M 施加位移向量場φ 扭曲后的圖像,Lsim(·)度量扭曲圖像M(φ)和固定圖像F 之間的相似性,Lsmooth(·)表示對變形場φ施加正則化,λ是正則化參數。在配準過程中,給定一個圖像對M 和F 的情況下,可以通過一組最優化的參數θ 快速獲得位移向量場φ,從而得到扭曲圖像M(φ)。
1.1 可變形配準網絡MSD-Vnet
可變形配準網絡MSD-Vnet 遵循編解碼結構,如圖2 所示。在編碼器階段,使用步長為2 的卷積對圖像進行降采樣。降采樣操作執行3 次,使圖像的分辨率分別為之前的1/2、1/4 和1/8。3 層結構中,卷積層的數量分別為1、2、3,其中最后兩層結構中的卷積使用殘差單元。然后,使用具有3 個卷積層的殘差單元連接編解碼底端。在解碼器階段,使用上采樣恢復空間分辨率。與編碼器階段類似,上采樣和卷積操作重復3 次,3 層結構中卷積層的數量分別為3、2、1。特別地,MSD-Vnet 在編解碼結構之間引入多尺度跳過連接。在解碼器端對來自各個尺度的特征映射進行級聯,并將級聯得到的特征映射經過一個選擇核注意力機制網絡,從而充分利用醫學圖像的多尺度特性獲取更多與配準有關的信息。同時,MSD-Vnet 包含深度監督機制,可以使配準網絡更好地學習,最終輸出位移向量場,即一個具有3 個通道(x、y、z 位移)的三維特征圖。它的大小與輸入相同,均為160×192×224。
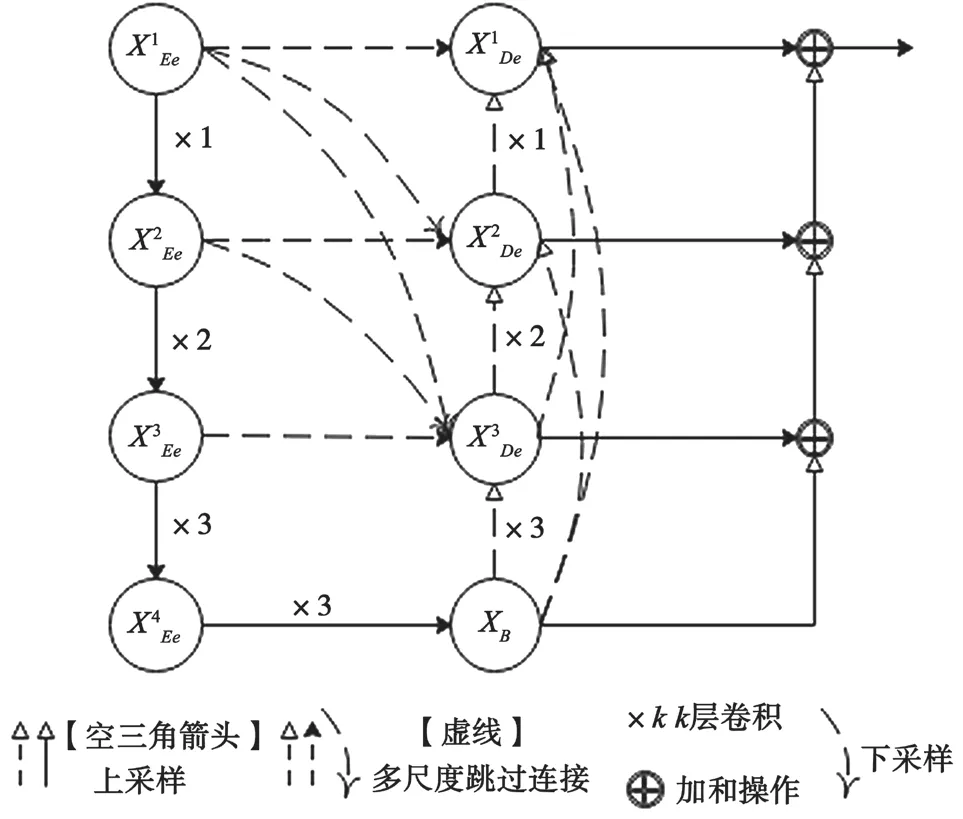
圖2 可變形配準網絡MSD-Vnet
1.1.1 多尺度跳過連接
基于編解碼結構的卷積神經網絡中,由跳過連接連接的特征映射之間存在差異。以可變形網絡最頂層的跳過連接為例,編碼器端的特征映射是原始圖像,而解碼器端的特征映射類似于最終的位移向量場。這兩組差異較大的特征映射進行級聯,會對預測過程產生不利的影響。基于此,MSD-Vnet 在編解碼器之間引入多尺度跳過連接,以使醫學圖像的解剖結構位置信息更加精確。
多尺度跳過連接使每一個解碼器層都結合了小尺度的特征映射、同尺度的特征映射以及大尺度的特征映射[8],過程如圖3 所示,展示了構造層的特征映射方法。
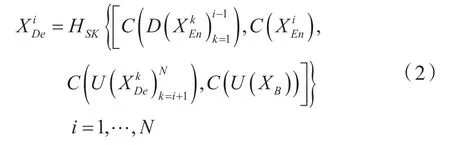
式中,i 是沿著編碼器下采樣層的索引,N 與下采樣的次數相同,C(·)表示卷積操作,D(·)和U(·)分別表示下采樣和上采樣操作,[·]表示級聯操作,HSK(·)表示選擇核注意力機制。
1.1.2 選擇核注意力機制SKNet
MSD-Vnet 的編碼器端使用選擇核注意力機制SKNet。這種非線性的多核信息聚合方法能夠根據輸入信息自適應地調整感受野的大小,獲取更多與配準有關的信息。選擇核注意力機制SKNet 由分離、融合及選擇3 部分組成。具體地,對于給定的特征映射X ∈RD×H×W×C,首先通過兩個卷積核大小不同的卷積進行兩個變換,分別為F1:X →U1∈RD×H×W×C和F2:X →U2∈RD×H×W×C。通過加和的方式融合兩個分支變換得到的結果,即:

通過一個全局平均池化嵌入全局信息,生成信道統計信息s ∈RC。式中,s 中的每個元素都是通過在空間維度D×H×W 對U 進行壓縮得到,第c個元素的計算公式為:
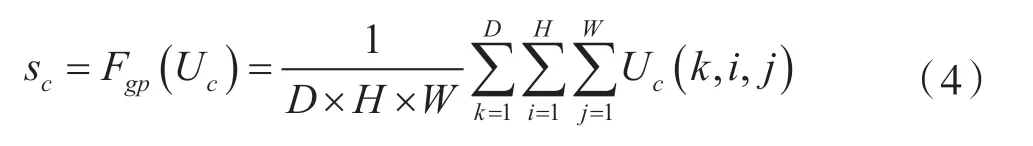
使用完全連接層將壓縮得到的特征變得更加緊湊z ∈Rd×1,其中d 是再次壓縮后的通道數。通過上述操作可達到提高效率的效果:

最后,使用softmax 函數,根據不同核上的注意力權重a和b 得到最后的特征映射Fclast,即:
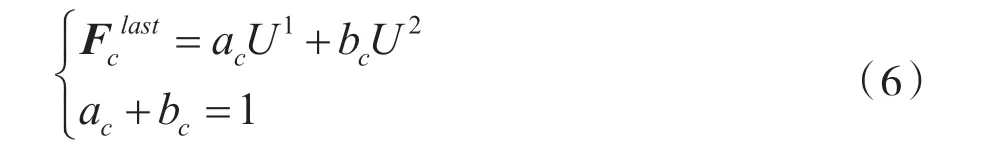
式中:
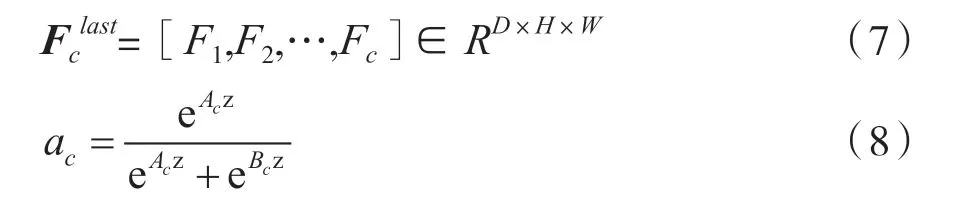
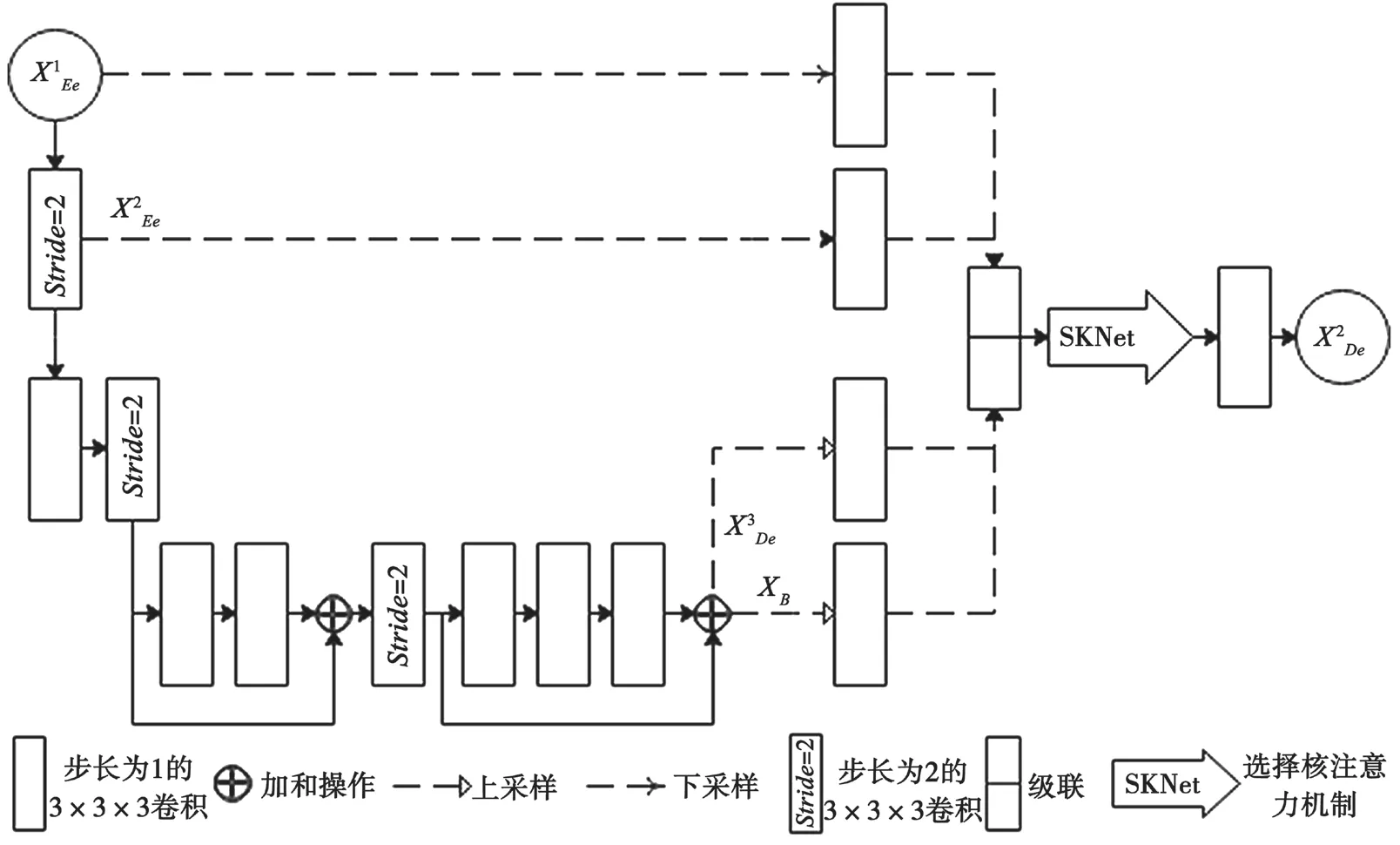
圖3 基于多尺度跳過連接的特征融合

式中,Ac,Bc∈Rc×d,Ac是A 的 第c 行,ac是a 的第c 個元素;Bc與bc同理。
1.1.3 深度監督
可變形配準網絡MSD-Vnet 在各個層添加了深度監督輔助分支,從MSD-Vnet 底部依次提取不同分辨率層次的階段性預測結果作為生成層的輸入。低層特征生成的階段性預測結果進行上采樣,并依次與高層特征生成的階段性預測結果進行融合,從而綜合多個分辨率下的階段性預測結果生成融合預測結果。
1.2 損失函數
損失函數由兩部分組成:一部分是扭曲圖像M(φ)與固定圖像F 之間的相似性度量Lsim,另一部分是施加于位移向量場φ 的正則化損失項Lsmooth。相似性度量懲罰外觀上的差異,正則化損失項懲罰位移向量場φ 的局部空間變化。
損失函數L 計算公式如下:

式中,λ 是正則化參數。
均方體素差MSE 作為相似性度量為:
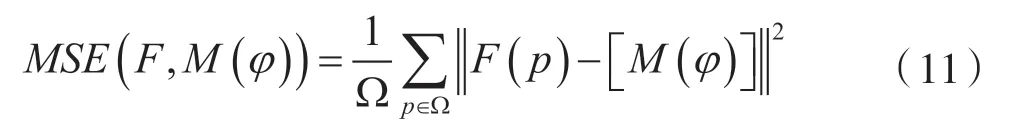
式中,Ω 表述輸入圖像的空間域,p 表示空間域內的體素。
在其空間梯度上使用擴散正則化器平滑φ,有:
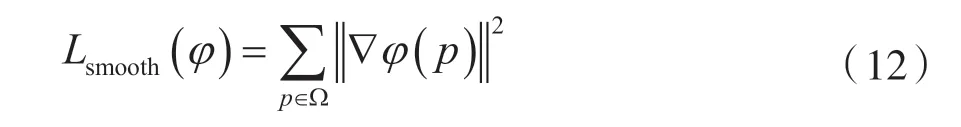
式中,Ω 表述輸入圖像的空間域,p 表示空間域內的體素,φ(p)是相鄰體素之間的差異。
2 實 驗
2.1 數據集
通過公共數據集ANDI[9]的腦MRI 數據評估提出的方法。首先,使用FreeSurfer[10]對大腦數據進行剝離和重采樣,將體素間距變為1 mm×1 mm×1 mm。其次,將圖像大小切割為160×192×224,并對數據進行歸一化。最后,用ANTs[11]進行仿射變換(Affine)。另外,采用數據增強的方法對圖像進行不同程度的扭曲,達到擴增數據的目的。
2.2 評估方法
在對配準后的圖像和固定圖像的解剖結構進行分割的基礎上,使用戴斯相似性系數(Dice Smilarity Cefficient,DSC)來評估網絡的性能。戴斯相似性系數(DSC)的計算公式為:
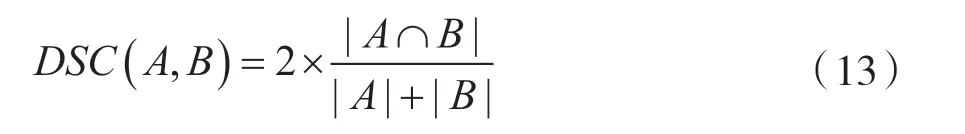
式中,A 和B 是某個解剖結構組成的一組體素。A 和B 重疊的區域越大,DSC 的數值越大。完全重疊的區域DSC=1。數值越接近1,說明配準的精度越高。
2.3 實 施
實驗在Ubuntu 16.04 操作系統下進行,使用Keras 和Tensorflow 后端實施,硬件設施為顯存16 GB 的NVIDIA Quadro RTX 5000 GPU,內存大小為128 GB。訓練過程中使用Adam 優化器,學習率為1e-4,批量大小為每訓練批一對。
3 結 果
為了驗證方法的有效性,將提出的方法與經典的傳統配準算法(包括基于ANTs[11]的Affine 和SyN[12])以及當下流行的基于深度學習的方法(包括3 層U-net[13]和體素變形[6])進行比較。這些方法在大腦數據集ADNI 中的一個示例上的可視化結果如圖4 所示。以二維切片的形式展示結果,僅用于可視化目的。
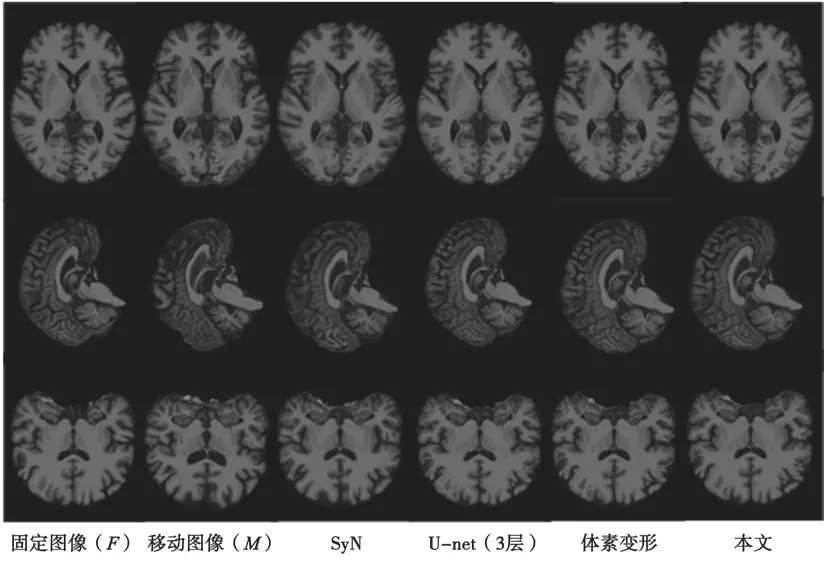
圖4 各種方法的可視化結果
基于ANTs[11]的Affine、SyN[12]、3 層U-net[13]、體素變形[6]以及提出的架構的平均戴斯相似性系數(DSC)如表1 所示。可以看出,與前幾種方法相比,提出的方法在精度方面達到了最先進的性能。
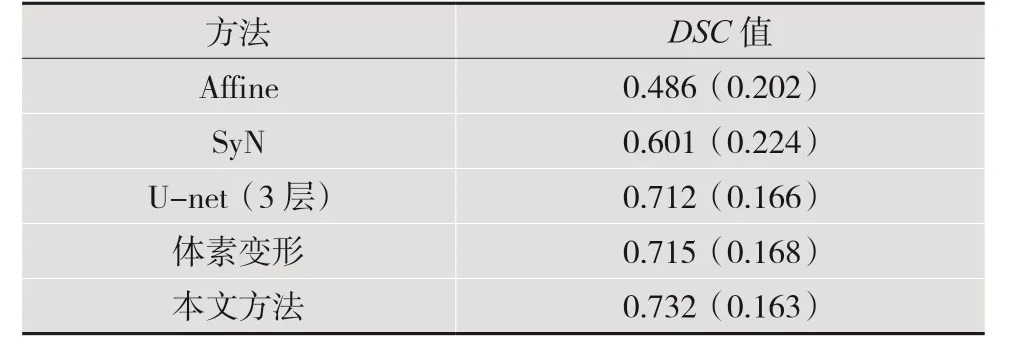
表1 平均戴斯相似性系數(DSC)
接下來進一步展示30 個解剖結構體積重疊的戴斯相似性系數。表2 列出了30 個解剖結構,并將所有解剖結構對應的平均戴斯相似性系數可視化為如圖5 所示的直方圖。由圖5 可以看出,在30個解剖結構中,提出的方法有27 個解剖結構的戴斯相似性系數(DSC)表現出最佳性能。

表2 30 個解剖結構索引表
4 結 語
三維醫學圖像配準具有重要的研究意義。針對編解碼結構的神經網絡模型在配準中的不足,提出一種新的卷積神經網絡MSD-Vnet 用于醫學圖像的端到端配準。與只支持小的三維圖像塊或者是二維切片的方法相比,該方法可以一次性預測整個位移向量場。該模型使用多尺度跳過連接來精確定位解剖結構的位置和邊界,使用選擇核注意力機制更好地學習醫學圖像的多尺度特性提高配準精度,同時使用深度監督對整個可變形配準網絡進行監督來防止過擬合。利用公共數據集ADNI 對提出的方法進行評估,評估指標為平均戴斯相似性系數,與Affine、SyN、U-net(三層)以及體素變形比較,分別獲得24.6%、13.1%、2%以及1.7%的精度提升。由于將圖像配準到同一模板圖像是大多數醫學圖像分析方法(如atlas 比對)的一個重要預處理部分,因此該模型的重點是將目標圖像配準到一個固定的模板圖像上。未來將致力于研究將目標圖像配準到不同模板圖像上。
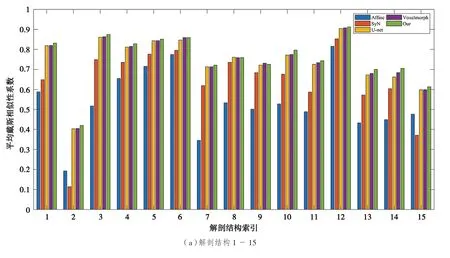
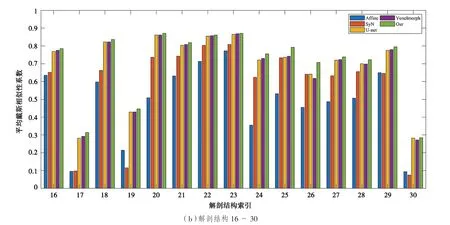
圖5 5 種方法解剖結構的平均DSC
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2020年1期)2020-09-21 09:24:52
中華詩詞(2019年7期)2019-11-25 01:43:04
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
