改進的基于DNN的惡意軟件檢測方法
2021-05-26 03:14:20張柏翰
計算機工程與應用 2021年10期
張柏翰,凌 捷
廣東工業大學 計算機學院,廣州510006
蓬勃發展的互聯網為人們的工作和生活提供諸多便利,同時也可能被不法分子利用,成為其牟利犯罪的工具。諸如計算機病毒、蠕蟲、木馬、僵尸網絡、勒索軟件等在內的惡意軟件長期以來都是不法分子用以破壞操作系統、竊取用戶重要數據的利器,互聯網應用的普及則加劇了惡意軟件的傳播。根據ΜcAfee Labs 在2019年8月發布的威脅報告[1],惡意軟件總數在2019年第一季度已經突破9億;而在惡意二進制可執行文件方面,從2017 年至2019 年間,單季度最高新增量高于110 萬。對惡意軟件的檢測和查殺一直是網絡空間安全研究領域的重要課題之一。
惡意軟件檢測方法可根據是否需要運行軟件分為靜態分析方法和動態分析方法。靜態分析方法只對二進制可執行文件中的代碼進行分析,動態分析方法則對可執行文件運行時的行為進行分析。無論哪種分析方法,傳統手段都需要大量人工工作和專家經驗,效率較低。而且攻擊者使用多態組合、仿冒、壓縮、混淆等方法,有意讓惡意軟件避開檢測軟件的檢測[2],這無疑增加了人工分析的難度。近年來機器學習尤其是深度學習在圖像處理、文本處理等領域的成功實踐,為從事惡意軟件分析工作的研究人員帶來啟示。當前網絡空間中惡意軟件樣本龐大的數量,以及二進制可執行文件本身龐大的可提取特征的數量,使得深度學習方法非常適合于惡意軟件分類工作。
2015 年,微軟開放了一個數量上萬的帶標簽的惡意代碼樣本集,供研究者們使用[3]。在已有的工作中,Zhang等[4]、Dinh等[5]、Burnaev等[6]、Drew等[7]、Patri等[8]以及Gsponer 等[9]使用該數據集研究基于機器學習的對惡意軟件家族進行多分類的方法。Κebede等[10]、Κim[11]、Rahul 等[12]同樣研究惡意軟件的分類問題,不過他們使用的是容易取得更好效果的神經網絡模型。以上研究工作的目的均是對惡意軟件按所屬家族分類。而在惡意PE(Portable Executable)文件檢測中,也即關于PE文件的“善”“惡”的二分類問題方面的最新研究中,有許多基于機器學習的方法被提出。文獻[13]使用共享近鄰聚類算法檢測新惡意軟件。文獻[14]基于生成對抗網絡構建惡意軟件檢測器模型。文獻[15]構建集成了卷積神經網絡和長短期記憶網絡的檢測器模型。文獻[16]使用深度置信網絡構建檢測器模型。文獻[17]針對缺乏確定性質樣本的情況,提出了一種基于半監督深度神經網絡的惡意樣本標記方法。文獻[18]基于許多新類型的惡意軟件都是現有惡意軟件的變體這一事實,將可執行文件轉為灰度圖,并使用基于卷積神經網絡(Convolution Neutral Network,CNN)的分類器進行同源性分類,以訓練好的分類器來識別。文獻[19]描述了一種端到端惡意PE 文件檢測模型ΜalConv,其直接將未經處理的原始PE 文件作為特征向量,并由使用了嵌入層和一維卷積層的神經網絡模型提取特征,從而做出“善惡”的判別。該文獻作者Raff 等人表示他們的模型在惡意PE文件的檢測上具有不錯的效果,然而文獻[20]的作者Κolosnjaji 等人針對該模型提出一種基于梯度下降的生成對抗樣本的算法,由該算法生成的對抗樣本逃避ΜalConv 檢測的成功率可達到60%。文獻[21]基于Endgame 公司開放的惡意PE 文件特征數據集Ember[22],用10個全連接層建立二分類模型DeepΜalNet,對PE文件的善惡進行判斷,輸出PE文件為惡意軟件的概率。DeepΜalNet 非端到端檢測模型,其接收的數據為PE文件經過預處理后得到的特征向量。該模型對惡意PE 文件具有不錯的檢出效果,且目前尚未有人提出針對此種模型的對抗攻擊方法。然而在本文實驗過程中,發現其存在參數數量過多和泛化性較差的問題。
在數據集方面,Virusshare、Virustotal、Μalshare等網站提供大量惡意軟件樣本供學習和研究使用,Μicrosoft也開放惡意PE樣本集供研究,其中每個PE文件具有所屬惡意軟件家族的標簽。至于正常可執行文件樣本,由于政策等因素,互聯網上并未有組織或個人開放大量可用原始樣本。也正因此,大量的關于惡意軟件的分類研究工作均集中在對惡意軟件所屬家族的歸類問題上。Endgame 公司于2017 年開放了一個用于研究惡意軟件檢測的數據集,其中包含由100 萬個PE 文件樣本通過特征工程轉化而來的100 萬個長為2 381 的32 位浮點數特征向量。本文在該數據集上設計并開展了驗證性實驗。
本文將針對文獻[21]設計的惡意PE 文件檢測器模型所存在的泛化性較差的問題,改進模型結構,提高模型的泛化能力,并使模型在后續剪枝工作中保持可用性。
1 相關工作
1.1 基于DNN的二分類模型
本文使用具有多個全連接層的神經網絡構成惡意軟件檢測器模型。檢測器接收的數據為將PE文件進行預處理后得到的特征向量,預處理的方法將在后文介紹。實驗中曾在模型中加入一維卷積層和循環神經層,但與單純使用全連接層的模型相比其效果不佳。由此推測,由本文所述數據預處理程序提取的特征向量不具備時序性,因而本文最后選擇深度神經網絡(Deep Neural Network,DNN)作為惡意軟件檢測器模型的基礎架構。
特征向量輸入模型后,會經過多個模塊M 。這里模塊M 是一個數據處理流程:模塊M 接收輸入數據或由上一個模塊處理后得到的輸出數據X ,經過批歸一化層(Batch Normalization,BN),使得向量X 各維數值x0,x1,…,xn均值趨于0,方差趨于1;然后數據經過一個具有n 個神經元的全連接層,此全連接層采用relu作為激活函數;最后使用定向Dropout方法,在每一個訓練步驟中挑選一定數量的權重參數,使其失活,通過這種方法防止神經網絡過度依賴某些神經元,導致訓練得到模型過度擬合數據集而泛化性差。
數據從最后一個模塊輸出后,再進入一個只有一個神經元的全連接層,即輸出層。該層以sigmoid 函數作為激活函數,得到介于0 和1 之間的32 位浮點數,表示判定輸入樣本為惡意PE文件的概率。
需要指出的是,本文設計的模型使用定向Dropout方法替代DeepΜalNet所用的普通Dropout方法,并通過實驗驗證其有效性。
1.2 全連接層
全連接層由一個線性函數加一個激活函數組成,如式(1)所示。假設ni-1為第i 個模塊接收的輸入向量Xi的維數。第i 個全連接層的權重矩陣為Wi,其由ni個維度為ni-1的向量構成,bi為偏置向量,維數為ni。a為激活函數,目的是對線性函數的輸出作非線性變換。

在本文設計的檢測器模型中,除了輸出層外的每個全連接層使用的激活函數皆為relu 函數。實驗曾嘗試使用sigmoid、leaky-relu、erelu、prelu等函數作為模塊M中全連接層使用的激活函數。實驗中發現,relu及其變種函數的效果最好,因此本文最終使用relu 作為模塊M 中全連接層的激活函數。而在輸出層中,本文使用sigmoid作為激活函數。
1.3 Batch Normalization
在訓練模型時,若各層網絡接收的輸入數據的分布不一致,則后層網絡需為了適應輸入數據的變化而不停調整,如此將導致學習速度降低,模型無法很好地收斂。因而本文設計的模型中引入BN機制,利用反向傳播使各網絡層的數據分布一致。
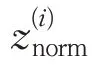

1.4 正則化
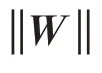
DeepΜalNet 模型使用Dropout 方法防止過擬合。這種在模型的每一步訓練中隨機選擇權重并令其失活的正則化方法在一定程度上可以防止模型過度依賴部分權重,但也導致模型訓練成型后所有權重的重要性一致,即沒有一個可以顯式擇取的最優子網絡,因而不利于模型后續剪枝中保持高可用性。而本文的實驗中使用一種稱為“定向Dropout”的方法代替Dropout。下一節將解釋這種正則化方法。
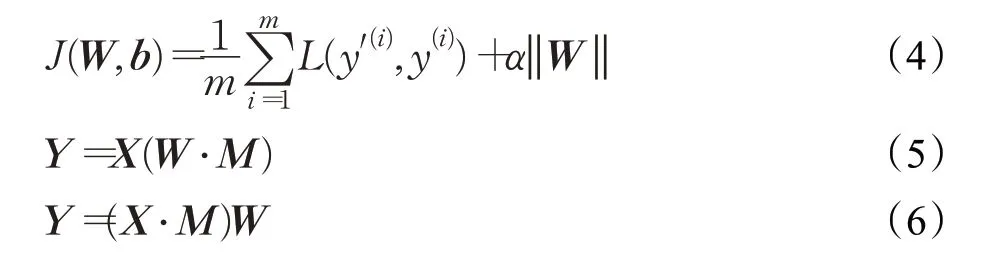
定向Dropout正則化方法由Aidan等人提出[23],是一種“基于重要性的剪枝方法”,其在每個網絡層中,對神經元的權重或是神經元的線性輸出值按大小排序(采用L1或L2范數),然后選出較小的一部分,從這部分權重或神經元中再隨機選出一部分,使其失活。這是一種優化的Dropout方法,不僅可以使模型更好地避免過擬合,提高模型的泛化能力,同時,可以使模型在訓練后得到一個最優子網絡,有利于模型的后續剪枝操作。
如同Dropout 正則化,定向Dropout 也分為針對權重和針對神經元的兩種,分別稱為權重剪枝和單元剪枝,它們篩選出重要權重的方法可分別用式(7)和式(8)表示,其中argmax-k 表示選出前k 個權重或單元。權重剪枝針對同一個神經元里的所有權重,將它們按一范數從大到小排序,然后選出前k 個作為保留權重,對其余權重行Dropout方法。單元剪枝則針對同一個神經層中的所有神經元,將它們根據各自的權重向量的二范數從大到小排序,選出前k 個作為保留神經元,對其余神經元同樣行Dropout方法。之所以不將殘余權重或神經元直接摒除,是因為它們中可能有一些會在后續訓練步驟中重新顯現重要性而進入前k,因此只對它們行隨機失活法,保證公平性。記模型參數數量為 ||θ ,候選失活參數占比為γ,對候選失活部分的隨機Dropout 比例為α,則在每次定向Dropout 時保留活性的參數數量為(1-γα) ||θ 。
在本文的實驗中使用針對權重的定向Dropout正則化方法替代Dropout方法,并測試其效果。
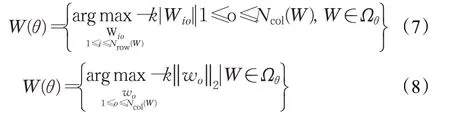
2 本文方法描述
2.1 數據集
EndGame公司開放的Ember數據集,是由對100萬個PE文件(包含正常可執行文件和惡意可執行文件)提取的特征向量和它們的標簽組成。其中,標簽0表示樣本為正常可執行文件,標簽1 表示樣本為惡意可執行文件,標簽-1 代表可執行文件未知善惡。在本文的實驗中,使用數據集中60 萬條帶有非-1 標簽的數據(其中包括標簽為0和1的數據各30萬條)作為訓練模型時使用的數據集,另外20 萬條(其中包括標簽為0 和1 的數據各10萬條)作為測試模型時使用的數據集。
在測試模型時,除了使用Ember 數據集做測試,也使用另外兩個樣本集來測試模型的泛化能力。一個是從Virusshare.com 下載的包括59 011 個惡意PE 文件的樣本集。在正常可執行文件樣本方面,由于許多軟件受版權法律保護,網上也沒有開放數量較大的正常可執行文件樣本集。本文的實驗采用The Universitiy Of Arizona開放的項目lynx-project(獲取地址為https://www2.cs.arizona.edu/projects/lynx-project/Samples/),其中包含39個善意PE文件,這些文件使用了一系列惡意代碼常用的編碼方法,包括使用VΜProtect、ExeCryptor 和Themida等工具對代碼進行混淆,以及添加自修改邏輯從而防篡改的方法。本文的實驗中使用這個項目來測試檢測模型的誤報率。
2.2 數據預處理
對每個PE 文件提取用于檢測器模型判別PE 文件善惡的信息,描述如下:
文件總體摘要信息。包括文件的虛擬大小,導入、導出函數數量,符號數量,是否有簽名、重定向、RSRC節、TLS節。
PE 頭部信息。這些信息提取自符合COFF(Object Common File Format)規范的PE 文件頭部的字段。提取的數據包括時間戳、目標機器、子系統、鏡像特征、DLL 特征、魔數、鏡像版本、鏈接器版本、代碼部分字節數、文件頭部大小、提交堆的大小。
導入函數信息。包括文件導入的庫名以及從導入的庫中引用的函數名。使用哈希函數將每個名稱字符串轉成256或1 024個二進制位數表示。
導出函數信息。包括一系列導出函數的名稱字符串。同樣使用哈希函數,將每個字符串轉成長為128的二進制位串。
節信息。PE 文件有多個節,從每個節中提取的信息包括節名、節大小、節的熵值、節的虛擬地址、節的特征(如是否可寫內存)。將節名使用哈希函數轉為50位串。將節名分別與節大小、節的熵值、節的虛擬地址配對,并使用哈希函數分別轉為50 位串。將入口節的特征用哈希函數分別轉為50位串。
數據目錄信息。數據目錄包括導出表、導入表、資源目錄、異常目錄、安全目錄、重定位基本表、調試目錄、描述字串、機器值、TLS 目錄、載入配值目錄、綁定輸入表、導入地址表、延遲載入描述、COΜ 信息。導出每個數據目錄的大小和虛擬地址。
字節統計信息。將文件中每個不同大小的字節(0~255)出現的次數進行統計,并除以文件總字節數,進行歸一化。
字節熵的統計信息。對文件使用固定大小的滑動窗口,將其按一定步長在文件上滑動,每滑動一步,計算窗口中的信息熵。在本文的實驗中,滑動窗口的大小為2 048 Byte,滑動步長為1 024 Byte。
可打印字符串的統計信息。選出的每個字符串需至少包含5個可打印字符。統計信息包括字符串總數,字符串平均長度,每條字符串的出現次數,字符串的信息熵。
將上文所述的文件總體摘要信息、PE頭部信息、導入函數信息、導出函數信息、節信息、數據目錄信息、字節統計信息、字節熵的統計信息、可打印字符串的統計信息打包,并轉為由2 381個32位浮點數構成的特征向量。其中,提取的各類文件信息對應的浮點數個數如表1所示。
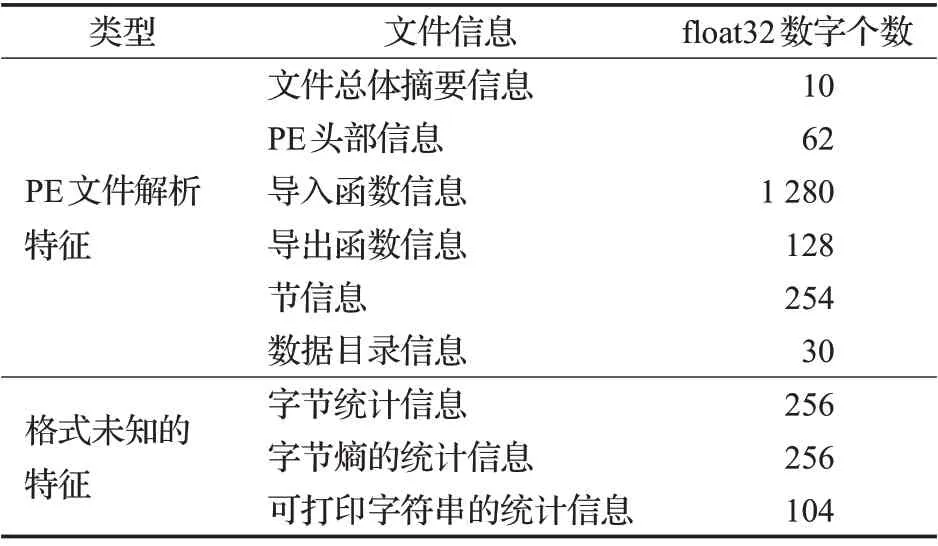
表1 PE文件特征向量概況
2.3 編碼與實驗設計
本文所述實驗使用易于搭建模型并測試、編碼較簡易的Κeras 框架來搭建惡意軟件檢測模型,訓練模型時使用Nvidia P100計算卡做運算。
實驗中,首先依文獻[21]所述搭建惡意軟件檢測器模型DeepΜalNet,并在Ember 數據集上訓練,使模型收斂。如圖1 為文獻[21]所述檢測器模型DeepΜalNet 的結構圖,其中包含10 個全連接層,在每個全連接層之后,使用BN和Dropout以避免模型過擬合,同時加速模型的收斂過程。模型的詳細參數可參考https://github.com/vinayakumarr/dnn-ember。

圖1 DeepΜalNet網絡結構圖
本文設計的檢測器模型同樣基于DNN,但與Deep-ΜalNet不同的是,本文模型在每個模塊中先使用BN機制處理模塊接收的向量,然后使用定向Dropout 算法擇取全連接層中的一部分權重使其失活,之后才讓數據流過模塊中的全連接層。在定向Dropout中使用的γ 和α參數大小分別為0.66 和0.75。本文設計的檢測器模型結構如圖2 所示。其中m 表示模塊個數,在實驗中測試了擁有10 個模塊的模型和擁有4 個模塊的模型的效果,前者各模塊包含的神經元數與DeepΜalNet 相同,后者各模塊包含的神經元數分別為2 381、4 762、2 381、1 024、128。
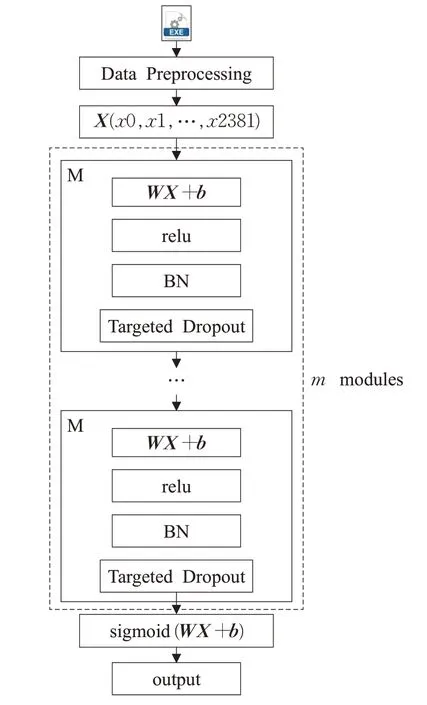
圖2 本文模型網絡結構圖
實驗使用Ember數據集中的標簽為0和1的數據各30萬條,共60萬條數據,作為訓練模型用的數據集。使用交叉熵損失函數作為模型目標優化函數,并使用Adam作為梯度下降的優化器,設置其學習率為0.01。為了加速模型收斂過程,防止模型在部分數據上過擬合,實驗中將60 萬條訓練數據打散,并設置模型每一次梯度下降過程中使用的批的大小為32 768。讓每個模型在訓練集上訓練500 epoch(周期),并在每個epoch后使用測試集對模型進行驗證,計算并記錄模型在測試集上的準確率。將模型在測試集上的準確率與epoch的關系繪制為坐標曲線,從而觀察模型的訓練情況。
本文在對實驗結果進行評估時采用的度量指標包括平均預測概率、召回率(模型在惡意軟件樣本集上的預測)、誤報率(模型在正常軟件樣本集上的預測)。所述“平均預測概率”即指模型將樣本集中的文件預測為惡意的概率的平均值。在本文實驗中,經過訓練的惡意軟件檢測模型可接收一個二進制可執行文件的字節內容,運算后返回一個介于0和1的浮點數,數值越接近1,則表示文件為惡意的概率越大。召回率,或稱“查全率”,表示模型在惡意樣本集中預測為“惡意”的樣本數占惡意樣本集總數的百分比。誤報率表示模型在正常樣本集中預測為“惡意”的樣本數占正常樣本集總數的百分比。本文的實驗分析中未采用二分類機器學習問題中常用的準確率、F1分數以及AUC作為度量指標,是因為受限于測試集中有限的正常樣本數量(本文實驗僅采用39個正常軟件樣本),這些指標并不能準確反映本文實驗中模型的性能。另外,本文實驗重點關注模型對惡意軟件的識別能力以及面對加殼文件時的判別能力,故將平均預測概率作為評價模型性能的重要指標之一。
3 實驗結果與對比分析
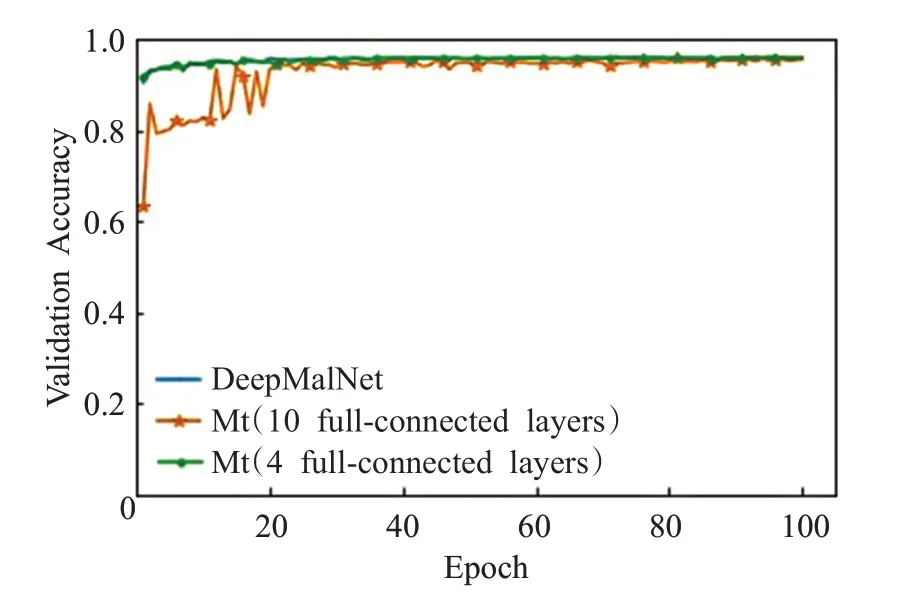
圖3 各模型在驗證集上的準確率變化情況
在訓練過程中,在完成每一個測試步驟后,使用Ember測試集驗證模型的性能。圖3展示了DeepΜalNet以及本文設計的模型(分別具有10 個模塊和4 個模塊)在前100 個訓練周期中的準確率變化情況。實驗中,DeepΜalNet 以及本文模型在100 個訓練周期基本達到穩定狀態;在超過500個訓練周期以后,各模型在Ember測試集上的準確率都在0.96左右。
實驗中用Virusshare 惡意樣本集中的59 011 個惡意PE 文件測試訓練好的模型。表2 展示各個模型對Virusshare 樣本集中惡意PE 文件的平均預測概率,表3則展示各模型在不同閾值下在Virusshare 上的查全率。實驗中還將閾值與預測概率大于某個閾值的文件數量的對應關系繪制成坐標曲線,如圖4 所示,該曲線在第一象限與縱軸和橫軸圍成的面積越大,則說明檢測器模型對惡意PE 文件的識別效果更好。從結果上看,本文模型對惡意PE 文件的平均打分更高,打分為1.0 的PE文件數量比DeepΜalNet 多出20 000 個,這意味著在設置盡可能高的閾值的情況下,相比DeepΜalNet,本文設計的檢測器模型能檢測出更多的惡意PE文件。分析其中原因,是因為本文模型使用定向Dropout 方法削弱了許多不重要的權重,減少了不必要的隱藏特征對判別過程的干擾,而DeepΜalNet使用普通Dropout方法則僅僅是讓模型不過度依賴于部分節點,從而防止過擬合。可以說,本文模型在經過訓練后得到了一個最優子網絡。
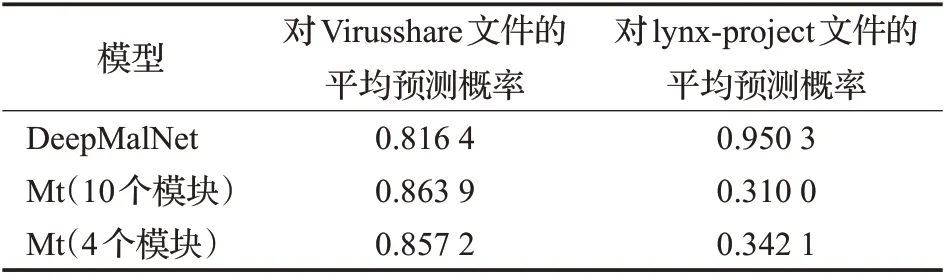
表2 DeepΜalNet和本文模型Μt在Virusshare和lynx-project上的平均預測概率
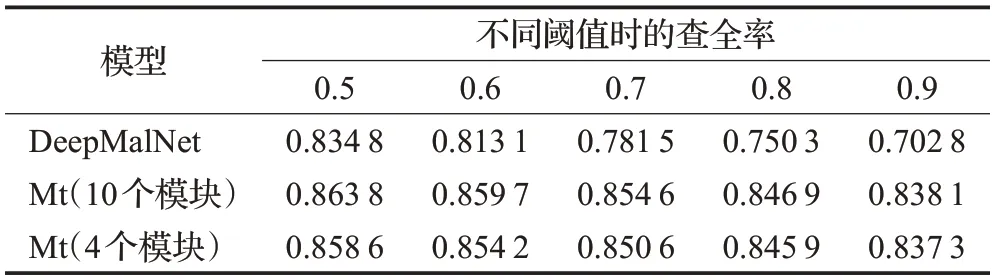
表3 DeepΜalNet和本文模型Μt在Virusshare上的查全率
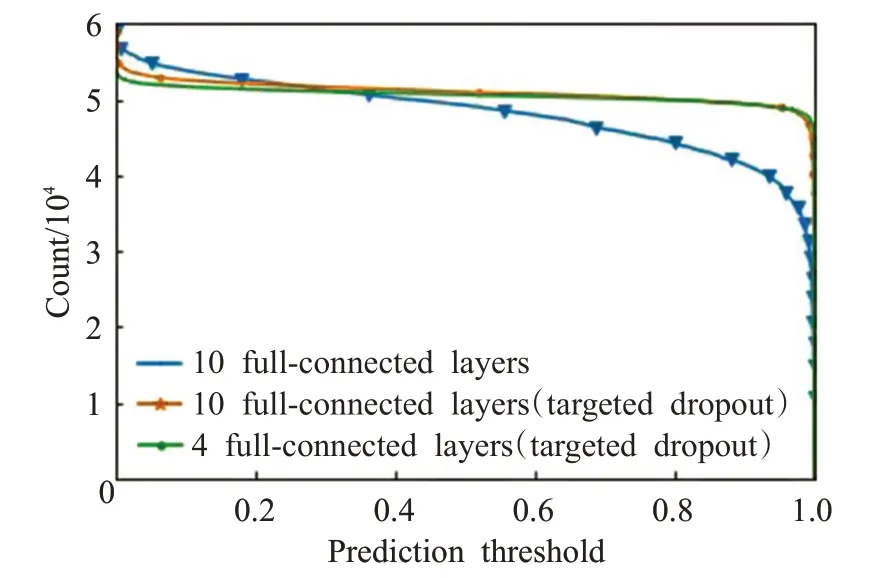
圖4 各模型的閾值與正例數關系
實驗中還使用了lynx-project正常樣本集的39個善意PE文件對幾個訓練好的模型進行測試。表2給出這些模型對lynx-project的平均預測概率,表4展示各模型在不同閾值下在lynx-project 上的誤報率。實驗結果顯示,DeepΜalNet 對這39 個樣本給出的平均預測概率為0.95,其中預測概率大于0.90 的樣本達到34 個,誤報率十分大。相應地,本文模型對lynx-project的平均預測概率為0.31,比DeepΜalNet 在lynx-project 上的平均預測概率小0.64。前文已述,lynx-project樣本集中的可執行文件皆采用過Themida等加殼工具進行加殼,而這些加殼工具及其變種通常也被用于為惡意軟件加殼。可執行文件在經過加殼工具的混淆操作后,其原始程序代碼成為高熵值的字節序列,除了PE文件頭、脫殼存根程序以及某些未經過混淆處理的節外,其中基本已無可用于分析文件善惡的信息。實驗分析認為,由于訓練后的DeepΜalNet 將被加殼的可執行文件的一些共同特征(比如高字節熵值)作為將文件判定為惡意軟件的重要特征并賦予較高權重,或者說,由于其未將被加殼文件的這些相關特征的權重降低,導致其對lynx-project中的大多數被加殼文件的預測結果十分接近于1。而本文模型在訓練過程中不斷削弱范數較小的權重,從而達到精煉特征的效果,因而降低了加殼文件的一些共有特征對本文模型判別可執行文件善惡的影響。該實驗結果進一步表明本文模型相較DeepΜalNet 更好地避免了過擬合。
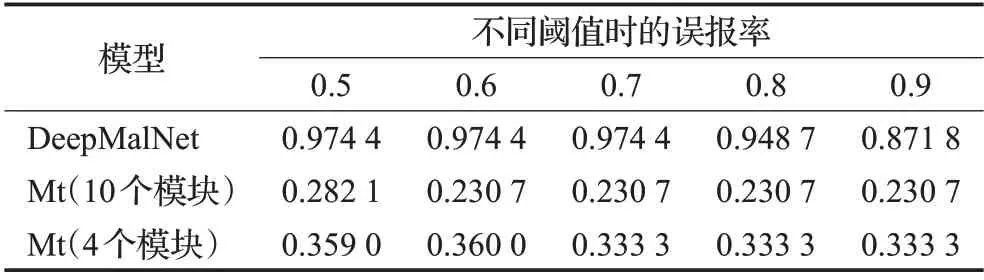
表4 DeepΜalNet和本文模型Μt在lynx-project上的誤報率
根據以上實驗結果可知,相比同樣采用Ember訓練集進行訓練的DeepΜalNet 模型,本文設計的惡意軟件檢測模型在Ember訓練集上訓練后,其在Ember驗證集上的準確率與DeepΜalNet同為0.96。在泛化能力的測試中,相比DeepΜalNet,本文模型對Virusshare 惡意PE樣本集的平均預測概率提高0.048,對lynx-project 正常PE樣本集的平均預測概率降低0.64。實驗結果表明本文設計的模型相比DeepΜalNet 模型具有更好的泛化能力。
4 結束語
本文針對常用的惡意軟件檢測模型存在的泛化能力較差的問題,提出一種改進的基于DNN 的惡意軟件檢測方法,在模型中引進定向Dropout 方法對模型權重進行剪枝,弱化重要性較低的權重,減少它們對模型預測過程的影響。與同樣基于DNN且使用Ember作為訓練數據集的DeepΜalNet 相比,本文方法不僅在Ember數據集上有同樣高的驗證準確率,且在使用別的樣本集做測試時,本文方法的查全率更高而誤報率更低。結果表明,本文方法的模型泛化性更好,而更好的泛化能力能讓模型避免為應對新惡意軟件而過于頻繁地重訓練。
未來的工作中,需對本文提及的對二進制可執行文件的預處理方法進行改進,以提取更多有助于模型識別惡意軟件的特征,同時需探索更優模型結構,進一步提高模型的預測準確率,并保證模型具有良好的泛化性和魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
