基于Petri網(wǎng)的流程變體合并方法*
2021-06-25 10:05:58王吳松鄭雪文
計(jì)算機(jī)工程與科學(xué) 2021年6期
王吳松,方 歡,鄭雪文
(安徽理工大學(xué)數(shù)學(xué)與大數(shù)據(jù)學(xué)院,安徽 淮南 232001)
1 引言
流程變體(Porcess Variants)可以被定義為系統(tǒng)流程族(模型)中相似但不同(Similar-but- different)的模型,通過對這些模型進(jìn)行映射,從而發(fā)現(xiàn)這些模型間共同擁有的片段以及存在差異的片段。此時(shí),將從模型中通過映射發(fā)現(xiàn)的片段稱為模型的特征,即這些模型至少有一個(gè)共同的特征,也至少有一個(gè)特征可相互區(qū)分。從粗粒度的流程系統(tǒng)的角度分析,流程變體是流程族模型中從基模型衍生出的其他相似流程模型;從細(xì)粒度的流程系統(tǒng)的角度分析,流程變體是指各流程模型中那些具有某些共性同時(shí)又具備各自個(gè)性的模型片段。在組織合并、收購或重組的背景下,不同組織之間的業(yè)務(wù)流程往往存在著多種變體結(jié)構(gòu)。對于組織管理者來說,業(yè)務(wù)流程的諸多變體在組織管理時(shí)會(huì)耗時(shí)耗力,同時(shí)也會(huì)增加運(yùn)營成本。因此,將以前屬于不同組織或分支機(jī)構(gòu)的諸多流程變體進(jìn)行合并,使之成為特定業(yè)務(wù)背景下的單一流程模型,以此來消除冗余。使得不同組織或分支機(jī)構(gòu)能共同使用這一特定業(yè)務(wù)背景下的單一流程模型,從而降低運(yùn)營成本是具有一定實(shí)踐意義的。這種做法對于組織或分支機(jī)構(gòu)來說是有益的,因?yàn)檩斎氲牧鞒套凅w的相關(guān)性降低,合并后的流程模型的規(guī)模會(huì)減小,模型規(guī)模的減小反過來又可以提高模型的可維護(hù)性和可理解性。
文獻(xiàn)[1,2]要求通過流程變體發(fā)現(xiàn)的參考模型能使用一些配置手段(移動(dòng)、刪除、插入)導(dǎo)出其中任意一個(gè)流程變體,即可配置性;文獻(xiàn)[3]要求合并模型應(yīng)考慮所有原始模型的行為,即全面性;文獻(xiàn)[4]要求合并過程模型中的每個(gè)節(jié)點(diǎn)都能很容易地追溯回其原始模型,即可追溯性。合并流程變體的目的是讓組織管理者能夠查看業(yè)務(wù)流程的多個(gè)變體之間的共性和差異,并對其進(jìn)行管理。此外,組織管理者可以對合并模型進(jìn)行更改操作,并將更改操作傳遞給流程變體,而不需要單獨(dú)對每個(gè)變體進(jìn)行更改操作。因而,本文中提出的變體合并算法需要滿足上述3個(gè)要求。
現(xiàn)有的合并流程模型的方法大致可以分為2類:第1類是基于流程行為[1,2,5 - 11];第2類是基于標(biāo)簽相似性[6,10,12]。
第1類方法要求合并模型滿足所有輸入模型的行為,這也就意味著合并模型能夠重放每個(gè)輸入模型的行為。文獻(xiàn)[1,2]介紹了由一個(gè)參考模型通過一些更改操作(刪除、插入、移動(dòng))來配置出流程變體,通過啟發(fā)式搜索方法挖掘流程變體進(jìn)而推導(dǎo)出新的參考模型;文獻(xiàn)[5]提出了一種計(jì)算合并模型的方法,而文獻(xiàn)[6]在文獻(xiàn)[5]的基礎(chǔ)上加入了從合并模型中提取上下文信息的算法,并將此上下文信息提供給分析師,用于找到模型中需要集中優(yōu)化的片段;文獻(xiàn)[7]研究了在合并模型中可能會(huì)遇到的一些問題,同時(shí)也從另外的視角對流程模型的合并進(jìn)行了深層次的研究;文獻(xiàn)[8]提出了一種分解驅(qū)動(dòng)方法,該方法允許從事件日志集合中發(fā)現(xiàn)層次合并流程模型,并且已發(fā)現(xiàn)的層次結(jié)構(gòu)是由嵌套的抽象化流程片段組成,這也就意味著允許在不同的抽象級別上瀏覽可變性;文獻(xiàn)[9]介紹了一種表達(dá)過程行為特征的形式化語言及其語義,并說明了它是如何支持流程合并的;文獻(xiàn)[10]介紹了一種處理流程變體族的建模方法,該方法的關(guān)鍵是在分解步驟即將主流程分解為子流程,以及決定哪些子過程應(yīng)該一起建模和哪些子過程單獨(dú)建模;文獻(xiàn)[11]通過對遺傳過程發(fā)現(xiàn)方法的擴(kuò)展,從事件日志集合中發(fā)現(xiàn)一個(gè)能描述一系列流程變體的可配置流程模型。
第2類方法則是只允許合并基于相同標(biāo)簽的流程模型。文獻(xiàn)[6]介紹了4種合并類型:順序合并、并行合并、條件合并和迭代合并,為了避免無效的合并,通過選擇合并點(diǎn)進(jìn)行合并以此產(chǎn)生一個(gè)合理的合并模型;隨著可配置流程模型中可配置節(jié)點(diǎn)的增長,搜索空間的大小是按指數(shù)增加的。文獻(xiàn)[9]介紹了一種擴(kuò)展的事件過程驅(qū)動(dòng)鏈,這種事件過程驅(qū)動(dòng)鏈可以用來描述單一模型的相似過程集,同時(shí)也減少了管理的流程模型的數(shù)量,且可以區(qū)分集合中發(fā)生合并的每個(gè)特定元素的流程邏輯。文獻(xiàn)[11]提出了3種策略:基于窮舉搜索的方法、基于遺傳的方法和貪心啟發(fā)式的方法,并利用事件日志從可配置流程模型中配置流程變體,該方法很好地表示了一個(gè)特定分支中流程的特征。
現(xiàn)有的流程變體合并方法都是以事件過程驅(qū)動(dòng)鏈為建模語言,合并方法以Petri網(wǎng)為建模語言的卻很少涉及。而Petri網(wǎng)作為常用系統(tǒng)建模語言之一,由于其簡單性、表達(dá)并發(fā)性的能力、清晰的語義和數(shù)學(xué)性質(zhì)而受到廣泛推崇,并隨之誕生了大量的仿真分析工具,為分析Petri網(wǎng)性質(zhì)提供了極大方便。同時(shí),在已有的合并方法中[1 - 4],合并后的模型不能同時(shí)滿足上述所提出的3個(gè)要求,即可追溯性、可配置性和全面性,并且合并后的模型結(jié)構(gòu)在一定程度上過于冗雜,不利于組織管理者理解,即可理解性較差。
本文主要描述了一種基于Petri網(wǎng)的流程變體合并方法,該方法以流程模型的集合作為輸入,并生成可配置的流程模型。可配置的流程模型是一個(gè)建模工具,它以集成的方式捕獲了一系列流程模型。同時(shí),生成的流程模型滿足以下3個(gè)要求:可追溯性、可配置性和全面性。并且合并后的流程模型在規(guī)模上得到了一定程度的簡化,便于組織管理者更好地理解模型。
2 相關(guān)概念
定義1(流程模型[13]) 滿足下列條件的三元組PM=(P,T;F)是一個(gè)流程模型,其中:
(1)P為庫所集,T為變遷集,將庫所集與變遷集中的元素稱為模型的節(jié)點(diǎn);
(2)P∪T≠?且P∩T=?;
(3)F是PM的流關(guān)系且F∈(P×T)∪ (T×P);
(4)dom(F)∪cod(F)=P∪T。其中,dom(F)={x∈P∪T|?y∈P∪T:(x,y)∈F};cod(F)={x∈P∪T|?y∈P∪T:(y,x)∈F}。
此時(shí),dom(F)也表示在定義域中2個(gè)相鄰的節(jié)點(diǎn)x與y之間為因果關(guān)系;而cod(F)表示在值域中2個(gè)相鄰節(jié)點(diǎn)間用x表示y。
定義2(流程變體[1,2]) 假設(shè)NG是一組流程模型,I表示一組流程更改操作(即刪除、插入、移動(dòng)),S0,…,Sn,S′∈NG是一系列的流程模型。設(shè)σ是流程更改操作中的任意一個(gè)更改操作,θ?I是一個(gè)對初始的流程模型進(jìn)行更改的操作序列,將滿足以下條件的流程模型稱為流程變體:
(1)S0[σ>Sn表示σ作用于S0,且Sn是S0應(yīng)用σ所得到的流程模型;
(2)S[θ>S′表示存在S0,S1,…,Sn∈NG,并且S=S0,S′=Sn,Si[σi>Si+1,i={1,2,…,n-1},對于這樣的S′,稱為S的流程變體。
定義3(前集與后集、傳遞前集與傳遞后集[14])假設(shè)G為一個(gè)流程圖,G中的節(jié)點(diǎn)a是一個(gè)二元組(λG(a),τG(a)),其中λG(a)為節(jié)點(diǎn)a的標(biāo)簽,τG(a)為節(jié)點(diǎn)a的類型。在沒有歧義的情況下,可以將下標(biāo)G從(λG(a),τG(a))中刪除。
NG∈G為流程圖中的節(jié)點(diǎn)集合,EG為流程圖的有向邊集合。對于一個(gè)節(jié)點(diǎn)a∈NG,將前集定義為·a={m|(m,a)∈G};類似地,將后集定義為:a·={m|(a,m)∈G}。
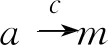

定義4(上下文相似性) 假設(shè)G1和G2是2個(gè)流程圖,并且M:NG1→/NG2是一個(gè)單射。在這一映射規(guī)則下,將G1中的節(jié)點(diǎn)映射到G2中。2個(gè)映射節(jié)點(diǎn)a∈NG1和m∈NG2的上下文相似性定義如式(1)所示:
Sim(a,m)=
(1)
定義5(匹配分?jǐn)?shù)) 設(shè)Si和Sj是2個(gè)流程變體,M是它們的映射函數(shù),設(shè)0≤ω1≤1,0≤ω2≤1,0≤ω3≤1是分配給公共節(jié)點(diǎn)、插入或刪除節(jié)點(diǎn)以及插入或刪除邊的權(quán)重值。c1代表公共節(jié)點(diǎn)的集合,c2代表插入或刪除節(jié)點(diǎn)的集合,c3代表公共有向邊的集合,c4代表插入或刪除有向邊的集合,對于cl(l=1,2,3,4)的定義如式(2)~式(5)所示:
c1=dom(M)∪cod(M)
(2)
c2=(NGi+NGj)c1,i≠j
且i=1,2,3;j=1,2,3
(3)
c3={(c,d)∈EGi|(M(c),M(d))∈EGj}∪
{(c′,d′)∈EGj|(M(c′),M(d′))∈EGi}
(4)
c4=(EGi+EGj)c3
(5)
f1表示流程變體中任意公共節(jié)點(diǎn)的距離,f2表示流程變體中插入或刪除節(jié)點(diǎn)的分?jǐn)?shù),f4表示流程變體中插入或刪除有向邊的分?jǐn)?shù),fi(i=1,2,4)定義如式(6)~式(8)所示:
(6)
(7)
(8)
則流程變體Si與Sj間的匹配分?jǐn)?shù)定義如式(9)所示:
(9)
3 流程變體間的匹配分?jǐn)?shù)
流程變體之間至少有一個(gè)共同的特征、也至少有一個(gè)特征相互區(qū)分。模型之間的相似性度量,大多采取因果關(guān)系去衡量,即模型之間的行為輪廓。本文方法是基于流程變體之間的映射關(guān)系,對變體間的共同特征與差異進(jìn)行衡量。為了更好地了解流程變體間的相似程度,本文通過匹配分?jǐn)?shù)來對流程變體進(jìn)行衡量,進(jìn)而得出流程變體間的相似程度。
算法1流程變體間匹配分?jǐn)?shù)
輸入:流程變體Si,Sj。
輸出:匹配分?jǐn)?shù)fS。
步驟1i←1;
步驟2 FORitonDO
步驟3j←i+1;
步驟4publicregions←Map(Si,Sj);
步驟5c1←CountpublicNode(Si,Sj);/*計(jì)算變體間公共節(jié)點(diǎn)數(shù)量*/
步驟6VSi←CountNode(Si);
步驟7VSj←CountNode(Sj);
步驟8c2←ComputerInsertedOrDeletedNode(c1,VSi,VSj);/*計(jì)算變體間插入或刪除節(jié)點(diǎn)的數(shù)量*/
步驟9c3←CountpublicEage(Si,Sj);/*計(jì)算變體間公共有向邊的數(shù)量*/
步驟10ESi←CountEage(Si);
步驟11ESj←CountEage(Sj);
步驟12c4←ComputerInsertedOrDeletedEage(ESi,ESj,c3);/*計(jì)算變體間插入或刪除有向邊的數(shù)量*/
步驟13Simi,j←Correlationsimilarity(Si,Sj);/*計(jì)算變體間的相似性*/
步驟14f1←Computerdistance(c1,Simi,j);/*計(jì)算任意公共節(jié)點(diǎn)距離*/
步驟15f2←ComputerScoreOfInsertedOrDeleted-Node(c1,VSi,VSj);/*計(jì)算插入或刪除節(jié)點(diǎn)的分?jǐn)?shù)*/
步驟16f4←ComputerScoreOfInsertedOrDeleted-Eage(c4,ESi,ESj);/*計(jì)算插入或刪除有向邊的分?jǐn)?shù)*/
步驟17fSi,jComputerMatchScore(ω1,2,3,f1,2,4);/*計(jì)算匹配分?jǐn)?shù)*/
步驟18 ENDFOR
步驟19 RETURNfS
分析流程變體間匹配分?jǐn)?shù)算法,步驟1~步驟3為算法的循環(huán)條件,通過這一循環(huán)得到流程變體間的不同組合。步驟4將變體Si映射到變體Sj上。步驟5~步驟16為計(jì)算流程變體間匹配分?jǐn)?shù)的準(zhǔn)備工作,其中步驟5為計(jì)算變體Si和變體Sj中共有部分的節(jié)點(diǎn)數(shù)量之和,步驟9與步驟5執(zhí)行一樣的操作,得出公共的有向邊;步驟6~步驟8計(jì)算變體Si和變體Sj插入或刪除節(jié)點(diǎn)的數(shù)量,步驟10~步驟12類似;步驟13計(jì)算節(jié)點(diǎn)間的上下文相似性,步驟14~步驟16分別計(jì)算公共節(jié)點(diǎn)的平均距離、變體Si和變體Sj插入或刪除節(jié)點(diǎn)的分?jǐn)?shù)、變體Si和變體Sj插入或刪除有向邊的分?jǐn)?shù)。步驟17計(jì)算變體間的匹配分?jǐn)?shù)。步驟18結(jié)束循環(huán)。步驟19返回匹配分?jǐn)?shù)的值。
算法1中的步驟5利用了式(2),步驟8利用了式(3),步驟9利用了式(4),步驟12利用了式(5),步驟13利用了式(1),步驟14利用了式(6),步驟15利用了式(7),步驟16利用了式(8),步驟17利用了式(9)。
如前文所述,匹配分?jǐn)?shù)是用來衡量流程變體間的相似程度。下面通過圖書館借還書籍的業(yè)務(wù)流程圖來對匹配分?jǐn)?shù)進(jìn)行說明,同時(shí),這一業(yè)務(wù)流程圖將作為貫穿全文的案例來使用。圖1 所示即為圖書館借還書籍的業(yè)務(wù)流程圖。
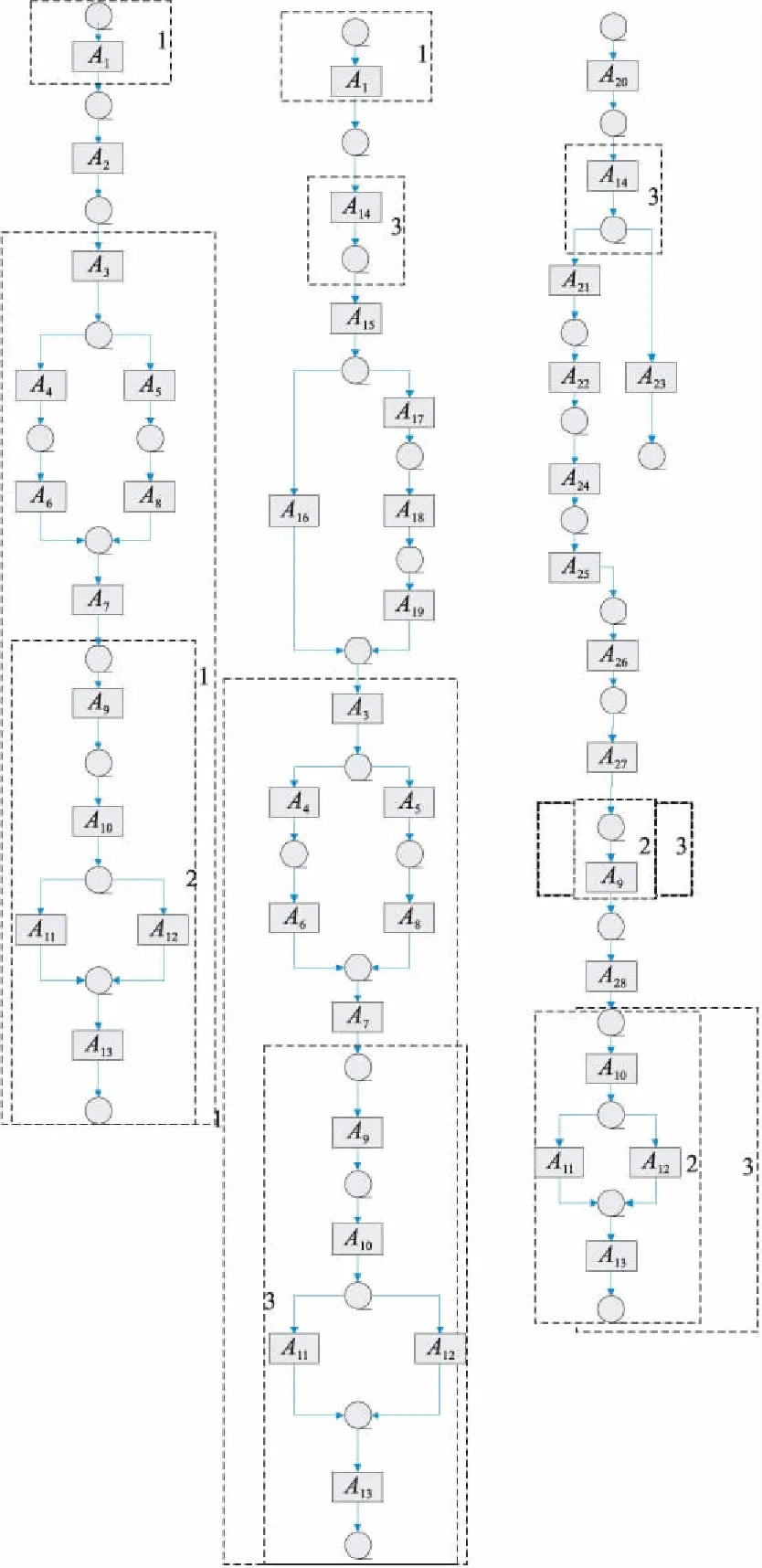
Figure 1 Variants diagram of loaning and returning books process in library
現(xiàn)對圖1中圖書館借還書籍流程變體圖中的變遷做如下說明:A1(讀者刷卡入館)、A2(無目的性的借書)、A3(到借閱區(qū)瀏覽,挑選所需圖書)、A4(自助機(jī)借書)、A5(服務(wù)臺借書)、A6(刷借書證,核對相關(guān)信息)、A7(所在樓層服務(wù)臺辦理借書手續(xù))、A8(借書成功,刷卡出館)、A9(閱讀完畢)、A10(還書前核實(shí))、A11(信息正常)、A12(超期罰款)、A13(還書成功)、A14(指定書籍借閱)、A15(檢索館藏)、A16(書籍在架)、A17(書籍不在架)、A18(預(yù)約指定書籍)、A19(預(yù)約書籍到館)、A20(登錄網(wǎng)上圖書館網(wǎng)址)、A21(網(wǎng)上辦理委托申請)、A22(委托申請辦理中)、A23(取消委托申請)、A24(委托申請成功)、A25(核實(shí)地址)、A26(書籍運(yùn)送)、A27(借書成功)、A28(將書寄回)。
匹配分?jǐn)?shù)的數(shù)值越高,則說明2個(gè)流程變體間的相似程度越高,即流程變體間共有的共同特征越多。匹配分?jǐn)?shù)0≤fS≤1。若通過算法計(jì)算出的匹配分?jǐn)?shù)小于一定的閾值,則對流程變體不進(jìn)行4.1節(jié)的算法2中流程變體的合并操作。此時(shí),從圖書館借還書籍的業(yè)務(wù)流程圖中選擇2個(gè)流程變體S2和S3來運(yùn)行算法1,得到這2個(gè)流程變體S2和S3的匹配分?jǐn)?shù)fS=0.57。因?yàn)榱鞒套凅wS2和S3的匹配分?jǐn)?shù)為0.57,說明這2個(gè)流程變體間的相似程度較高,即所共有的共同特征較多,而從圖1中也不難看出2個(gè)流程變體所共有的共同特征有2個(gè)部分(即圖1中標(biāo)號為3的框所圈出的部分)。基于算法1計(jì)算這2個(gè)流程變體的具體過程在第5節(jié)中給出。
4 流程變體的合并方法
流程變體的合并是在一對可配置的流程圖上(如圖1所示)進(jìn)行的,但是有時(shí)也會(huì)出現(xiàn)合并2個(gè)不可配置的流程圖的情況。為此,文獻(xiàn)[15,16]中提出了一種使用擴(kuò)展的Condec語言對不可配置的流程模型進(jìn)行約束規(guī)范,進(jìn)而將不可配置的流程模型轉(zhuǎn)變成可配置的流程模型的方法,之后再進(jìn)行流程變體的合并。
4.1 算法設(shè)計(jì)
算法2流程變體的合并算法
輸入:流程變體S1、S2。
輸出:合并模型MP。
步驟1map(S1,S2)→publicregions∪differentregions;/*將S1,S2映射,劃分公共區(qū)域與差異區(qū)域*/
步驟2P=NULL;//節(jié)點(diǎn)的最大公共區(qū)域?yàn)榭罩?/p>
步驟3s=1;
步驟4 WHILEsDO
步驟5IF所有節(jié)點(diǎn)都包含在P中THEN
步驟6s=0;
步驟7ELSETHEN
步驟8Randomchoose(Vm≠Pl);/*隨機(jī)挑選一個(gè)節(jié)點(diǎn)*/
步驟9Pl=Searchmaxpublicregion(Vm);/*尋找節(jié)點(diǎn)Vm的最大公共區(qū)域*/
步驟10P.add(Pl);/*將尋找到的最大公共區(qū)域添加到P*/
步驟11s=1;
步驟12ENDIF
步驟13 ENDWHILE
步驟14Addactivity(ST,ET);/*在變體S1和S2中插入開始活動(dòng)ST與結(jié)束活動(dòng)ET*/
步驟15Fi=maxpublicregions∪differentregions;//將最大公共區(qū)域與差異區(qū)域拆分為片段
步驟16i=1;
步驟17 WHILEiDO
步驟18matchscorei=computer(Fi);
步驟19IFmatchscorei=1THEN
步驟20Abstractpublicregions(Fi);
步驟21ELSETHEN
步驟22Notabstractpublicregion(Fi);
步驟23ENDIF
步驟24 ENDWHILE

步驟27 ENDFOR
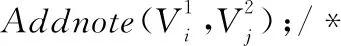
步驟30 ENDFOR
步驟31originalversionMP′←unionpublicregions;


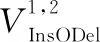
步驟35MP()←MergeRedunancyPlaces(MP″);
步驟36 RETURNMP
分析流程合并算法,步驟1在變體S1與變體S2建立映射關(guān)系,找到變體S1與變體S2相同與差異的一些片段,步驟2~步驟14將變體S1和S2之間的映射劃分為一個(gè)僅由匹配節(jié)點(diǎn)和公共的有向邊構(gòu)成的最大公共區(qū)域,其中,s=0,1為判斷是否找到最大公共區(qū)域的條件。步驟15分別對變體S1、S2添加一個(gè)開始活動(dòng)(ST)與結(jié)束活動(dòng)(ET)。步驟16~步驟25對最大公共區(qū)域進(jìn)行抽象化處理,其中步驟19計(jì)算這些片段的匹配分?jǐn)?shù),步驟20~步驟24為判斷片段可抽象化的條件。步驟25~步驟27對變體S1和S2中的每個(gè)有向邊都添加一個(gè)注釋。步驟28~步驟30與步驟25~步驟27進(jìn)行的操作類似,只不過是對節(jié)點(diǎn)進(jìn)行操作。步驟31對變體S1和S2中最大公共區(qū)域執(zhí)行并集操作,得到原始版本的合并模型MP′。步驟32將變體S1和S2中替換邊的注釋結(jié)合起來。步驟33對節(jié)點(diǎn)也進(jìn)行類似的操作。步驟34將原始版本的合并模型MP′與變體S1和S2的插入或刪除的節(jié)點(diǎn)進(jìn)行連接,得到合并模型MP″。其連接方式是根據(jù)源和匯在變體S1和S2中的位置。步驟35將合并模型MP″中冗余的庫所合并為一個(gè)庫所,以此得到最終的合并模型MP。
定理1(可配置性) 合并模型使用一些配置操作(移動(dòng)、刪除、插入)導(dǎo)出其中任意一個(gè)流程變體。
證明流程變體是由參考模型經(jīng)過一系列的配置操作得到的。本文提出的合并算法旨在將流程變體合并為在一個(gè)特定業(yè)務(wù)背景下的單一參考模型。因此,這個(gè)單一的參考模型也可以通過配置操作得到任意一個(gè)流程變體。
□
定理2(可追溯性) 合并過程模型中的每個(gè)節(jié)點(diǎn)都能追溯回其原始模型。
證明合并算法中,對輸入的每個(gè)流程變體的節(jié)點(diǎn)與有向邊進(jìn)行了注釋(如在節(jié)點(diǎn)與有向邊中添加了數(shù)字注釋),確保了在合并后的模型中能更好地追溯來源。
□
定理3(兼容性) 合并模型考慮所有原始模型的行為。
證明因?yàn)楹喜⒛P褪怯闪鞒套凅w經(jīng)由合并算法得來的。利用反證法,假設(shè)合并模型沒有考慮所有原始模型的行為,根據(jù)定理1,合并模型具有可配置性,即合并模型通過移動(dòng)、刪除、插入等配置操作可以得到任意流程變體。如若假設(shè)成立,則導(dǎo)出的流程變體與合并算法之前的流程變體是不一致的。因此,假設(shè)是不成立的,即合并模型考慮所有原始模型的行為。
□
4.2 基于Petri網(wǎng)的流程變體合并方法的性質(zhì)分析
由于Petri網(wǎng)系統(tǒng)具有安全性、活性等性質(zhì),本文提出的流程變體合并方法建立在Petri網(wǎng)系統(tǒng)之上。下面對本文提出的基于Petri網(wǎng)的流程變體合并方法的相關(guān)性質(zhì)進(jìn)行分析。

綜上,定理4的(1)得證。(2)和(1)的證明相似,在此不做贅述。
□
5 案例研究
流程變體不同組合間的匹配分?jǐn)?shù)主要分為以下2種情況:組合間匹配分?jǐn)?shù)相同和匹配分?jǐn)?shù)不相同。而本文考慮的是后一種情況,當(dāng)變體數(shù)量龐大時(shí),變體數(shù)量為3個(gè)是一個(gè)臨界值,如若變體數(shù)量為4個(gè)甚至更多,也是通過相同的方法來計(jì)算匹配分?jǐn)?shù),從而挑選出最適配的2個(gè)流程變體。因此在本文的研究中選擇3個(gè)變體來計(jì)算不同變體組合的匹配分?jǐn)?shù)。接下來通過對圖書館借還書籍的流程來進(jìn)一步闡述所提出的方法。以標(biāo)準(zhǔn)借還書籍的流程模型為基礎(chǔ),通過一系列更改操作(如刪除、插入、置換)來配置流程變體,以此得到3個(gè)流程變體,分別為S1(圖1左)、S2(圖1中)和S3(圖1 右)。流程變體S1和S2是線下圖書館借閱書籍的業(yè)務(wù)流程圖,而流程變體S3是線上圖書館借閱書籍的流程圖。對于3個(gè)變體來說,其共有的部分為書籍閱讀完畢至還書成功的這一過程;其不同之處就在于,線下圖書館是讀者親自去圖書館挑選所需書籍,而線上圖書館通過客戶端挑選書籍,之后通過郵寄的方式來達(dá)到借書的目的。但是,對變體S1和S2來說,這2個(gè)流程變體的共同特征還包括刷卡入館和借書這2個(gè)片段;那么,2個(gè)流程變體S1和S2中挑選借閱書籍的方式是不同的,流程變體S1是毫無目的性地挑選借閱書籍,流程變體S2是挑選特定的借閱書籍,這種特定的借閱書籍還可能不在架。對于流程變體的具體描述如圖1所示。
之后本文以圖書館借還書籍業(yè)務(wù)流程Si(i=1,2,3)作為算法1和算法2的輸入,驗(yàn)證本文所提出的流程變體間匹配分?jǐn)?shù)算法和流程變體合并算法。
執(zhí)行算法1中步驟4找到2個(gè)變體中的共有部分,用帶標(biāo)號虛線框標(biāo)識出來,對于不同變體間的共有部分用了不同標(biāo)號的虛線框標(biāo)識,如圖2所示;執(zhí)行算法1中步驟5,統(tǒng)計(jì)3個(gè)流程變體兩兩之間公共節(jié)點(diǎn)的數(shù)量,即圖1中虛線框住的部分就是3個(gè)流程變體的公共部分,記為c1;執(zhí)行算法1步驟6~步驟8,計(jì)算2個(gè)流程變體的總節(jié)點(diǎn)數(shù),再與公共節(jié)點(diǎn)數(shù)相比較得出變體中插入或刪除節(jié)點(diǎn)的數(shù)量,記為c2。

Figure 2 Abstract fragments F1 and F2
算法1 中的步驟9計(jì)算2個(gè)變體中公共部分的有向邊的數(shù)量,記為c3;步驟10~步驟12計(jì)算變體中插入或刪除有向邊的數(shù)量,記為c4。
算法1 中步驟13計(jì)算節(jié)點(diǎn)間的上下文相似性,此時(shí)在流程變體間分別選取一個(gè)特殊的節(jié)點(diǎn),由定義5中的式(1)計(jì)算得出Sim(a,m)。
算法1中的步驟14計(jì)算公共節(jié)點(diǎn)的平均距離、步驟15計(jì)算變體Si和變體Sj插入或刪除節(jié)點(diǎn)的分?jǐn)?shù)、步驟16計(jì)算變體Si和變體Sj插入或刪除有向邊的分?jǐn)?shù),對應(yīng)地分別記為f1,f2,f4。
對于流程變體S1和S2、S1和S3以及S2和S3來說,各流程變體之間相關(guān)的數(shù)值詳見表1。
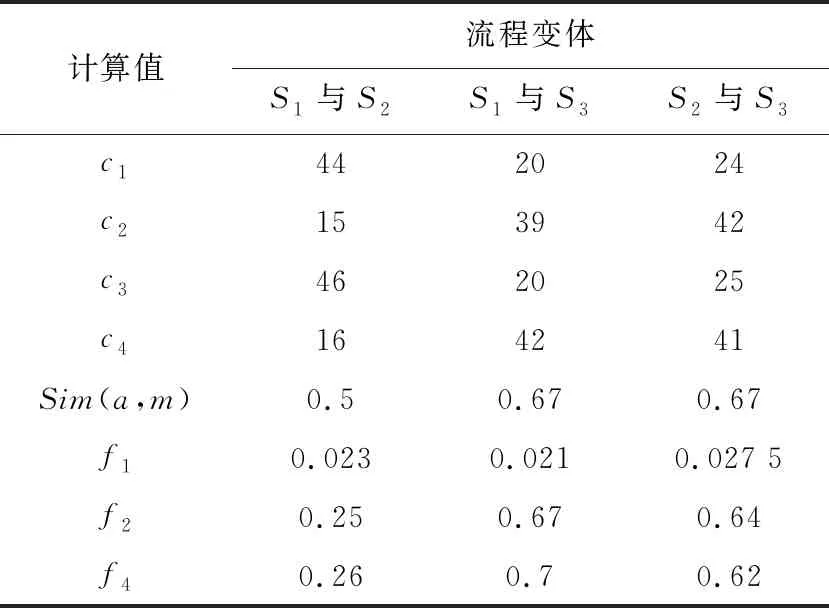
Table 1 Values associated with the matching score between each process variant
執(zhí)行算法1中步驟17,計(jì)算變體間的匹配分?jǐn)?shù),此時(shí)將式(9)中的權(quán)重ωi設(shè)置為1,則流程變體Si(i=1,2,3)和之間的匹配分?jǐn)?shù)可由式(9)計(jì)算得出,記為fSi,j。
表2中所示為2個(gè)流程變體之間的匹配分?jǐn)?shù)。不難看出流程變體S1和S2的匹配分?jǐn)?shù)相對于其他2對的匹配分?jǐn)?shù)要稍微高一點(diǎn),說明了S1和S2的相似程度略高于其他2對變體。因此,在接下來流程變體的合并算法中,選擇匹配分?jǐn)?shù)稍微高于其他2對的流程變體S1和S2。

Table 2 Matching score fSi,j between process variants
執(zhí)行算法2中步驟1,對變體S1和S2建立一個(gè)映射關(guān)系,從而找到流程變體S1和S2中相同與存在差異的一些片段。之后執(zhí)行算法2中的步驟2~步驟14,將變體S1和S2之間的映射劃分為一個(gè)僅由匹配節(jié)點(diǎn)和公共的有向邊組成的最大公共區(qū)域。為了找到所有的最大公共區(qū)域,隨機(jī)找一個(gè)沒有包含在任何最大公共區(qū)域的匹配節(jié)點(diǎn),并使用廣度優(yōu)先來搜索該節(jié)點(diǎn)的最大公共區(qū)域,之后使用相同的方法選擇另外的匹配節(jié)點(diǎn)進(jìn)行類似的操作,并以此創(chuàng)建另外一個(gè)最大公共區(qū)域。
算法2 中步驟15分別對變體S1、S2添加一個(gè)開始活動(dòng)(ST)與結(jié)束活動(dòng)(ET)。步驟16~步驟24用Fi標(biāo)記找到的最大公共區(qū)域與差異區(qū)域,之后計(jì)算上述2類區(qū)域的匹配分?jǐn)?shù),將匹配分?jǐn)?shù)計(jì)算結(jié)果為1的區(qū)域內(nèi)部行為抽象化,得到了2個(gè)抽象化的片段,如圖2所示。并將抽象化片段嵌入到流程變體S1和S2中,簡化了變體S1與S2的結(jié)構(gòu)。執(zhí)行步驟25~步驟30,對有向邊和節(jié)點(diǎn)添加注釋。執(zhí)行完算法2中前30個(gè)步驟后得到的流程圖如圖3所示。
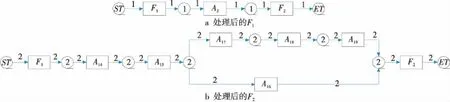
Figure 3 Process variants after processing
執(zhí)行算法2中步驟31~步驟34,得到一個(gè)合并模型MP″,如圖4所示。合并后的模型應(yīng)當(dāng)滿足這樣的要求:流程圖中的變遷最多有一個(gè)輸入庫所或輸出庫所,顯然圖4中的2處變遷不符合提出的要求,因此對合并模型MP″執(zhí)行算法2中的步驟35,將冗余的庫所合并為一個(gè),得到如圖5所示的流程合并模型MP。
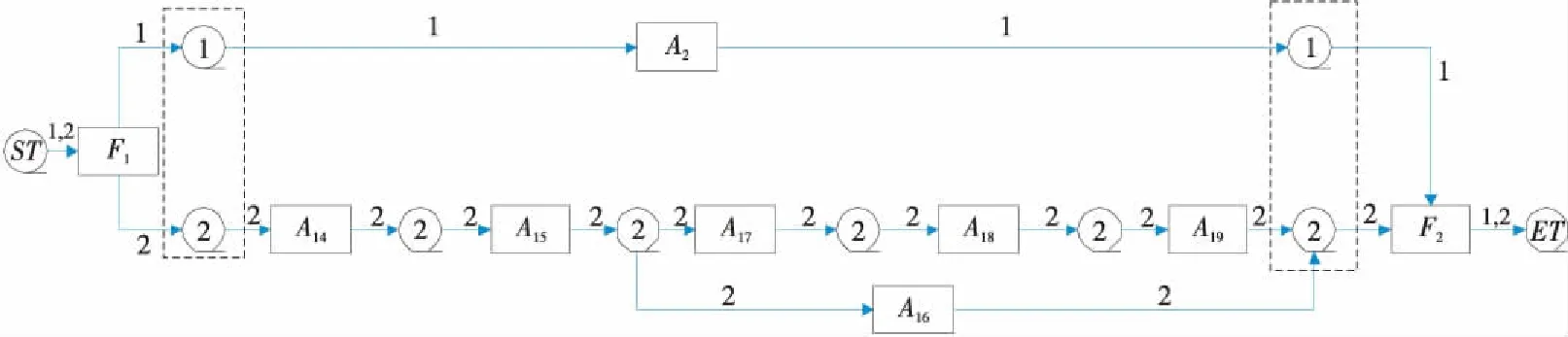
Figure 4 Process variants merging model MP″

Figure 5 Process variants merging model MP
流程變體合并模型MP經(jīng)簡化之后,可以使用合并比(fc=|MP|/(|G1|+|G2|))來衡量流程變體的合并情況,即通過節(jié)點(diǎn)的增減情況來衡量流程變體的合并情況。從圖2與圖5中可以分別得出流程變體G1和G2的節(jié)點(diǎn)數(shù)|G1|+|G2|為59,流程變體合并圖MP節(jié)點(diǎn)數(shù)|MP|為17,則合并比為0.29。合并比也從側(cè)面反映了一個(gè)事實(shí),即合并比越低,說明2個(gè)流程變體合并后所產(chǎn)生的合并圖的效果越好。
6 結(jié)束語
本文以匹配分?jǐn)?shù)作為流程變體相似性的判斷基準(zhǔn),從備選流程變體中選出一對流程變體作為輸入,輸出是由這2個(gè)流程變體合并得到的流程模型。輸出的流程模型具有全面性、可追溯性、可配置性,即保證合并后的模型包含了其輸入的原流程變體,且可以通過對合并后的模型進(jìn)行一些配置推導(dǎo)出原流程變體。此外,本文提出的流程變體合并方法在滿足上述3個(gè)性質(zhì)的基礎(chǔ)上,還對變體間的最大公共區(qū)域進(jìn)行了抽象化處理,使得流程變體的規(guī)模在一定程度上得到了縮減。因此,提升了合并模型的可理解性。但是,若作為輸入的多個(gè)流程變體具有相同的匹配分?jǐn)?shù),需要對多個(gè)流程變體進(jìn)行合并,最終得到合并模型。而合并的步驟是先將2個(gè)流程變體合并,再將得到的模型與第3個(gè)流程變體合并,直到所有的流程變體合并完畢。在未來的工作中希望能夠一次性完成多個(gè)流程變體的合并,而不需要先將2個(gè)流程變體合并 ,再與剩下的流程變體合并,從而大大節(jié)省多個(gè)流程變體合并所需要的時(shí)間,同時(shí),在多個(gè)流程變體的合并過程中也能降低出錯(cuò)率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
