一種基于端到端模型的中文句法分析方法
2021-06-22 03:03:32邵幫麗奚雪峰付保川
蘇州科技大學學報(自然科學版) 2021年2期
關鍵詞:模型
楊 顥,徐 清,邵幫麗,奚雪峰*,付保川
(1.蘇州科技大學 電子與信息工程學院,江蘇 蘇州 215009;2.蘇州市虛擬現實智能交互及應用技術重點實驗室,江蘇 蘇州 215009;3.蘇州市公安局,江蘇 蘇州 215131)
句法分析作為自然語言處理中的一項核心任務,對信息抽取、自動問答及機器翻譯等自然語言處理上游任務起著重要的作用。句法分析就是識別出句子中所包含的句法單位以及句法單位之間的相互關系,并將分析結果自動表示成句法樹結構。其主要工作可看作是從連續的句子線性序列到具有形式化樹結構的轉換任務[1]。
句法分析工作最早開始于20 世紀50 年代,人們在進行機器翻譯任務研究時發現必須找到一種更深層次的句子表達方法,便開始了自然語言句法結構分析任務的研究。目前的句法分析方法主要分為基于規則和基于統計兩大類[2]。英文句法分析任務開始較早,同時有認可度較高的數據集支持,其中具有代表性的如美國賓夕法尼亞州大學標注的賓州樹庫[3],因此新的算法往往首先在英文數據集上進行實驗,最終延伸到其他語言的研究。Cross 等人[4]結合LSTM 神經網絡基于句子成分的跨度(span)提出了一個移進歸約的系統,在英文賓州樹庫上的實驗結果F1值為91.30%,法語上F1值為83.31%;Socher 等人[5]則使用了一個結構遞歸的神經網絡(Recursive Neural Network,RNN)來學習句法樹中的遞歸結構,也取得了一些成果;Hall 等人[6]提出直接從句法樹表層提取有效特征而不是通過分析句法樹內部標記關系,將句法分析工作的難點轉化成了特征工程,從而不需要考慮句法問題,大大降低了句法分析算法的復雜度,其F1值達到了89.2%。
相對于英文句法分析,中文句法中語義關系更加復雜,同時因為缺乏較為成熟的標注理論,標準漢語樹結構語料庫的建設也相對滯后,這使得漢語的句法分析技術發展緩慢[2]。Fung P 等人[7]采用轉換學習的方法進行分詞/詞性標注,用極大熵模型識別短語,在第一版CTB 上測試F1值達到了75.09%;徐潤華[8]首先自行構建了一個具有百萬級別搭配型的詞語搭配知識庫,將詞語搭配知識和基于句法功能匹配的句法分析算法相結合,構建了一個基于詞語搭配知識和語法功能匹配的句法分析器(CGFM),在新華社新聞語料開放數據集上F1值約80%。
因為中文相對復雜的語法結構,中文的句法結構分析大都聚焦于對句子進行分詞和詞性標注,分詞和詞性標注的好壞直接決定了分析器的好壞。基于這一現狀,筆者嘗試采用雙向LSTM 神經網絡,并引入注意力機制[9],提出一種深度的端到端模型,將分詞、詞性標注及句法結構放在一起分析,簡化了句法分析任務,降低了研究人員在分詞和詞性標注上的專業性要求。在中文標準數據集CTB9 上的實驗表明,具有一定可行性和較好的識別率。
1 任務描述
1.1 CTB 理論
CTB 項目1998 年開始于賓夕法尼亞州大學,自2001 年發布Chinese Treebank 2.0 以來,16 年發布的最新版Chinese Treebank 9.0 已經成為了一個具有多樣化數據來源且數量龐大的中文句法結構數據集。賓州英文樹庫(PTB)的建立,驗證了英文詞性標注及語法分析器English Part-Of-Speech(POS)Taggers 和Parsers的可用性,為中文樹庫的發展奠定了基礎[3]。中文樹庫建設團隊借鑒英文樹庫經驗并尋求專業的中文語言學家的幫助,最終將樹庫的標注任務劃分為分詞、詞性標注和切分短語結構三個子任務,以實現對不同層次的句法成分組合特點進行細致的描述[10]。其標注策略沿用了英文骨架分析(skelton parsing)的思想,形成比較扁平的句法結構樹,并對短語的功能進行了標記[11]。CTB 結構如圖1 所示。

圖1 CTB 數據集結構
1.2 任務說明
人工將大量的普通中文語句標注成標準化的句法結構樹,將耗費巨大的人力物力。同時即便有統一的標注存在,但其中仍然存在著標注人員個人的主觀色彩,不可避免的使得最終的標注標準化結果間存在差異。該文的主要任務是借用深度神經網絡,完成從自然語句到標準化句法結構樹的自動生成標注工作。
2 模型
2.1 預處理
中文樹庫的數據集分為raw、segmened、postagged、bracketed 四個部分,文中選取了其中raw 和bracketed兩部分作為原始數據來源。利用word2vec 模型對原句進行詞向量轉換[12],并將原數據轉換成包含原句及其對應的樹結構的二元組作為神經網絡的輸入來訓練模型。最終實現輸入原句得到相應的樹結構的效果。
2.2 算法流程
如圖2 所示,文中所采用的方法,首先,將CTB 數據集原始數據轉換成標準的二元組作為輸入,該二元組包括原始句子及其對應的句法分析樹;然后,通過Tuple2Instance 方法,將標準二元組轉化成模型的輸入Instance,每一個Instance 包括句法樹中的句子關系、短語關系、詞性標注、分詞四個部分;接著,將Instance 作為輸入,訓練下文所提到的Encoder-Decoder 模型;最后,經過調參及訓練得到最優模型。
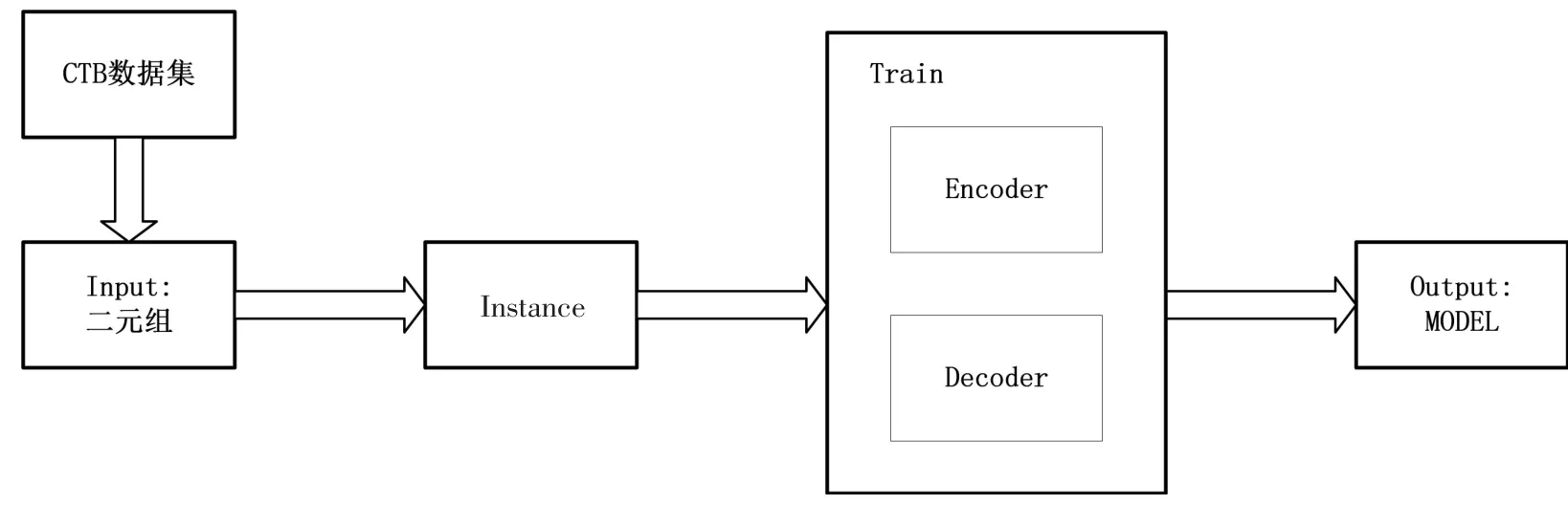
圖2 算法流程圖
2.3 模型結構
將樹結構的自動生成看作一個Seq2Seq 任務[13],輸入中文自然語句X=(x1,x2,…,xn),其中xi表示句子中的第i 個單詞,n 表示句子長度;輸出序列Y=(y1,y2,…,ym),其中m 表示得到的樹結構序列長度。希望由給定的輸入序列X 得到語義解析樹Y 的條件概率p(Y|X)

其中yj表示輸出序列中的第j 個token,Y1j-1表示輸出序列中的第1 個到第j-1 個序列,表示輸出的自然語句。筆者針對這個Seq2Seq 任務,結合CTB 的結構[10]表示和Liu 等人[14]相關工作提出了一種Encoder-Decoder 模型。模型結構如圖3 所示。

圖3 文中模型結構
2.3.1 編碼結構
文中采用雙向的長短時記憶網絡(bi-LSTM)作為編碼器[15],意在通過該編碼器將輸入的中文句子Χ 轉化成向量表示。首先,將句子中的每一個token xi都轉化成一個向量表示,其中表示隨機初始化的詞嵌入,表示預訓練的詞嵌入,W1表示(dw+dp)×dinput維度的矩陣,其中w、p 和input 分別表示分詞的詞向量、預訓練的詞向量和輸入分詞的維度,b1是一維n 列的隨機向量,“+”表示將橫向拼接在一起。最終通過該編碼器得到句子的隱層單元表示

2.3.2 深層解碼結構
實驗證明,輸入序列的長度將對神經網絡的預測結果產生一定影響,而自然漢語語句標注成標準的CTB 樹結構后,其長度增加了不少。在文中的測試集上統計顯示,自然語句的平均長度為30,標注過后的樹結構平均長度為99。筆者對CTB 樹結構分析發現,每個樹結構序列中包含Syntactic Brackets、POS tags、分詞三個部分。基于此結構,文中提出了一種深層解碼結構,將CTB 樹結構序列拆分成以下三個層次,分別為分詞,其中p、u、v 分別表示對應的個數。每個部分在端到端框架下分開進行解碼預測,其概率分布可表示為
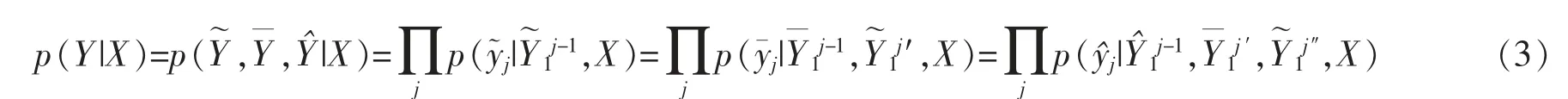
①Syntactic Brackets 預測
在這里采用了一個序列解碼器如圖3 第一層上所示,預測結構中的每一個token 對應樹結構中的父節點,詞條間關系及詞條詞性當作其子節點,以插入的機制插入合適的位置,該解碼器的隱層單元如下

結構中的token 的概率分布表示如下



其中權重βji為

②POS tags 預測
POS tags 的預測與之前所做的Syntactic Brackets 預測密切聯系,在每個Syntactic Bracket 中可能包含著k 個分詞和k 個POS tags,因此,可以將POS tags 表示為,其中表示第k 個中的第mk個POS tags。
其詞向量表示

故該解碼器的隱層單元表示如下

POS tags 預測的概率分布如下

③分詞預測
分詞的預測基于Syntactic Brackets 和POS tags 預測,每一個關系內僅對應一個分詞。故分詞序列可表示為;詞向量表示為。POS tags 的隱藏單元的輸出作為分詞預測的輸入,其解碼單元隱藏層如下

分詞預測的概率分布如下

3 實驗
3.1 實驗選取的數據
中文樹庫共包含來自于報刊新聞、雜志文章、廣播會話等八個大類的3 726 條數據(見表1)。該次實驗分別選取了新聞、雜志文章及微博三個大類的1 155 篇文章作為數據的原始輸入。此外筆者對這1 155 篇文章進行了簡單的數據清洗,選取了其中句子長度在20 到80 之間的句子,并且去除掉了其中含有特殊符號及網址的句子,最終得到了10 012 條數據,共包含23 198 個字符。并通過word2vec 將數據訓練得到100 維的詞向量。文中選取了10 012 條數據中的7 288 條數據作為訓練集,1 724 條數據作為驗證集,1 000 條數據作為測試集進行實驗。

表1 CTB 數據來源及分布
3.2 參數設置及實驗設備
筆者的實驗軟件采用Python(2.7.12 版本)、Pytorch(1.1.0 版本)、CUDA(10.1 版本),實驗操作系統為Ubuntu16.04;硬件計算平臺采用英特爾I5、16G 內存、英偉達GTX2080TI、11G 顯存。實驗模型在J.M.Liu[14]模型基礎上,經過預處理等代碼修改后形成該系統模型代碼(模型開源代碼地址:https://github.com/dressnotycoon/Chinese-syntactic-analysis/)。
3.3 算法對比系統
與文中實驗模型相比對的系統有如下五類:
①HMM+中心驅動模型[16]采用傳統機器學習方法,首先,應用基于隱馬爾科夫模型(HMM)的方法進行一體化的分詞/詞性標注;然后,利用中心驅動模型進行短語識別。在賓州中文樹庫CTB1 數據集上取得了F1值76.4%的成果。
②K-best 句法分析器融合算法[17]提出了一個基于線性模型的通用框架,以結合來自多個解析器的k 個最佳解析輸出。通過將當時表現最好的頭部驅動的詞法化模型和基于潛在注釋的非詞法化模型相結合,在賓州中文樹庫CTB5 上F1值為85.5%。
③向上學習方法改進的移進-歸約算法[18]在傳統的移進-歸約句法分析系統上進行改進,首先利用伯克利句子分析器對大規模的無標注數據進行自動標注,將標注的結果再作為改進分析器的額外訓練數據,在賓州中文樹庫CTB5 上F1值為82.4%。
④基于條件隨機場模型的分塊算法[2]將漢語句法分析分為三個階段:首先,基于條件隨機場模型將句子分塊;其次,對各句子塊進行句法分析得到句子塊級別的句法樹;最后,將各句子塊句法樹整合成完整的句子結構樹。在賓州中文樹庫CTB8 上F1值為75%。
⑤抽取lookahead 特征的移進-歸約算法[19]利用一個快速的神經模型來提取前向特征,并構建了一個雙向的LSTM 模型,該模型利用完整的句子信息來預測每個單詞的開頭和結尾的成分的層次結構,在賓州中文樹庫CTB5 上F1值為85.5%。
3.4 實驗結果
這里筆者使用精確率、召回率、F1值[20]來評價文中模型的優劣,其中精確率表示預測的結果中正確的短語結構個數,計算公式為

召回率表示我們預測結構的全面性,計算公式為

精確率和召回率通常情況下相互制約,因此,筆者按照評價習慣引入了F1值來平衡兩者關系,即

首先對在驗證集上得到的F1值分布進行了統計,如圖4 所示。其中F1值超過0.9 的數據占總測試數的13.6%,且這部分平均的F1值為0.956;F1值超過0.8 的數據占總測試數據的47.3%,且平均F1值為0.876;F1值超過0.7 的數據占總測試數據的82.1%,且平均F1值為0.826。

圖4 F1 值分布
此外,該文也對驗證集上不同長度的語句的F1值進行了統計分析。文中驗證集的句子長度在5 到60 之間,平均長度為29,如圖5 所示,發現當句子長度增大的時候不管是精確率還是召回率都緩慢的降低,其中在句子長度小于20 的時候表現較好,但是整體上維持在一個不錯水平,F1值保持在0.70 以上。
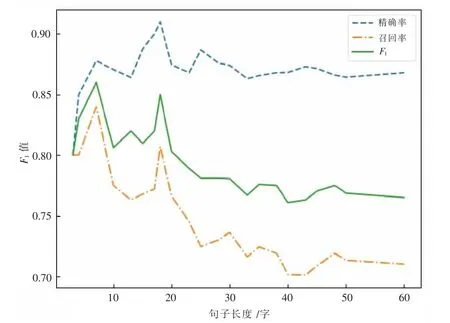
圖5 不同長度的語句的F1 值、召回率及精確率
最后選取了同樣使用賓州中文樹庫CTB作為數據集的算法系統,與文中所提到的方法進行了對比。由表2 可見,模型1 由于賓州中文樹庫CTB1 發布較早、數據量較少,因此結果相對較差。模型2 由于融合了當時表現極為優秀的句法分析系統,因此也有較好的結果。模型3和模型5 均針對移進-歸約算法做出了一定的修改,其中模型3 將其他句法分析器得到的分析結果作為自己分析器額外的訓練數據,其他分析器的精度也將影響其分析器本身的結果,故其F1值略低于模型5。模型4 將句子分塊操作,再整合各塊句法子樹的方法,在一定程度上影響了句子的完整性,其在CTB5 上的結果較差,但針對其文中提到的特定信息檢索系統有一定幫助。由表2 可知,模型6 具有可行性且具有一定分析效果,但仍然有進一步提升的空間。未來繼續增加訓練數據,相信將得到更好效果。

表2 算法系統對比
4 結語
深度學習及神經網絡算法給句法分析任務提供了新的方法和可能,但完全的中文句法結構分析任務仍然是中文信息處理中的一個難題。目前還面臨著諸多的難題,比如:缺少相關的樹結構數據集、照搬英文的標注理念是否完全適合中文的語法習慣等。文中采用的深度學習算法,直接提供了一種序列到序列的轉換方法,使研究人員不需要再對中文分詞及詞性標注做太多的工作,但是仍然需要依賴龐大的數據量。未來將逐步擴大訓練的數據量,并探索新的方法,能夠更好的適應中文特有的句法結構,以期望進一步提高分析器的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
