
未知輸入干擾下異構多傳感器分布式兩級信息濾波與偏差聯合估計
2021-04-24 03:02:22李宇,周潔,申強,高嵩
中國測試 2021年2期
李 宇,周 潔,申 強,高 嵩
(1.西安工業大學電子信息工程學院,陜西 西安 710021; 2.西北工業大學 空天微納系統教育部重點實驗室,陜西 西安 710072)
0 引 言
多傳感器網絡是由多個具有一定傳感、計算執行和通信能力的傳感器組成的網絡[1]。近年來,傳感器以其集成化,智能化的優點被廣泛應用于各個領域,如無人機、機器人、雷達等[2-3]。傳統的目標跟蹤是以數據處理為基礎的單傳感器單目標跟蹤,即一個傳感器只能跟蹤一個目標。單個傳感器在能量、時間、感知距離、處理能力、通信帶寬等處理能力有限,無法獨立完成復雜任務。并且,單一數據由于信息的不完備性和不確定性而表現為價值密度低,信息誤差大,因此多傳感器網絡順勢而生。多傳感器網絡具有互補監控區域、信息共享的優點,從而能夠對探測信息進行優化融合,最大限度地過濾掉無用信息,提升目標的跟蹤性能。如果某些傳感器在目標跟蹤過程中發生故障,其他傳感器仍可以正常工作。然而在傳感器跟蹤的過程中往往會存在傳感器跟蹤結果與目標真實狀態偏差較大的問題。這是由于傳感器在工作會存在一定的偏差,比如硬件和軟件運行導致的固有偏差,以及外界環境影響等外部偏差。其中,大多數會存在未知輸入的影響,即無法量測的擾動或輸入,這些未知輸入沒有先驗知識,無法被精確的建模,導致傳感器量測存在較大誤差,降低系統估計精度。為了提升目標估計的精度,許多學者提出了一些偏差估計方法和抗干擾方法。
偏差估計方法主要是基于標準卡爾曼算法以及最小二乘算法進行改進的。文獻[4]提出了一種非線性最小二乘公式以及塊坐標下降優化算法。通過求解最小二乘問題和方位偏差估計,實現了在沒有噪聲的情況下準確地恢復傳感器偏差,然而在實際環境中噪聲是不可避免的,因此該文獻的算法不適用于實際情況。文獻[5]提出了一種兩級擴展卡爾曼濾波算法用于非線性傳感器系統故障估計,該算法在故障診斷上效果顯著,但并不適用于含未知輸入的工作環境。文獻[6]研究了基于期望最大化算法的迭代偏差估計,利用擴展卡爾曼濾波和平滑推導EM估計過程來估計量測偏差;但其要求有足夠多的量測數據,并且平滑窗口很小,易導致結果無效。文獻[7]針對位移傳感器量測過程中引入的誤差,提出了3類誤差模型并且基于加窗函數法對誤差進行補償,再采用最小二乘法對進行偏差估計修正來降低量測誤差,但其需要對誤差進行精確建模,而實際中傳感器受到的誤差往往不止3類。以上研究的偏差估計算法均沒有考慮到系統偏差存在未知干擾的問題。
針對未知干擾問題,目前國內外采取的抗干擾算法主要分為前饋控制和反饋控制。前饋控制主要是擾動觀測器控制[8]和滑模控制,估計擾動然后及時補償。然而這些方法依賴于擾動和系統方程的精確建模,并且滑模控制可能會引起抖振現象,在實際中會損壞系統。反饋控制主要有魯棒控制[9-11]、H∞控制[12]和可變結構控制等。這些方法主要通過抑制擾動來提高閉環系統的控制性能,但有一定的滯后效應,不能及時衰減擾動。
本文考慮到含未知輸入的偏差估計問題,設計了改進的兩級信息濾波器及其多傳感器分布式一致性融合濾波器。提出了含未知輸入的傳感器偏差模型并對偏差模型進行等價轉換,以消除未知輸入的影響,用兩級信息濾波算法對目標狀態和傳感器偏差進行實時的雙重估計,狀態估計和偏差估計進行相互修正提高雙方的估計精度,能夠及時對未知輸入等偏差進行濾除。并且相比于兩級卡爾曼濾波,在數據量大的情況下,兩級信息濾波與兩級卡爾曼濾波有著相同的估計精度,但由于其不用計算濾波增益就能進行估計,大大地減少了系統的計算量。進一步地,進行傳感器網絡化的設計,采取分布式的數據融合結構,一致性估計的原則,根據網絡通信拓撲采取基于通信量加權的融合方法,識別出網絡中的重要節點并賦予更高的權值,相比于常見的平均加權方法,能夠提高整個傳感器網絡一致性的收斂速度,從而提高融合效率。
1 系統模型
傳感器偏差主要考慮由內部固有偏差、外部未知輸入以及噪聲3部分。傳感器觀測不僅要觀測目標,同時還要考慮到偏差的影響。為此,建立以下線性離散時間隨機多傳感器系統模型:
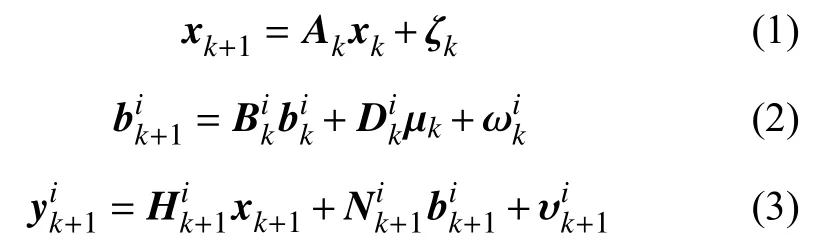
式中:xk∈Rn——k時刻濾波狀態量;
μk∈Rq——未知輸入;
假定mi>pi>qi,為滿秩。噪聲為互不相關的零均值白噪聲,滿足,是其各自的協方差矩陣,δk-l為克羅內克函數。系統建模場景如圖1所示,該問題可歸結為式(1)~(3)中動態多傳感系統的局部單傳感器濾波器設計以及數據融合處理算法設計。
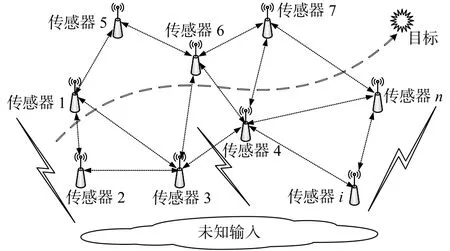
圖 1 受未知輸入影響的多傳感器進行目標跟蹤場景
2 局部單傳感器濾波器的設計
當量測個數遠大于狀態量個數時,使用信息濾波計算效率會更高。結合未知輸入以及兩級濾波思想,局部濾波器的設計采用兩級濾波的結構和信息濾波的形式,即狀態濾波器和偏差濾波器兩級聯合信息估計。對兩級Kalman算法進行改進,并且結合信息濾波的優勢。首先消除未知輸入的影響,其次進行噪聲處理,分離噪聲交叉項,最后結合信息濾波形式設計兩級信息濾波器。
2.1 構建偏差解耦模型
首先,為了消除未知輸入μk,對μk和進行解耦。根據式(1)~(3),聯立方程組:
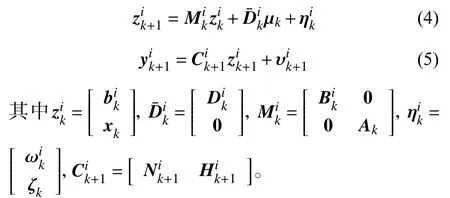
將式(4)代入式(5),則有
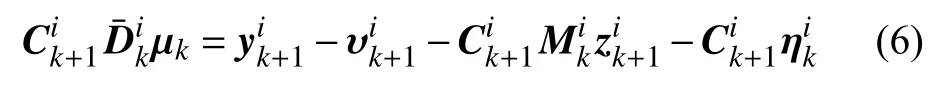
那么μk就可以表示為
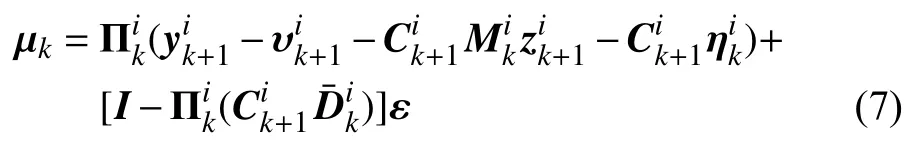
其中,ε是一個具有適當維數的任意矩陣。把式(7)再代入到式(4)中,則有

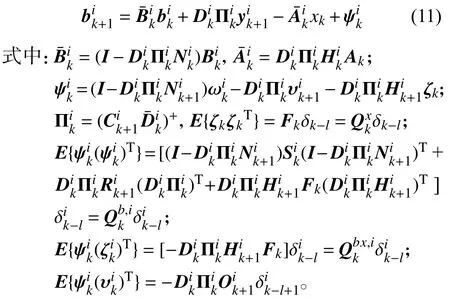
由此,用式(11)替換式(2),能夠建立新的不含未知輸入的系統模型。因為方程(3)和(11)的噪聲相關,會導致線性高斯濾波結構改變,不能直接運用兩級卡爾曼濾波。因此,需要對偏差噪聲和觀測噪聲進行解相關處理,以改變系統結構使之噪聲獨立。
2.2 噪聲處理
假設rank(NiDi)=p,那么存在全行秩矩陣L,使得偏差噪聲和觀測噪聲解相關。則方程(1)、(3)、(11)可以擴維改寫成如下形式:

由此,可以使得偏差噪聲與量測噪聲相互獨立。
2.3 改進兩級信息濾波器
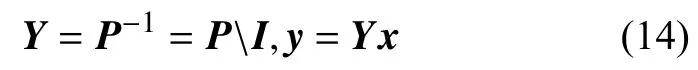
其中, 表示左除算子。
2.3.1 偏差濾波器(在不考慮xk的情況)
預測無狀態偏差信息矩陣及其協方差:
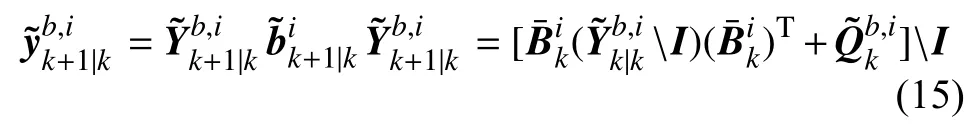
更新無狀態偏差信息矩陣及其協方差矩陣:
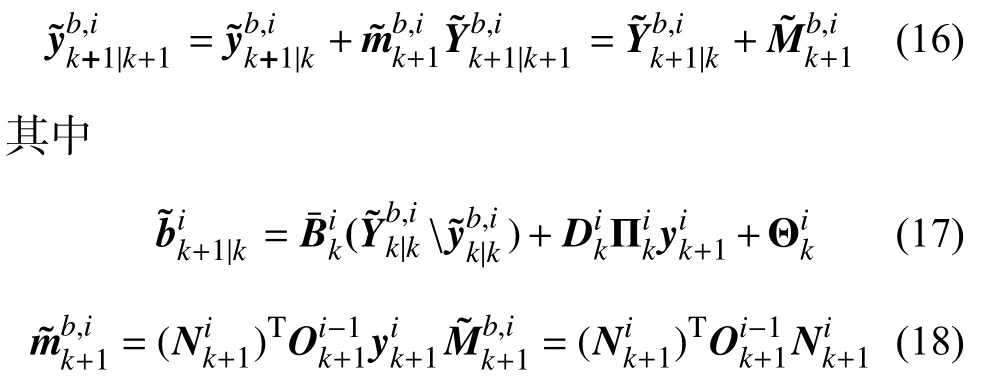
2.3.2 狀態濾波器
預測狀態信息矩陣及其協方差:
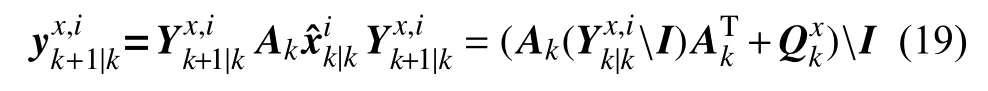
更新狀態信息矩陣及其協方差:
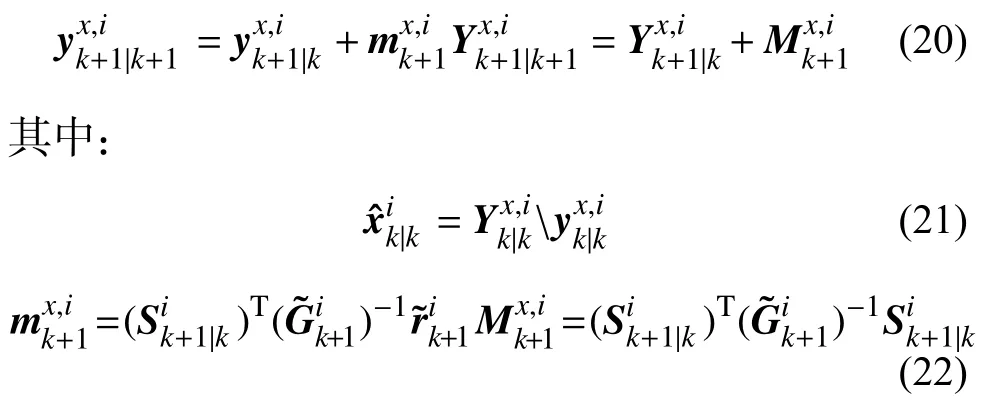
2.3.3 輔助變量
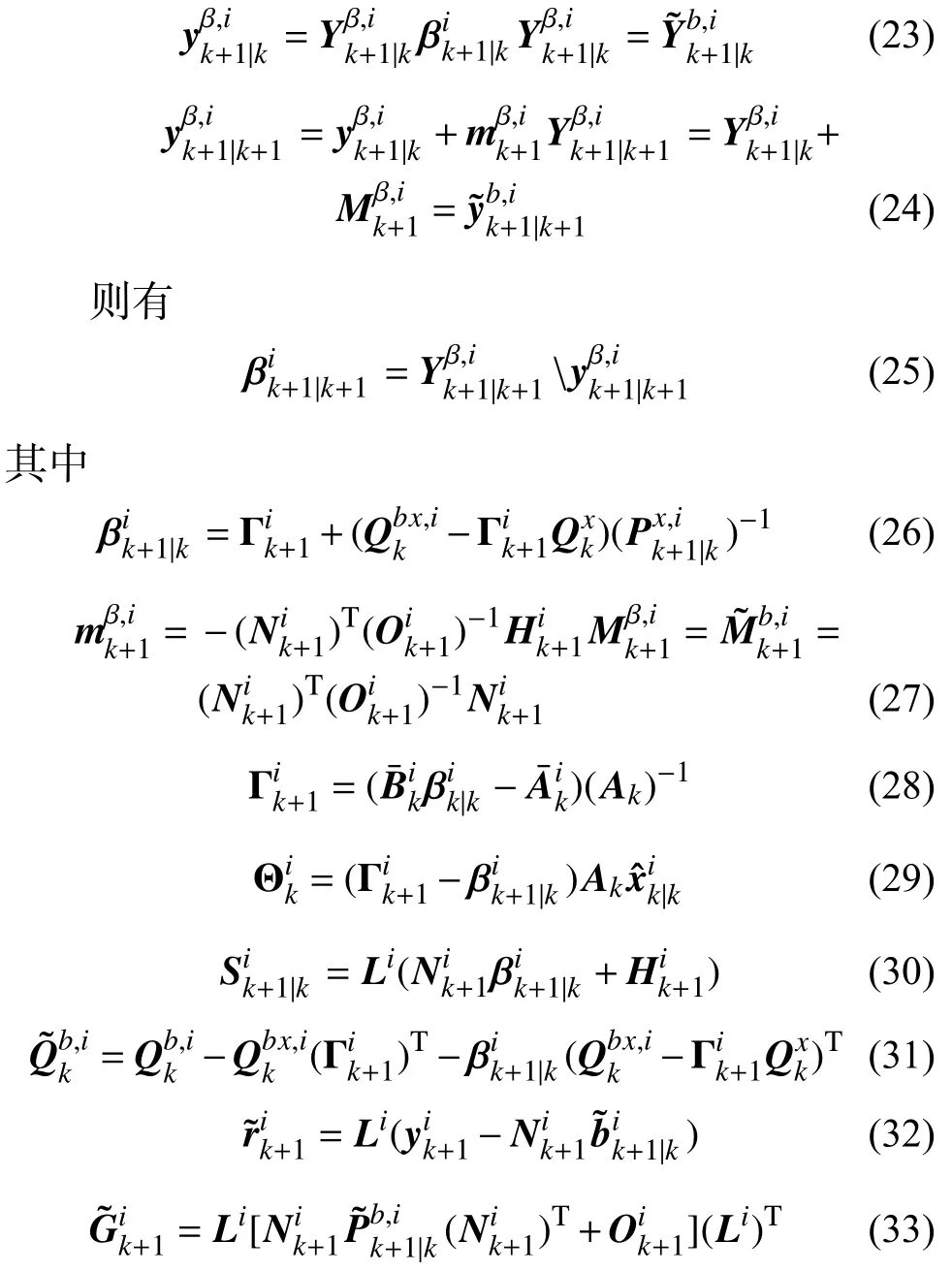
2.3.4 最優兩級濾波器的校正配準

3 分布式一致性多傳感器數據融合
分布式融合結構相比于集中式結構減少了傳感器通信量和數據處理的計算量,傳感器節點不用都上傳數據到融合中心,只需與鄰居傳感器相互交換信息。不同傳感器之間的局部估計不一致,為了提高每個傳感器的估計精度,減少傳感器間的不一致性,本算法采用一致性估計融合方法使每個傳感器收集鄰居傳感器的局部估計加以融合,并將融合后的估計值反饋給各個傳感器,能夠使各個傳感器的估計值趨于一致。由于傳感器偏差不僅僅只有未知輸入的影響,還包括傳感器自身偏差,所以每個傳感器的偏差是其本身特有的,不能夠進行一致性濾波。因此,本文設計各傳感器先在本地進行局部估計,再與鄰居節點互相交換狀態信息矢量及其矩陣。
本文設計基于節點通信量的加權規則,即考慮整個網絡的通信拓撲,根據節點的通信情況確定權值因子。在分布式傳感器網絡中,非鄰居節點的任意兩個節點必須經過其他節點的傳遞才能獲得彼此的信息。網絡每進行一次一致性迭代,信息就會進行一次傳遞,因此本文定義Timeij表示節點i的信息傳遞到節點j的最少傳遞次數;定義為節點i收到其他所有節點信息的最少迭代次數之和;定義Ωmax表示網絡中最多鄰居節點的個數;定義為節點通信量。由此可見,有限迭代次數以內,ρ(i)越小,Δ(i)越大,節點i得到的信息就越多,估計精度就越高。這樣迭代更新的方法使得通信量高的鄰居節點賦予權值更高,每個傳感器采集到鄰居的信息都會進行迭代,使得每個傳感器更新的值都更精確,這樣循環往復,最終所有的傳感器的狀態估計會漸進達成一致。
根據平均一致融合準則,令U(l)=[uij(l)]表示狀態估計迭代l步的線性加權矩陣,uij(l)表示傳感器節點i處節點j的權重。定義如下的加權矩陣規則:
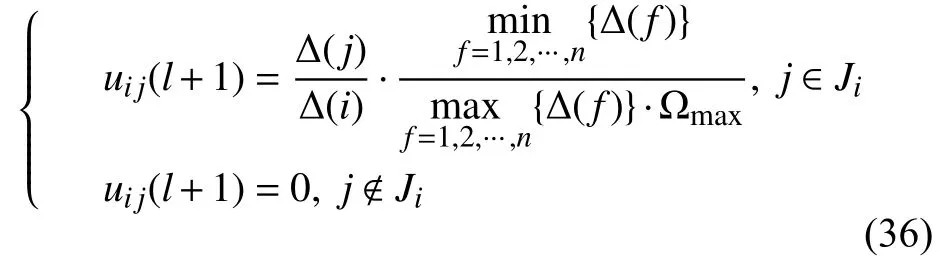
根據式(1)~(3),傳感器i進行l次一致融合后,其狀態估計加權系數矩陣為U(l),其相應的全局最優信息矢量和信息矩陣為:
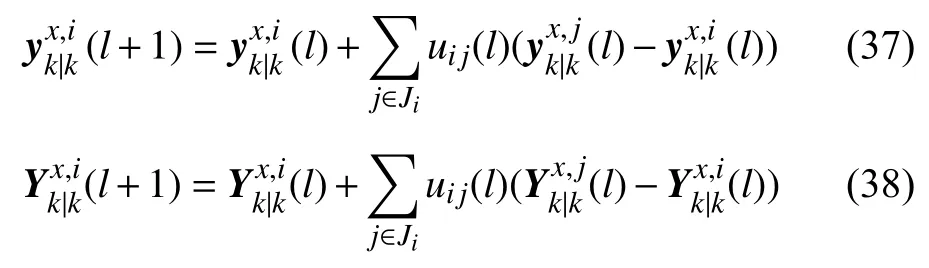
則全局最優狀態估計可表示為:
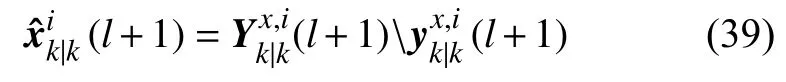
分布式一致性數據融合算法通過迭代,不斷提高各個傳感器的狀態估計精度,融合后的狀態估計反饋給各傳感器繼續進行兩級濾波算法,結合局部兩級濾波算法用狀態估計對偏差進行修正,使得傳感器的狀態和偏差估計精度經過雙方面的提高。
4 仿 真
以脈沖多普勒雷達距離跟蹤為例進行算法仿真分析。由于目標在運動中轉彎越多,它的有效速度就越小,用來完成任務的時間越長,因此,一般情況下目標做勻速直線飛行。常規多普勒雷達的距離跟蹤環路和速度跟蹤環路是相互獨立的,因此距離和速度自然成為量測的兩個分量。本文設定以下仿真場景:目標做勻速直線運動,所有的傳感器均受到相同的未知輸入干擾,但每個傳感器受內部偏差影響,其系統偏差演化模型各不相同。考慮式(1)~(3)中的系統,設置以下參數進行仿真。假設有10個傳感器,參數設置為


圖 2 傳感器網絡拓撲圖
傳感器網絡對應的拓撲也可以用下面的鄰接矩陣來表示:

由拓撲圖可知:

則ρ=[19,14,17,25,18,15,19,14,20,21],從拓撲圖中可以看出,傳感器8的鄰居節點最多,因此,設置Ωmax=5。
為了證明本算法的可行性、穩定性以及優越性,本文將平均估計誤差函數Average(k)和平均不一致程度函數Together(k)作為體現算法的性能指標。為體現本文所提算法性能的優越性,仿真設計與文獻[13]與文獻[14]進行對比。
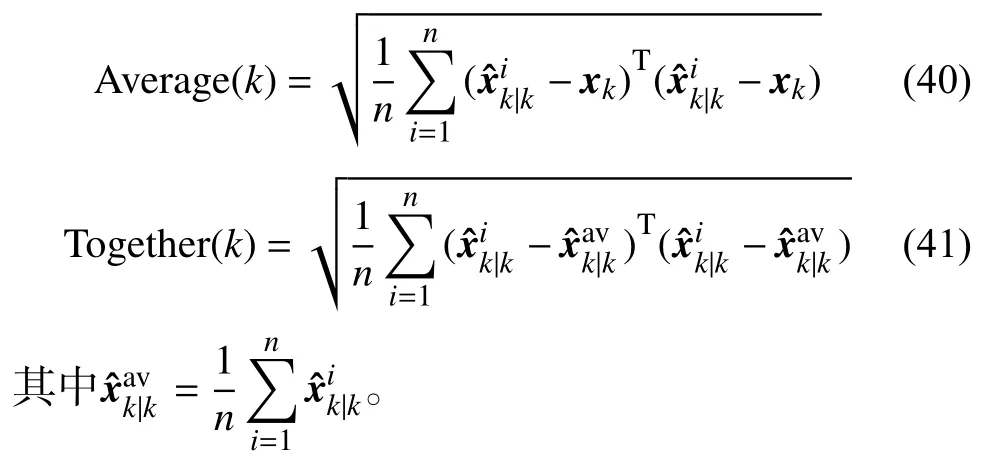
系統未知輸入如圖3所示,本文利用估計誤差變化的平均值表示估計精度的提高,從圖3中可以看出,未知輸入的波形中包含了隨機值、鋸齒波、正弦波以及零值,體現了未知輸入的多樣性,本文根據以上的未知輸入來進行算法濾波。
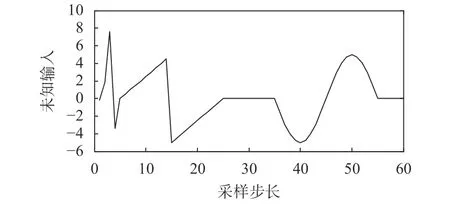
圖 3 未知輸入變化情況
系統狀態估計誤差和偏差估計誤差均值效果如圖4所示。圖中,KF表示傳統卡爾曼算法,TSIF共識算法表示為本文提出的兩級信息濾波共識算法,CKF共識算法表示文獻[13]提出的擴維卡爾曼共識算法,TSKF共識算法表示文獻[14]提出的局部兩級卡爾曼濾波結合文獻[13]的權值設計進行共識。

圖 4 狀態估計誤差和偏差估計誤差變化情況
從圖4可知,KF算法的誤差波形與未知輸入的波形相似,證明KF算法對未知輸入的濾除效果差。其他3種算法的濾波誤差相比于KF算法有明顯的改善是由于其他3種算法進行了共識融合并且都對未知輸入進行了相關處理。其中,本文算法誤差最小,波形相對平滑,證明濾除未知輸入的效果非常顯著。幾種共識算法的估計不一致程度見圖5。

圖 5 不同算法的估計不一致程度
由圖5能夠看出,本文所提出的算法不一致誤差在0.02內,傳感器網絡一致性程度明顯優于其他算法。仿真驗證進行Monte Carlo運算,驗證本算法的可靠性。Monte Carlo試驗中,每次試驗都會產生新的噪聲,每次試驗初始狀態會重新隨機選擇。仿真對4種算法采取1 000次Monte Carlo循環,最后對1 000次循環的結果取均值,效果如圖6所示,可以看出,本文的算法誤差較低,性能較好。算法1 000次循環后的估計不一致程度均值如圖7所示。
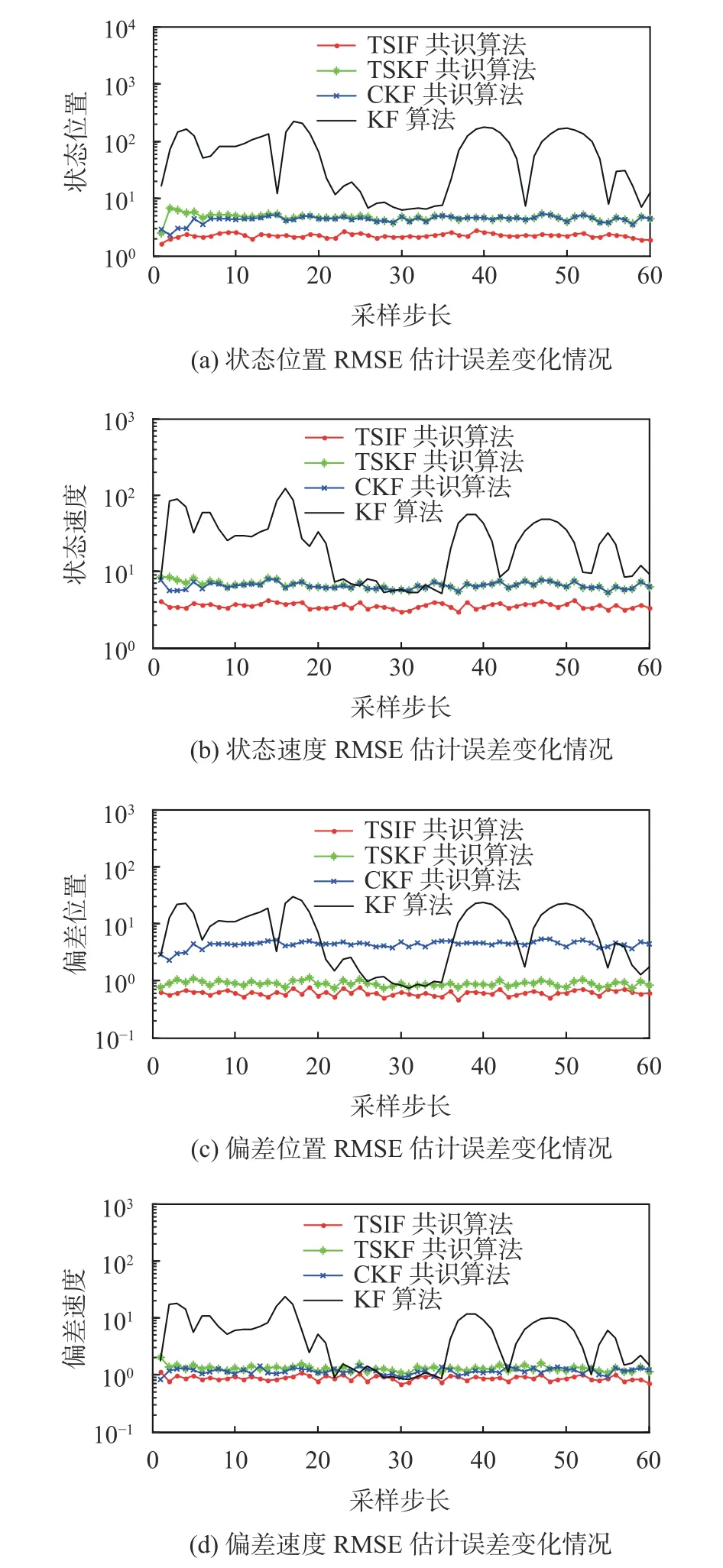
圖 6 狀態及偏差的位置、速度RMSE
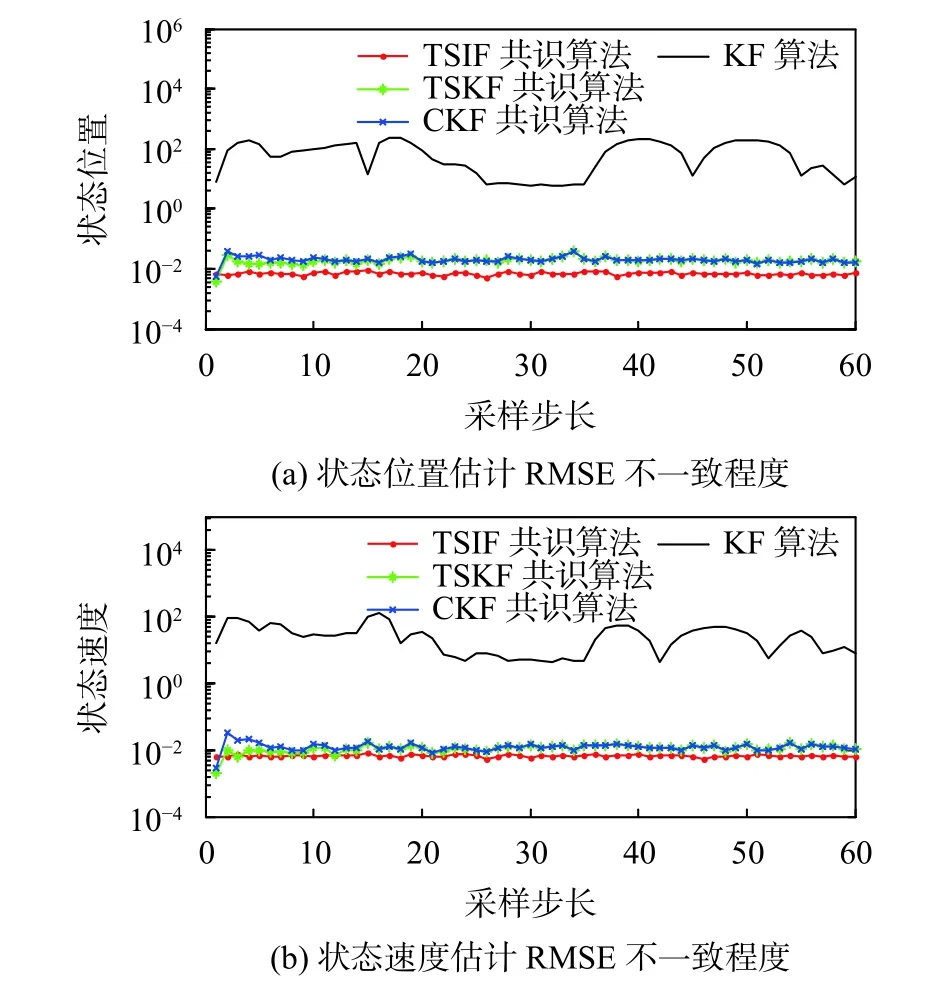
圖 7 估計不一致程度RMSE
仿真結果顯示,無論未知輸入的波形是隨機的還是有規律的,本文所提出的算法均表現出較低的估計誤差,并且具有很高的穩定性。KF算法并未進行共識融合,因此每個傳感器的估計結果基本都各不相同,其估計不一致程度差異明顯。利用1 000次蒙特卡洛循環后,從圖6~圖7可以看出無論是對于狀態估計還是偏差估計,本文提出的算法估計誤差波形平穩,誤差較低,跟蹤精度較高,網絡的一致性估計程度有很大的提升。
5 結束語
針對多傳感器在目標跟蹤過程中受未知輸入影響導致跟蹤效果低下的情況,本文提出了分布式一致性加權融合兩級信息濾波算法用于多傳感器系統進行數據融合。在有系統偏差存在的情況下,改進的兩級信息濾波不僅可以解決未知輸入的影響,還可以有效避免處理高維矩陣運算,提出的分布式一致性算法在傳感器網絡一致性估計程度上相比于其他算法有著較高的優勢。仿真結果表明,提出的TSIF 共識算法估計誤差比較小,具有一定的可行性,并且估計精度明顯比其他濾波算法估計精度高,誤差小,具有很好的穩定性,可以顯著提高系統狀態和偏差的估計精度。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
