基于融合路徑監(jiān)督的多波段圖像語義分割
2021-04-10 05:50:26康萌萌谷小婧顧幸生
康萌萌, 楊 浩, 谷小婧, 顧幸生
(1. 華東理工大學(xué)化工過程先進(jìn)控制和優(yōu)化技術(shù)教育部重點(diǎn)實(shí)驗(yàn)室,上海 200237;2. 中國民航科學(xué)技術(shù)研究院,北京 100028)
城市場(chǎng)景的語義分割是實(shí)現(xiàn)自動(dòng)駕駛的關(guān)鍵技術(shù)[1],通過識(shí)別圖像中每個(gè)像素所屬的類別,使自動(dòng)駕駛車輛實(shí)現(xiàn)環(huán)境理解[2],進(jìn)而實(shí)現(xiàn)可靠判斷。近年來,隨著深度學(xué)習(xí)技術(shù)的發(fā)展,基于深度學(xué)習(xí)的語義分割方法也日新月異。Shelhamer 等[3]提出了第1 個(gè)端到端的語義分割模型(FCN),隨后,Handa 等[4]將FCN 擴(kuò)展成一個(gè)對(duì)稱的編碼-解碼結(jié)構(gòu)SegNet,通過解碼器逐步還原圖像的空間位置信息,避免直接上采樣導(dǎo)致分割細(xì)節(jié)不夠精細(xì)的問題。文獻(xiàn)[5]也采用類似的編碼-解碼網(wǎng)絡(luò)。此外,還有一些研究致力于提高圖像全局信息的利用率,如空洞卷積[6]、多尺度預(yù)測(cè)[7]、條件隨機(jī)場(chǎng)模型[8]等。
基于深度學(xué)習(xí)的語義分割技術(shù)主要圍繞可見光圖像展開,但是在夜間、大霧或強(qiáng)曝光等特殊的光照環(huán)境下,系統(tǒng)性能會(huì)顯著下降,導(dǎo)致無法正確分割物體,這也是影響自動(dòng)駕駛系統(tǒng)走向?qū)嶋H應(yīng)用的重要原因之一。紅外熱成像相機(jī)根據(jù)物體發(fā)射的熱輻射強(qiáng)度成像[9],具有不受光照環(huán)境影響的優(yōu)點(diǎn)。可見光-紅外(RGB-IR)多波段圖像由兩個(gè)傳感器相機(jī)同時(shí)捕獲并進(jìn)行配準(zhǔn)[10],其中,可見光圖像記錄的是場(chǎng)景的反射特性,光照良好時(shí)可以提供豐富的色彩特征和細(xì)膩的紋理特征,但光照不佳時(shí)圖像信息不足[11];長波紅外圖像記錄的是場(chǎng)景的熱輻射特性,雖然是單色圖像且缺乏細(xì)膩的紋理,但可在光照環(huán)境差的情況下提供人、車等熱目標(biāo)的顯著特征。因此,聯(lián)合使用RGB-IR 多波段圖像中的互補(bǔ)信息,可以提高自動(dòng)駕駛系統(tǒng)的魯棒性和準(zhǔn)確性,使得全天候復(fù)雜交通環(huán)境下的安全行駛成為可能。
目前,基于深度學(xué)習(xí)的多波段圖像語義分割方法主要采用編碼-解碼結(jié)構(gòu),根據(jù)特征融合方法不同可分為編碼端融合[12-13]、解碼端融合[14]和獨(dú)立模塊融合[15-16]三大類。Hazirbas 等[12]提出編碼端融合的FuseNet,采用VGG16 模型構(gòu)建兩個(gè)并行的編碼器和一個(gè)共用的解碼器,在編碼端將深度信息對(duì)應(yīng)地相加到可見光通道中,是最直接的編碼端融合結(jié)構(gòu)。Sun等[13]提出的RTFNet 網(wǎng)絡(luò)也采取編碼端融合結(jié)構(gòu),通過ResNet 殘差網(wǎng)絡(luò)進(jìn)行特征提取,并提出一種新的解碼器來恢復(fù)特征圖分辨率。Ha 等[14]構(gòu)建的MFNet輕量級(jí)網(wǎng)絡(luò)采用解碼端融合方法,將編碼端捕獲的多波段信息直接連接到解碼端構(gòu)成解碼端融合架構(gòu),以減少對(duì)特征提取的干擾。以上模型都采用特征直接相加或級(jí)聯(lián)的方式,而Lee 等[15]提出的RDFNet網(wǎng)絡(luò)結(jié)構(gòu)通過構(gòu)建MMF 融合模塊對(duì)多模態(tài)特征和多級(jí)特征進(jìn)行篩選融合,屬于獨(dú)立模塊融合結(jié)構(gòu)。類似的工作還有Valada 等[16]提出的AdaptNet 網(wǎng)絡(luò),通過多尺度特征融合塊MS 構(gòu)建獨(dú)立模塊融合結(jié)構(gòu)。
多波段圖像語義分割方法缺乏對(duì)融合特征的有效性判別,可能導(dǎo)致互補(bǔ)信息丟失或信息過度冗余。為了提高融合特征的鑒別性,本文對(duì)特征融合過程施加監(jiān)督信號(hào),提出了一種基于融合路徑監(jiān)督的多波段圖像語義分割方法(SFNet)。通過將特征融合模塊串聯(lián)形成特征融合支路,在融合支路末端施加監(jiān)督信號(hào),使融合特征更具有鑒別性。此外,構(gòu)建了Dice 損失和交叉熵?fù)p失的混合監(jiān)督訓(xùn)練模式,改善對(duì)于小目標(biāo)的分割效果。
1 基于融合路徑監(jiān)督的多波段圖像語義分割
1.1 多波段圖像語義分割整體框架
基于融合路徑監(jiān)督的多波段圖像語義分割網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示。基礎(chǔ)模型采用基于SegNet[4]的編碼器-解碼器架構(gòu),該架構(gòu)可以靈活地將多波段圖像的多級(jí)特征進(jìn)行融合,提高信息利用率。首先利用SegNet 模型構(gòu)建兩個(gè)并行的編碼器,分別對(duì)可見光圖像和紅外圖像進(jìn)行特征提取,在編碼末端得到兩個(gè)512×10×10 的高層語義特征圖,代表編碼輸出的10×10 特征圖共有512 個(gè);然后將提取到的多波段高層語義特征直接級(jí)聯(lián),通過一個(gè)共用的解碼器進(jìn)行解碼。
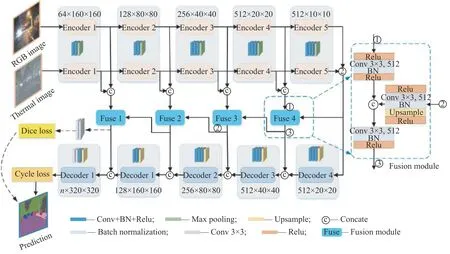
圖1基于融合路徑監(jiān)督的多波段圖像語義分割網(wǎng)絡(luò)結(jié)構(gòu)Fig.1Multi-spectral image semantic segmentation network with supervised feature fusion
本文模型包括4 個(gè)相似的特征融合模塊,將其互相串聯(lián)形成特征融合支路。特征融合模塊作為特征運(yùn)輸?shù)臉蛄海瑢⑷诤虾蟮母邔诱Z義特征(即上一個(gè)特征融合模塊的輸出)和當(dāng)前編碼端引出的中間特征再次進(jìn)行融合,并分別連接到對(duì)應(yīng)的解碼端,以幫助解碼器更好地恢復(fù)對(duì)象細(xì)節(jié)。在融合支路上設(shè)置Dice 損失函數(shù)對(duì)融合過程進(jìn)行監(jiān)督,聯(lián)合解碼支路的交叉熵?fù)p失函數(shù),利用二者之和作為網(wǎng)絡(luò)的最終損失進(jìn)行反向傳播,構(gòu)成混合監(jiān)督訓(xùn)練模式。
1.2 融合模塊及融合支路
首先構(gòu)建特征融合模塊,具體結(jié)構(gòu)如圖1 中Fusion module 所示。融合模塊有兩個(gè)輸入,一是從編碼端引出的多波段特征,將其級(jí)聯(lián)后送入融合模塊①端,通過3×3 卷積進(jìn)行融合預(yù)處理并將通道降為原來的1/2;二是來自高層的融合信息,利用模塊②端的3×3 卷積將其通道降為原來的1/2。將經(jīng)過預(yù)處理的兩組特征圖級(jí)聯(lián),通過3×3 卷積進(jìn)行后處理,并將通道降為原來的1/2 輸出到③端;輸出的融合信息連接到解碼端,促進(jìn)解碼分割,同時(shí)將其作為下一個(gè)融合模塊的輸入。通過以上從高層到低層特征的傳遞,將特征融合模塊串聯(lián)成融合支路,利用高層融合信息指導(dǎo)低層信息融合。本文構(gòu)建的特征融合模塊避免了互補(bǔ)信息丟失和信息過度冗余等問題,使融合信息在捷徑連接的過程中保持對(duì)齊,減少?zèng)_突。另外,為了防止過擬合,在特征融合模塊輸入端①、②添加Relu 激活函數(shù)來減少網(wǎng)絡(luò)的稀疏性。
1.3 融合路徑監(jiān)督
為了使融合特征更具有鑒別性,在獨(dú)立的融合支路末端直接添加損失函數(shù)構(gòu)成融合監(jiān)督信號(hào),利用監(jiān)督信號(hào)促進(jìn)特征融合過程。類似的工作有Lee 等[17]提出的深度監(jiān)督網(wǎng)絡(luò),該工作指出利用監(jiān)督學(xué)習(xí)可以讓中間隱藏層的學(xué)習(xí)過程更加直接和透明,減少分類的錯(cuò)誤,從而使學(xué)習(xí)到的特征更加魯棒和易區(qū)分。本文方法與深度監(jiān)督網(wǎng)絡(luò)工作的不同之處在于,深度監(jiān)督復(fù)用了同一條網(wǎng)絡(luò)支路,而本文基于融合模塊構(gòu)建了一條獨(dú)立的新支路,并對(duì)其施加不同的監(jiān)督信號(hào)。
首先,使用圖像分割中常用的交叉熵?fù)p失函數(shù)對(duì)融合支路進(jìn)行監(jiān)督,其具有求導(dǎo)方便、易于訓(xùn)練的優(yōu)點(diǎn),交叉熵?fù)p失函數(shù)( Lcross)如式(1)所示。交叉熵?fù)p失函數(shù)對(duì)每個(gè)類別具有相同的關(guān)注度,易受類別不平衡因素的影響,因此為了提升對(duì)小目標(biāo)的分割精度,使用Dice 損失函數(shù) (LDice)[18]對(duì)融合支路進(jìn)行監(jiān)督。Dice損失函數(shù)最初用于醫(yī)學(xué)圖像分割,它以交并比最大為優(yōu)化目標(biāo),可以從較大的背景區(qū)域中將前景目標(biāo)分離出來,防止預(yù)測(cè)結(jié)果偏向于背景,具有較強(qiáng)的檢測(cè)小目標(biāo)區(qū)域的能力,Dice 損失函數(shù)如式(2)所示。本文在解碼支路使用交叉熵作為損失函數(shù),在融合支路使用Dice 損失函數(shù)作為監(jiān)督信號(hào)。最后,使用Dice 損失函數(shù)和交叉熵?fù)p失函數(shù)之和作為網(wǎng)絡(luò)的最終損失函數(shù)進(jìn)行反向傳播,構(gòu)建混合監(jiān)督訓(xùn)練模式,最終的損失函數(shù)( Ltotal)見式(3)。
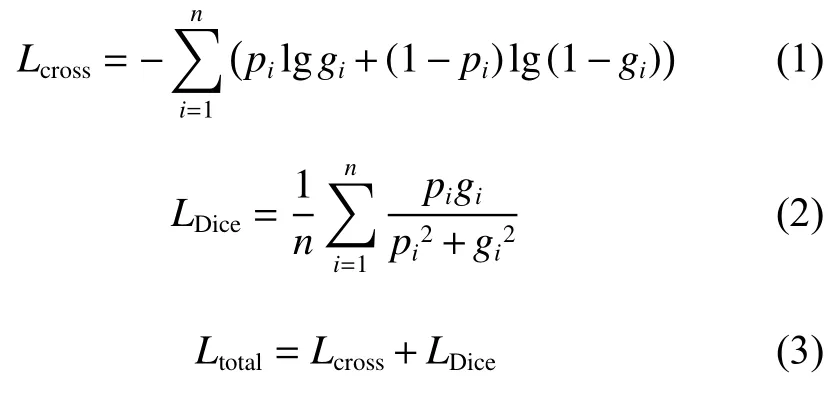
其中:n 為數(shù)據(jù)集中分割類別的個(gè)數(shù); pi和 gi分別為預(yù)測(cè)分割值和標(biāo)簽值。
2 實(shí)驗(yàn)與分析
2.1 實(shí)驗(yàn)環(huán)境與參數(shù)設(shè)置
計(jì)算機(jī)硬件配置為Intel Core i7-7700k CPU,GeForce GTX 2080Ti GPU,操作系統(tǒng)為Ubuntu 16.04 LTS,計(jì)算框架為Python 3.6.6,Cuda 9.0,Cudnn 7.2 以及Torch 0.4.1。網(wǎng)絡(luò)訓(xùn)練過程中將圖片分辨率統(tǒng)一設(shè)置為320×320,參數(shù)學(xué)習(xí)采用帶動(dòng)量的小批量隨機(jī)梯度下降方法,為解決訓(xùn)練期間出現(xiàn)的輕微過擬合問題,在卷積層之后添加L2正則化。訓(xùn)練批次大小為4,最大迭代次數(shù)Tmax=400,初始學(xué)習(xí)率η0=0.01。訓(xùn)練過程中學(xué)習(xí)率 ηT隨迭代次數(shù)T 使用poly 策略衰減至0,其表達(dá)式為
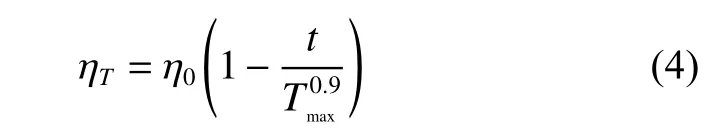
2.2 數(shù)據(jù)集及評(píng)價(jià)指標(biāo)
2.2.1 數(shù)據(jù)集 對(duì)比實(shí)驗(yàn)在兩個(gè)多波段語義分割數(shù)據(jù)集上展開。數(shù)據(jù)集1 是課題組自行構(gòu)建的夜間道路場(chǎng)景圖像語義分割數(shù)據(jù)集,共有541 組配準(zhǔn)的RGB-IR 圖像及語義標(biāo)簽圖,圖片分辨率為400×300。語義標(biāo)簽設(shè)定為:汽車、自行車、行人、天空、樹木、交通燈、道路、人行道、建筑、欄桿、路標(biāo)、桿子、巴士共計(jì)13 類物體,外加空類,代表13 種物體之外的場(chǎng)景,本文模型的訓(xùn)練與評(píng)估過程不包括空類。數(shù)據(jù)集2 是Ha 等[14]針對(duì)自動(dòng)駕駛問題構(gòu)建的城市場(chǎng)景RGB-IR 圖像語義分割數(shù)據(jù)集,共包含1569張分割圖像(其中820 張圖片來自白天,另外749 張圖片來自夜晚),圖片分辨率為480×640。語義標(biāo)注中提供了在交通環(huán)境中常見的8 種障礙物及背景標(biāo)簽,本文在數(shù)據(jù)集2 上的實(shí)驗(yàn)不計(jì)算背景標(biāo)簽。
2.2.2 評(píng)價(jià)指標(biāo) 在算法評(píng)估中,采用每個(gè)類別的分割準(zhǔn)確率(Acc)、聯(lián)合交叉概率(IoU)、Acc 和IoU 在所有類別上的平均分割準(zhǔn)確率(mAcc)及平均聯(lián)合交叉概率(mIoU)指標(biāo)對(duì)語義分割性能進(jìn)行定量分析,公式如下:
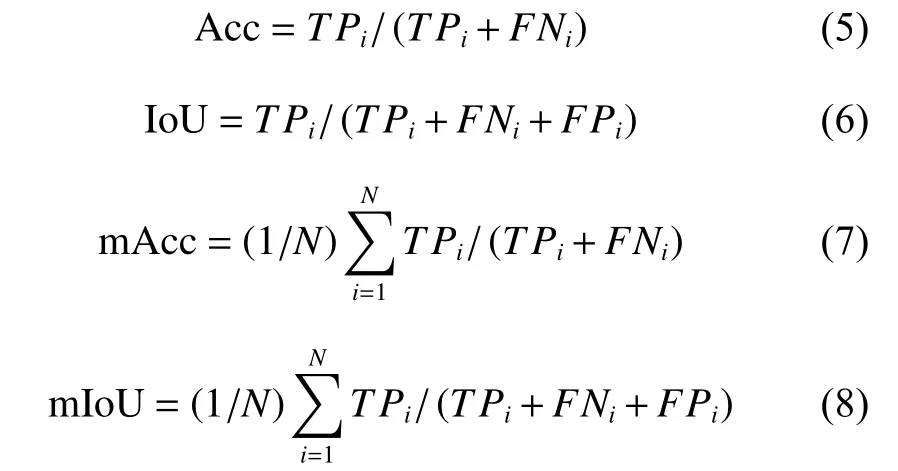
2.3 實(shí)驗(yàn)結(jié)果與分析
2.3.1 消融實(shí)驗(yàn) 消融實(shí)驗(yàn)主要分為三部分。首先,為了驗(yàn)證融合支路可以讓高層融合指導(dǎo)低層融合,使信息的利用率更高,從而改善分割效果,本文設(shè)計(jì)了基于獨(dú)立模塊融合方法與融合支路方法的對(duì)比實(shí)驗(yàn)。獨(dú)立模塊融合方法是指在圖1 中多波段圖像語義分割架構(gòu)的基礎(chǔ)上,利用兩個(gè)3×3 卷積代替圖1 中的Fusion module,通過它對(duì)級(jí)聯(lián)后的多波段特征進(jìn)行融合,并將其連接到解碼端,結(jié)構(gòu)如圖2(a)所示。融合支路方法是指在本文模型基礎(chǔ)上去掉融合支路末端的監(jiān)督信號(hào),結(jié)構(gòu)如圖2(b)所示。兩種方法分別在兩個(gè)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),對(duì)比結(jié)果如表1 所示。從表1 可以看出,利用特征融合支路可以將分割結(jié)果mIoU 值提升1.0~2.0,說明融合支路與獨(dú)立融合模塊相比可以利用更多的融合信息,提高語義分割效果。
在融合支路末端直接施加監(jiān)督信號(hào),構(gòu)成基于融合路徑監(jiān)督的分割模型,根據(jù)監(jiān)督信號(hào)的不同,分別將交叉熵?fù)p失監(jiān)督和Dice 損失監(jiān)督的模型稱為SFNet*和SFNet,簡化結(jié)構(gòu)如圖2(c)所示。在融合支路末端添加與分割支路相同的交叉熵?fù)p失監(jiān)督信號(hào)時(shí),實(shí)驗(yàn)結(jié)果見表1 中的SFNet*。對(duì)比表1 的實(shí)驗(yàn)結(jié)果可知,在融合支路末端添加交叉熵?fù)p失時(shí),在兩個(gè)數(shù)據(jù)集上的mIoU 值和mAcc 值與融合支路方法相比都有所提高,說明對(duì)融合路徑設(shè)置交叉熵信號(hào)監(jiān)督能提高融合特征的鑒別性,進(jìn)而改善分割效果。
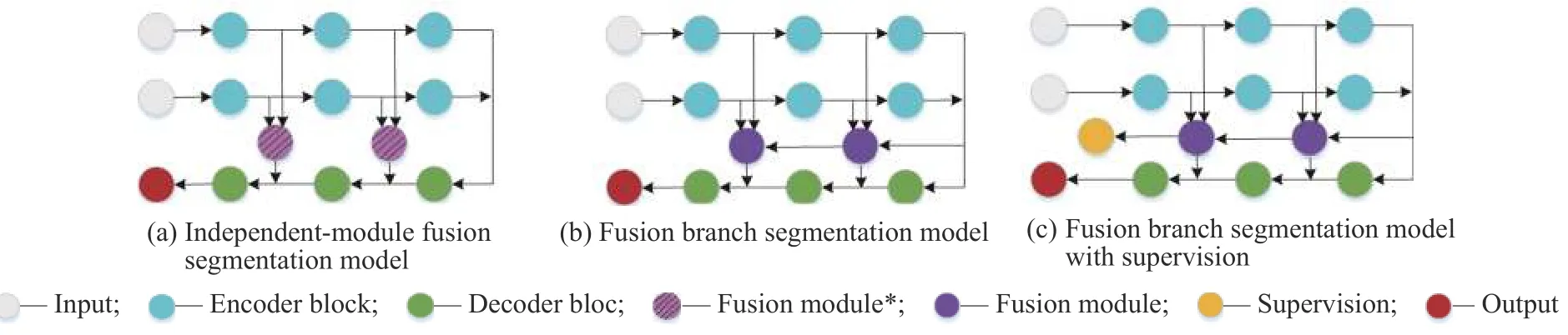
圖2消融實(shí)驗(yàn)?zāi)P虵ig.2Ablation experimental model
將融合支路末端的交叉熵?fù)p失替換成Dice 損失,與解碼分割支路上的交叉熵?fù)p失構(gòu)成混合監(jiān)督訓(xùn)練模式,實(shí)驗(yàn)結(jié)果見表1 中的SFNet。對(duì)比SFNet*與SFNet 的分割結(jié)果可以看到,Dice 損失監(jiān)督模型的mAcc 沒有明顯提高,而mIoU 值提升1 左右,這恰好體現(xiàn)了Dice 損失函數(shù)的特點(diǎn),以交并比最大化為目標(biāo)進(jìn)行參數(shù)更新,提升小目標(biāo)的分割效果。圖3示出了在特征融合支路上分別添加Dice 損失和交叉熵?fù)p失的分割結(jié)果對(duì)比,從圖3中紅色圓圈標(biāo)注的地方可以看出,在特征融合支路上添加Dice 損失監(jiān)督信號(hào)時(shí),模型對(duì)路標(biāo)、桿子等細(xì)小物體的分割效果將更優(yōu)。
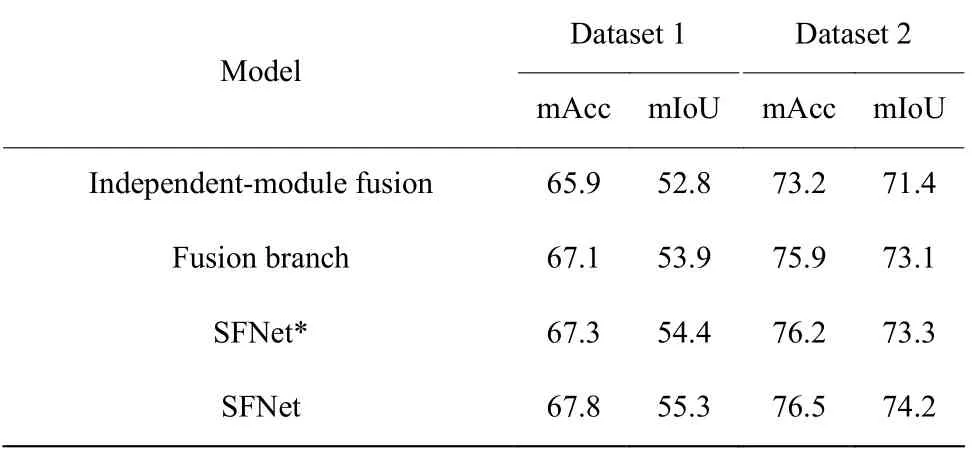
表1在數(shù)據(jù)集1 和數(shù)據(jù)集2 上的消融實(shí)驗(yàn)結(jié)果Table1Ablation experimental results on dataset1and dataset 2
圖4 分別示出了表1 中4 組對(duì)比模型在數(shù)據(jù)集1 的訓(xùn)練過程中,驗(yàn)證集的損失函數(shù)變化和mIoU 變化情況。觀察圖4(a)中損失函數(shù)變化曲線發(fā)現(xiàn),在融合支路上加入損失函數(shù)進(jìn)行融合監(jiān)督之后,SFNet*和SFNet 損失曲線下降較快,說明設(shè)置融合監(jiān)督信號(hào)后加快了收斂速度,減少了訓(xùn)練時(shí)間。圖4(b)中mIoU值的變化曲線顯示,加入Dice 損失的混合監(jiān)督信號(hào)方法與其他方法相比具有較好的分割效果。綜上,基于融合路徑監(jiān)督的方法加快了模型收斂速度,同時(shí)能提升融合特征鑒別性,進(jìn)而改善分割結(jié)果。
2.3.2 算法對(duì)比及分析 本文選取了目前較為成功的幾種分割網(wǎng)絡(luò)作為對(duì)比算法,其中包括FCN[3]、SegNet[4]和UNet[13]等經(jīng)典的單模態(tài)圖像語義分割方法,以及FuseNet[12]、MFNet[14]、RTFNet[13]和RDFNet[15]等多波段圖像語義分割方法,分別在數(shù)據(jù)集1、2 上進(jìn)行實(shí)驗(yàn)。表2 和表3 分別示出了對(duì)比算法在數(shù)據(jù)集1 和數(shù)據(jù)集2 上的分割結(jié)果,表中黑體字表示分割最優(yōu)值。結(jié)果驗(yàn)證了本文提出的基于融合路徑監(jiān)督的多波段圖像語義分割模型具有較好的分割效果。
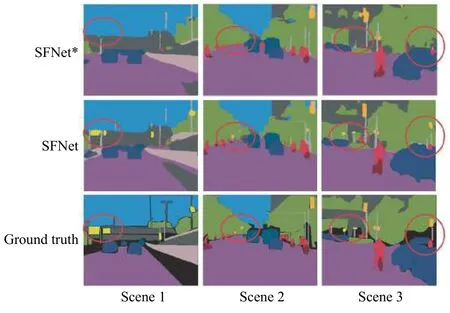
圖3不同監(jiān)督信號(hào)對(duì)比結(jié)果Fig.3Comparison results of different supervision signals
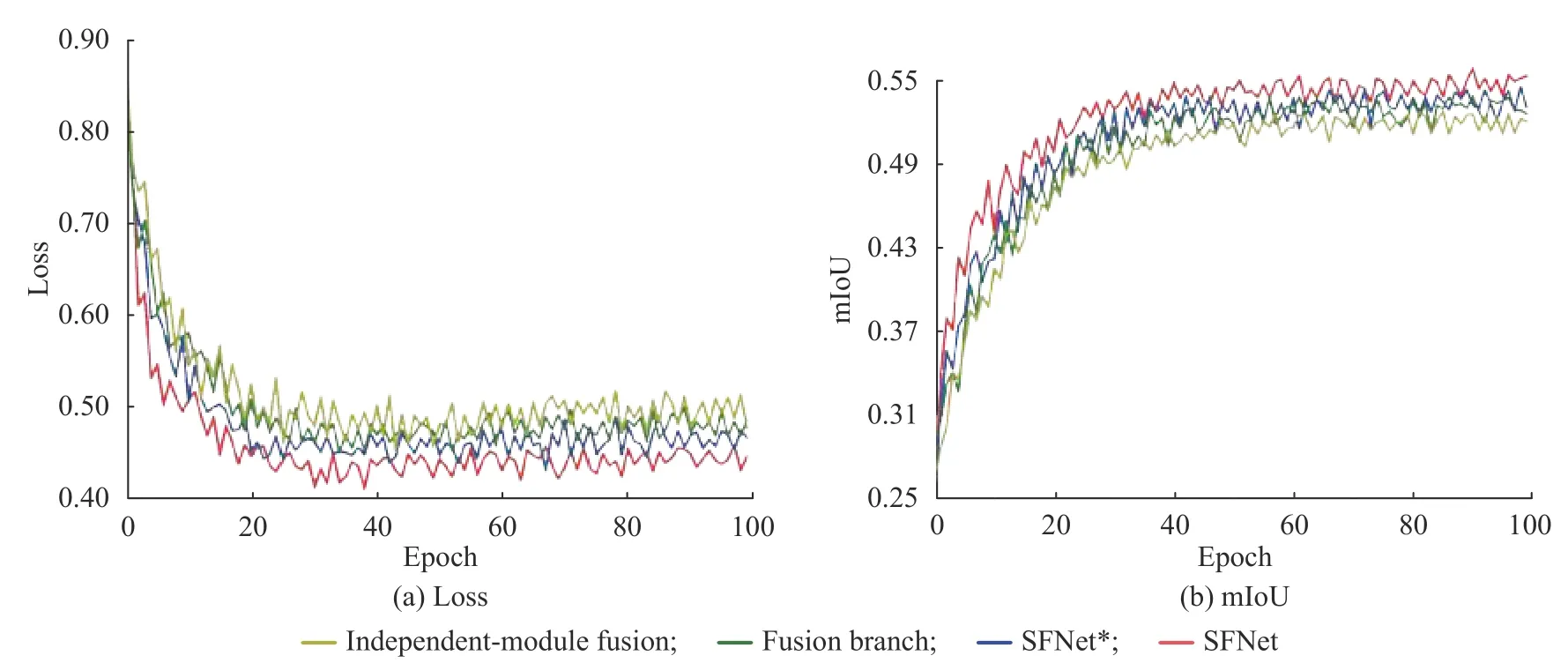
圖4驗(yàn)證集上的損失函數(shù)和mIoU 變化曲線Fig.4Loss and mIoU curves on the validation set
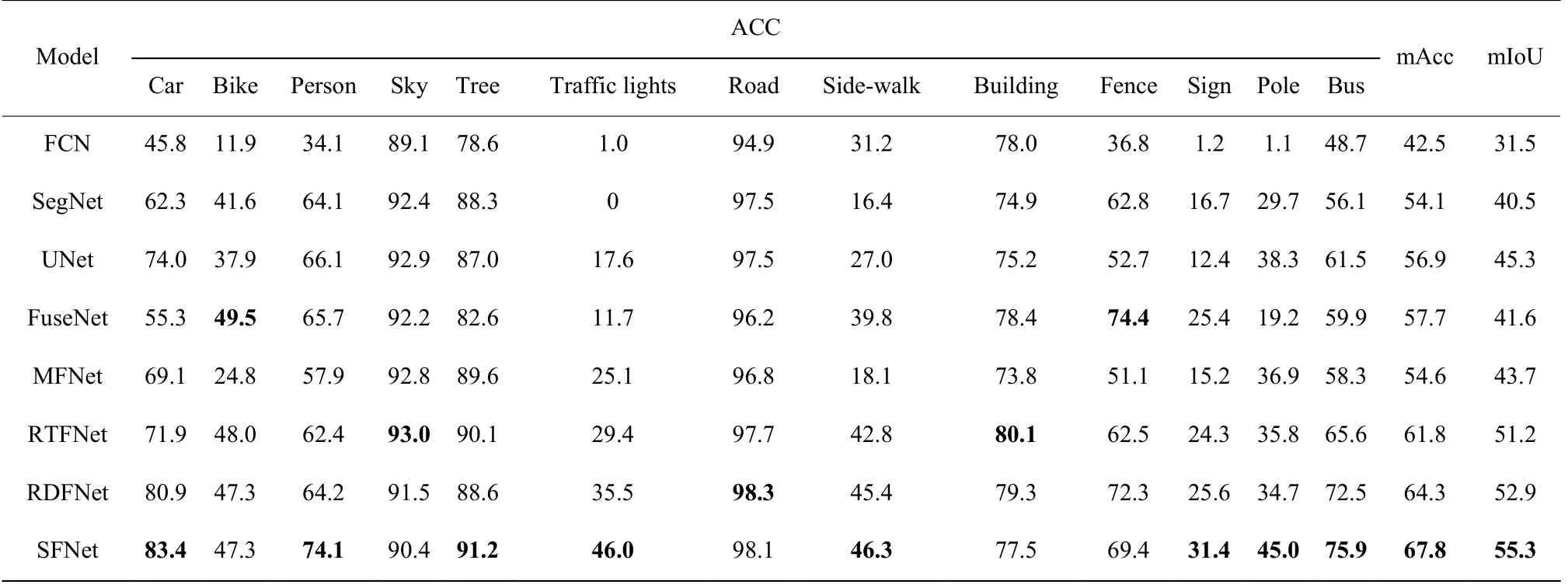
表2不同分割方法在數(shù)據(jù)集1 上的分割結(jié)果Table2Segmentation results of different segmentation methods on dataset 1
表2 中只顯示了每個(gè)類別(不含空類)的Acc、mAcc 和mIoU。從比較結(jié)果來看,在當(dāng)前主流算法中,以獨(dú)立模塊融合方法為代表的RDFNet 模型表現(xiàn)較好,分割結(jié)果mIoU 值為52.9,本文的SFNet 方法與RDFNet 相比,mIoU 提高了2.4。從整體對(duì)比結(jié)果來看,本文方法不論在mAcc 還是mIoU 評(píng)價(jià)指標(biāo)上都優(yōu)于其他算法,在大多數(shù)類別的像素準(zhǔn)確率上與其他方法相比也有較好的分割效果,特別是對(duì)交通燈、標(biāo)志牌、桿子等小目標(biāo)的分割像素準(zhǔn)確率有較明顯的提高,驗(yàn)證了在融合支路末端添加Dice 損失監(jiān)督信號(hào)對(duì)小目標(biāo)分割的有效性。
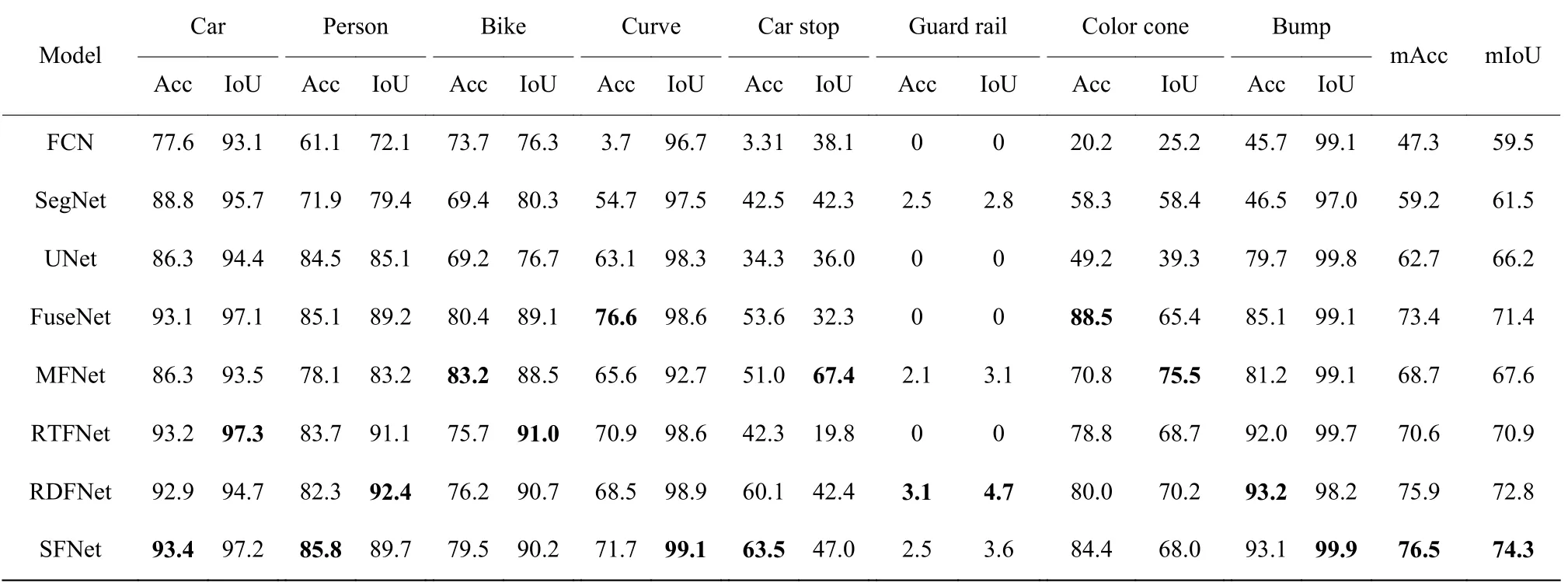
表3不同分割方法在數(shù)據(jù)集2 上的分割結(jié)果Table3Segmentation results of different segmentation methods on dataset 2
表3 數(shù)據(jù)集中含有大量的背景類像素,這對(duì)小目標(biāo)對(duì)象的分割造成了很大的挑戰(zhàn),因此,為了消除背景類像素對(duì)整體分割效果的影響,在數(shù)據(jù)集2 上的實(shí)驗(yàn)過程中不計(jì)算背景類像素。盡管如此,在數(shù)據(jù)集2 上進(jìn)行語義分割實(shí)驗(yàn)時(shí),依然出現(xiàn)某些分割方法對(duì)護(hù)欄類別分割結(jié)果為0 的情況,這是由于該類別在數(shù)據(jù)集2 中所占比重較小(約占0.1%),因此沒有被檢測(cè)到。從表3 的分割結(jié)果來看,采用本文方法得到的mIoU 與mAcc 值明顯高于其他模型。
從表2 和表3 的分割結(jié)果可以看出,本文的SFNet模型在兩個(gè)數(shù)據(jù)集上的mAcc 和mIoU 值均達(dá)到最高,體現(xiàn)了本文方法在不同的語義分割數(shù)據(jù)集上都具有良好的表現(xiàn),魯棒性較好。圖5 示出了不同方法在兩個(gè)數(shù)據(jù)集上的語義分割結(jié)果。

圖5語義分割結(jié)果Fig.5Results of semantic segmentation
此外,對(duì)于自動(dòng)駕駛技術(shù)來說,圖像分割的實(shí)時(shí)性也是決定其能否走向?qū)嶋H應(yīng)用的一個(gè)重要因素。因此,為了評(píng)價(jià)模型的實(shí)時(shí)分割效果,利用NVIDIA GeForce GTX2080Ti 顯卡對(duì)上述語義分割網(wǎng)絡(luò)的推理速度進(jìn)行測(cè)量。在數(shù)據(jù)集1 上輸入圖片分辨率為320×320 的情況下,對(duì)比不同融合方法對(duì)同一張圖片進(jìn)行分割所需的平均時(shí)間成本t 和速度(FPS),其中FPS 表示每秒可以分割多少張圖像,分割性能和效果對(duì)比如表4 所示。
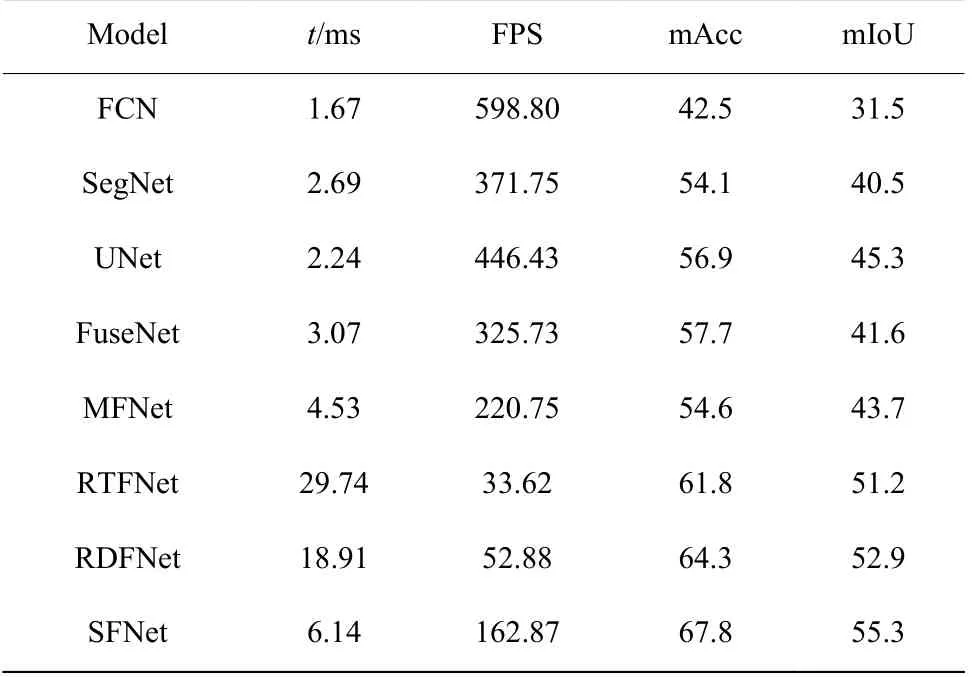
表4不同模型推理速度和性能對(duì)比Table4Comparison of inference speed and performance for different models
RTFNet 與RDFNet 都由卷積層數(shù)更深的ResNet基礎(chǔ)網(wǎng)絡(luò)構(gòu)成,從表4 中可以看到,與其他基于VGG網(wǎng)絡(luò)的方法相比,RTFNet 和RDFNet 可以提取更多的圖像特征,因此其分割效果優(yōu)于其他主流算法,但是使用更深的模型在一定程度上增加了網(wǎng)絡(luò)運(yùn)算量和模型參數(shù),因此其分割速度均較差。本文模型使用VGG16 基礎(chǔ)網(wǎng)絡(luò)搭建,模型參數(shù)較少,訓(xùn)練速度快;同時(shí),本文模型構(gòu)建融合路徑監(jiān)督策略,使融合特征更具有鑒別性,從而提升分割結(jié)果。從對(duì)比結(jié)果來看,采用本文方法得到的mIoU 值比RDFNet 方法高2.4,分割速度約為RDFNet 方法的3 倍。綜上,本文提出的基于融合路徑監(jiān)督的多波段圖像語義分割方法不僅具有優(yōu)良的分割結(jié)果,同時(shí)具有可靠的推理速度。
3 結(jié)束語
為了增強(qiáng)多波段圖像融合特征的鑒別性,提高語義分割效果,本文提出一種基于融合路徑監(jiān)督的多波段圖像語義分割方法。首先,利用獨(dú)立融合模塊將高層特征與低層特征串聯(lián)形成融合支路,提高信息利用率;其次,對(duì)獨(dú)立融合支路施加監(jiān)督信號(hào),不僅使融合特征更具有鑒別性,而且加快模型收斂速度,提高訓(xùn)練效率;最后,對(duì)融合支路施加Dice 損失監(jiān)督信號(hào),與分割主支路的交叉熵?fù)p失構(gòu)成混合監(jiān)督訓(xùn)練模式,改善對(duì)于小目標(biāo)的分割結(jié)果。在不同數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果顯示,本文方法與同類算法相比,具有更好的分割效果和分割性能。
猜你喜歡
人大建設(shè)(2020年4期)2020-09-21 03:39:12
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
浙江人大(2014年4期)2014-03-20 16:20:16
