基于屬性基隱私信息檢索的位置隱私保護方法
2021-05-06 12:10:58杜剛張國印
哈爾濱工程大學學報 2021年5期
杜剛, 張 張國印
(1.哈爾濱工程大學 計算機科學與技術學院,黑龍江 哈爾濱 150001; 2.佳木斯大學 信息電子技術學院,黑龍江 佳木斯 154007; 3.山東科技大學 計算機科學與工程學院,山東 青島 266590)
隨著基于位置服務(location based service, LBS)的廣泛應用,越來越多的人們開始關注該服務中的隱私泄露問題[1-2]。當前較為普遍的隱私保護方法有泛化[3- 4]、模糊[5-6]、加密[7-8]以及空間變換[9]等,但上述方法都面臨同樣的問題,即在LBS服務器提供服務的過程中不可避免地要獲知用戶的真實意圖,進而可根據諸如興趣點類型、查詢種類等信息分析獲得用戶隱私。隱私信息檢索(private information retrieval, PIR)是應對這種潛在隱私泄露的有效辦法[10-11]。該方法對LBS服務器中的數據加密,通過二進制的可計算PIR和硬件PIR實現零信息泄露的結果檢索。Wightman等[12]根據這一觀點,基于經緯度的地理差異,提出了基于地圖查詢的PIR。楊松濤等[13]基于該技術建立了基于位置服務的盲查詢方法。
但是,由于基于位置服務本身的特性,使得這種以索引為基礎的隱私信息檢索在執行過程中需搜尋較大規模的數據條目,這增加了反饋結果的處理時間,影響了服務質量[14]。Hu等[15]提出用分層索引提升索引效率。Yi等[16]則提出了模糊索引的概念。通常情況下,基于位置服務是一種針對用戶提交信息進行反饋的服務,其反饋結果主要針對用戶屬性信息獲得的查詢結果[17-18]。因此,使用屬性作為索引進行隱私信息檢索將會減少處理數據量,提高檢索效率,減少對服務質量的影響。基于上述觀點,本文基于屬性基加密提出了一種可應用于位置隱私保護的屬性基PIR方法,該方法在有效的保護用戶隱私信息的同時,能給提供比索引為基礎的隱私信息檢索方法更好的服務質量。最后,通過安全性分析和比較實驗,進一步證明本文所提出的方法在隱私保護能力方面和算法執行效率方面的優越性。
1 隱私保護相關定義
1.1 系統架構及攻擊假設
與傳統隱私保護方法不同,基于隱私信息檢索的位置隱私保護方法并不需要可信或非可信第三方,因此該方法采用如圖1所示的二層系統架構。

圖1 二層系統架構示意Fig.1 The system structure of two entities
從圖1中可以看出,該架構中存在2個實體,即用戶和LBS服務器。用戶是指在固定位置或移動過程中,通過自身設備向LBS服務器請求服務的使用者;而LBS服務器是在獲得用戶請求信息后向用戶提供服務結果的服務提供者。通常,LBS服務器由政府或大型企業提供因此是真實可信的,但所有信息均由該實體處理,使得該實體易成為攻擊焦點,且在巨大商業利益誘惑下存在泄露用戶隱私的可能。因此,本文假設該實體為半可信實體,既能夠提供位置服務,又可對用戶隱私信息進行收集并分析,因此需將用戶信息隱藏防止LBS服務器獲得用戶隱私。
1.2 隱私保護需求
針對1.1中給出的以LBS服務器為潛在攻擊者的攻擊假設,若需保護用戶的隱私信息,在整個基于位置服務的過程中需降低對LBS服務器的信息公布量,同時還需要獲得所需要的查詢服務結果。因此,基于用戶屬性特點,有如下隱私保護和服務需求:
1) LBS服務器無法準確識別由用戶查詢信息轉化的屬性信息;
2) LBS服務器能夠根據用戶提交的加密查詢信息反饋查詢結果;
3) 隱私處理以及服務獲取過程應在用戶可接受時間范圍內完成。
基于上述需求,本文設計并提出了隱私保護方法。
2 屬性基PIR方法及算法
2.1 屬性基PIR方法
通常,用戶請求基于位置服務反饋時需向LBS服務器提交查詢,該查詢一般為:距離我最近的飯店、當前道路上的加油站或者到某酒店的最短路程等。這些信息可形式化為Q={(x,y),t,c},其中(x,y)為用戶所在位置,t為提出查詢的時間,c為查詢的內容。因此,上述信息可以用用戶屬性加以代替,即存在用戶屬性A={A1,A2,…,An}中的每一個屬性對應查詢中的一個形式化表述內容。因此,上述查詢的隱私保護可轉換為用戶屬性隱私信息檢索,并解密反饋信息的處理過程。這一過程可表示為如圖2所示的LBS服務器和用戶之間的信息傳遞協議。
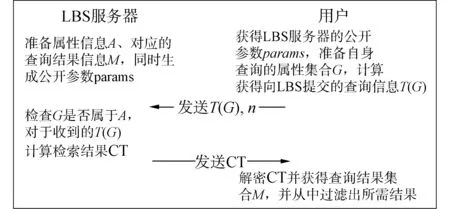
圖2 屬性基PIR傳遞協議Fig.2 The protocol of attribute based PIR
2.2 屬性基PIR方法執行過程
按照屬性基PIR的處理協議,隱私檢索方法存在2個處理階段,分別為LBS服務器信息處理和用戶信息處理。為便于對屬性PIR的理解,本文借鑒文獻[12]所提供的隱私信息檢索方法,將這2個階段按照時間順序加以表述。為便于理解,表1給出了屬性PIR處理中所使用的參數及所表示的含義。
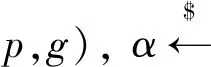
式中:g是G的生成器,G是p階大素數循環群,F(·)是多項式時間概率算法。
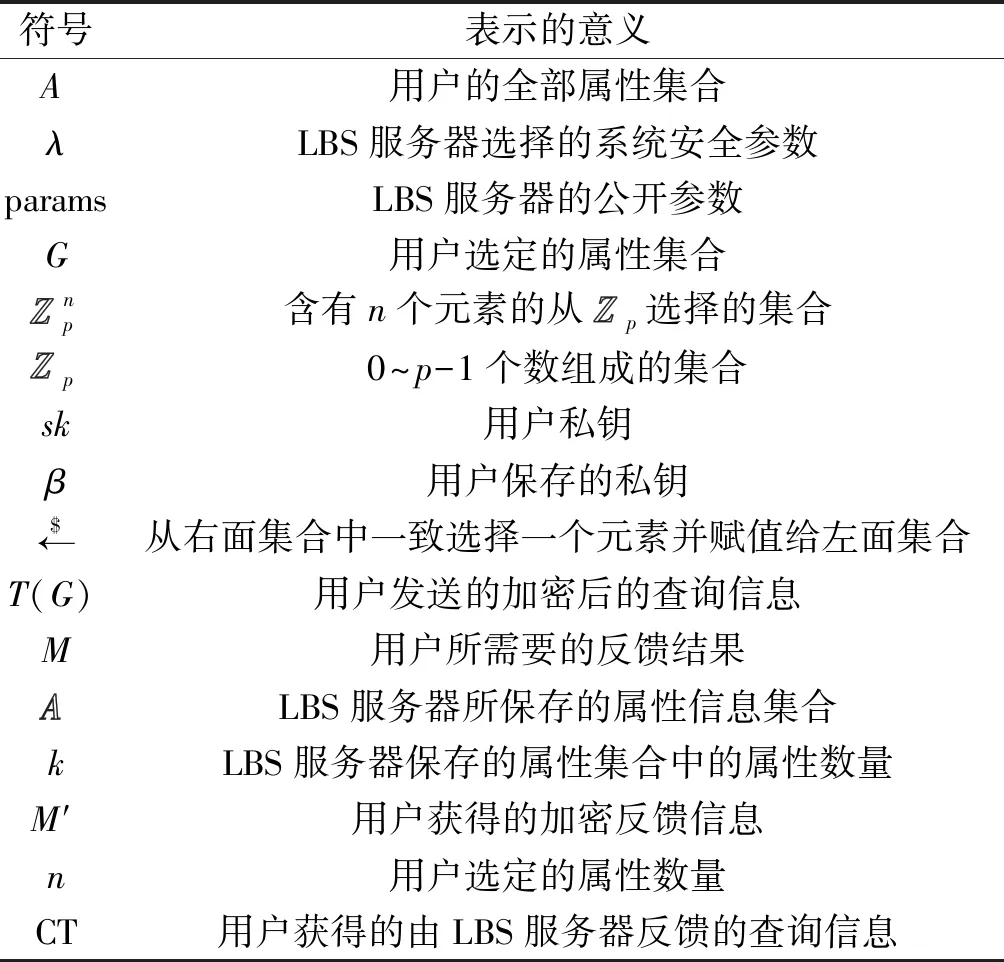
表1 屬性PIR所涉及的參數Table 1 Parameters used in attribute based PIR
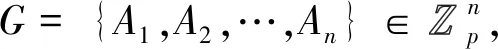
h←gβ
對于每個i分別計算:
ui←g1hri,vi←gri,Xi←gsi,Yi←gti

算法1用戶加密查詢處理
輸入:用戶查詢信息轉換后的屬性信息G和私鑰β←Zp
輸出:加密后的用戶查詢信息T(G)
2 計算h←gβ;
3for(i=1,i<=n,i++)
4ui←g1hri,vi←gri;
5Xi←gsi,Yi←gti;
9end
10returnT(G)={Ui,Vi,Xi,Yi};
算法1中,第3~9行通過for循環實現對每個屬性對應的查詢進行加密,并獲得加密查詢信息T(G),該過程若不考慮累乘其時間復雜度為O(n),但在算法的6~8行對屬性信息進行了累乘計算,因而實際的時間復雜度將達到O(n2)。
當LBS服務器收到用戶發送的T(G)時,對于保存的興趣點數據M,以及數據屬性A,|A|=k,LBS服務器完成如下計算:
同時計算:
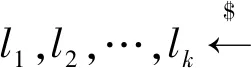
C3=Wt·M
LBS服務器獲得加密信息CT=(C0,C1,C2,C3),并將其發送給用戶。上述處理可表示為如算法2所示的計算處理過程。
算法2LBS服務器進行隱私信息檢索
輸入:用戶提交的加密查詢信息T(G)
輸出:LBS服務器基于屬性PIR處理后的加密查詢結果CT。
1for(i=1,i<=k,i++)
2 計算Pi,Qi,Wi;
3end
4 隨機選擇l1~lk,t;
5 累乘計算P和W;
6 計算C0,C1,C2,C3;
7returnCT=(C0,C1,C2,C3);
算法2通過for循環對LBS服務器內保存的所有屬性處理后獲得反饋的查詢結果,并向用戶發送含有n個屬性的查詢結果集合。此時,for循環的規模遠大于算法1中的for循環,即k?n。此時算法2的時間復雜度為O(k)+O(n)=O(k)。
用戶在收到由LBS服務器發送過來的信息CT后,計算:
((gt·∑i∈Aηili)-β·(gt·∑i∈Arili·ht·∑i∈Aηili))-β·
(gt·∑i∈Aθili)-β·gt·∑i∈Aβrili·ht·∑i∈Aθili·M=M
由此可在M中過濾出所需要的查詢信息。最后對CT的處理過程可簡化為算法3所示的處理過程。
算法3加密反饋信息解密
輸入:LBS服務器反饋的加密查詢結果CT;
輸出:明文M′。
2returnM′;
算法3對每個屬性信息進行了累加計算,處理后獲得針對用戶提交屬性的查詢結果信息。該算法的時間復雜度為O(n)。
綜上,經過3個算法的處理實現了屬性基PIR的處理過程,用戶可通過秘密的信息檢索過程獲得所需的查詢反饋。
3 性能評估
3.1 隱私保護和可用性分析
屬性基PIR的安全性取決于LBS服務器無法準確識別由用戶查詢信息轉化的屬性信息。其可用性取決于對查詢結果的準確反饋以及在有效的時間內的計算處理。
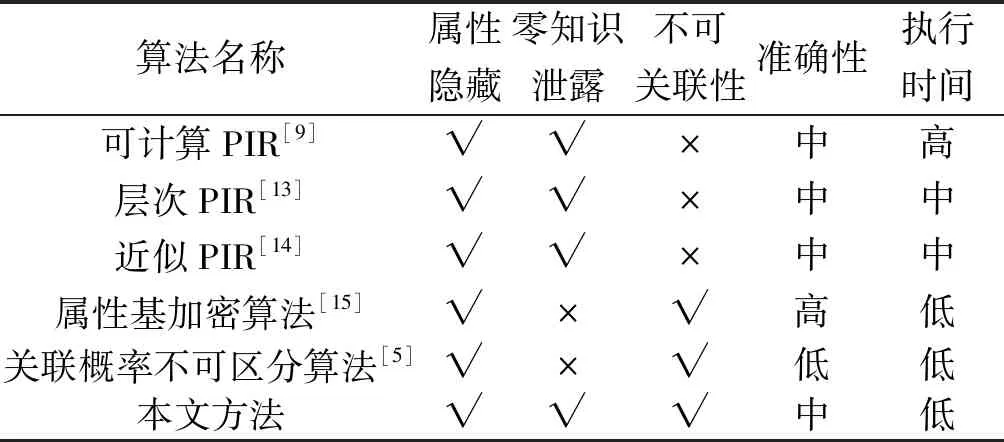
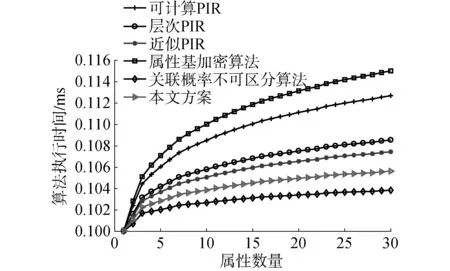
為進一步說明本文所提出算法的隱私保護能力,設存在一個在挑戰者A和用戶U之間的博弈來證明隱私保護強度。假設挑戰者A準備了2組屬性(a1,a2),并將這2個查詢發送給用戶U。U隨機選擇c∈(1,2)并表示為ac,同時將2組屬性加密,然后將任意一組屬性M發送給挑戰者A。如果挑戰者A能夠計算得出c′ 滿足p(ac′)≠p(ac),則A獲勝。若A獲勝,則需對于任意一組屬性,存在p(ai∈ac|ac∈M)≠p(aj∈ac|ac∈M)?(0 對于另一組屬性,有: 在本文算法的處理下,攻擊者可獲得的是加密后的屬性信息,在不能獲得解密密鑰的前提下,攻擊者只能進行猜測,此時2次猜測成功的概率彼此相等,有pi=pj,?(0 通過上一節給出的屬性基PIR在隱私保護和可用性方面的理論分析可知,該算法能夠保障用戶的隱私且具有良好的執行效率。本節將通過與其他幾種基于位置服務的隱私保護算法之間的對比,進一步證明所提出方法的優越性。參與比較的算法有:基于索引的可計算PIR[10],基于分層索引的層次PIR[15],基于模糊索引的近似PIR[16],基于屬性泛化的屬性基加密算法[17]以及基于屬性模糊的關聯概率不可區分算法[5]。實驗將使用北京出租車行駛數據,并在Intel Core i5 1.70 GHz CPU、4gb RAM筆記本電腦上利用Matlab R2017a在Windows 7×64操作系統上完成測試,所有結果均是取計算500次后的平均值作為比較結果并繪制完成結果圖。 表2給出了幾種算法在不同安全環境下、查詢準確性以及算法運行時間上的效果比較。 表2 不同算法效果比較Table 2 The comparison effects of different algorithms 圖3給出了幾種不同算法在屬性數量變化下的攻擊者猜測成功概率。從該圖中可以看出,本文方法因使用屬性基PIR,所以隨屬性增加,攻擊者攻擊成功的概率變化不大。同樣使用PIR技術的可計算PIR、層次PIR以及近似PIR等3種方法的攻擊成功概率也變化不大,這是因采用PIR索引差異導致的攻擊效果差異。而屬性基加密算法,盡管采用屬性加密來防止屬性被攻擊者識別,但該算法一方面需提交用戶真實位置,導致被識別的概率高于PIR;另一方面隨著屬性數量的增加,其保護性逐漸降低,因此其攻擊成功率要高于上述幾種基于PIR的算法。最后,關聯概率不可區分算法采用的是位置模糊,并未對用戶的屬性信息加以保護,其被攻擊者有效識別的概率高于其他算法,攻擊成功率最高。 圖4給出了幾種不同算法在查詢次數變化下的攻擊成功概率。從該圖中可以看出,隨著查詢次數的增加,所有算法都不可避免地存在更高的被攻擊者識別的概率。這是因為隨著查詢次數的增加,用戶將暴露更多的潛在信息給LBS服務器,這些信息可作為背景知識被攻擊者所利用,進而提升攻擊成功率。在這些方法中,本文方法因采用屬性基PIR,其被暴露屬性的可能性較低,攻擊者利用屬性關聯獲取用戶隱私信息的成功率要低于其他PIR算法。而其他PIR算法,諸如計算PIR、層次PIR以及近似PIR等3種方法,由于采用加密技術,使得可暴露的信息量要少于泛化或模糊的算法,因此其攻擊成功率要低于屬性基加密算法和和關聯概率不可區分算法。最后,屬性基加密算法可針對的屬性要高于關聯概率不可區分算法,其攻擊成功率要低于關聯概率不可區分算法,而關聯概率不可區分算法則是幾種算法中最易被攻擊者攻破并獲取用戶隱私信息的算法。 圖3 不同算法的攻擊成功概率vs.屬性數量Fig.3 The success ratio of guessing the privacy vs. the number of attributes 圖4 不同算法的攻擊成功概率vs.查詢次數Fig.4 The success ratio of guessing the privacy vs. the number of requests 圖5給出了幾種不同算法在屬性數量變化下的算法執行時間差異。從該圖中可以看出,所有算法的執行時間均隨用戶屬性數量的增加而增長,這是因為屬性加密算法以及其他算法,都需對增加的屬性進行加密、泛化或模糊處理,上述過程增加了處理時間。在這些算法中,本文算法由于采用了屬性基檢索,其執行時間要低于采用索引檢索的PIR算法,且由于對多個屬性同時加密,其執行時間要低于用戶協作的屬性基加密算法,僅高于采用偏移的關聯概率不可區分算法。其他幾種PIR則按照可計算PIR,層次PIR以及近似PIR的順序,其算法執行時間相應減少。 圖5 不同算法的算法執行時間vs.屬性數量Fig.5 The running time of various algorithms vs. the number of attributes 圖6給出了不同算法在查詢次數變化下的算法執行時間差異。從該圖可看出,隨查詢次數的增加,所有算法的執行時間均逐漸增長,這是由于每次查詢需重新執行隱私保護算法,其執行時間隨查詢次數逐漸增加。本文方法由于采用屬性基檢索,其算法處理步驟相對較少,因而其執行時間最少。而屬性基加密算法由于采用協作用戶提供查詢結果,因此在多次查詢的情況下,其算法執行時間稍高。關聯概率不可區分算法需要計算各位置間的關聯概率,且需要滿足差分隱私約束,因而其執行時間要高于前2個算法。最后,計算PIR、層次PIR以及近似PIR則按照索引執行的難易程度,其算法執行時間依次增加。 圖6 不同算法的算法執行時間vs.查詢次數Fig.6 The running time of various algorithms vs. the number of requests 綜上,可認為本文所提出的屬性基隱私信息檢索方法在安全性和算法執行效率等方面要優于其他同類算法。 1) 通過安全性和性能分析以及同類算法的對比實驗,可認為本文所提出的方案具有更好的隱私保護能力和算法執行效率。 2) 在研究過程中還發現,這種基于加密手段的隱私保護算法其計算時間仍高于匿名策略的隱私保護算法,但其隱私保護能力更高。所以,本文所提出的方案更適合在一些計算能夠較強的移動設備上使用。 由于本文方案是利用移動用戶屬性完成的隱私信息檢索,今后的工作將在較少屬性范圍內的特征屬性匹配檢索方面展開,以進一步減少算法執行時間。3.2 實驗設定
3.3 測試結果及分析



4 結論
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31商用汽車(2016年11期)2016-12-19 01:20:16新聞傳播(2016年18期)2016-07-19 10:12:06商用汽車(2016年6期)2016-06-29 09:18:54商用汽車(2016年4期)2016-05-09 01:23:12現代計算機(2016年11期)2016-02-28 18:35:15創業家(2015年5期)2015-02-27 07:53:25中外會展(2014年4期)2014-11-27 07:46:46河南科技(2014年11期)2014-02-27 14:10:19圖書館界(2013年5期)2013-03-11 18:50:29
