基于電力數據分析的污水站點監測方法研究
2021-05-07 00:38:33黃彥斌駱德漢蔡高琰
現代信息科技 2021年21期
關鍵詞:數據分析
黃彥斌 駱德漢 蔡高琰


摘 ?要:在經濟發展日新月異的今天,環境治污已成為確保社會經濟健康有序發展的關鍵。為實現對污水站點的有效管控,需對其運行狀態進行實時監測,為此,文章提出一種負荷功率曲線自動化異常檢測的方法。對智能電表采集的負荷數據進行離群點分析并提取典型日負荷曲線,采用一種改進的皮爾遜相關系數分析方法,對每個站點的負荷曲線進行異常檢測,判斷污水站點的運行情況,提高異常檢測準確率并減少人為誤差和投入,具有較好的實際應用價值。
關鍵詞:智能電表;負荷曲線;數據分析;異常檢測
中圖分類號:TP399 ? ? ? 文獻標識碼:A文章編號:2096-4706(2021)21-0121-05
Abstract: With the rapid development of economy, environmental pollution control has become the key to ensure the healthy and orderly development of social economy. In order to realize the effective management and control of sewage stations, it is necessary to monitor their operation status in real time. Therefore, this paper proposes an automatic anomaly detection method of load power curve, analyzes the outliers of the load data collected by the smart meter, extracts the typical daily load curve, and uses an improved Pearson correlation coefficient analysis method to detect the anomaly of the load curve of each station, in this way, we can judge the operation situation of the sewage station, improve the accuracy of anomaly detection and reduce human error and investment. It has good practical application value.
Keywords: smart meter; load curve; data analysis; anomaly detection
0 ?引 ?言
污水處理是城村生活污水治理的核心環節,但是其異常檢測至今尚未達到預期效果。目前,國內外對污水排放的監測主要是在各個治污設備處安裝多個傳感器,包括以活性污泥法、生物接觸氧化法等為核心技術的一體化污水處理設備[1],自動控制系統中的主控模塊設備[2](PLC),對各個傳感器采集的參數進行分析[3,4]。以物聯網技術和網絡通信技術為核心的遠程監控技術得到了一定的應用[5,6],如構建通用分組無線服務(General Packet Radio Service, GPRS)和基于Internet網絡平臺的遠程污水監控系統[7],或者定期對在線污水水質化學檢測儀器進行清理維護[8]。傳統的監測手段因存在以下問題而難以推廣:傳感設備安裝困難,多點安裝容易出故障,易受外界影響,溫度、濕度、水量等因素都可能會使監測結果出現偏差,以及成本投入大[9]。因此尋找一種既能減少(或杜絕)人為因素干擾,又可降低安裝運行成本的解決方案是本文的研究重點。本文通過智能電表對電力數據的采集與處理,提出一種負荷曲線異常檢測的方法,實現了對污水站點的科學監管,大大減少了人力成本的投入,具有低成本、適用范圍廣的優勢。
1 ?智能電表采集終端
智能電表是對電子式電表的改進升級,能夠對電力數據進行實時采集、分析、存儲。具有高性能、低成本、高速率、高精度、高存儲的優勢。本方法中采用智能電表,核心控制器MCU為HT6501,內核處理器為32位處理器ARM Cortex-M0,Flash為128 K,SRAM為8 K;采用高精度專用計量芯片ATT7022E,采樣頻率為14.4 kHz[10],脈沖常數為1600 imp/kWh;采用高性能繼電器,內置溫度補償時鐘,時鐘誤差小于0.5秒。實驗數據來源于廣東省佛山市470多個農村污水站點實時采集的平臺負荷曲線數據表。上報的數據類型包括三項電流、三項電壓、有功功率、無功功率、總功率等參數,本方法用到的只有負荷功率這一參數,監測頻率為1分鐘上報1個點,共30天的數據。數據集中的數據可能會出現缺值,在數據預處理時進行插值補充。主要采用內插法對原始上報數據進行數據插值。由于電表設備在4G網絡通信傳輸過程中漏報造成的明顯缺數,采用結合前后監測數據的方式,取均值,即,提高了負荷曲線的平滑性。本方法工作流程如圖1所示。
2 ?離群點檢測
電力負荷數據具有很強的周期性,且流程工藝的改變使負荷曲線的形態特征呈現出比較明顯的差異。不同流程設計的站點,可能具有相似的典型日負荷曲線,相同的流程工藝也可能具有不同的特征典型日負荷曲線。由于污水處理站的噸量級設計存在較大的差距,離群點檢測之前,先對負荷功率數據樣本進行標準化處理,使得處理后數據的數量級差距不會過大。負荷曲線數據的歸一化表達式為:
其中,Xm為歸一化后的負荷功率曲線在第m分鐘的值,Pm為原始數據,PMax和PMin分別為數據的最大值和最小值。在實際污水處理站點的設計中,采用互感器的降壓變比方便用于量測和保護智能電表系統,電表采集上報的二次電流、二次功率與實際電流、實際功率為20倍(100/5)的關系,需乘以20才能還原原本的電力數據,將數據集導出為CSV文件(.csv)。污水處理站點工藝流程圖如圖2所示。
采用機器學習算法孤立森林(Isolation Forest, IForest)進行異常離群值檢測[11],篩選排除與其他數據點不同的異常點。IForest是目前最常用的異常點檢測算法之一,算法原理是,數據集中的異常值為少量,并且與正常值差距較大,容易被孤立,算法時間效率高,能處理大規模數據樣本,通常隨機二叉樹iTree數量越多,算法越穩定。由于每次切數據空間都是隨機選取一個維度和維度的特征,有大量的維度未被使用,算法的可靠性降低。IForest的缺點是不適用于維度很高的數據。本文使用的數據集中,數據類型只有負荷功率(ActivePowerTotal)一個維度,故可采用IForest進行異常檢測,下面介紹計算步驟:
(1)對訓練集中的數據進行采樣并將采樣數據作為根節點,遞歸,不斷構造新葉子節點,直至葉子節點無法繼續分割或達到樹的最大高度(構建t個iTree樹)。
(2)對iForest森林中的每個iTree樹進行檢測,并計算路徑長度(path length),根據異常分數(anomaly score)計算公式,計算每個數據點的異常分數,異常分數越接近于1,其成為異常離群點的概率越大;如果分數都比0.5小,可以確定它們都是正常數值;如果大部分分數都在0.5附近,則不存在明顯的異常數據點。
假設樣本負荷數據有m個污水處理站點,每條典型日負荷曲線有1 440個離散數據點,將數據集中每天的負荷數據構成一個m×1 440的矩陣:
矩陣中第m行數據為第m個污水處理站點的典型日負荷曲線數據,根據實際運行情況,本文設定采樣的樣本大小Ψ為默認值256,二叉樹數t=100,樹深度height=8,iTree數據集異常比例為0.01。以某站點2021年10月24日負荷功率曲線為例,檢測結果如圖3所示。從圖3中總共找出9個異常離群點,本文不對異常數據的產生原因做深入研究,直接篩除會造成數據長度發生變化,修改離群點的值為其右鄰點,即Pi=Pi+1。處理完的數據規格仍為1 440×1,可以提高站點檢測的準確度以及減少計算復雜度。
3 ?提取擬合典型日負荷曲線
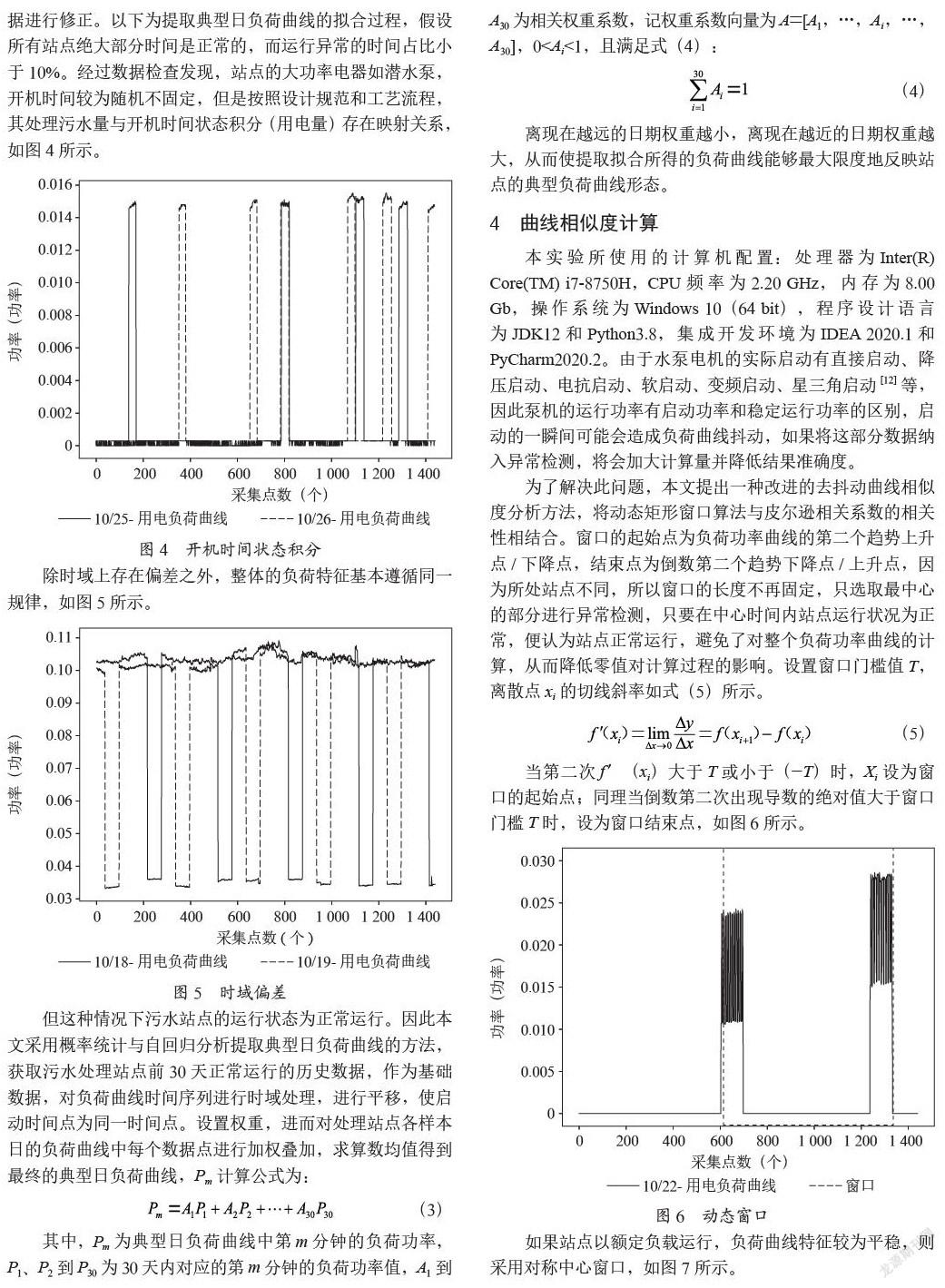
離散點檢測可以消除噪聲對數據的影響并對不一致的數據進行修正。以下為提取典型日負荷曲線的擬合過程,假設所有站點絕大部分時間是正常的,而運行異常的時間占比小于10%。經過數據檢查發現,站點的大功率電器如潛水泵,開機時間較為隨機不固定,但是按照設計規范和工藝流程,其處理污水量與開機時間狀態積分(用電量)存在映射關系,如圖4所示。
除時域上存在偏差之外,整體的負荷特征基本遵循同一規律,如圖5所示。
但這種情況下污水站點的運行狀態為正常運行。因此本文采用概率統計與自回歸分析提取典型日負荷曲線的方法,獲取污水處理站點前30天正常運行的歷史數據,作為基礎數據,對負荷曲線時間序列進行時域處理,進行平移,使啟動時間點為同一時間點。設置權重,進而對處理站點各樣本日的負荷曲線中每個數據點進行加權疊加,求算數均值得到最終的典型日負荷曲線,Pm計算公式為:
其中,Pm為典型日負荷曲線中第m分鐘的負荷功率,P1、P2到P30為30天內對應的第m分鐘的負荷功率值,A1到A30為相關權重系數,記權重系數向量為A=[A1,…,Ai,…,A30],0<Ai<1,且滿足式(4):
離現在越遠的日期權重越小,離現在越近的日期權重越大,從而使提取擬合所得的負荷曲線能夠最大限度地反映站點的典型負荷曲線形態。
4 ?曲線相似度計算
本實驗所使用的計算機配置:處理器為Inter(R) Core(TM) i7-8750H,CPU頻率為2.20 GHz,內存為8.00 Gb,操作系統為Windows 10(64 bit),程序設計語言為JDK12和Python3.8,集成開發環境為IDEA 2020.1和PyCharm2020.2。由于水泵電機的實際啟動有直接啟動、降壓啟動、電抗啟動、軟啟動、變頻啟動、星三角啟動[12]等,因此泵機的運行功率有啟動功率和穩定運行功率的區別,啟動的一瞬間可能會造成負荷曲線抖動,如果將這部分數據納入異常檢測,將會加大計算量并降低結果準確度。
為了解決此問題,本文提出一種改進的去抖動曲線相似度分析方法,將動態矩形窗口算法與皮爾遜相關系數的相關性相結合。窗口的起始點為負荷功率曲線的第二個趨勢上升點/下降點,結束點為倒數第二個趨勢下降點/上升點,因為所處站點不同,所以窗口的長度不再固定,只選取最中心的部分進行異常檢測,只要在中心時間內站點運行狀況為正常,便認為站點正常運行,避免了對整個負荷功率曲線的計算,從而降低零值對計算過程的影響。設置窗口門檻值T,離散點xi的切線斜率如式(5)所示。
當第二次f′(xi)大于T或小于(-T)時,Xi設為窗口的起始點;同理當倒數第二次出現導數的絕對值大于窗口門檻T時,設為窗口結束點,如圖6所示。
如果站點以額定負載運行,負荷曲線特征較為平穩,則采用對稱中心窗口,如圖7所示。
皮爾遜相關系數也稱為皮爾遜積矩相關系數,定義一種簡單的線性相關系數指標,用于計算兩個變量X=[X1,X2,…Xn]T和Y=[Y1,Y2,…Yn]T的線性相關程度,結果落在[-1,1]區間,對于長度為n 的離散序列,計算公式為:
其中,R為皮爾遜相關系數,Xi和Yi為每個數據點的值,和為功率曲線均值。R的絕對值越大,表明相關性越大;R的絕對值越小,表明相關性越小。并且當R為-1時,X和Y為完全負相關;R為0時,X和Y沒有相關關系;R為1時,X和Y為完全正相關,相關性區間如表1所示。若污水站點正常運行,則典型日負荷曲線和待檢測日負荷曲線之間的相關系數R在[0.5,1]之間較為準確。
其中,R為曲線相似度系數,S為離散負荷曲線積分的比值,S的絕對值≤1。當功率時間的積分比值非常接近1時,說明站點按照設計規范運行,即使相似度較低,也屬于正常運行狀態;相似度系數較高,即待檢測功率曲線和站點的典型日負荷曲線具有同步的特征狀態,站點處于正常運行狀態。通過對實驗數據的統計分析,可以優化提高污水異常站點的檢測率。以圖5為例,相關系數為0.871 243 5,積分比值為0.975 659 8,所以可以判斷出該站點處于正常運行狀態。根據實驗情況,最終設置模型參數為:相關系數R=0.85,曲線積分比值S=0.9,窗口門檻T=0.01,核心窗口區間=[300,1100],系統的異常檢測誤差比較低,模型收斂性好,取得較好的檢測效果。
基于治污處理站點的實際運行情況,在佛山市農村地區選取了50個均勻分布的污水處理站點,根據它們的運行狀況進行異常檢測方法的試點驗證。所采用的治污設備主要有集水池提升泵、調節池提升泵、回流泵、加藥泵、潛水泵、曝氣機、風機、攪拌機、鼓風機、中間池等。由于不同規模不同設計的站點所采用的治污設備型號與額定功率不盡相同,部分治污設備的主要用電功率如表2所示。
導出后臺MongoDB數據庫中DataTime為2021年10月30日這一天的部分系統檢測記錄,如表3所示,檢測記錄為當日站點運行情況。除個別站點負荷功率曲線接近于0疑似停運外,有3個站點低于最近七日均線,在曲線特征形態上體現為整體幅度變小,如圖8所示。可以看出,工作日期間的功率曲線具有較強的規律性,星期六日期間,站點的污水處理噸數減少,這與農村居民的生活作息規律有一定的關系。
檢測結果與系統后臺結果基本一致,異常運行的站點都能被檢測出來,有少數正常運行的站點被檢測為狀態異常,總體準確率達到88%,如圖9所示。
綜上,80%以上的污水處理站點從流程設計上來說是正常運行的,只有少數污水處理站點出現運行異常狀況。本文提出的基于智能電表的負荷功率曲線數學分析異常檢測方法,在污水處理站的自動化異常監控上具有較好的表現。
5 ?結 ?論
為了降低人力成本,構建便于安裝的污水站自動化監測體系,提出一種基于智能電表的負荷曲線數學分析的方法,對污水處理站點的運行狀況起到科學監控的作用,可以較為準確地判斷站點的運行狀況,及時發現污水站點運行異常行為。本文所提出的方法對治污管理自動化系統的構建具有一定的現實意義。如何細化污水站點的異常分類是后續研究內容之一;此次研究未將氣候、季節,降雨等因素納入考察范圍,只考慮了歷史用電量因素,后續研究中會將客觀變化因素作為影響用電量變化的因素,并搭建Spark計算框架與機器學習和負荷識別相結合的方法,以提高系統監控識別準確度。
參考文獻:
[1] 張婷,王孟珍,曹仲.農村一體化生活污水處理設備應用現狀與發展趨勢 [J].凈水技術,2021,40(S1):107-111.
[2] 石磊.污水處理系統中的自動控制系統設計 [J].集成電路應用,2021,38(9):158-159.
[3] 莊婉婉.污染源在線監測中存在的問題及發展趨勢 [J].上海環境科學,2019,38(5):218-219+223.
[4] 李倩.污染源自動監控在污染防治中的作用 [J].環境與發展,2019,31(9):60-61.
[5] 顧浩,徐宏飛,陳衛兵.基于物聯網技術的工業污染總量控制系統的研究 [J].物聯網技術,2016,6(11):84-86.
[6] 于大偉,鐘華,李子梅.基于物聯網的城鎮污水處理監管系統設計與研究 [J].長春工程學院學報(自然科學版),2015,16(3):94-97+103.
[7] 顏秀勤,韋啟信,楊超,等.村鎮污水處理設施遠程監控系統設計與實現 [J].物聯網技術,2018,8(12):58-60+63.
[8] 周智墩.如何提高污水水質檢測的準確性及穩定性 [J].資源節約與環保,2019(8):51.
[9] 劉忠輝,蔡高琰,梁炳基,等.基于電力數據分析的污染物排放監測方法研究 [J].信息技術與網絡安全,2021,40(2):52-55+73.
[10] 荊永震.非侵入式負荷識別系統研發 [D].廣州:廣東工業大學,2019.
[11] 黃福興,周廣山,丁宏,等.基于孤立森林算法的電能量異常數據檢測 [J].華東師范大學學報(自然科學版),2019(5):123-132.
[12] 曹錫楓.溪洛渡水電站進水口配電設備選擇研究 [J].水電站設計,2014,30(1):20-27.
作者簡介:黃彥斌(1997—),男,漢族,廣東揭陽人,碩士研究生在讀,主要研究方向:數據分析、智能電表;駱德漢(1958—),男,漢族,安徽蕪湖人,教授,博士,主要研究方向:仿生嗅覺、模式識別與綠色電子技術;蔡高琰(1982—),男,漢族,廣東揭陽人,中級工程師,本科,主要研究方向:信號處理。
猜你喜歡
職工法律天地·下半月(2016年10期)2016-11-30 11:52:57
商情(2016年40期)2016-11-28 11:28:07
商(2016年32期)2016-11-24 17:39:41
科技資訊(2016年18期)2016-11-15 18:05:53
考試周刊(2016年84期)2016-11-11 23:57:34
科技視界(2016年18期)2016-11-03 22:51:40
體育時空(2016年8期)2016-10-25 18:02:39
現代經濟信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
