互惠雙向生成對抗網絡用于跨模態行人重識別
2021-04-30 02:16:30魏梓鈺王楠楠高新波
西安電子科技大學學報 2021年2期
魏梓鈺,楊 曦,王楠楠,楊 東,高新波
(1.西安電子科技大學 通信工程學院,陜西 西安 710071;2.西安空間無線電技術研究所,陜西 西安 710100;3.重慶郵電大學 圖像認知重慶市重點實驗室,重慶 400065)
隨著人們對社會公共安全的日益關注,大量監控攝像頭被部署在公共場所中以實現對高威脅人群的實時監測。行人重識別旨在利用計算機視覺技術在多個攝像頭下檢索特定的監控行人圖像。近幾年已有大量基于深度學習的方法在可見光行人重識別方向取得重大進展[1]。然而,現實中多數惡性事件易發生在夜間弱光條件下。為了保證對危險人員的全天時監控,紅外攝像頭被廣泛應用于夜間場景中[2],將其與可見光攝像頭聯合,可實現對危險人群的追蹤與抓捕。如何從可見光(或紅外)攝像頭下檢索紅外(或可見光)攝像頭下的特定行人圖像,即跨模態行人重識別,對于我國安防智能化建設具有重要的研究意義。可見光與紅外圖像存在明顯的差異:可見光圖像為三通道圖像,包含豐富的顏色信息;而紅外圖像為單通道灰度圖像,缺少顏色信息。跨模態行人重識別的難點不僅體現在異質圖像巨大的跨模態差異,也體現在相同模態不同攝像頭下由于光線、視角變化引起的行人圖像差異。
為了促進跨模態行人重識別課題的研究,WU等[3]利用4個RGB可見光攝像頭和2個紅外攝像頭對491個行人進行多時段多場景拍攝,構建了大型可見光-紅外行人數據集SYSU-MM01。韓國東國大學NGUYEN等[4]采用可見光-熱成像雙目攝像頭在同一場景下對412個行人成像并構建RegDB數據集,兩個數據集的提出促進了跨模態行人重識別的研究進展。為了提升跨模態行人重識別的準確率,文獻[3]設計了一種深度零填充的方法,但該方法僅使用身份損失進行訓練,從而限制了特征的辨識力。文獻[5]提出了一種雙流卷積神經網絡,并采用雙向抑制排序損失和身份損失同時約束網絡,以學習到更加具有區別性的特征。文獻[6]充分考慮了分類子空間與特征嵌入子空間的關聯性,并提出一種端到端的雙流超平面多嵌入網絡來學習異質行人圖像的共享特征。然而,上述方法并不能完全將異質行人特征映射到同一子空間,從而影響了跨模態行人重識別系統的性能。另外,有一些工作是利用生成對抗網絡[7]生成偽異質圖像以消減模態差異。文獻[8]采用熱生成對抗網絡框架將RGB圖像轉換為熱紅外圖像,該框架可以實現視頻監控下可見光與紅外圖像的相互匹配。文獻[9]提出了一種新穎的對抗學習方式來學習具有辨別力的特征表示。文獻[10]利用循環生成對抗網絡(CycleGAN)[11]生成跨模態圖像,然后構建了自注意力模態融合網絡,增強了特征區分能力;但生成的圖像質量較差,影響了跨模態行人重識別的性能。文獻[12]提出一種減少雙極差的學習方式來約束異質圖像的表征差異以及模態差異,并取得了較好的效果。然而這些方法僅使用生成對抗網絡,并沒有考慮生成過程中隱藏特征的關聯性,因此,限制了神經網絡學習共享特征的能力。
為此,筆者提出一種新穎的互惠雙向生成對抗網絡,以提升跨模態行人重識別的準確率。該網絡由兩個結構對稱的圖像轉換子網絡組成,分別用于可見光圖像生成紅外圖像,以及紅外圖像生成可見光圖像。為了使生成的異質圖像更接近于真實圖像,提出一種聯合損失函數拉近圖像轉換過程中兩個隱藏空間的特征分布,建立兩個不相關單向生成網絡的相互作用關系,使生成的圖像既保留行人身份信息,又接近于真實圖像風格。通過將原始圖像與生成的異質圖像相結合進行區別性特征提取,能夠抑制模態差異,實現模態統一,得到更具有判別性的行人特征。
1 異質圖像轉換網絡
給定一組可見光圖像V和一組紅外圖像I,網絡將在可見光和紅外行人圖像之間學習兩組映射關系,即G:VI和F:IV。不同于其他方法,直接利用變自分編碼器或生成對抗網絡將紅外或可見光圖像映射到同一空間中,文中將為每組映射構建兩個子生成器,并探索在生成圖像過程中隱藏空間特征的分布,引入一種新穎的關聯損失來拉近兩個映射中間特征的距離,約束潛在空間的特征分布。因此,中間圖像在分布上具有高度相似性,從而驅動網絡最終生成的異質圖像更接近于真實圖像。
1.1 圖像轉換網絡結構
圖像轉換網絡由兩個單向對稱的子網絡組成,每個子網絡包含兩個子生成器和一個判別器。生成器G將可見光圖像v轉換為對應的紅外圖像i,G由G1和G2構成,分別用于生成中間特征表示以及最終的偽紅外圖像。生成器F由F1和F2構成,用于將行人圖像由紅外模態轉換為可見光模態。另外,判別器Dv和DI用于辨別圖像是原始圖像還是生成的偽異質圖像。子生成器G1、G2、F1和F2具有相同的網絡結構,包含兩個步長為2的下采樣,9個殘差模塊,以及兩個步長為1/2的上采樣。生成器G的網絡結構如圖1所示,F的結構與其相同。由于子生成器的輸入與輸出圖像具有相同的尺寸,因此實現了原始圖像、中間圖像以及生成圖像之間的像素對齊。判別器Dv和DI采用PatchGAN[13]的網絡結構,包含5個卷積層,4個線性整流(Leaky ReLU)層以及3個歸一化層(Batch Normalization,BN)。由于該結構參數較少,因此具有較快的運行速度。

圖1 圖像轉換網絡結構圖
1.2 目標函數
對于兩個單向的圖像轉換網絡,為了保證生成的異質圖像能夠保留更多的邊緣信息,引入圖像重構損失來引導輸出圖像的分布接近目標分布。圖像重構損失可以表示為
Lrec(G,F)=Ev,i[‖G(v)-i‖1]+Ev,i[‖F(i)-v‖1] ,
(1)
其中,G(v)和F(i)表示由生成器生成的偽異質圖像,i和v為真實圖像。通過減小生成圖像與真實圖像的L1距離,驅使生成器生成更逼真的異質圖像。
為了確保生成的圖像再次經過生成器后能夠輸出與原始圖像分布相近的圖像,引入循環一致性損失來拉近數據分布。循環一致性損失可表示為
Lcyc(G,F)=Ev~pdata(v)[‖F(G(v))-v‖1]+Ei~pdata(i)[‖G(F(i))-i‖1]。
(2)
循環一致性損失可以將生成的紅外(可見光)圖像再重新轉換回原始的可見光(紅外)圖像,因此實現了圖像分布匹配。
由于兩個單向的圖像轉換網絡之間參數不共享,生成的中間圖像和最終圖像由圖2(a)所示。兩個相互獨立的網絡生成的圖像只能由圖像重構損失和循環一致性損失約束,故隱藏空間的圖像差異較大,且最終生成的異質圖像易受噪聲影響。因此,引入一種聯合損失來拉近隱藏空間特征分布,聯合損失可表示為
Lass(G,F)=Ev,i[‖G1(v)-F1(i)‖1]+Ev,i[‖G1(F(i))-F1(G(v))‖1] ,
(3)
其中,G1試圖生成與F1生成的中間圖像具有相似分布的中間圖像。另外,在F1和G1將生成圖像反向轉換為原始圖像時,也同時拉近隱藏空間特征的分布。如圖2(b)所示,經過聯合損失的約束,使得兩個網絡相互作用,生成具有相似分布的中間特征,引導生成器產生高質量且更加逼真的異質圖像。

圖2 加入聯合損失前后對比圖
除了生成器生成以假亂真的圖像外,引入判別器并設計對抗損失來判別圖像是否為真實圖像。對于映射函數G:VI以及它的判別器DI,將目標函數定義為
LGAN(G,DI,V,I)=Ei~pdata(i)[logDI(i)]+Ev~pdata(v)[log(1-DI(G(v)))],
(4)
對于映射函數F:IV和它的判別器Dv,對抗損失LGAN(F,Dv,I,V)可以表示成相似的形式。生成器試圖生成接近于真實圖像的偽圖像來欺騙判別器,而判別器試圖拉大生成圖像與真實圖像的分布,從而正確地判斷圖像是否真實。生成器與判別器相互博弈,其目標函數表示為
L(G,F,Dv,DI)=Lrec(G,F)+Lcyc(G,F)+Lass(G,F)+LGAN(G,DI,V,I)+LGAN(F,DV,I,V) ,
(5)
基于上述整體損失函數,交替訓練生成器與判別器,博弈式訓練過程可以表示為
(6)
通過上述函數優化,即可生成紋理清晰、視覺效果逼真的異質行人圖像。
2 區別性特征提取


圖3 區別性特征提取網絡結構圖
2.1 區別性特征提取網絡結構
利用ResNet-50作為特征提取網絡的骨干。另外,修改了第5個卷積層并將步長改為1。對于ResNet-50輸出的2 048 維特征圖,利用全局平均池化得到特征向量;對其進行批歸一化操作后,可以輸入至全連接層進行表征學習。在度量學習時,直接利用批歸一化之前的特征向量計算歐氏距離并拉近類內間距;在測試階段,依然利用原始圖像和生成圖像的組合進行行人檢索,得到最有利的判別性特征。
2.2 目標函數
為了獲得每個行人的特有特征,引入身份分類損失來增強判別性。身份損失可以表示為
(7)
其中,N為訓練時一批次圖像的數量,C為行人身份類別數,zj為全連接層第j個神經元的激活值,yi為圖像的標簽即行人身份。另外,引入度量損失來拉近相同行人特征之間的距離并拉遠不同行人特征之間的距離。度量損失可以表示為
(8)
其中,ρ為預定義的邊界值,fa、fp代表相同身份的行人特征,fa、fn代表不同身份的行人特征。d(fa,fp)為正樣本之間的歐氏距離。故區別性特征提取網絡的目標函數可以表示為
Loverall=Lid+Lmetric。
(9)
經過行人表征學習以及度量學習,區別性特征提取網絡能夠提取到每個行人單獨具備的特征,提高特征判別性并緩解類內差異。
3 實驗結果與分析
3.1 數據集及實驗設置
在SYSU-MM01和RegDB兩個公開數據集上進行實驗。SYSU-MM01數據集由兩個紅外攝像頭和四個可見光攝像頭拍攝的491個行人的圖像組成,訓練集包含395個行人的22 258張可見光圖像和11 909張紅外圖像;測試集中96人的3 803張紅外圖像用于檢索,6 775張可見光圖像為數據庫。論文采用最具挑戰性的single-shot all-search模式進行實驗來驗證提出方法的有效性。RegDB數據集由雙目攝像頭拍攝的412個行人的圖像組成,每個行人包含10張熱紅外圖像和10張可見光圖像;筆者對每個數據集進行10次實驗并取平均值以獲得穩定的實驗結果,采用累積匹配特性曲線(CMC)和平均精度均值(mAP)來進行測評。
用Pytorch框架在TITAN RTX GPU上實現了所提出的方法,在訓練圖像轉換網絡時,將批量大小設為4,每個行人包含1張紅外圖像和1張可見光圖像,一批次包含兩個行人。實驗在SYSU-MM01數據集上訓練20 000次,在RegDB數據集上訓練10 000次,學習率為0.000 2。在訓練區別性特征提取網絡時,固定圖像轉換網絡的參數。每個批次圖片包含16個行人,每個行人設置兩張紅外圖像和兩張可見光圖像。實驗在兩個數據集上進行120輪訓練,設定初始學習率為0.000 35并且在訓練40輪后變為原始的1/10。在度量學習中的參數ρ設置為0.3。
3.2 消融實驗
為了驗證所提出方法中所有損失函數的有效性,在SYSU-MM01數據集上利用不同的損失函數進行訓練并比較測試結果。如表1所示,在圖像轉換階段,使用圖像重建損失和聯合損失而不使用循環一致性損失,實驗得到的CMC-1準確率只能達到34.65%,比使用循環損失降低了8.39%,這說明循環一致性損失在圖像生成過程中起到重要的作用,能夠建立生成圖像與原始圖像的聯系,保證生成圖像的質量。另外,加入聯合損失拉近中間特征的分布后,跨模態行人重識別的CMC-1準確率提升了3.60%,平均精度均值提升了3.31%,因此,驗證了所提出的聯合損失的有效性;在區別性特征提取階段,網絡主要利用分類損失和度量損失進行學習。由于SYSU-MM01數據集中的行人圖像由不同場景的攝像頭采集,圖像分辨率、行人姿態差異較大,所以僅依賴度量損失難以將同一行人特征拉近,將不同行人的特征距離拉遠,mAP僅有5.44%。而僅使用分類損失,網絡能夠學習到不同行人的大部分特有特征,CMC-1準確率可以達到32.29%。在同時使用兩種損失函數后,CMC-1準確率增長了10.75%。通過此消融實驗,驗證了方法中所有目標函數的有效性。

表1 不同目標函數組成下SYSU-MM01數據集的準確率 %
另外,圖4展示了異質圖像生成過程中兩條網絡的中間層圖像距離分布,由分布圖可以直觀的看出,在加入聯合損失前,中間圖像的特征差異大,距離遠;在經過聯合損失拉近特征分布后,中間圖像的距離大部分控制在100以內,距離得到明顯縮減,因此,進一步驗證了聯合損失的有效性。

圖4 中間層圖像距離分布圖
注:√表示包含損失;×表示不包含損失
3.3 與跨模態行人重識別現有方法對比實驗
為了驗證文中所提出方法的有效性與優越性,本節將與現有的跨模態行人重識別方法進行對比。這些方法包括傳統的非深度學習方法(LOMO[14],HOG[15])、深度特征學習法(One-stream,Two-stream,Zero-padding[3])、特征距離度量學習法(BDTR[5],D-HSME[6])以及基于生成對抗網絡的方法(cmGAN[9]、D2RL[12]、自注意力模態融合[10])。在數據集SYSU-MM01和RegDB上的比較結果如表2所示。LOMO、HOG等傳統的特征提取方法由于難以提取到有效的判別性特征,所以行人重識別的準確率很低,CMC-1和mAP均不高于5%。在基于深度學習的方法中,One-stream,Two-stream以及Zero-padding方法只進行表征學習,限制了特征學習的能力。對于雙流網絡BDTR和D-HSME,它們通過兩條網絡分別提取可見光與紅外模態的特有特征,再利用全連接層獲取模態共享特征,另外加入了度量學習法,所以D-HSME相比于只使用表征學習的Zero-padding方法,CMC-1準確率提升了5.88%。基于生成對抗網絡的方法將可見光或紅外圖像轉換成另一模態圖像,削弱了模態差異,將圖像統一至同一模態。因而基于自注意力模態融合方法的mAP,相比D-HSME增長了10.06%。文中提出的方法不僅采用生成對抗網絡,并且充分考慮生成過程中隱藏空間特征并拉近特征分布,因此CMC-1準確率和mAP可以分別達到43.04%、55.58%,超過自注意力模態融合法9.73%、22.4%,驗證了該方法的優越性。

表2 文中方法與其他方法在SYSU-MM01和RegDB數據集上的CMC和mAP準確率 %
為了形象地展示文中提出方法的檢索結果,將SYSU-MM01和RegDB數據集的部分檢索結果可視化,可視化結果如圖5所示。利用圖像轉換網絡生成與查詢庫中紅外圖像所對應的可見光行人圖像,然后將兩幅圖結合起來進行檢索。同樣地,在待搜索的數據庫中,將原始的可見光圖像與生成的紅外圖像相結合。實線框和虛線框分別表示檢索成功和檢索失敗的行人圖像。文中方法可以檢索到大部分相同身份的行人,但對于具有相似體型和穿著的人容易被錯檢。
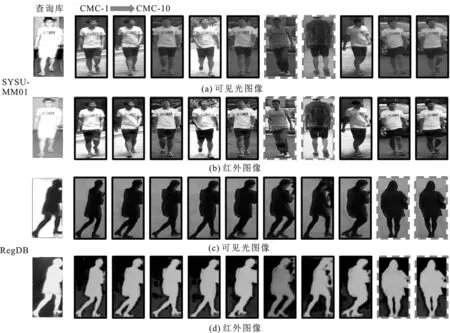
圖5 文中方法在SYSU-MM01和RegDB數據集的可視化結果
4 結束語
筆者提出一種基于互惠生成對抗網絡的跨模態行人重識別方法,該方法由圖像轉換網絡與區別性特征提取網絡組成。在圖像轉換過程中設計一種新穎的聯合損失來拉近隱藏空間特征分布,促使生成的異質行人圖像能夠保留原始行人圖像的身份,同時接近于真實異質圖像風格。在區別性特征提取階段,將原始圖像與生成圖像結合作為輸入圖像,從而消減跨模態差異,使網絡更加關注不同行人之間的特有特征,學習到具有判別性的信息,提高跨模態行人重識別的準確率。通過在跨模態公開數據集SYSU-MM01和RegDB上進行消融實驗以及與其他方法的對比實驗,驗證了所提出方法的有效性。在今后工作中,將改進生成對抗網絡結構,以生成更高質量的異質圖像,進一步提升跨模態行人重識別的準確率。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
