采用CNN-SSD的雷達HRRP小樣本目標識別方法
2021-04-30 02:46:26郭澤坤王鵬輝劉宏偉
西安電子科技大學學報 2021年2期
郭澤坤,田 隆,韓 寧,王鵬輝,劉宏偉,陳 渤
(1.西安電子科技大學 雷達信號處理國家重點實驗室,陜西 西安 710071;2.中國人民解放軍32181部隊,陜西 西安 710032)
雷達高分辨距離像(High Resolution Range Profile,HRRP)是由寬帶雷達信號獲取的目標散射中心子回波沿雷達射線投影的向量和,它包含了目標散射中心的分布信息、目標結構以及目標尺寸等重要特征[1-3]。與合成孔徑雷達(SAR)等相比,雷達高分辨距離像具有穩定、易于獲取和處理的特點[4]。隨著寬帶雷達以及雷達自動目標識別技術(RATR)的發展,雷達高分辨距離像已成為備受關注的研究熱點。
雷達目標識別系統包括預處理、特征提取和分類三部分[3]。在進行目標特征提取及分類之前,通常會經過數據預處理消除原始信號的3個敏感性[2-3]。有大量研究表明,提取具有鑒別性的特征對于提高雷達高分辨距離像目標識別性能至關重要[5]。淺層統計識別模型雖然對訓練樣本量要求不高,但是其性能嚴重受限于其線性的建模方式,導致模型對數據的特征提取能力不足,這類經典的方法包括因子分析(Factor Analysis,FA)模型[6]、最大相關系數法(Maximum Correlation Coefficient,MCC)[7]以及自適應高斯分類器(Automatic Gaussian Classifier,AGC)等[8]。文獻[1]提出了多任務稀疏學習的統計建模方法,通過挖掘不同任務間共享的結構信息降低了模型對數據量的需求,在雷達高分辨距離像庫內小樣本識別中取得了不錯的性能。為了提高模型對數據的特征提取能力,得益于深度學習在模式識別中的快速發展,以深層神經網絡為代表的特征提取方法也被廣泛應用于雷達高分辨距離像的特征提取。針對雷達高分辨距離像小樣本識別問題,文獻[3]首先通過批歸一化算法改進了卷積神經網絡收斂慢的問題,然后對雷達高分辨距離像進行自動特征提取,再利用支持向量機(SVM)對其進行分類;文獻[4]提出了一種基于遷移學習的雷達目標識別方法,該方法首先在大樣本雷達高分辨距離像數據上訓練得到一個初始卷積神經網絡模型,再結合飛機目標識別任務調優模型參數,顯著改善了模型在小樣本條件下的目標識別能力。然而,這兩種方法仍然是基于庫內小樣本識別場景,無法實現對庫外非合作目標的高效泛化。文獻[6]利用元學習實現了對于庫內目標的庫外姿態角的快速泛化;然而,該方法仍然假設測試樣本的類別是訓練集中見過的。
筆者提出一種基于卷積神經網絡模型連續自蒸餾(Convolutional Neural Network Sequential Self-Distillation,CNN-SSD)的雷達高分辨距離像非合作(庫外小樣本)目標識別方法。一方面通過連續自蒸餾機制對類別間的相關性進行建模,提高了模型提取特征的泛化能力,同時利用集成學習的思想對連續自蒸餾進行改進,實驗表明改進后的模型對非合作目標的特征提取的泛化能力更強;另一方面,考慮到基于梯度下降優化得到的分類器性能受觀測數據量影響較大[9],采用了基于優化的具有閉式解的線性分類器對蒸餾得到的非合作目標的特征進行分類。文中主要討論了兩種滿足條件的分類器,它們分別是:支持向量機(SVM)和邏輯回歸(Logistic)。
1 采用CNN-SSD的雷達高分辨距離像小樣本目標識別方法
1.1 定義目標識別小樣本訓練任務
定義小樣本目標識別模型訓練數據Dm={(X,y)},其中共有C類樣本,X為訓練集,y為標簽,通過Dm進行訓練,獲取特征提取器。該過程為
(1)
其中,Lce為交叉熵損失函數,φ為特征提取網絡參數,θ為梯度下降優化下的分類器參數。
然后,以具有閉式解的線性分類器為基學習器進行分類器訓練:
(2)
其中,θlc為具有閉式解的線性分類器參數;A為基學習器,表達式為y*=fθlc(X*),下標*表示s或q;特征提取網絡參數φ在該過程中保持不變。
(3)
其中,Lmeta為損失函數,m為平均類別準確率(Mean Class Accuracy,MCA)。
1.2 基于自蒸餾模型改進的神經網絡
基于自蒸餾模型改進的卷積神經網絡訓練過程如圖1所示,它分成兩個子過程:基模型訓練過程和子模型蒸餾提取過程。在基模型訓練環節,通過雷達高分辨距離像訓練數據Dm獲取基模型,用于子模型的蒸餾提取;在子模型蒸餾提取環節,通過對所訓練的基模型進行模型連續自蒸餾,獲得G代子模型,并以最后一代(第G代)改進的神經網絡模型作為特征提取器對非合作小樣本目標提取特征。

圖1 自蒸餾模型改進的卷積神經網絡訓練及測試流程
1.2.1 基模型訓練
(a) Softmax函數
通過式(1)的方式訓練卷積神經網絡。該過程中交叉熵損失函數通過Softmax進行計算[10]:
(4)
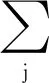
令T>1,這樣會使Softmax函數曲線更加平滑,突出了不同類別之間的相關性,同時兼顧了類別之間的絕對關系保持不變[11]。因此,以新的概率分布pi為監督信息,更易學習到性能更加魯棒的子模型。
(b) 基模型集成

(5)
其中,Φ為集成模型對樣本提取的特征向量,φi表示第i個基模型的參數。

(6)
其中,Φi和Φj分別為類別i和類別j通過集成模型所提取的特征向量。
集成后的基模型參數在以后的學習中固定不變,不再更新。
1.2.2 子模型蒸餾提取

(7)

式(7)可以進一步展開成下式:
(8)
(9)
其中,φ1為需要學習的子模型參數。
在此過程中,通過學習率自適應算法Adam優化的方法最小化LKD,從而得到的子模型稱為第1代子模型,該過程稱之為模型知識蒸餾。將分類和模型知識蒸餾的目標聯合起來,可以將第一代子模型的優化目標表示為
(10)
其中,β=1-α,表示均衡因子,用于平衡不同目標函數對模型參數學習的影響。
為了實現多代模型連續自蒸餾,進一步引入了網絡自生機制[12],對第1代子模型繼續進行知識蒸餾。以第1代子模型與第2代初始子模型的輸出類別概率分布繼續進行上述訓練過程,直至第G代,得到了第G代子模型。該過程如下:
(11)
其中,φG-1和φG分別為G-1和G代模型所學參數,f(Dm,φG-1)和f(Dm,φG)分別為G-1代和G代子模型概率分布。選擇第G代子模型為最終的特征提取器,用于對僅有少量觀測樣本的非合作目標進行特征提取。模型連續自蒸餾可以在訓練數據集上模型性能不降低的前提下迭代多代進行訓練,新代的子模型會在其上一代子模型的基礎上引入新的自由度(由初始化帶來的),因而能夠快速準確地泛化到未知的新的類別中去。在實驗中,筆者經驗性地給出了該結論成立的邊界條件。
1.3 分類器
具有閉式解的線性分類器,如支持向量機、邏輯回歸以及嶺回歸等,對于訓練樣本數稀疏的場景,它們具有易于快速優化求解的特點[9]。因此,筆者采用向量機、邏輯回歸對自蒸餾模型提取到的特征進行分類。
2 實驗結果與分析
2.1 實驗數據
為了驗證所提出的基于雷達高分辨距離像的非合作目標小樣本識別方法的有效性,首先通過三維制圖軟件構建50類飛機的3D模型;然后通過高頻電磁計算軟件對該50類飛機的模型進行電磁仿真,得到飛機目標的寬帶電磁散射數據。對該數據進行逆傅里葉變換(IFFT),進而得到飛機模型的一維距離像(HRRP)。仿真參數如表1所示。

表1 電磁散射計算參數
對50類飛機在84°俯仰角下進行電磁計算,每類目標的每個俯仰角有3 200個雷達高分辨距離像樣本,每類目標的方位角覆蓋范圍為10.05°~90°。圖2展示了50類飛機中部分飛機的三維模型及對應的一維距離像。

圖2 部分飛機目標三維模型及仿真一維距離像
為了克服雷達高分辨距離像敏感性問題,筆者參照文獻[2]對所得到的一維距離像數據進行能量歸一、重心對齊處理,得到預處理之后的一維距離像。注意,對于所使用的統計模型,筆者對上述處理過后的距離像再進行分幀,以克服姿態敏感性;對于基于深度模型的其他方法,筆者不進行此操作。
2.2 實驗設置
在模型結構及超參數設置方面,采用三層卷積神經網絡作為基礎網絡模型[13]。第1層輸入通道數為1,輸出通道數為32,步長為9;第2層輸出通道為64,步長為9;第3層輸出通道為128,步長為9。最后通過全連接層,將卷積輸出的特征轉化為向量。另一方面,設置Softmax的溫度系數T為4,并固定不變。設置式(10)~(11)中均衡因子系數α為0.4。根據1.3節的介紹,使用支持向量機和邏輯回歸作為分類器,對比分析在K等于1、5和10個樣本的條件下,非合作(庫外)目標的識別結果。
2.3 實驗結果分析
為了驗證筆者所提方法(CNNSSD-SVM和CNNSSD-Logistic模型)的有效性,將其與多個基線算法進行了定量和定性的分析比較,見表2。其中,SVM是按監督學習方式對數據進行二元分類的廣義線性分類器,其決策邊界是對學習樣本求解的最大邊距超平面[9-10]。Logistic屬于對數線性模型,其本質是假設數據服從高斯分布,然后使用極大似然估計做參數估計[10]。AGC屬于統計識別模型的一種,通過計算每類每幀樣本的均值及方差作為模板庫,對測試樣本進行匹配識別[8]。CNN-FC是利用卷積神經網絡提取特征并用全連接網絡分類的方法,該方法在測試階段在非合作目標上對全連接網絡進行微調。CNNSSD-SVM和CNNSSD-Logistic為基模型集成之后通過連續自蒸餾迭代3次,將得到的第3代子模型作為特征提取器,通過SVM和Logistic對提取的特征進行分類的方法。
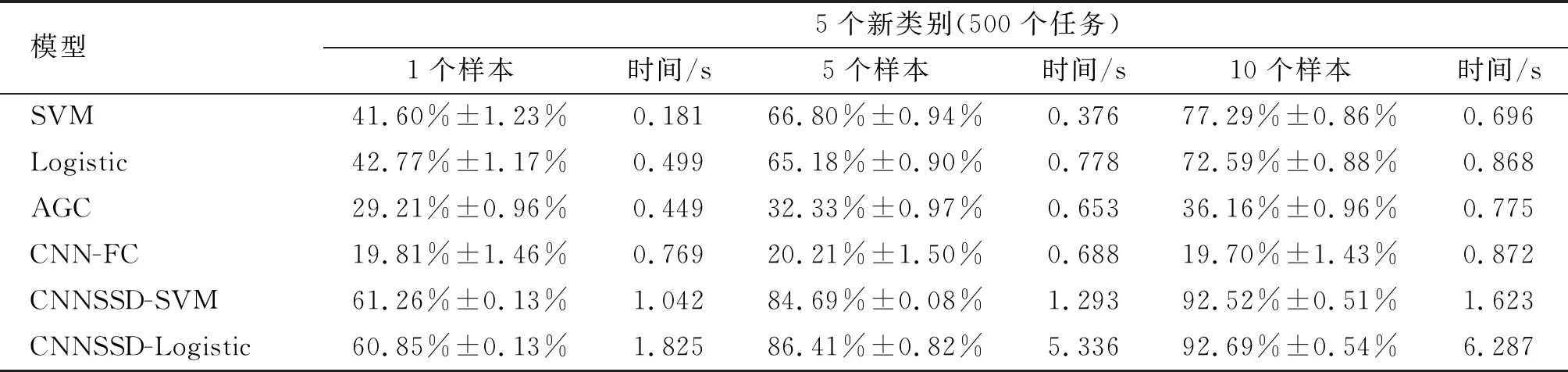
表2 小樣本識別方法準確率對比
對于識別能力而言,模型對5類飛機進行識別,不訓練模型進行隨機猜測的識別正確率應不低于20%。如表2所示,SVM和Logistic具備對非合作目標小樣本識別的能力,并且隨著樣本數增多,其識別能力提升明顯。以SVM為例,每類10個樣本時的性能較每類1個樣本的性能提高超過30%;而AGC則由于樣本維度遠高于樣本數量,導致其協方差矩陣估計較差,其性能遠低于其他兩種淺層的基線模型。CNN-FC這種基于非合作目標微調分類器的方法在每類樣本數不超過10的情況下,其識別準確率約為20%,因此不具備識別能力,說明這類具有閉式解的線性分類器(淺層模型)在小樣本非合作目標識別任務中較基于新數據微調的深度模型更魯棒。另一方面,筆者所提出的CNNSSD-SVM和CNNSSD-Logistic方法相較于淺層模型SVM和Logistic,在1個樣本的實驗中準確率分別提高了19.66%和18.08%,在5個樣本的實驗中準確率分別提高了17.62%和21.23%,在10個樣本的實驗中準確率分別提高了14.43%和20.10%。由此可見,筆者所提方法相較于SVM和Logistic方法其識別準確率更高,說明連續自蒸餾有利于模型學習到更具泛化能力的關于非合作目標的特征表示。
另一方面,筆者進行了如表3所示的消融實驗,驗證了自蒸餾模型和連續自蒸餾模型以及分類器的選擇對非合作目標小樣本識別能力的影響,共對所提方法的6種變體進行了實驗。其中,CNN-SVM和CNN-Logistic為卷積神經網絡提取特征,分別利用SVM和Logistic對所提特征進行分類。CNNKD-SVM和CNNKD-Logistic為通過模型知識蒸餾獲取特征提取器,并分別通過SVM和Logistic進行分類。CNNSSD-SVM和CNNSSD-Logistic如上所述。
如表3所示,以基于SVM分類器的3種變體為例(下面3行),在非合作目標每類帶標注訓練樣本數為1、5和10的條件下,筆者所提方法與CNN-SVM性能相比均提高2%左右,與CNNKD-SVM相比性能也均有所提升,平均漲幅在1%左右。由此可見,筆者所提方法較CNN-SVM和CNNKD-SVM更加準確。對于基于CNN的深層模型的不同變體,從模型關于新的非合作目標的識別時間上來看,筆者所提方法耗時均小于CNNKD-SVM和CNN-SVM。由此可見,筆者所提方法更加高效。

表3 小樣本識別率消融實驗
最后,通過T-SNE[6]可視化方法對5個樣本條件下訓練好的SVM、Logistic、AGC、CNN-FC、CNNSSD-Logistic以及CNNSSD-SVM模型在相應的雷達高分辨距離像測試樣本上對其預測類別分布情況進行可視化展示,從而定性地對表2得到的數值結果進行解釋。可視化結果如圖3所示,三角形、正方形、圓點、十字星和五角星這5種不同形狀分別代表5種不同類別的非合作目標的樣本點。SVM、Logistic、AGC以及CNN-FC的5類樣本點分布雜亂,聚集性弱,CNNSSD-Logistic和CNNSSD-SVM的5類樣本點分布整齊,聚集性強。因此,在非合作目標小樣本識別問題中,筆者所提方法較其他基線方法識別能力最強。

圖3 雷達高分辨距離像測試集樣本TSNE分類可視化
3 結束語
為了提高模型在小樣本條件下對非合作目標雷達高分辨距離像的泛化能力,筆者提出了一種卷積神經網絡模型連續自蒸餾(CNNSSD)的雷達高分辨距離像小樣本目標識別方法。該方法在類別多樣化的完備合作目標訓練集上學習一個基模型作為初始的特征提取器,隨后基于模型連續自蒸餾機制得到泛化能力更高效的新的特征提取器,最后使用具有閉式解的線性分類器(SVM、Logistic)進行分類識別。基于電磁仿真數據開展了實驗驗證,結果證明,利用類別多樣的完備合作目標訓練集,所提方法可以有效地提高模型對非合作小樣本目標的泛化能力,實現了對庫外樣本的快速有效識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
