基于SSD的低空監視雷達目標檢測
2021-04-24 09:05:10易重輝張建偉
湖南城市學院學報(自然科學版) 2021年2期
易重輝,張建偉,錢 江
(1. 四川大學 視覺合成圖形圖像技術國防重點學科實驗室,成都 610065;2. 電子科技大學 長三角研究院(湖州),浙江 湖州 313001)
近年來,我國各個城市規模不斷擴大,民用的小型飛行器日益增多,使得國內航空流量不斷增加.這類飛行器機載設備差,不能及時、準確地通報本機位置,導致二次雷達較難探測到此類飛行器;其體積小、速度慢、飛行高度低等特征也使得一次雷達對此類飛行器的檢測識別變得非常困難.這給現有的空管工作施加了較大壓力,因此解決民用小型飛行器的檢測問題具有重要的研究意義和實用價值.
目前,國內外研究人員在雷達目標檢測方面做了許多工作.恒虛警率(CFAR)檢測是傳統的雷達目標檢測方法,具有檢測時間長和只能檢測點目標的缺點.為改善雷達目標檢測效果,大致發展出了2 個改進方向,即基于傳統信號處理的方法和基于特征的模式分類方法.對于前者,多屬于僅針對CFAR 的改進.如基于主成分分析(PCA)的矩陣CFAR 檢測[1]和基于積分圖像的快速CFAR 算法[2],顯著提升了檢測速度.文獻[3]提出的多尺度自適應選取區域CFAR 算法,提供了定位不同目標的新思路.基于CFAR 的改進算法只利用了檢測區域的信號幅度差異,未對目標進行特征建模,因此容易漏檢[4].
對于基于特征的模式分類方法,則將問題轉化成模式識別問題.文獻[5]用神經網絡的方法選擇使用CFAR 檢測器的種類;文獻[6]用卷積神經網絡替代分數階傅里葉變換;文獻[7]用改進的支持向量機識別雷達目標與遮擋物.上述方法所考慮的神經網絡屬于淺層網絡,提取特征不夠深刻.文獻[8]利用多種卷積神經網絡對MTD 圖像進行學習訓練,驗證了MTD 圖像結合卷積神經網絡的目標檢測算法在雷達目標檢測中的可行性,在檢測精度和速度方面有較大的提升,但其列舉的網絡結構簡單,特征提取程度有限,對小目標的檢測能力不足.SSD 是針對視頻目標的檢測算法,其檢測速度和綜合精度領先于其他視頻目標的檢測算法[9].相比其他用卷積神經網絡進行雷達目標檢測的方法,SSD 擁有更深的網絡結構,提升了小目標的檢測能力,加快了檢測速度,可以直接確定目標的位置.
基于此,本文提出了基于SSD 的低空監視雷達目標檢測算法.相對視頻目標,雷達目標在輸入圖像上的分辨率更低.根據低空監視雷達的實測數據,雷達目標只有8~16 個像素尺度,因此需要對數據集作許多改進以適應小目標:為便于卷積神經網絡處理,增加MTD 圖像在速度方向的像素尺度,并進行圖像切片;為更加符合實際運行情況,模擬數據的參數均與真實雷達參數相同;為了更好地對比模型優劣,生成了不同信噪比(signal to noise ratio, SNR)的雷達回波信號.
1 SSD 低空監視雷達目標檢測
基于SSD 的低空監視雷達目標檢測方法的流程如圖1 所示.

圖1 SSD 低空監視雷達目標檢測流程
由圖1 可知,首先,系統進行信號預處理;其次,生成MTD 切片圖像數據集,改進SSD 模型的各項參數和訓練數據集;最后,進行模型測試和評估,并對比不同模型在不同環境下的檢測效果.信號預處理部分,主要分為匹配濾波、動目標顯示和動目標檢測,生成MTD 圖像;構建數據集部分,主要分為圖像像素拓展和切片;測試評估部分主要對比測試SSD 與CFAR 2 種方法的系統性能.模型評估主要依賴P-R(precision-recall)曲線、平均精度均值(mean average precision, mAP,即各類別AP 的平均值)和平均檢測時間3 個性能指標.因CFAR 沒有分類功能,為便于對比,實驗生成的回波信號中只包含一種目標,所以文中mAP 是僅有一個類別的平均精度均值.
1.1 信號預處理
按照傳統的雷達目標檢測流程進行信號預處理,生成的MTD 圖像能夠反映雷達目標的形態學特征,因此可用于卷積神經網絡特征提取.圖2 顯示了具有4 個目標的回波信號在預處理階段提取其運動特征的過程.
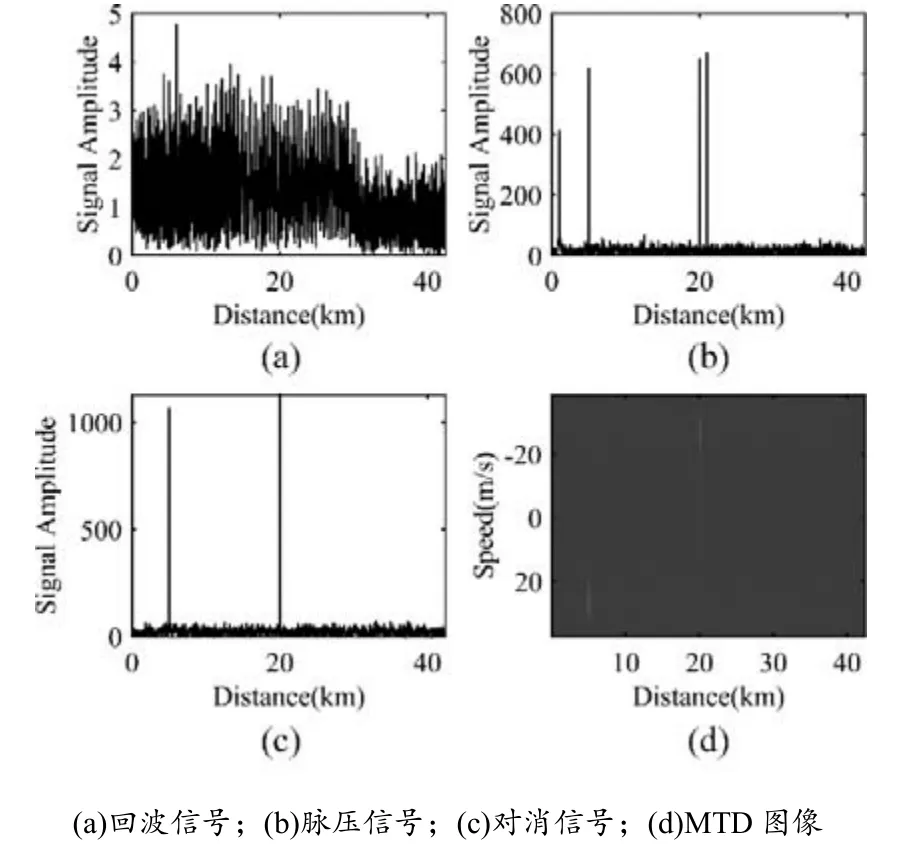
圖2 信號預處理效果
匹配濾波也稱脈沖壓縮,匹配濾波器利用信號發射源的信號參數,設計LFM(linear frequency modulation)信號,將LFM 信號與回波信號進行濾波,顯著提升了回波信號的信噪比.圖2(a)~(b)展示了模擬雷達回波信號經過匹配濾波器前、后的結果,顯然,通過匹配濾波,目標在距離維度上更加清晰.
利用目標回波脈沖間相位的起伏可以區分動目標和固定目標,本研究采用時域差分實現動目標顯示.如圖2(c)所示,位于距離為1 km 和21 km 的靜止目標被對消.通過動目標顯示與動目標檢測,可以有效地消除靜止目標并對運動目標測速測距.圖2(d)為動目標檢測結果,其中縱軸表示速度大小.由圖2(d)可知,MTD 圖像反映了雷達目標的距離和速度特征,也反映了雷達目標的部分形態學特征,因此,能夠通過設計卷積神經網絡進行特征提取.
1.2 構建數據集
數據集的構建主要考慮回波參數設計、圖像矩陣和矩陣切片.為了使模型能更貼近實際運用的場景,模擬回波數據的雷達參數和目標參數均與實際雷達保持一致,這樣計算得到的模擬回波會更加符合低、小、慢的目標特征,由此訓練得到的模型也更具實用性.在傳統的圖像目標檢測中,圖片的格式往往是.jpg 或者.png 這類壓縮格式,其數值范圍只有0~255,但MTD 圖像是實數矩陣,若直接轉換成圖像,將會損失大量目標信息.卷積神經網絡的計算過程并未將數值范圍嚴格限制在0~255,因此,為盡可能保留MTD 圖像的信息,可將卷積神經網絡的輸入圖像設為歸一化后的MTD 圖像.
在實際數據中,MTD 圖像的分辨率一般為10×2 830,而常用深度學習模型的輸入圖像分辨率為300~1 000 像素,兩者尺度相差較大.因此,先將MTD 圖像縱向尺寸進行延展、橫向尺寸進行分片,即分辨率為10×2 830 的圖像先縱向擴展為64×2 830,再切割成若干個64×64 尺寸的方形圖像,切片原理如圖3 所示.

圖3 MTD 圖像切片原理
從圖3 可知,每獲取到1 個正樣本,隨后會獲取1 份負樣本,以保證數據集的平衡性.圖3中的三維坐標圖則顯示了正負樣本在一定噪聲下的幅值差異.
1.3 SSD 模型設計
SSD 基于前饋卷積網絡,該網絡會生成固定大小的邊界框集合,并對這些框中存在的對象類實例進行評分,再執行非極大值抑制以生成最終檢測結果.其主要特點有:用于檢測的多尺度特征圖、用于檢測的卷積檢測器和默認先驗框.
為了更好地檢測不同尺度的目標,設計了多尺度特征圖用于檢測.卷積神經網絡的特征圖尺寸逐漸減小,生成了不同大小的特征圖;不同尺度的特征圖都參與檢測,可使IoU(重疊度)達到最大,有利于識別小目標.使用更簡單的卷積直接計算得分,可以更快地得到檢測值.在特征圖中使用多個不同尺寸的先驗框,可以有效地得到最適合目標形狀的先驗框.SSD 模型的網絡結構如圖4 所示.
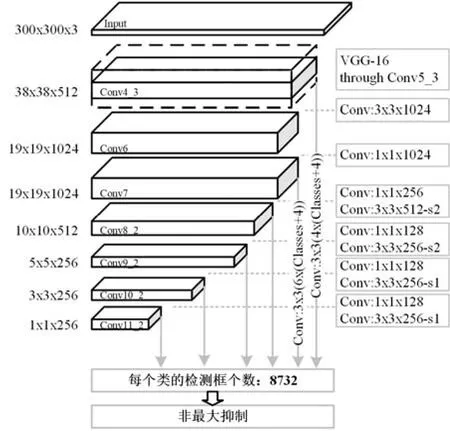
圖4 SSD 網絡結構
由圖4 可知,SSD 是在VGG16 的基礎上添加更多層來獲取更精細的特征.輸入圖像尺寸為300×300,使用VGG16 進行部分特征提取后,將VGG 的全鏈接層轉換為Conv6 和Conv7;再利用Conv8~Conv10 進一步細化特征圖尺寸;最后利用Conv11 輸出分數.除此之外,為了得到更精確的先驗圖位置和尺寸,SSD 還將VGG16 之后的卷積層都輸出并參與分類計算.
SSD 損失函數的設計分為3 個部分:前景分類誤差、背景分類誤差和位置回歸誤差.在誤差計算時,將IoU>0.5 的先驗框用在前景分類誤差計算;將IoU<0.5 的先驗框用在背景分類誤差計算;將前景分類誤差、背景分類誤差和位置回歸誤差進行加權求和得到最終誤差.
2 實驗結果分析
本研究所用的硬件實驗平臺主要包括Core i7-7700(CPU),NVIDA GTX 1080ti(GPU)和16G RAM;軟件平臺包括Matlab(用于回波信號處理和數據集構建)和MMDetection(用于搭建目標檢測的深度學習環境).為直觀顯示2 個模型的檢測效果,隨機選取8 組CFAR 與SSD 的檢測結果圖進行對比,如圖5 所示.

圖5 CFAR 與SSD 目標檢測效果對比
在圖5 中,每組圖像中的左圖為CFAR 檢測結果,右圖為SSD 檢測結果;左側為64×64 分辨率的切片MTD 圖像,右側為32×32 分辨率的切片MTD 圖像;每組圖像的檢測率閾值設為0.5,回波SNR 為-10 dB.
為準確、定量評估模型的檢測效果,設置了P-R 曲線、平均檢測時間(ms)和mAP 3 個基礎評估指標.其中,P-R 曲線的橫軸recall 是查全率;縱軸precision 是查準率.通過調整檢測率閾值,獲得模型在某個檢測率下的查全率和查準率,當檢測率閾值越高,查準率越高,查全率越低;反之,當檢測率閾值越低,查準率越低,查全率越高.可見,查全率和查準率是一對相互制約的參數.P-R 曲線越接近坐標軸的右上角代表這個模型的檢測效果越好.平均檢測均值mAP 為P-R曲線的面積積分,可定量評估模型檢測效果.平均檢測時間為模型檢測1 張MTD 圖片所花的時間,單位為ms.2 種模型的平均檢測時間和平均檢測率的對比結果如表1 所示.

表1 2 種模型檢測時間和檢測率對比
CFAR 和SSD 檢測模型的性能測試結果分別如圖6(a)~圖6(d)所示.其中,圖6(a)為2 種模型在5 dB 信噪比下的P-R 曲線對比;圖6(b)為2 種模型mAP 在不同SNR 下的變化曲線.由圖6(b)中的數據,可以算得CFAR 和SSD 的綜合平均檢測均值分別為0.521 和0.653.為了更全面地評估CFAR 和SSD 模型的實際使用效果,研究了不同程度噪聲對2 種檢測模型的干擾,實驗模擬出-15,-10,-5,1,5 和10 dB 6 個等級的SNR,對模型進行評估測試.圖6(c)和圖6(d)分別為不同SNR 對CFAR 和SSD 模型測試效果的影響.
由圖5、圖6 及表1 可得出如下結論:
1)與CFAR 相比,SSD 能更準確地提取小目標和低分辨率的目標特征.CFAR 需預先設置一種飛行器的固定尺寸,而SSD 能夠通過設定更多先驗框并不斷逼近標簽尺寸,更全面地提取MTD圖像中目標的形態特征,區分噪聲背景.如圖5所示,在高分辨率圖像中兩者差異較小,但在較低分辨率的圖像中,CFAR 有明顯漏檢.
2)與CFAR 相比,SSD 能檢測到弱信號的目標.CFAR 設置了固定檢測框和檢測閾值,這使得CFAR 提取的特征信息不夠豐富,當目標信號較弱時,CFAR 無法檢測到.如圖6(c)和圖6(d)所示,SSD 具有約達90%的查全率,而CFAR 最多只能達到70%,雖然此時CFAR 的查準率并不低,但還是說明CFAR 漏檢了大量弱信號目標.
3)相對于CFAR 模型,SSD 模型的平均檢測均值更高、速度更快.CFAR 和SSD 檢測算法雖均使用Python 進行計算,但SSD 可以使用GPU加速,提高效率.如表1 所示,SSD 的檢測率比CFAR 高了18.75%,速度約是CFAR 的13.2 倍.
4)與SSD 相比,CFAR 對噪聲更敏感.如圖6(b)所示,隨著信噪比的提升,CFAR 和SSD 的檢測率不斷提高;當信噪比高于5 dB 后,SSD 的檢測率變化并不明顯,CFAR 卻有一定程度下降,這說明微小的噪聲變化對CFAR 的影響更大.

圖6 CFAR 和SSD 檢測模型的性能測試結果
3 結語
將視頻目標檢測方法引入雷達目標檢測,并針對低空雷達檢測目標的特殊性,通過修正圖像尺寸來改進MTD 圖像,利用低空監視雷達的信號參數生成對應的模擬數據集,對其進行測試和訓練以符合真實應用場景.研究結果表明,所提方法在檢測準確度和速度上均領先于CFAR.但該方法局限性在于輸入圖像后,模型會將圖像尺寸拉伸至300×300,從而增加了計算量,且拉伸算法可能對目標特征有一定的干擾.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
