基于綜合指標多階段相似的發動機壽命預測
2021-05-06 10:16:38趙洪利陳天銘
系統工程與電子技術 2021年5期
趙洪利, 陳天銘, 鄭 涅
(中國民航大學航空工程學院, 天津 300300)
0 引 言
當前,在航空發動機的維修中,預測與健康管理(prognostics and health management,PHM)技術發揮著重要作用,能夠通過傳感器收集到的數據,進行航空發動機在翼剩余使用壽命(remaining useful life,RUL)預測和健康管理,指導發動機維修。這不僅可以有效地保障飛機的飛行安全,還可用于規劃發動機維修,降低維修成本,幫助航空公司實現經濟性,安全性目標[1]。
發動機RUL預測是一種預測發動機未來故障時間或維持正常運行剩余時間的技術[2]。該技術能夠在發動機出現故障之前預留足夠的時間,同時獲取可靠的維修策略[3]。因此,在RUL預測領域,準確可靠的預測方法至關重要[4-5]。當前發動機RUL預測主要分為3類:基于物理失效模型的方法、基于數據驅動的方法和混合方法[6]。目前的研究方向主要集中在基于數據驅動的方法。因為該方法更容易實現,有較為準確的預測,而且能夠通過各種傳感器收集的監視數據來代替系統退化的物理知識[7]。
基于退化建模和回歸預測是數據驅動方法的主要研究方向。文獻[8]基于歐氏距離綜合多源數據,通過非線性漂移Wiener過程預測RUL。文獻[9]采用基于多階段Wiener過程的正態總體均值和變異系數一致性檢驗的方法進行剩余壽命預測。文獻[10]提出一種整合自編碼神經網絡和雙向長短期記憶神經網絡優勢的混合健康狀態預測模型,優化渦扇發動機的剩余使用壽命預測。文獻[11]基于改進的門控循環單元進行預測,克服傳統門控循環單元型在處理多狀態參數時的重復建模問題。
另外,在數據驅動方法中,還可以利用樣本的退化特征相似性進行RUL預測。該方法的思路是,通過判斷兩個樣本的變化軌跡相似度,判斷兩者是否有相似的運行循環。文獻[12]提出基于相似性的壽命預測方法,該方法比神經網絡等方法有更好的預測效果。文獻[13]通過聚類融合多個參數建立健康指標,使用相關向量機進行建模,最后使用多模型相似性進行預測。文獻[14]采用低維正交多變量特征進行相似性匹配,融合最相似的一組RUL信息實現預測,并且有較好的預測效果。文獻[15]平移樣本的變化軌跡進行相似性匹配,解決正常階段時域對算法的影響。文獻[16]提出一種有中心化和無中心化相結合的相似性匹配方法。
上述基于退化特征相似性預測的研究,都建立了綜合健康指標,但是缺乏與單個參數的比較,無法體現健康指標的有效性。此外,發動機不同階段的變化對于相似性預測的影響,對于如何使有限的樣本庫發揮出更好的效果等問題還有待解決。本文基于發動機性能退化規律,建立3個標準綜合篩選與發動機性能變化關聯性更大的指標,通過關聯性的差異給相關指標分配權重,并將其融合成綜合指標;根據發動機性能衰退趨勢的變化特點以及樣本數量對于相似度的影響,區分不同階段,移動不同階段測試樣本進行相似性匹配;采用由美國航空航天局公布的航空發動機數據集驗證綜合指標的有效性,并與單模型匹配,多模型匹配的預測方法進行比較,最終計算結果表明本文的方法具有更高的預測精度。
1 基于發動機性能變化規律的綜合指標
當前,在構建一維指標的問題上,主要采用深度學習來解決而很少結合具體設備的特性。文獻[17]采用深度卷積網絡構建軸承的一維指標。文獻[18]利用增強受限玻爾茲曼機和自組織映射網絡來構建一維指標。文獻[19]提出一種受限玻爾茲曼機和長短時記憶網絡構建發動機一維指標的方法。對于航空發動機而言,發動機性能衰退受不同工作條件的影響,而發動機性能衰退又會影響多個傳感器數據[20]。因此,為了更加準確地表征發動機的退化狀態,預測發動機的在翼RUL,應當采用多個指標共同評估,而非單個指標單獨評估。然而發動機是一個復雜的系統,需要依靠很多個傳感器去反映各個方面的狀態,但并非所有的傳感器數據都能表征發動機的性能狀態。如果采用所有傳感器采集的數據綜合判斷發動機的退化狀態,勢必會引入一些與發動機性能無關或者與發動機性能退化關聯較小的參數,進而影響發動機RUL的預測。
1.1 基于發動機特性的指標篩選
航空發動機的各個傳感器,反映發動機各個狀態的變化,但不同傳感器對于發動機的性能變化的敏感程度不一樣。對于發動機性能變化越敏感的參數,其變化幅度會越大,而一些對發動機性能變化不敏感的參數,不會隨著發動性能衰退而出現較大的波動。因此,定義第一個反映與發動機性能衰退關聯性的標準是參數變化幅度。不同參數的量綱不同,為了更好的進行比較,應當將參數變化幅度標準化,第j個參數的變化幅度為
(1)
式中,j是指第j個參數;i是指第i臺發動機;n是指一共有n臺發動機;maxc,i和minc,i分別是指第i臺發動機在運行失效循環內的最大值和最小值。
雖然航空發動機個體之間差異比較大,性能變化也不盡相同,但是航空發動機的出廠標準不可能根據每一臺發動機去制定,出廠使用的發動機應當符合一套相對固定標準,表征發動機達到相應的性能要求[21-22]。因此,發動機中與性能關聯更密切的指標的起始值差異不能夠太大。而參數的變化幅度,會影響該參數的起始值差異。為了克服這種影響,需要在相同的變化幅度下比較參數的起始值差異。在相同的變化幅度下,參數的起始值的差異越小與發動機性能關系越密切,反之,越疏離。基于此,定義的第2個反映與發動機性能衰退關聯性的標準為參數起始值差異,第j個參數的起始值差異為
(2)
式中,cj是第j個參數的變化幅度;maxs, j和mins, j分別是指第j個參數在所有發動機的起始時刻的最大值和最小值。
根據適航條例,對于如何確定一個發動機是否失效也需要一定的標準[23-24]。有很多原因可以引起發動機性能衰退直至失效,在不同發動機的不同參數上的反映也各不相同。但是在失效時刻,與性能關聯更密切的指標在不同發動機上的差異會比較小。在由相同故障引起的發動機失效的數據集中,這種差異會有更加明顯的體現。所以,定義的第3個反映與發動機性能衰退關聯性的標準為參數失效值差異,第j個參數的失效值差異為
(3)
式中,maxf, j和minf, j分別是指第j個參數在所有發動機失效時刻的最大值和最小值。在相同的變化幅度標準下,差異越小,與發動機性能關聯性越大,反之,越小。
將以上的3個標準進行融合,形成一個綜合標準對所有參數進行篩選。融合形成的綜合標準為
(4)
式中,k是指數據集中的參數數量。為了選出與發動機性能關聯性更高的參數,要求參數變化幅度要大于其起始值差異和失效值差異,即選取綜合標準hj大于0的參數。
1.2 綜合指標的建立
綜合指標建立的具體步驟如下。
步驟1通過綜合標準篩選出n個參數xj,并建立對應的樣本集。
步驟2對xj對應的樣本集K進行濾波和歸一化,構成新的樣本集R。
步驟3計算各個參數對應的權重系數wj:
(5)
步驟4將權重系數wj配置給對應的參數xj,然后進行融合形成第k個發動機在第i個運行循環的綜合指標yk,i:
(6)
通過建立綜合指標,可以得到m個發動機的樣本集Y={y1,y2,…,ym},每個發動機的樣本集都是一維綜合指標,表征各個運行循環中,航空發動機的健康狀態,yk={yk,1,yk,2,…,yk,i}。
2 基于多階段多模型的相似性匹配的RUL預測
2.1 相似性匹配
相似性匹配是將當前發動機已知的健康狀態變化軌跡作為輸入,然后選取一定的度量方法,把該軌跡與樣本庫中的變化軌跡一一進行匹配,選擇該度量方法下匹配最優的變化軌跡。在相似性匹配的研究中,主要采用軌跡間距離的二次方進行度量[25-27]。當前,對于軌跡間距離一次方和二次方度量的比較相對匱乏。本文選取兩種對應的度量方式進行比較。這兩種度量方式是均方根誤差(root mean square error, RMSE)和平方絕對誤差(mean absolute error, MAE)。通過這兩種方法,分析比較不同度量方法對于RUL預測精度的影響。
(7)
(8)
在進行相似度匹配時,為了找到預測樣本與樣本庫中各個樣本的最佳匹配位置,采用的是移動模型匹配。因為不同樣本的性能變化趨勢不一樣,固定模型進行相似度匹配得到的結果不一定是兩個模型最相似匹配結果。
移動模型匹配的步驟如下。
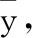
步驟 2將預測模型的綜合指標與樣本庫的綜合指標從起始位置進行匹配,直至該樣本的失效位置,得到第i臺發動機的度量序列RMSEi={RMSEi,1,RMSEi,2,…,RMSEi,z}和MAEi={MAEi,1,MAEi,2,…,MAEi,z}。
步驟 3把第i臺發動機的度量序列RMSEi和MAEi中的值進行排序,找到第i臺發動機對應的最佳位置posi,利用第i臺發動機總的運行循環Ti,計算預測模型匹配第i臺發動機的RUL(RULi)。
步驟 4重復步驟1~步驟3直至將樣本庫中的所有樣本都進行匹配,得到總的RUL序列RUL={RUL1,RUL2,…,RULI}。
將上述得到的RUL序列進行排序,選取相似度最高對應的RUL,可以實現單模型RUL預測。
2.2 最優多模型選取
為了更好地表達發動機的性能衰退,提高預測精度,采用多模型綜合預測。而選取的模型數量對于發動機RUL預測有一定影響。因此,需要尋找最優的多模型以達到最好的多模型預測效果。將相似性匹配得到的RUL序列RUL按照度量從小到大進行排序,從兩個模型到所有模型按照:
(9)
(10)
(11)
給各個模型預測的RUL配置相應的權重,然后融合形成新的RUL序列RULnew={RULnew,2,RULnew,3,…,RULnew,n},RULnew,n表示n個模型共同預測的RUL。使用平均絕對百分比誤差(meanabsolutepercentageerror,MAPE)評價不同數量的模型共同預測的結果,最后選取最優的模型數量進行發動機的RUL預測。
2.3 多階段剩余壽命預測
在運行的早期階段,設備或者系統往往具有較大的不確定性,性能衰退也不明顯[28-29],某發動機性能衰退過程如圖1所示。
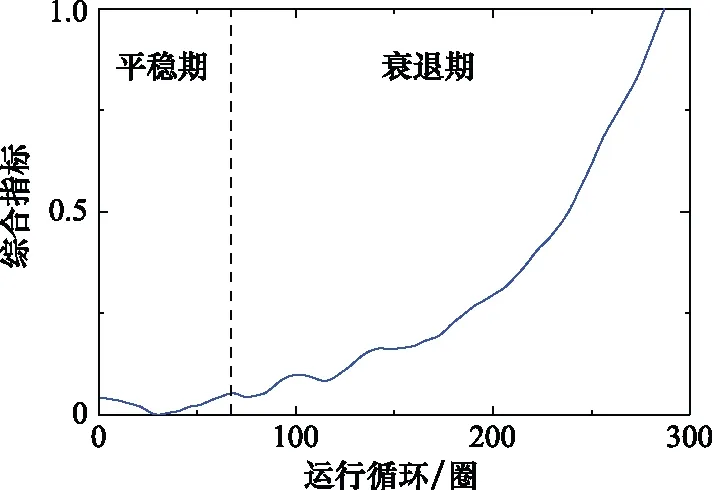
圖1 某發動機性能衰退過程
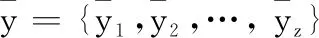
RULpre=(RULnew1+RULnew2)/2
(12)
進行融合,實現航空發動機的RUL預測,得到最終的預測結果RULpre。
3 方法驗證
3.1 數據來源
本文的方法驗證采用美國國家航空航天局(NationalAeronauticsandSpaceAdministration,NASA)公布的C-MAPSS數據集[30]。該數據集在航空發動機RUL預測領域中得到廣泛使用,其科學性和可靠性得到充分肯定[31]。NASA所使用的發動機仿真模型簡圖如圖2所示。本文使用FD001數據集。該數據集給定3個條件變量,分別為:飛行高度為0Kft,油門角度為100°,馬赫數為0.84。數據集中的21個傳感器參數如表1所示。
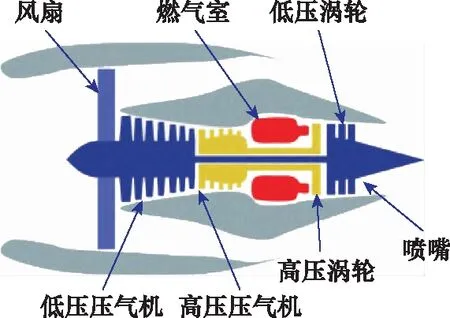
圖2 發動機仿真模型簡圖
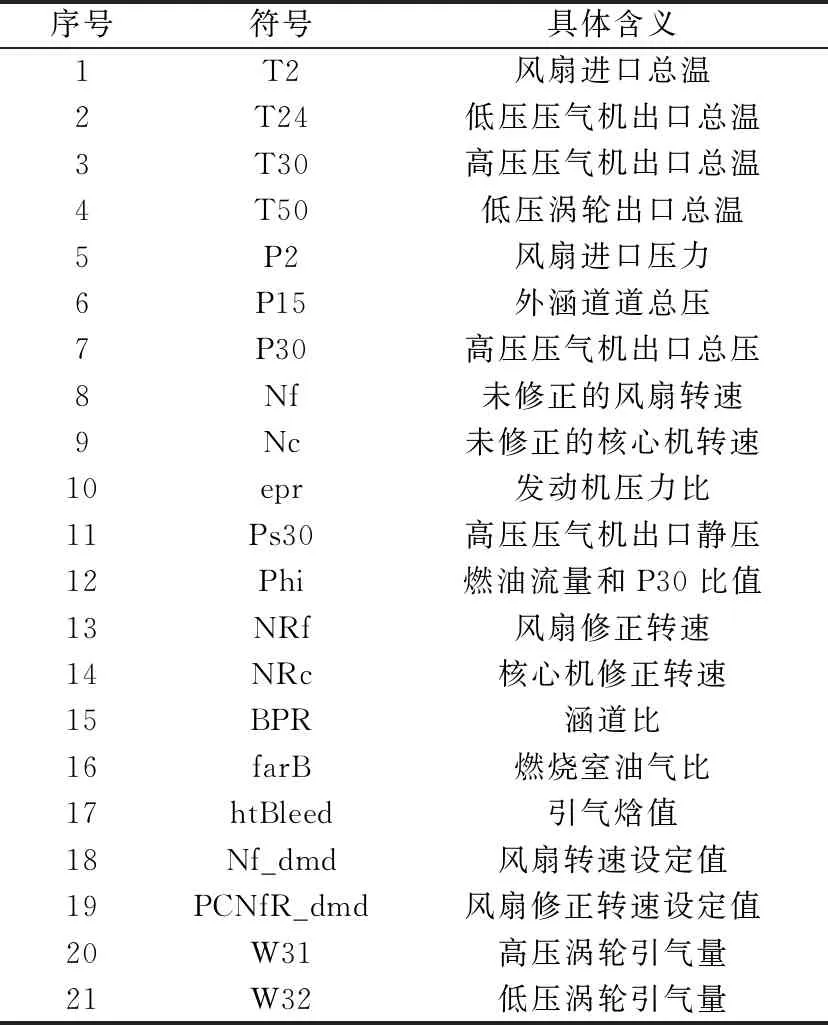
序號符號具體含義1T2風扇進口總溫2T24低壓壓氣機出口總溫3T30高壓壓氣機出口總溫4T50低壓渦輪出口總溫5P2風扇進口壓力6P15外涵道道總壓7P30高壓壓氣機出口總壓8Nf未修正的風扇轉速9Nc未修正的核心機轉速10epr發動機壓力比11Ps30高壓壓氣機出口靜壓12Phi燃油流量和P30比值13NRf風扇修正轉速14NRc核心機修正轉速15BPR涵道比16farB燃燒室油氣比17htBleed引氣焓值18Nf_dmd風扇轉速設定值19PCNfR_dmd風扇修正轉速設定值20W31高壓渦輪引氣量21W32低壓渦輪引氣量
將FD001的測試集中的100臺發動機分為兩個部分,第1部分是前80臺發動機的數據,用于構建樣本庫;第2部分是后20臺發動機的數據,對每個發動機的前40個、80個、120個運行循環進行單模型RUL預測驗證綜合指標的有效性,采用每個發動機的前120個運行循環對不同階段分別進行最優多模型選擇,最后進行多階段多模型相似性匹配的RUL預測。
3.2 構建綜合指標
在進行參數篩選之前,先將21個參數中,在整個運行循環中刪除沒有發生變化的參數1,5,6,10,16,18,19,最終剩下14個參數。將剩下的14個參數重新排序,然后使用參數變化幅度,參數起始值差異,參數失效值差異3個標準進行評判,再用綜合標準進行篩選,最終得到的3個標準和綜合標準的分析圖,如圖3~圖6所示。
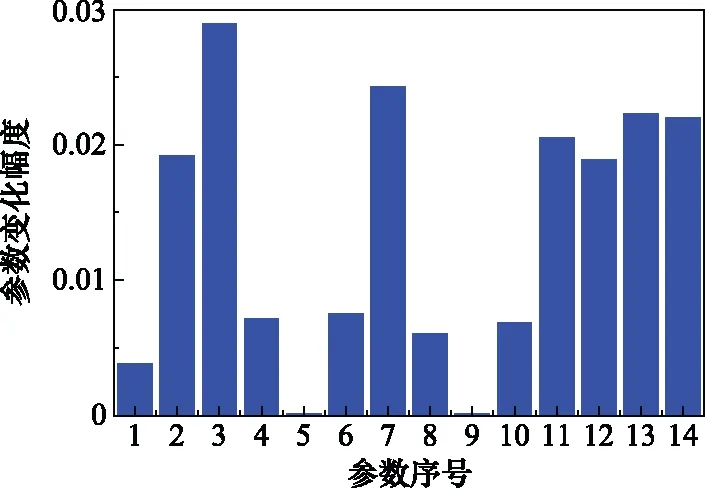
圖3 參數變化幅度分析圖
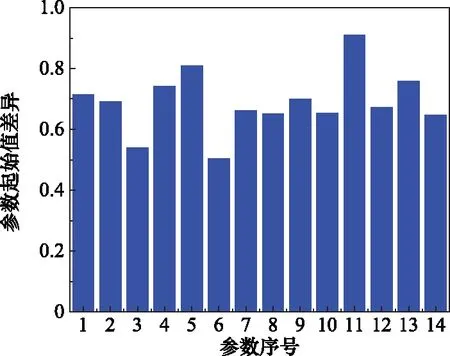
圖4 參數起始值差異分析圖
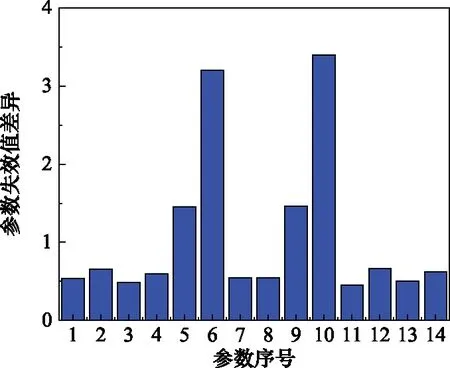
圖5 參數失效值差異分析圖
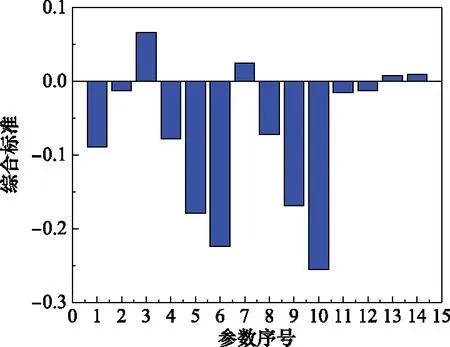
圖6 綜合標準分析圖
經過綜合標準的篩選,最終只有第3個參數(低壓渦輪出口總溫),第7個參數(高壓壓氣機出口靜壓),第13個參數(高壓渦輪引氣量),第14個參數(低壓渦輪引氣量)符合標準,如表2所示。本文采用一維數字濾波器對這4個參數進行濾波并進行歸一化,再用穩健局部加權回歸進行平滑處理,最后按照表2的權重進行綜合指標融合。

表2 參數權重
前6個發動機建立的綜合指標的變化趨勢如圖7所示。
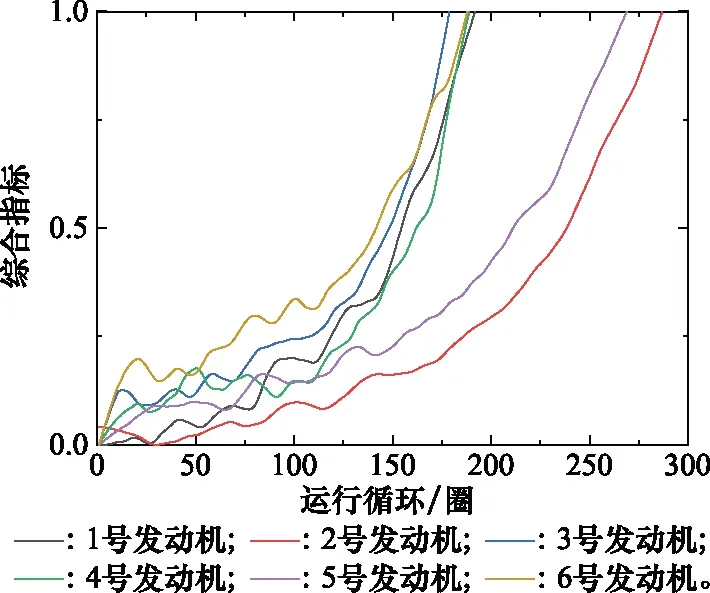
圖7 前6臺發動機的綜合指標變化軌跡
3.3 RUL預測
為了驗證綜合指標的有效性,分別采用預測樣本的綜合指標和低壓渦輪出口總溫前40個、80個、120個運行循環進行相同的數據預處理,然后用MAE指標進行相似性度量,對20臺發動機做單模型壽命預測。預測結果如表3所示。
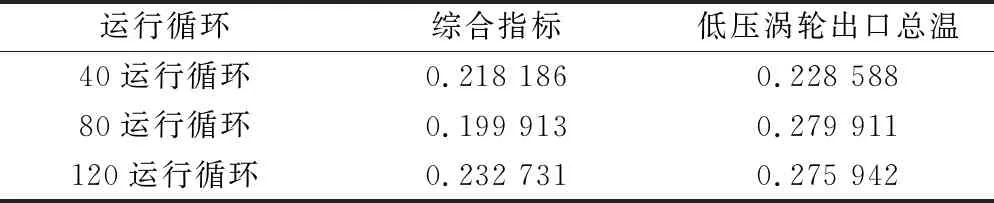
表3 不同指標的預測精度
通過預測結果,可以發現綜合指標的預測效果明顯優于單參數的預測效果。在3個不同的運行循環中,綜合指標的MAPE分別提升4.55%,28.58%,15.66%。
此外,使用不同的度量方式可能會對相似性匹配的結果造成一定影響。因此,本文選取兩種度量方式進行比較,同樣是采用20臺發動機前40個、80個、120個運行循環做單模型壽命預測。RMSE和MAE兩種度量方式的預測結果如表4所示。
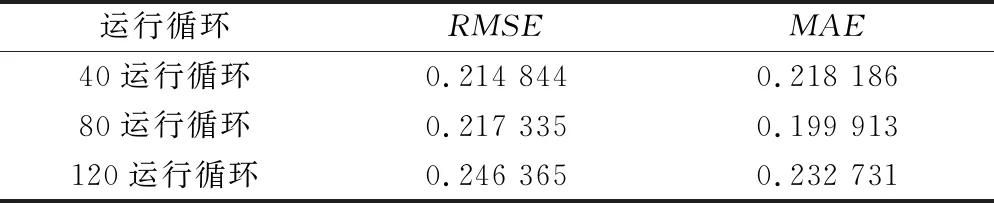
表4 不同度量方式的預測精度
從計算結果可以看出,度量方式MAE的預測效果整體上要優于度量方式RMSE,特別是在運行循環比較大的時候。在40運行循環時,兩者的預測效果差別不大。在后面兩個運行循環,MAE的預測效果分別提高8.02%和5.53%。
確定了健康指標和度量方式之后,在120個運行循環下,對全階段和半階段分別進行最優多模型選擇,得到預測精度隨著融合的模型數量變化如圖8所示。

圖8 不同多模型預測精度
可得到在全階段時使用8個模型融合效果最好,在半階段時采用18個模型融合的效果最好。將兩個階段的結果進行融合,得到的預測結果與多模型預測,單模型預測比較如表5所示。
通過多階段多模型進行預測,結果明顯優于多模型預測和單模型預測,預測精度分別提高17.60%和37.01%。這驗證了多階段多模型預測的有效性。

表5 3種預測方法的結果對比
4 結束語
本文采用參數變化幅度,參數起始值差異,參數失效值差異綜合篩選參數,將符合標準的參數融合成綜合指標。該指標相比于單參數能夠更好地表征發動機的性能衰退。
利用兩種度量方式RMSE和MAE分別進行相似性匹配,MAE能夠更好地克服數據波動帶來的影響,特別是發動機處于性能衰退比較嚴重的階段。
為了解決采用全壽命周期數據進行相似性匹配對于發動機性能衰退期不敏感的問題,同時兼顧預測數據的整體性變化趨勢和局部差異,采用整階段和半階段進行多階段多模型相似性預測,研究結果表明本文所提出的方法比只采用整個階段的數據進行多模型相似性預測的方法,有更小的預測誤差和更高的預測精度,MAPE降低了17.60%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車維修與保養(2021年8期)2021-02-16 00:28:30
汽車維修與保養(2021年8期)2021-02-16 00:28:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2014年2期)2014-02-27 12:10:15
汽車與新動力(2013年5期)2013-03-11 16:08:17
