礦區土地復墾歷史文獻數據挖掘方法及應用研究
2021-04-17 09:54:44胡鈺琳張紹良于婭娜侯湖平楊永均公云龍
中國礦業 2021年4期
胡鈺琳,張紹良,2,于婭娜,侯湖平,楊永均,公云龍
(1.中國礦業大學公共管理學院,江蘇 徐州 221116;2.礦山生態修復教育部工程研究中心,江蘇 徐州 221116)
0 引 言
自20世紀80年代大規模開展礦區土地復墾研究以來,我國很多礦區已經積累了大量的復墾數據資料,包括復墾技術、復墾經驗、復墾質量、復墾評價和示范工程等信息。這些歷史文獻不僅可以為礦區未來土地復墾提供直接的、廉價的資料,而且可形成“歷史數據鏈”,為礦區綜合治理、系統修復提供決策支持。尤其是其中“反復”的研究區介紹、采樣、試驗和分析結果等,如果系統歸納、提煉,也就是數據挖掘,可形成該礦區土地復墾和生態修復的“知識”。因此,引入數據挖掘技術不但可節省研究時間,而且可節約研究成本,避免“重復”研究,為大數據時代礦山土地復墾和生態重建的研究提供新的研究“范式”。本文嘗試利用數據挖掘技術,結合Python語言編程,對礦區土地復墾歷史科技文獻開展信息集成和知識發現,并以徐州礦區為例開展實證研究,為礦區土地復墾與生態修復研究探索一條新的途徑。
1 礦區復墾信息數據挖掘概述
1.1 研究現狀
數據集成、分析、預測、建模和數據挖掘、可視化等是大數據時代的基本技術[1],國內外許多專家已經研發出了許多與數據挖掘有關的軟件,取得了長足的進步[2],并應用于經濟領域[3]、社會領域[4]和文化領域[5]等。礦區信息數據挖掘已經能實現地質數據特征的表述、對比、聯系、聚類以及分析等功能,并且已經有數據挖掘的軟件問世[6]。為了從海量的地質信息中找到有效的信息,有學者開發了語義檢索模型[7]。然而,數據冗余、數據沖突及其真偽識別等,給礦區土地復墾與生態重建信息集成和知識發現提出了挑戰。
1.2 數據特點
數據挖掘就是在大量的、不完全的、有噪聲的、模糊的隨機數據中,提取隱含在其中的、人們事先不知道的潛在有用信息和知識的過程[8]。礦區土地復墾文獻資料是研究人員日積月累形成的重要知識成果,但由于主題不同、內容不同、格式不同等特點,使得信息分散,制約了信息集成的難度和應用價值。
由表1可知,區別于傳統數據環境,礦區土地復墾文獻資料的數據特點在數據類型、數據篩選、數據挖掘等方面都有極大的不同。由此可見,必須開發有針對性的數據挖掘方法,才能對礦區土地復墾文獻進行精準挖掘,才能在大量的歷史文獻資料中準確快速地識別出礦區基本信息、開采及其影響信息、復墾信息等。
2 礦區復墾信息數據挖掘方法
2.1 數據挖掘步驟
1) 首先根據《現代漢語分類詞典》中的分類規則對礦區土地復墾文獻關鍵詞進行編碼化處理。
2) 利用標簽LDA模型改進TF*IDF方法[9],構建關鍵詞-文獻矩陣。
3) 以CD_Sim方法訪問矩陣計算關鍵詞相似度,建立空間向量模型、應用AP聚類方法確定該礦區土地復墾文獻的主題要素。
4) 運用Python可視化編程語言遍歷文獻,根據聚類結果和其他需要提取的重要信息,進行數據挖掘與集成分析[10-11]。
5) 以文本數據庫作為核心結合空間與屬性數據庫,采用C#可視化編程語言,結合ArcEngine在VS.NET環境中實現GIS的二次開發,建立能夠呈現該礦區土地復墾歷史數據的信息管理系統。
2.2 關鍵技術
2.2.1 TF*IDF算法
首先將文獻關鍵詞按《現代漢語分類詞典》中5個級別層次進行體系分類。由表2可知,以“采礦”和“采煤”的編碼“陸三Hb01”為例,兩個詞語編碼位均相同,可認為兩詞語完全相似,相似度為1;若兩個詞語的編碼位有一位不同,則兩詞語相似度為0。

表1 數據特點Table 1 Characteristics of data

表2 編碼規則示例Table 2 Code rule example
其次,利用TF*IDF算法計算詞語重要性,計算見式(1)。
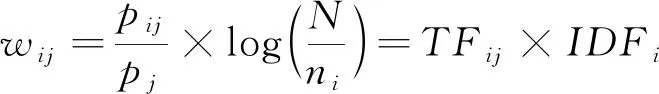
(1)
式中:pij為關鍵詞在待分析文檔中出現的數量;TFij為pij與待分析文檔中總詞語數量pj的比值;IDFi為逆文檔頻率;N為樣本數量;ni為文檔中包含詞語ti的數量。
根據詞語重要性wij構建關鍵詞-文獻權重矩陣,在待分析文檔中關鍵詞出現的頻率利用樣本D將頻數向量表示出來,則樣本D表示為式(2)。

(2)
2.2.2 CD_Sim方法
采用CD_Sim方法計算關鍵詞相似度,其思想為訪問關鍵詞-文獻矩陣,找到待度量關鍵詞返回其編碼,根據公式對編碼相似度進行計算,返回關鍵詞相似度。
定義:假設有關鍵詞A的編碼為“a1a2a3a4a5”,關鍵詞B的編碼為“b1b2b3b4b5”,語義重合度為k1。見式(3)。
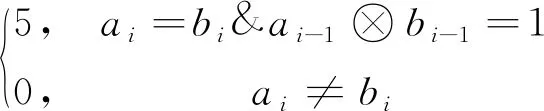
(3)
選取相同的語義長度(即編碼后的位數相同),從而方便計算語義重合度。以關鍵詞“生態”“環境”“景觀”為例,對其進行編碼后計算每兩個詞語之間k1的值,見表3。
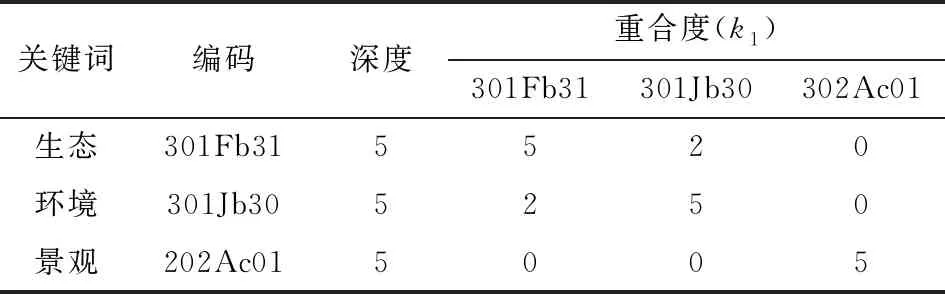
表3 k1計算結果Table 3 Calculated results of k1
分析表3可知,通過語義重合度利用CD_Sim方法對詞語之間的相似程度進行一個標準化的衡量計算,見式(4)。
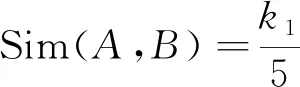
(4)
設文獻i中有M個關鍵詞{x1,x2,…,xm}(m=1,2,…,M),文獻j中有N個關鍵詞{y1,y2,…,yn}(n=1,2,…,N),smn為第i個文獻中的關鍵詞m與第j個文獻中的關鍵詞n的相似度。計算文獻i與文獻j中所有關鍵詞的相似度矩陣,見式(5)。
2.2.3 AP聚類方法
采用聚類分析不僅可以確定文獻主題要素,同時檢驗文本相似度量效果。相比較其他聚類方法,AP聚類可以按照自身特性,選取合理聚類數目進行聚類。根據關鍵詞相似度計算結果,通過AP聚類算法對待聚類文獻進行自動聚類,由于不同文獻主題包含子主題,根據聚類數目和實際文獻數目決定是否繼續執行聚類操作,直至聚類數目基本不再變化或者接近于1。
2.2.4 基于Python語言的信息提取
Python語言可以對ArcGIS進行腳本的編寫,可快速實現GIS基本功能的編碼化[10-11],嵌入Python語言將提高土地復墾歷史文獻數據挖掘的工作效率。選取Python語言中的PDFMiner模塊[12-13]進行解析處理,通過Python語言進行編程,即可在Excel中提取到對應的信息。
2.2.5 ArcGIS二次開發
該系統包括應用層、中間層以及數據層等三層結構。使用COM連接三層結構,這樣具有面向對象、可重用性、語言獨立、過程透明和版本升級穩健等優點[14]。中間層包括系統的主要功能模塊,數據層中包括地理空間數據、屬性數據以及文本數據。該系統減少了系統設計與實現之間的相互作用,降低了各層之間依賴程度的同時,也提高了本文系統的可擴展性,使得功能更加連貫,數據可以實時更新。
3 應用研究:以徐州礦區為例
3.1 數據挖掘過程
以中國知網(CNKI)文獻庫為基礎,以“土地復墾”“生態修復”“徐州礦區”“塌陷地”“植被恢復”“土壤改良”等作為文獻索引主題詞,將時間區間設置為1980—2019年,檢索到研究文獻518篇。下載文獻并利用Python爬取其關鍵內容,如“題目”“發表時間”“關鍵詞”“摘要”等,形成獨立文檔,以便計算機自動讀取。
利用TF*IDF算法計算詞語重要性,構建徐州礦區土地復墾與生態修復歷史文獻的樣本矩陣,文獻主題從初值開始不斷分詞,不斷聚類,不斷更新,不斷替換。
以隨機選取的四篇文獻為例。對分詞結果進行編碼化處理,處理結果見表4。據此計算相似度,計算結果見表5。根據關鍵詞相似度計算結果,通過AP聚類方法對關鍵詞進行聚類,并將原始關鍵詞替換為該關鍵詞聚類中心,該替換過程如圖1所示。
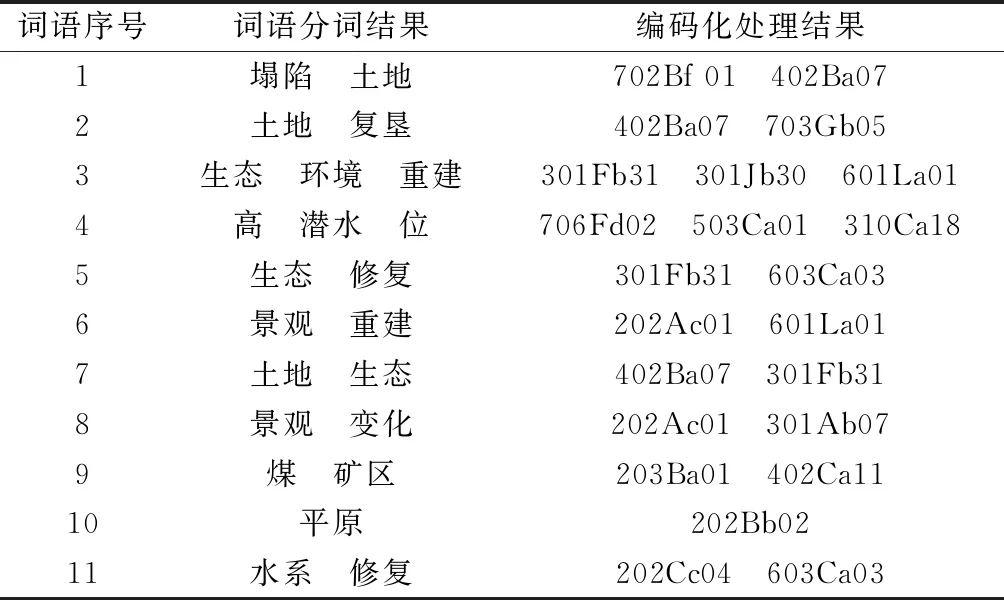
表4 分詞與編碼化處理結果Table 4 Treatment results of word segmentation and encoding
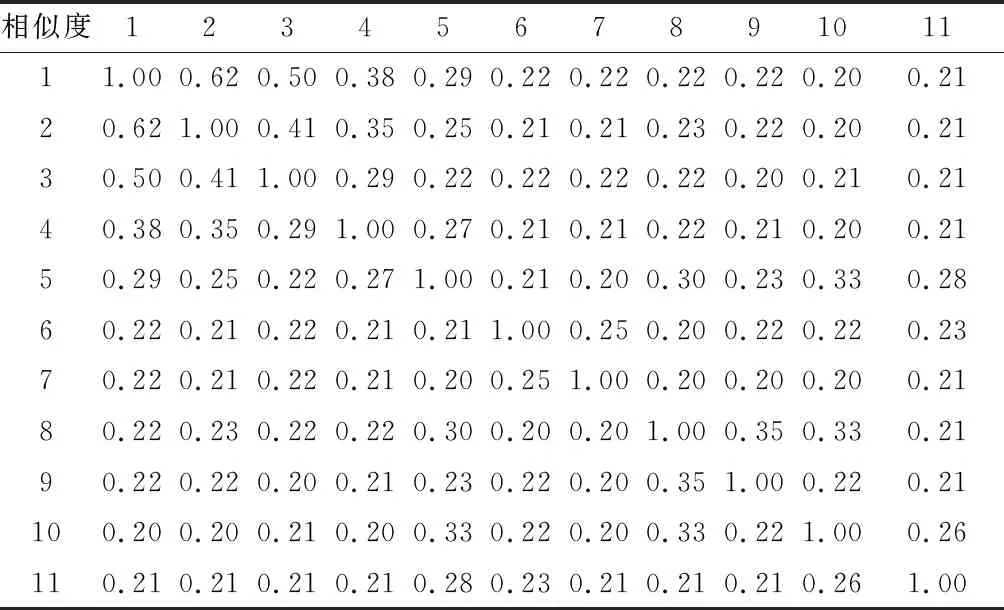
表5 關鍵詞相似度計算結果Table 5 Calculation results of keywords similarity
確定文獻的主題要素后,遍歷文獻找到特定主題要素關鍵詞,將其對應的有用信息提取出來,利用ArcGIS二次開發技術將數據挖掘結果進行綜合、集成,建立徐州礦區土地復墾與生態修復信息管理系統并開展時空數據分析。
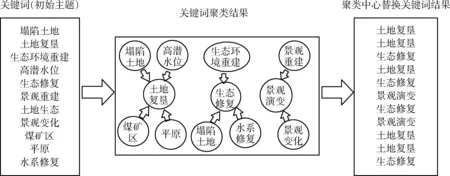
圖1 關鍵詞替換實例Fig.1 Keywords replacement example
3.2 數據挖掘結果
3.2.1 研究區域及時間的挖掘結果
結果表明:1995年以后徐州礦區土地復墾的研究逐漸增多,2014年達到高峰,數量最多(圖2)。主要研究區域是龐莊礦區、新河-臥牛礦區、義安礦區、垞城礦區、張集礦區、賈汪礦區、大黃山礦區和董莊礦區等(圖3)。
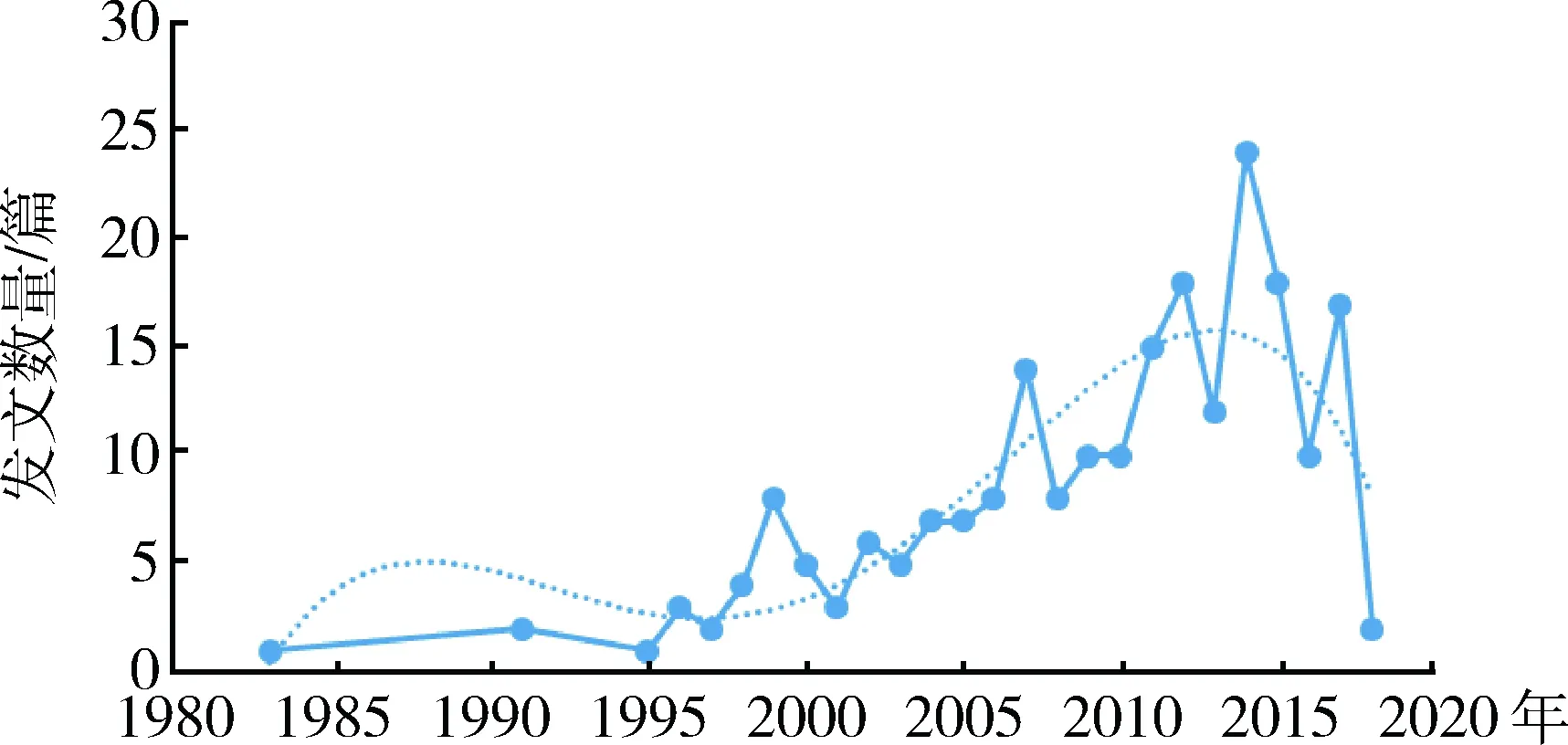
圖2 歷年研究文獻統計Fig.2 Statistics of historical literature
3.2.2 煤炭開采影響的挖掘結果
根據文獻主題要素挖掘徐州礦區復墾文獻,可以從挖掘結果中發現如下情況。
1) 土壤改良情況。徐州礦區煤炭開采對土壤的理化性質、碳效應均產生了影響,存在重金屬污染現象。以土壤理化性質的挖掘結果為例,可見粉煤灰充填方法更適合徐州礦區(圖4)。
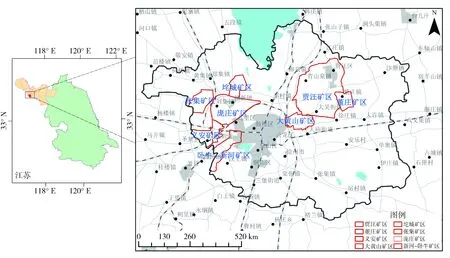
圖3 重點區域分布圖Fig.3 Key area distribution map
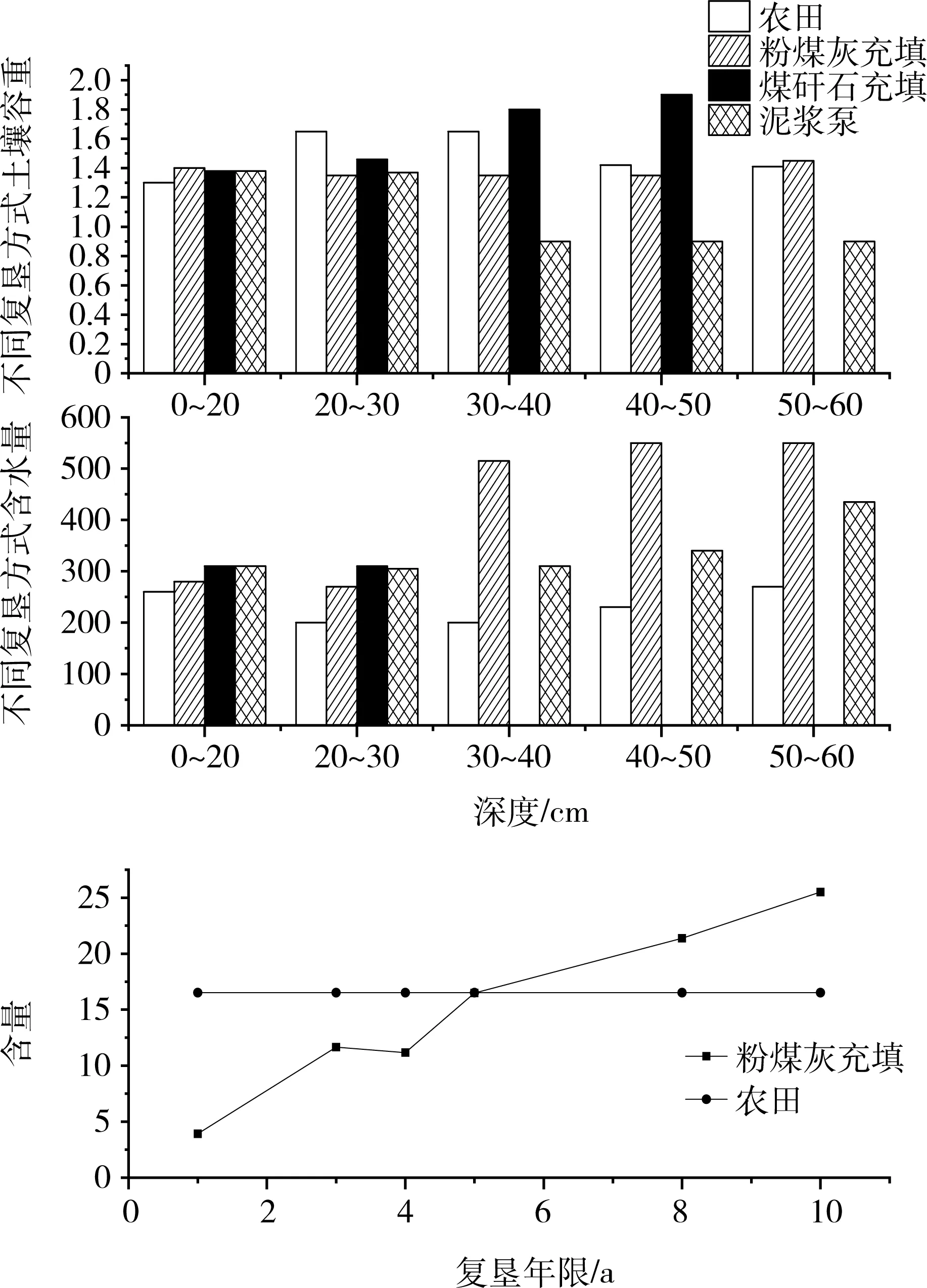
圖4 礦區土壤理化特性挖掘情況Fig.4 Soil physical and chemical properties of mining area
2) 水文治理情況。徐州礦區曾發生水害、水資源短缺、水污染、地表水系紊亂等問題。以水污染狀況挖掘結果為例,徐州龐莊礦區的權臺礦井水中多環芳烴含量較高,因此對其生態修復的治理將更為嚴峻(表6)。
3) 植被修復情況。徐州礦區植被凈初級生產力隨煤礦的開采強度增大而下降,但閉礦后逐漸恢復。
4) 景觀格局演變情況。景觀格局在采礦前后發生顯著變化;最主要特征是塌陷積水面積顯著增加。
5) 塌陷地情況。挖掘得到徐州市域范圍內礦區的歷史概況以及塌陷狀況。以賈汪礦區挖掘結果為例,其基本信息如圖5所示。
3.2.3 復墾技術與示范工程的挖掘結果
結果表明:徐州礦區曾成功開發出了泥漿泵復墾、基塘復墾、煤矸石充填復墾、高效農業復墾、建設用地復墾、生態濕地修復、景觀修復、采礦跡地修復、關閉礦山地下水污染防控等技術體系,并得到大面積的推廣。
以賈汪礦區的生態修復示范工程為例。賈汪礦區的采煤塌陷地復墾示范工程分布在青山泉鎮、賈汪鎮、紫莊鎮和大吳鎮,其中潘安湖生態濕地是近年研究的焦點,采用了“基本農田整理、采煤塌陷地復墾、生態環境修復、濕地景觀開發”四位一體的模式。
4 討 論
運用查準率(precision)、召回率(recall)、正確率T和F值來評判數據挖掘的精度,見式(6)~式(9)。
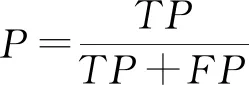
(6)
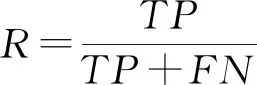
(7)
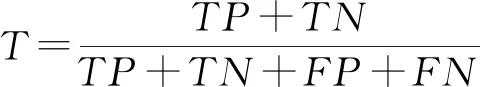
(8)
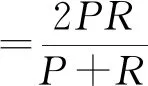
(9)
式中:TP為挖掘文獻數量;TN為真無效數量;FN為假無效數量;FP為人工處理的文獻數量與挖掘模型得到結果的文獻數量的差值;P為對數據挖掘的準確性;R為衡量數據挖掘的相關性;T為數據挖掘結果的正確率;F值為數據挖掘算法的總體性能。
通過整理TP、FP、FN、TN的值,對數據挖掘的結果進行對比分析[15]。以不同礦區評價結果為例,見表7。
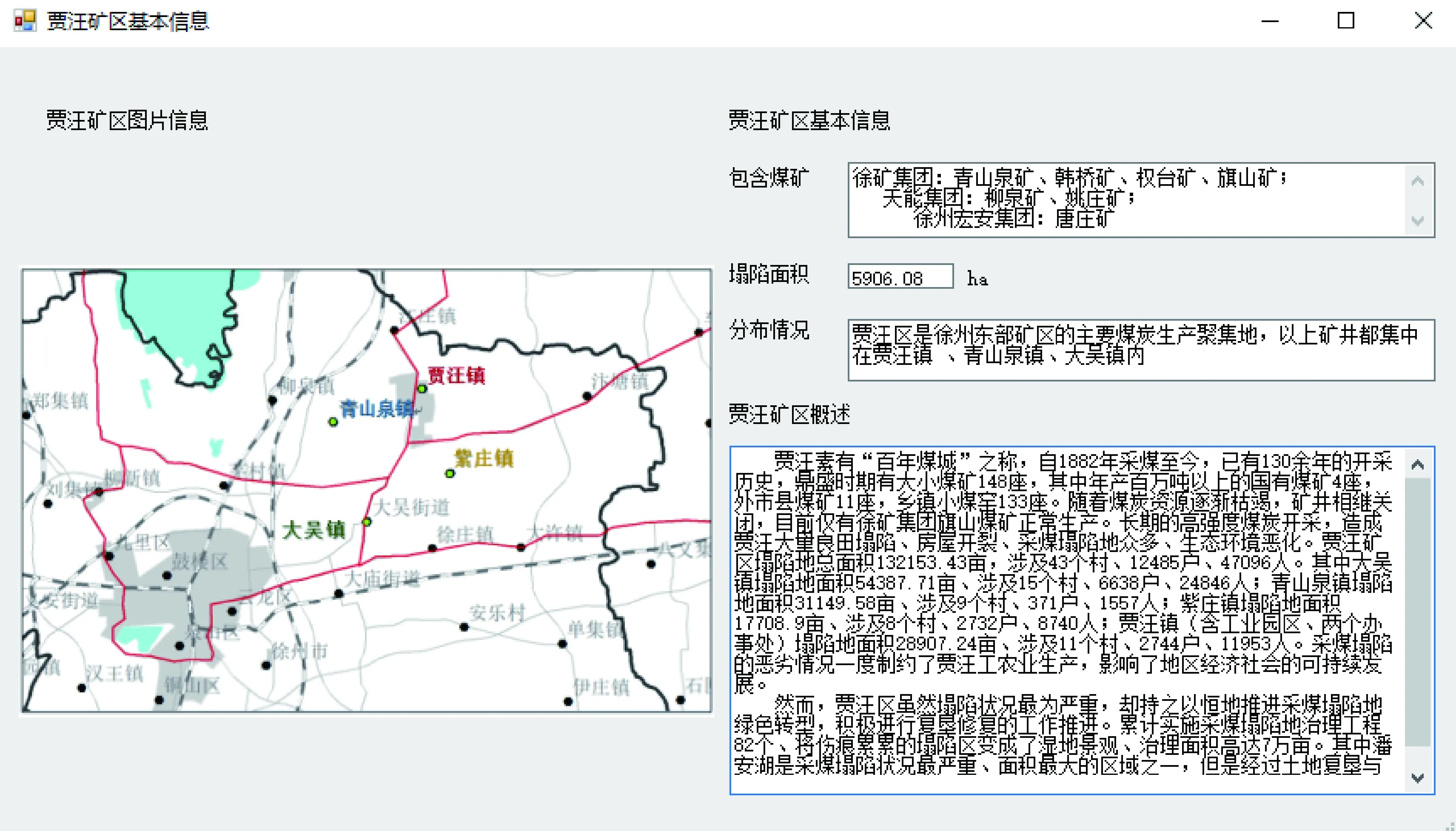
圖5 賈汪礦區概況Fig.5 Overview of Jiawang mining area
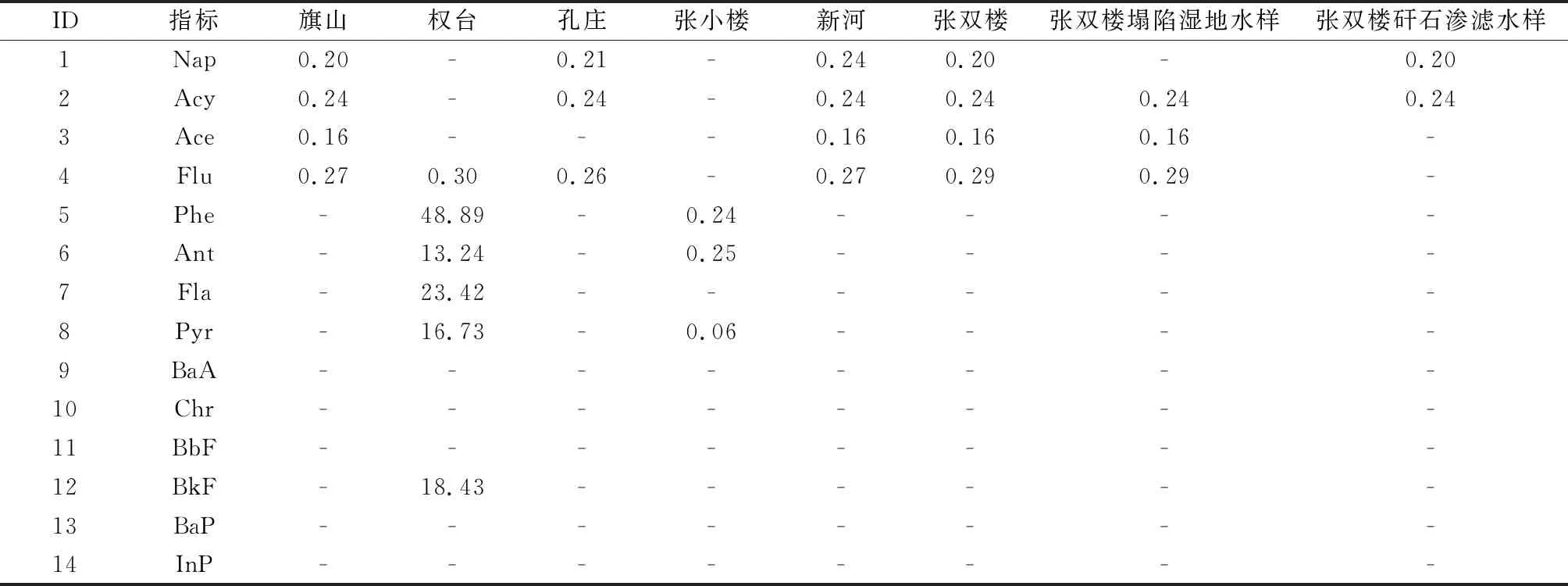
表6 龐莊礦水樣中多環芳烴含量Table 6 Pahs in water samples from Pangzhuang mine
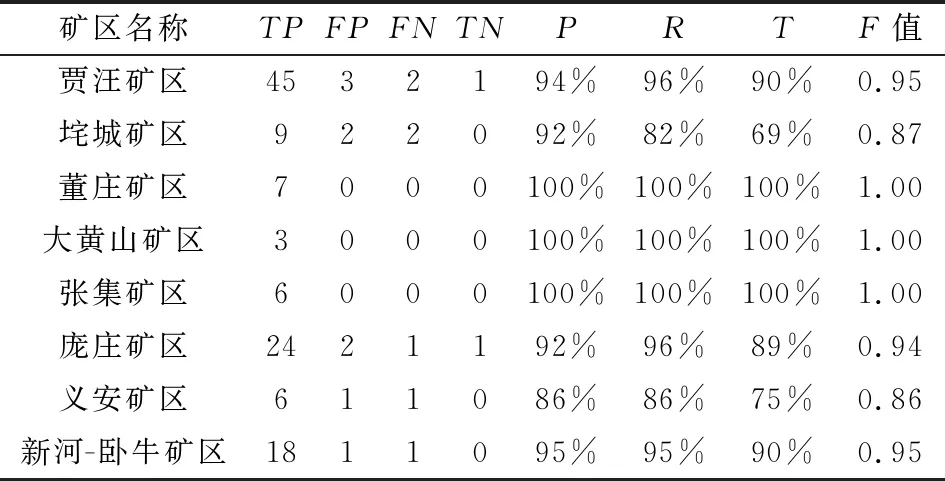
表7 不同礦區挖掘結果性能指標對比Table 7 Comparison of performance indexesof different mining results
從表7可以看出,利用數據挖掘得到的結果比較準確,證明該方法高效可行。通過少量的人工參與,確定了礦區土地復墾歷史文獻研究的主題要素,避免了“重復”研究,可以彌補人工統計時的無目的性、費時費力等不足,實現礦區土地復墾的信息集成與知識發現。
5 結 語
隨著我國對礦區生態環境修復的重視,礦區復墾文獻也不斷增多,采用數據挖掘技術,可彌補人工統計的不足。另外,礦區歷史面貌很難通過現場調查復原,而歷史文獻較完整記錄了其原貌,所以數據挖掘技術可發揮恢復歷史“數據鏈”的特殊作用。本文通過對土地復墾歷史文獻關鍵詞分詞編碼化,構建TF*IDF算法和空間向量模型、聚類分析,采用Python語言進行數據挖掘,最后在ArcGIS基礎上二次開發,顯示數據挖掘結果。以徐州礦區為例,開展實證研究,得到了徐州礦區的塌陷情況、復墾技術以及示范工程等重要歷史信息,克服了土地復墾歷史文獻的數據冗余、數據沖突以及真偽識別等難點。據此表明數據挖掘技術可實現礦區土地復墾與生態重建信息的集成與知識發現,為礦區系統修復、綜合治理提供基礎數據支撐。
猜你喜歡
保健醫苑(2021年7期)2021-08-13 08:48:02
大眾投資指南(2021年35期)2021-02-16 01:06:26
學生天地(2020年36期)2020-06-09 03:12:30
小學科學(學生版)(2020年5期)2020-05-25 07:11:32
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(2015年6期)2015-12-26 01:16:46
領導文萃(2015年4期)2015-02-28 09:19:05
中外會展(2014年4期)2014-11-27 07:46:46
電子設計工程(2014年18期)2014-02-27 12:00:13
