基于特征重整及優化訓練的遮擋人臉識別算法
2021-06-24 07:30:36鄒鵬楊治昆李鍇淞
大連交通大學學報 2021年3期
鄒鵬,楊治昆 ,李鍇淞
(1.東北財經大學 網絡信息管理中心 遼寧 大連 116025;2.浙江宇視科技有限公司 研究院,浙江 杭州 310051)*
隨著人臉識別算法的不斷成熟,其在越來越多的應用場景中發揮積極作用,如證件查詢,出入考勤查驗,人臉支付等,另外在治理交通痼疾“闖紅燈”問題上也大顯身手.早期的人臉識別典型算法有模板匹配法,PCA(主成分分析法)和LDA(線性判別分析)等,但是這些方法對訓練集和測試場景、光照、人臉的表情等因素比較敏感,泛化能力不足,不具備太多的使用價值.之后的人臉檢測算法普遍采用了人工特征+分類器的思想,常見的描述圖像特征有HOG,SIFT[1],LBP,Gabor等,典型的代表特征是LBP(局部二值模式)特征,這種特征簡單卻有效,部分解決了光照敏感問題,但還是存在姿態和表情的問題.現階段主要的方法是基于深度學習的方法,利用卷積神經網絡(CNN)對輸入的人臉圖片進行學習,提取出區別不同人的特征向量,替代人工設計的特征.DeepFace是CVPR2014上由Facebook提出的方法,使用3D模型來完成人臉對齊任務,然后使用深度卷積神經網絡對對齊后的人臉進行分類學習,最終在LFW上取得了97.35%的準確率,由于采用了多層局部卷積結構,產生了大量的參數量,且對數據量要求很大,因此應用有很大的局限性.FaceNet是由谷歌公司推出的關于人臉識別的算法,其使用三元組損失函數(Triplet Loss[2]代替常用的Softmax交叉熵函數,同時使用了Inception[3]模型,產生的參數量較小,在LFW取得了99.63%的準確率.可以看出基于深度學習的人臉識別算法已經較好地解決了多數場景中的人臉識別任務,效果堪比人眼.但是實際應用中總是會存在人臉受到遮擋(如戴口罩,帽子),導致特征發生缺失,以上方法在解決這類問題時,效果差強人意.
本文以ResNet50網絡為基礎模型,提出了基于信息熵的權重特征來優化池化層特征的方法對卷積層的特征信息進行聚合增強;同時提出了一種改進型PSO算法對CNN誤差反傳階段的初始權值進行優化,實驗結果表明改進后的模型對識別結果有所提升,尤其是對于遮擋人臉識別,效果明顯.
1 基于信息熵的權重特征表示優化池化層特征
近年來,深度學習技術已經在圖像處理,自然語言處理等方面取得了突出的成績,并且在多個領域的工程應用中取得了較大的突破.然而在使用卷積層訓練網絡時,在對卷積層輸出的特征圖進行處理時,往往會使用池化層對特征圖進行采樣操作,通過對不同位置的特征進行聚合,從而達到減少卷積特征的目的.而且對模型網絡進行設計的時候,對圖像特征聚合的好壞,也會直接影響網絡訓練的收斂速度和其魯棒性.在此,本文提出的一種基于信息熵的權重特征表示的卷積計算方法.通過對需要池化的卷積做類似信息熵的計算方式,將需要池化的區域進行基于信息熵的方式特征聚合,對特征的信息進行進一步的聚合,使得到的新的特征信息表達與原特征保持一致聯系,從而保證信息特征表征的最大化.算法流程如圖1所示.
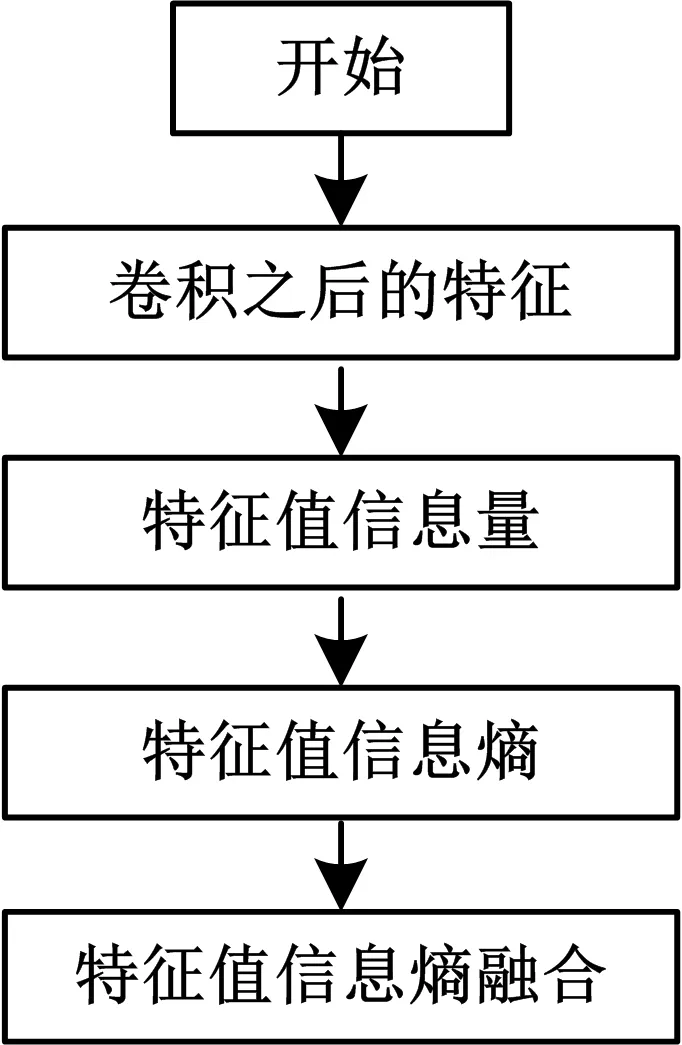
圖1 基于信息熵的權重特征聚合流程
具體流程如下:
首先得到卷積之后的特征,然后對卷積之后的每個特征值,選擇合適的濾波器的大小,對每一個特征值先求取特征值所占的概率P(xi),如若卷積之后的特征是一個2×2的矩陣,里面的特征值分別標記為x1,x2,x3,x4,則對任意一個特征值的概率值為:
P(xi)=xi/∑(xi)
(1)
故對卷積之后的特征是任意一個n×n的矩陣,里面任意一個特征值概率值為:
(2)
通過該特征的概率值進行信息量的求取.特征值信息量求取如式(3)所示.
(3)
當取得特征值信息量后,對特征值的所有信息作熵處理,信息熵求取公式如式(4)所示.
H(x)=-∑log(P(xi))P(xi)
(4)
得到特征值的信息熵后,將信息熵和特征值信息作進一步融合.最后融合到的新的特征值計算公式如式(5)所示.
Feature(x)=H(x)·xi
(5)
通過對卷積后的特征進行聚合,結合了不同特征之間的聚合能力,也充分使用了同一特征的強度信息,使其擁有更充分的表征能力.運算效率高,不會增加新的參數,使提取的網絡特征更加充分.
2 基于PSO和GSA優化的CNN算法的方法
一般的CNN 網絡都采用梯度下降算法,梯度下降法是一種快速的局部搜索算法,它能使得算法快速收斂。PSO是在CNN網絡優化中比較有效的方法之一,它具有信息共享能力和收斂速度快等特點,但是全局搜索能力較差.GSA是全局智能搜索算法,實現了位置的調整和對空間中最優解的搜索.利用PSO的記憶能力、信息共享能力和GSA的全局搜素能力進行融合,形成一種改進型PSO優化算法,在每次迭代中,計算利用此優化算法計算粒子的位置,并利用此位置更新CNN的初始權值,該算法的適應度函數作為CNN的誤差函數,以此對CNN的誤差反傳階段進行改進.
算法具體實現流程如圖2所示.
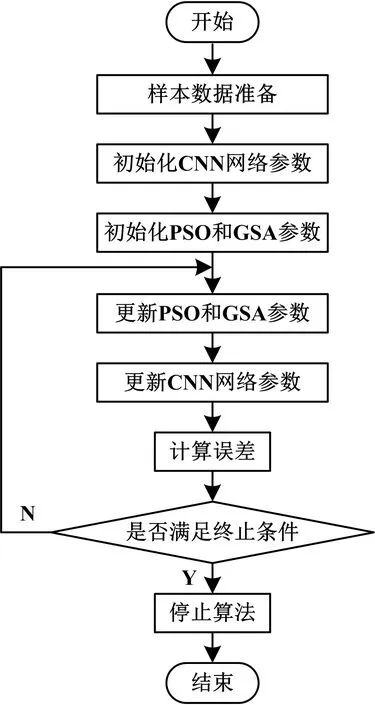
圖2 PSO-GSA 對CNN算法優化流程
算法的主要實現流程按照以下5步:
(1)樣本數據準備和初始化CNN網絡參數
(2)初始化PSO和GSA參數
初始化PSO和GSA參數時,設置α值為20,G0值為1,質量和加速度均為0,粒子規模N為25,迭代次數為1000, 加速系數、c1、c2、c3均為1.49,初始質量和加速度均為0,慣性權重w′從0.4~0.9線性增加,初始速度V為[0,1]間有間隔的隨機值.
(3)更新PSO和GSA參數
GSA和PSO 在每次迭代中,會根據如下步驟更新參數:
①首先計算引力常量G(t)和歐幾里得距離Rij(t).
G(t)=G0e-αt/tmax
(6)
Rij(t)=||Xi(t)Xj(t)||2
(7)
式中,α為下降系數;G0為初始引力常數;tmax為最大迭代次數;Xi(t)和Xj(t)分別表示第t次迭代中第i個粒子和第j個粒子的位置.
②計算粒子受其它粒子引力合力
(8)
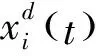
③計算適應度函數fi(t).
(9)
式中:m表示輸出節點數;q表示訓練樣本數;gi表示經訓練樣本訓練后的預測輸出;σ為訓練樣本目標輸出.
④計算粒子質量Mi(t).
(10)
式中:fi(t)表示粒子i在第t次迭代中的適應度函數值;best(t)表示粒子i在第t次迭代中的最好適應度值;worst(t)表示粒子i在第t次迭代中的最差適應度.
(11)
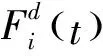
(12)
(13)
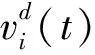
⑦計算PSO粒子最優位置gi,best.通過比較粒子i的改進最優解和原最優解的適應度值,取兩者適應度值較大的作為新的全局最優粒子.粒子i的改進最優解.
(14)
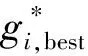
⑧計算PSO和GSA融合后的粒子的速度V.
(15)
式中:Vi(t)表示粒子i在第t次迭代中的速度;w′為慣性權重,用于均衡粒子的探索能力與開發能力;gi,best表示PSO算法在第t次迭代中粒子i最優位置的改進值,即局部極值的位置坐標;gbest表示PSO算法在第t次迭代中當前群體的最優位置,即全局極值的位置坐標;rand表示[0,1]之間的隨機數;c1、c2、c3表示加速系數,其數值被調整,可以平衡引力和記憶,以及社會信息對搜索的影響;a表示粒子i在引力合力作用下的加速度.
⑨計算PSO和GSA融合后的粒子的位置X.粒子i第t+1次迭代中的位置
(16)
式中:Vi(t+1)表示粒子i在第t+1次迭代中的速度;Xi(t)表示粒子i在第t次迭代中的位置.
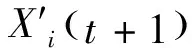
(4)更新CNN網絡參數
在每次迭代中,根據步驟(4)對GSA和PSO進行參數更新,并以得到的粒子位置X去更新CNN的權值W.
(5)計算誤差
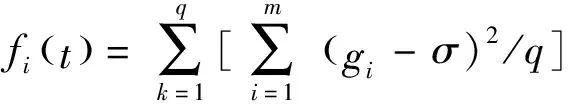
改進核心是將GSA和PSO優化方法結合,各取所長,最終形成一種搜索能力較強的改進型GSA算法.它的主要特點在于GSA的最優解是通過PSO的群體最優解和個體改進最優解共同作用獲得的.
4 實驗過程
4.1 實驗環境
本文中的實驗訓練和測試過程中主要是在服務器上進行的,顯卡為NVIDIA Tesla P40,深度學習框架為Tensorflow.
4.2 實驗數據及模型預訓練
常用的公開人臉數據集有很多,如LFW,PubFig等,LFW數據集一共包含了13 233張圖片,包含5749個人,其中有1 680個人有2張或者以上的圖片.為了提高模型的檢測精度,本文的實驗數據集有兩個,其中首先是在LFW數據集上進行模型預訓練,總共訓練11萬次,每次從訓練集中隨機抽取560張圖片,之后對自己采集的人臉圖片數據集約6 000張,1 000個id人使用預訓練的模型繼續訓練8萬次后進行測試.為了進一步檢測本文方法對遮擋人臉的檢測效果,本文使用40×40像素的方塊,對圖片進行隨機遮擋,并同樣的進行訓練.
4.3 實驗結果分析
為了方便表示,本文將基于信息熵的權重特征優化方法表示為方法一,將基于改進PSO優化方法表示為方法二,本文使用傳統ResNet50網絡,同時分別結合方法一,方法二在相同測試集中進行測試,具體結果如表1所示.

表1 實驗結果
從表1可以看出相對于傳統的ResNet50網絡,在同樣的測試環境和測試樣本下,方法一、方法二對ResNet50網絡分別有了0.47%,0.25%的提升,由于正面人臉特征較完全,ResNet50網絡本身效果較好,本文的算法對其改進效果不明顯,對于遮擋數據集,由于自身人臉信息不完整,導致ResNet50網絡識別準確率只有67.15%,結合本文所提算法后分別有了2.6%,3.08%的提升,最終識別準確率可以達到71.34%,提升結果較為顯著.
5 結論
通過以上結果看出,對ResNet50網絡使用信息熵的權重特征對池化層的信息進行優化,和對ResNet50網絡使用改進型PSO算法對誤差反傳階段的初始權值進行優化,可以明顯提高模型對人臉的識別精度,尤其是當目標人臉信息不完整時,效果提升更為明顯.同時本文改進算法在原始ResNet50的基礎上再不會增加額外參數,因此也不會對模型的速度產生影響.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
