基于智能語音識別技術在醫療病歷錄入領域的應用探索
2021-06-04 09:23:50趙媛媛
科技經濟導刊 2021年14期
趙媛媛
(長治醫學院 生物醫學工程系,山西 長治 046000)
1. 語音識別技術在醫療領域應用的可行性
隨著深度學習算法的日益發展,建立在信息化普及及行業大數據基礎上的人工智能技術將有可能比以往更能在醫療領域內解決實際問題并獲得前所未有的成功。其次,近年來,我國也出臺一系列政策、建議,不斷推動人工智能在醫療領域的快速發展。2017年12月,國家衛生健康委印發的《醫院信息化建設應用技術指引》中,明確了人工智能技術在醫院可開展疾病風險預測、醫學影像輔助診斷、臨床輔助診療智能健康管理、醫院智能管理、虛擬助理等6大種類應用建設。其中,第259項虛擬助理,指按醫生指令和需求搜集、整理和推薦信息,支持語音識別、自然語言處理等引擎,支持基于機器的智能分診、輔助診斷、電子病歷書寫等功能,支持基于知識圖譜的智能輔助診斷和用藥推薦等功能。即明確了語音識別技術在醫療領域的應用的可行性。
病歷收集和整理臨床資料的重要途徑之一,也是醫學臨床研究的重要組成部分。對醫生來說,病例的重要性不言而喻。電子病歷的根本目的是將醫生從繁多、繁瑣的文字工作中解放出來。但由于不同醫院的信息系統搭載的系統數據、模板、檢查方式等不夠科學嚴密,導致有50%以上的住院醫生平均每天用于書寫病歷的時間長達4小時[1],且該數據仍在增長中。尤其是門急診處作為醫院病人流轉率較高的兩個部門,每天要處理大量病人,如此的電子病歷錄入時間,將會極大縮短醫生與病人的有效溝通時間,減少病人流轉率。若將智能語音識別技術應用于病例錄入領域,進行實時的文字記錄,將能更加及時、準確地記錄患者在就醫過程中的主訴癥狀、既往病史、診斷結果、診療過程,進而大幅提高醫生的工作效率。
2. 語音識別技術的基本原理
語音識別是一門交叉學科,涉及到信號處理、模式識別、概率論和信息論、發生機理和聽覺機理等領域。作為模式識別的分支之一,其根本目標是利用各種技術、算法,對原始語音信號進行處理、訓練,形成參考模型,根據該參考模型,實現對后期捕捉到的語音信號的分類和解釋。其基本的原理如圖1所示[2],主要包括兩個階段:訓練階段和識別階段。訓練時,對語音段預處理后,進行特征提取,形成每個使用者的模型參數,同時進行模型的存儲,形成語音數據庫。識別時,對被識別信號預處理后,提取其特征參數,并與之前訓練階段產生的參數模型比較,根據一定的搜索和匹配策略,得到結果并輸出。由此可見,語音識別的準確率與選擇的特征、語音模型、與處理結果都有關系,缺一不可。
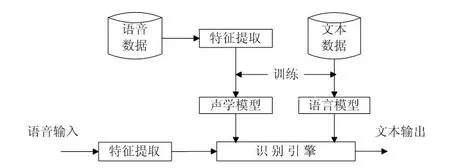
圖2. 1 語音識別基本原理圖
3. 語音識別技術在醫療病歷錄入領域的應用
3.1 國外應用現狀
在發達國家,已有相對成熟的語音識別產品進入醫院系統,為醫生緩解病歷書寫的工作壓力。比如專門從事語音識別軟件、圖像處理軟件及輸入法軟件研發的Nuance公司的英文語音產品Dragon NaturallySpeaking9,其覆蓋全美72%的醫療機構,最高語音識別率達99%,輕松實現醫生口述患者病例,設備自動記錄功能。Amazon公司開發的語音助手Alexa不但能夠回答醫療問題,提供醫療信息,還可以集成到電子病歷中,成為一個被動的記錄者,實現高效的信息錄入。初創于2015年的Saykara,其團隊專注于語音識別技術在電子病歷上的應用,其推出的人工智能語音助手可以自動創建文檔,簡化工作流,讓醫生更容易與EMR系統進行交互。數據表明,使用SayKara的醫生在管理電子健康記錄上花費的時間減少了70%。
3.2 國內應用現狀
我國的語音識別技術在醫療領域內起步較晚,但近幾年已取得長足發展。2017年,科大訊飛與中國醫學科學院北京協和醫學院簽署全面戰略合作框架協議,即科大訊飛的口腔科語音電子病歷系統正式在北京協和醫院投入使用。該系統包括一個可以夾在醫生領口的醫學麥克風,一個可以裝在醫生口袋的發射器,還有一個可以插在醫生工作電腦上的接收器。在接診過程中,醫生只需要以口述的方式說出患者的病歷,醫生的工作電腦上就會自動生成結構化的電子病歷。之后,只需醫生對電子病歷內容進行簡單修改確認,即可打印提供給患者,并完成電子檔案保存。
云知聲智能醫療語音錄入系統以面向醫療領域的高性能識別引擎為基礎,通過語音和手持設備上的功能鍵與醫院內HIS系統交互。醫生通過語音錄入的方式,規范病歷輸入,增加病歷輸入安全性。目前,云知聲已在多家代表性的大型綜合三甲醫院正式上線使用,這些醫院分布在全國各地、各區,具有極強代表性。根據統計的使用數據,該系統的使用有效節省醫生約38%的時間,相當可觀。
4. 關鍵技術
4.1 前端語音數據處理技術
語音數據的前端處理包括端點檢測、特征參數提取兩個部分。醫療系統的病例的關鍵字可看作是孤立字或孤立詞類。因此,準確獲取有效語音信號的開始點及結束點,作為正確處理語音信號的基本問題及進行語音信號預處理的前提在孤立詞識別中尤為重要。目前,語音信號端點檢測方式主要包括短時能量、短時平均過零率、短時自相關、頻域端點檢測等。其中,短時能量需要選擇合適的窗函數;在噪音的相關性呈現下降趨勢時,短時自相關函數對噪音和靜音的區分能量較弱;環境噪聲較大或變化劇烈的情況下,頻域端點檢測方式要更理想一些。根據以上方式的優缺點,在實時處理醫療系統的病例信息時,要根據不同的科室需求,選擇不同的前端語音數據處理技術。這意味著想要在整個醫院病例領域應用語音識別技術來獲取信息,需要設計多種前端數據處理模塊來滿足需求,這在技術上是一個難點。
原始有效語音信號所攜帶的數據量巨大,對于硬件系統的運算負擔過重;此外,原始語音信號還包含了諸如噪聲等大量隨機因素,這些因素對系統的識別率有很大影響。提取適合的語音信號特征參數,可以有效降低信號冗余度,使得模板訓練和模式匹配的數據特征更加明顯,減輕系統運行負擔。當前,在語音識別技術中,常用的特征提取方法是梅爾倒譜系數MFCC、線性預測倒譜系數LpCC。兩種算法各有優點。但在我國醫療系統內,以漢語為主,需要對輔音部分有較強的分辨能力,同時考慮到語音信號的價值信息多集中在低頻部分,在有信道噪聲的環境中,更需要追求高識別率,MFCC算法更有優越性。
4.2 基于HIS系統的語音數據傳輸協議及通信機制
電子病歷系統屬于醫院信息管理系統HIS的一部分;而HIS系統本質上屬于分布式管理系統,且其內部數據屬于局域網內部的傳輸數據。要將語音識別技術嵌入到該系統中,實現應用,則語音數據必須遵循醫療系統內部客戶端與服務器端之間數據傳輸的相關協議(即使用語音識別技術調用客戶端程序軟件,比如實時傳輸協議(Realtime Transport protocol,RTp)。
RTp是由IETF的多媒體傳輸工作小組于1996年公布的網絡傳輸協議,該協議詳細說明了在互聯網上傳遞音頻及視頻的標準數據包格式,為數據提供了具有實時特征的端對端傳送服務。但其本身沒有提供按時發送機制及其他服務質量保證,即該協議不保證數據傳送及底層網絡的可靠性。因此需要和RTp控制協議RTCp一起使用,來監控服務質量并傳送正在進行的會話參與者的相關信息。
其次,將語音識別技術應用在HIS系統中,本質上也屬于網絡中的本地進程間的通信方式。而這樣的通信方式有很多種,包括但不局限于消息傳遞、共享內存、遠程過程調用等。根據RTp控制協議創建在UDp協議之上,而UDp協議與TCp協議相對應的特征要求,將語音識別技術應用在HIS系統內的病歷書寫領域,選擇并建立合理的基于Socket傳輸機制的服務端與客戶端的通信方式也是其關鍵技術之一。
4.3 服務端語音識別技術
語音識別的最終結果即要求在服務端找到一個相匹配的模型序列,以求真實、準確地描述輸入的語音信號的語義。常用的識別搜索技術有動態時間規整技術DWT、矢量量化技術VQ、隱馬爾可夫模型技術HMM、人工神經網絡技術ANN等。其中,DWT技術的識別性能過分依賴于端點檢測,同時需要與所有模板進行匹配,工作量大;VQ技術的信息保密性能較強,但訓練過程的計算方法復雜;ANN技術具備良好的容錯性和學習特征,但對語音信號的動態時間特性描述力較差。HMM技術雖然相較于其他技術,更貼近人類語音活動的隨機性,識別率更好,但在中文語音識別中,因其發音、語法相較于英文具有較強特殊性,導致單一的識別技術在實際應用中并不能取得良好的識別效果。為適應更多的應用場景,提高識別率,增加通信數據安全性,通常的方式是將不同的識別技術進行組合。
5. 存在問題
將語音識別技術應用于門診病歷錄入領域,其主要目的是實現醫療報告的實時輸出,提高醫生工作效率。考慮到醫療門診信息的特殊性,該技術的應用需要更側重于強實時性、高準確率及數據傳輸的安全可靠。但由于智能語音識別技術本身發展時間短,醫院信息化建設尚未完全成熟,因此,在兩者結合過程中仍有太多問題亟待解決。
首先是環境噪聲問題。在門急診部,外部環境噪雜,語音識別的干擾項多,在預處理階段,目前仍未有理想處理方法能進行完全去噪。這將大大影響最終的識別結果。其次,在當前的語音處理技術中,尚無法解決多音字、協同發音[3]及地方性口音問題,在引入并合理使用語言模型及聲學模型之間的自適應技術方面,仍有太多內容需要深入研究、探索。第三,在門診部門,不同科室有不同的專業詞匯,且量巨大,開發該項技術應用,需要建立包含這些詞匯的識別數據庫并且能實時擴充,此種情況下,識別過程的計算量許將呈指數增長,為算法程序及傳輸硬件帶來更大的新挑戰。
6. 結語
本文討論了智能語音識別技術在門診病歷錄入方面的應用的技術關鍵點及難點,并對建立符合HIS系統要求的分布式語音識別服務程序提出了建議。隨著技術的發展,希望醫護人員能夠充分使用語音技術實現文字輸入工作,進一步解放雙手,提升工作效率。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
鴨綠江(2021年35期)2021-04-19 12:24:18
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
家庭影院技術(2017年9期)2017-09-26 03:41:45
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
