基于時態邊緣算子的時間序列自主分段表示法*
2021-06-25 10:06:02殷煒宏王若愚段倩倩李國強
計算機工程與科學 2021年6期
關鍵詞:方法
殷煒宏,王若愚,段倩倩,李國強
(1.上海工程技術大學電子電氣工程學院,上海 201620 ;2.上海交通大學軟件學院,上海 200240)
1 引言
近年來,數據量日益增長,數據中隱藏著許多有價值的信息,需要通過數據挖掘[1]來探究數據中隱含的有用信息。那么,在數據挖掘領域中,時間序列則是數據挖掘的一個熱門研究領域[2]。時間序列作為一種特殊的大數據,普遍存在于金融、醫療、農業、氣象、科學觀測和工程等各個領域。若將原始數據直接用于時間序列的數據挖掘任務[3]中,則會導致過多的噪聲被引入,使得實驗結果往往較差,影響最終的度量精度。
因此,許多研究者提出了時間序列的表示方法,為后續的相似性搜索[4,5]工作做了很好的鋪墊。現階段,時間序列表示方法主要有4種[6]:頻域表示法(離散傅里葉變換DFT(Discrete Fourier Transform)[7]和離散小波變換DWT (Discrete Wavelet Transform)[8])、奇異值分解SVD(Singular Value Decomposition)表示法[9]、符號近似聚合SAX(Symbolic Aggregate Approximation)表示法[10]和分段線性表示法PLR(Piecewise Linear Representation)[11]。
很多應用領域更關注時間序列在某個時間段的變化模式和規律,而不是單點特征。例如在醫療領域中,心電時間序列[12]在同一周期內會有不同的波段特征,如P波、PR間期、QRS波群、ST段等,這些波段間期有著各自的序列趨勢特征,若從單點特征看是很難看出其屬于哪個波段,而通過時序的表示方法能很清楚地看出每個波段的趨勢特征,能更準確判斷出該波形屬于哪類波段,進一步確診病人的心臟疾病。
在上述時序表示方法中,時間序列的分段線性表示方法簡單直觀且數據壓縮效率高。該方法能夠找到原序列上的某些特征點,并利用點與點之間一系列連續、首尾連接的直線段來近似表示時間序列,是一種數據降維和降噪的常見時序表示方法。因此,該方法得到了眾多研究者的重視。
然而,尋找一種合適的分段線性表示方法并非易事。近年來,研究人員已經提出了一系列分段算法。目前,分段線性表示方法主要有2種,一種是由Keogh等[13]提出的采用擬合誤差的方法進行分段表示,其主要思想是使得原始序列與擬合序列之間的殘差平方和最小。而孫志偉等[14]提出的分段算法也是首先考慮擬合誤差,并針對優先級較高的分段進行預分段,同時在分段時考慮最大、最小值點,從而提高了固定點分段效率。盡管這種自底向上的算法分段效果好,但時間復雜度較高,且不支持在線分段。另一種表示方法則是考慮全局約束值和尋找重要點。如文獻[15]提出的基于重要趨勢點的分段線性算法,即若一個待測點的特征值在局部區間內與區間端點特征值的比值超過某個閾值,則認定該點為重要點;廖俊等[16]根據序列的特征首先找出重要趨勢轉折點,即趨勢變化明顯的點,進而通過某種規則刪除相對不重要的點;陳帥飛等[17]提出了一種根據序列中極值點和變化幅度比較大的點來得到關鍵點的分段線性算法;而肖輝等[18]提出的基于時態邊緣算子的時間序列分段線性表示法,則是根據時間序列的特征設計出一種時態邊緣算子,并最終得到時間序列的邊緣點。這種自頂向下的算法盡管在一定程度上提高了分段精度,但用戶參數不易確定,且對整體考慮不足。
針對上述問題,本文提出一種以時態邊緣算子TEO(Temporal Edge Operator)為基礎的自主分段線性表示方法APLR_TEO(Autonomous Piecewise Linear Representation based on Temporal Edge Operator),該方法不僅精度高,在參數的設定上較為簡單,有良好的適應性和穩定性,且時間復雜度不高,時間序列測試數據集經過表示后的可視化效果也不錯,能準確刻畫出時間序列的主要趨勢特征。首先根據邊緣極值點的度量方法得到邊緣極值點序列,再通過一種自主分段線性啟發式規則得到最終的關鍵點序列。該方法對分段點數的劃分更精確,從而使得壓縮率的調節更為靈活。同時,也能更精準地反映時間序列曲線的總體特征,大幅度提高了分段效率,擬合效果也更好。
2 相關定義
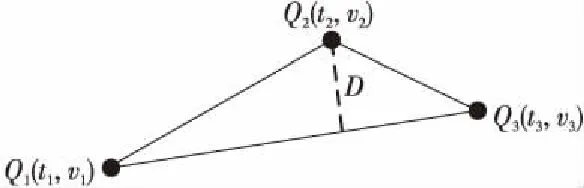
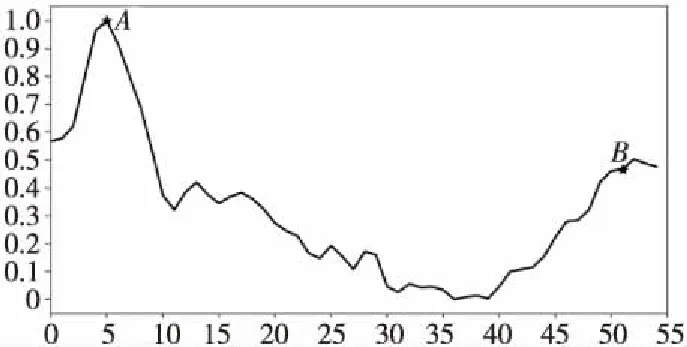
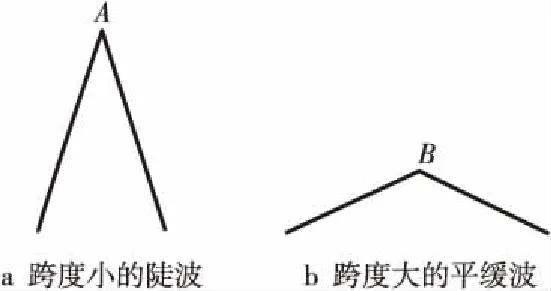
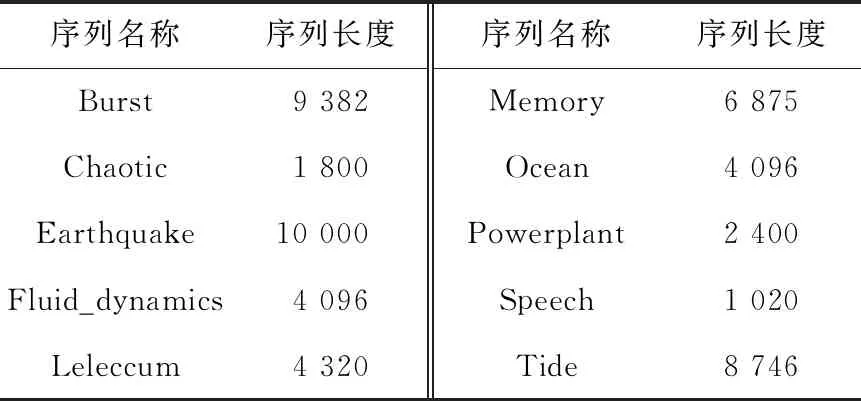
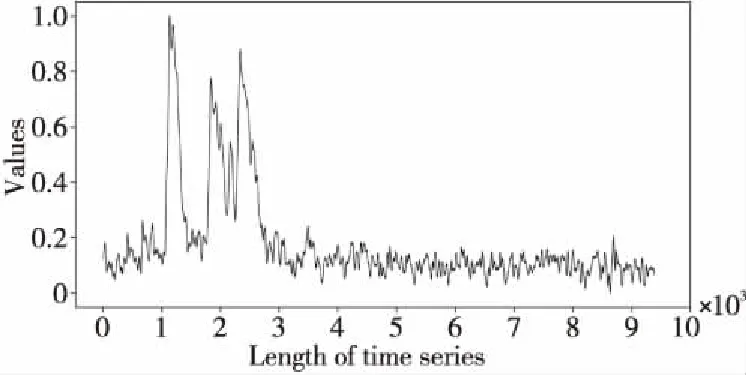
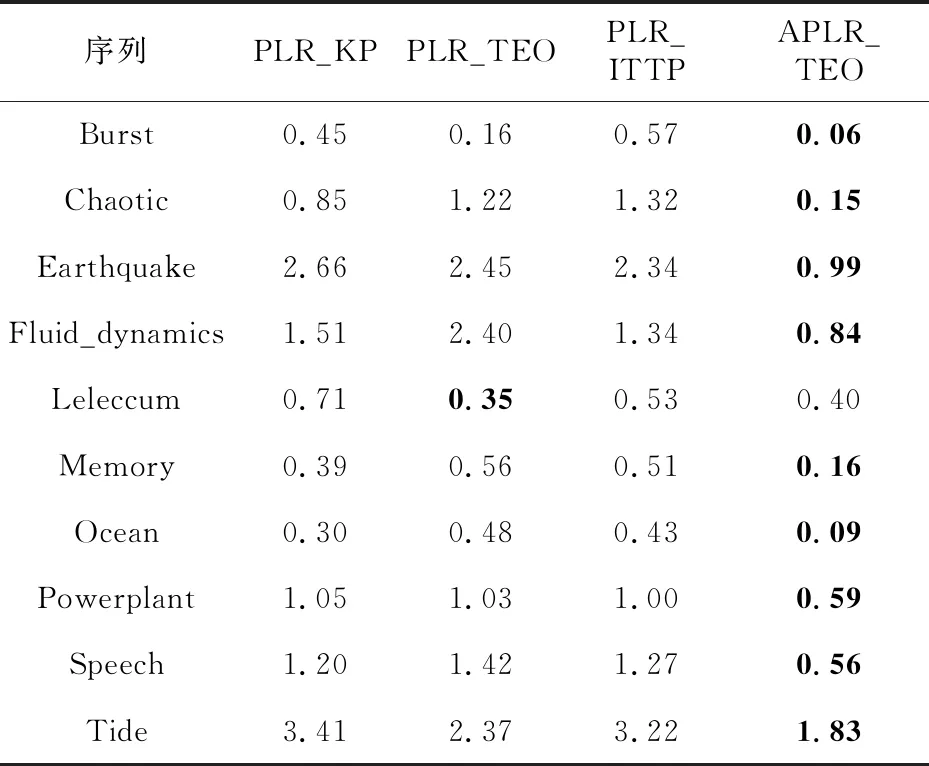
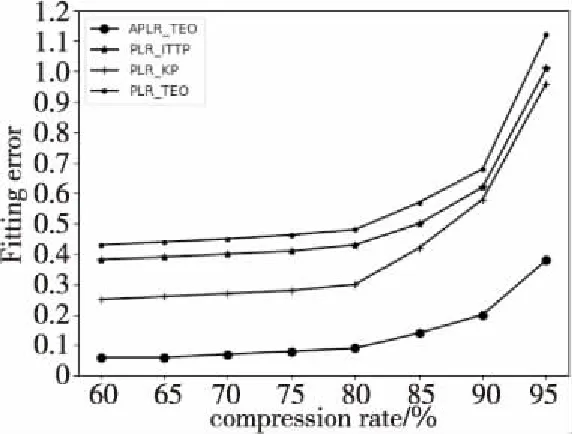
定義1(時間序列) 時間序列是一組由連續時間變量和對應的特征值組成的有序集合。從時間序列的角度來看,每個數據單元可以被抽象成一個二元組(t,v),t為時間變量,v為特征值變量。定義時間序列X={x1=(t1,v1),x2=(t2,v2),…,xn=(tn,vn)},滿足ti X={x1,x2,…,xn} (1) 定義2(時間序列的分段線性表示) 設時間序列X={x1,x2,…,xn},分段點的集合記為X′={x′1,x′2,…,x′m},其中x′2=x1,x′m=xn,且m XL={f1(x′1,x′2),f2(x′2,x′3),…,fm-1(x′m-1,x′m)} (2) 其中,fm-1(x′m-1,x′m)表示在[x′m-1,x′m]上用于擬合時間序列的線性函數。 定義3(壓縮率) 設原始時間序列X={x1,x2,…,xn},分段點的集合為X′={x′1,x′2,…,x′m},那么該時間序列的壓縮率記為: (3) (4) 擬合誤差是檢驗擬合時間序列和原始時間序列差異度的一個重要指標。在相同壓縮率下,一個序列的擬合誤差越大,那么擬合效果越差;反之,則擬合效果越好。這也是間接判斷分段線性方法好壞的一個標準。 定義5(一維卷積) 與數字信號不同,本文采用的卷積計算是基于數字圖像處理領域。眾所周知,近幾年圖像處理成了熱門的研究領域,二維卷積在該領域用處甚廣,其原理是利用卷積核(卷積模板)在圖像上滑動,將圖像點上的像素灰度值與對應的卷積核上的數值相乘,然后將所有相乘后的值相加作為卷積核中間像素對應的圖像上像素的灰度值,并最終滑動完所有圖像卷積的過程,實質為矩陣與矩陣之間的卷積計算。而一維卷積原理與二維卷積相同,常用于序列模型和自然語言處理等領域,對于2個一維序列的卷積計算定義為: T*S=E (5) 其中,T∈Rn×1為時間序列,S∈Rn×1為與時間序列做卷積的邊緣算子,而E∈Rn×1為本文所需的與時間序列等長的輸出序列,*表示卷積運算符。 定義6(趨勢轉折距離) 設時間序列X={x1,x2,…,xn},在進行分段任務前,我們需要計算出當前點與其前后點之間的趨勢偏轉距離[19],如圖1所示。 Figure 1 Trend deflection distance 圖1中的Q1,Q2,Q3為在邊緣極值點序列中的某鄰域內的3個點,這3個點正好構成幾何三角形,圖1中垂直虛線段D的長度d就是趨勢轉折距離,定義為: (6) 其中,Q2(t2,v2)為待檢測點。趨勢轉折距離d越大,這個點越重要。 APLR_TEO是一種自主分段線性表示方法。將時態邊緣算子與原始時間序列進行卷積得到潛在邊緣點序列,再通過過濾規則得到最終的關鍵點序列,并連接這些關鍵點之間的直線段序列來表示出原始時間序列。該方法主要分為2個部分:第1部分是基于時態邊緣算子的邊緣極值點度量方法的設計;第2部分是利用邊緣極值點的自主分段線性方法,并得到關鍵點序列。 邊緣算子[20]常用于檢測圖像的灰度級變化很快的點的集合(即圖像的邊緣),利用邊緣鄰近梯度值變化規律檢測邊緣。本文根據邊緣算子的特征,設計出了符合時間序列特點的時態邊緣算子,采用該算子來檢測時序的邊緣,并根據相應的關聯規則從中提取出若干個邊緣點,最后通過分段方法得到最終的分段序列點。在時間序列中,若一個序列點為邊緣點,那么在其鄰域內,位于該點左右兩端的時間序列將呈現不同的變化趨勢。在圖2所示的時間序列中,序列點A左側呈現上升趨勢,右側呈現下降趨勢;而點B左側呈現平緩趨勢,右側呈現上升趨勢。因此,本文定義A,B為邊緣點。這種左右鄰域都有不同變化趨勢的點,可稱之為時間序列的邊緣點[21,22]。 Figure 2 Edge points of a time series 本文將以時態邊緣算子為基礎,對分段線性算法進行改進,設計出一種基于時態邊緣算子的自主分段線性表示方法APLR_TEO。 給定時間序列X={x1,x2,…,xn},定義時態邊緣算子為: TEO(t,u)={w(i)×(xt+i-xi)|i= -u,…,-2,-1,0,1,2,…,u} (7) 該算子設計的基本思路是根據該點左右鄰域相對該點變化幅度的影響來判斷該點的重要程度,其中w(i)為計算邊緣算子TEO的權重,定義為: w(i)=abs(i) (8) 即越靠近檢測窗口中心的點權重越低,即只考慮該點鄰域對當前點的變化幅度影響,u是檢測窗口長度,由用戶自己設定,實驗表明,當u取1,2,3,4時,實驗效果最好。可以針對數據集特征來選擇合適的窗口進行邊緣算子設計,該算子具有較強的適應性和靈活性。 根據定義5將TEO與時間序列做一維卷積計算: TEO(t,u)*X(t)=E(t) (9) 其中,TEO(t,u)是根據在線卷積計算時間序列點得到的相應的時態邊緣算子,X(t)為當前卷積的序列點,E(t)為輸出的邊緣強度序列。 由于時序關聯性強的特點,相鄰點的邊緣幅度相近,若用這些邊緣點進行線性分段,無法準確刻畫時序的主要特征。下面將給出一種邊緣點的度量方法。 經過TEO卷積計算得到的對應的邊緣強度序列記為E={e1,e2,…,en}。若X={x1,x2,…,xn}滿足以下條件之一: (1)ei>ei-1且ei≥ei+1,或ei≥ei-1且ei>ei+1,其中1 (2)ei 點ei即為相應的邊緣強度極值序列點,由此可找出與之對應的時間序列邊緣極值點xi,并將這些邊緣極值點放入邊緣極值點序列集合Q={q1,q2,…,qm}中,最終,就可以得到邊緣極值點序列Q={q1,q2,…,qm},其中m 設時間序列X={x1,x2,…,xn},其輸出的關鍵點序列為{xi1,xi2,…,xik},其中1≤i1≤i2<… (10) 其中,L(xik-1,xik)表示在區間[ik-1,ik]上連接相鄰關鍵點的線性函數,式(10)也可簡化為L′={L(xi1,xi2),L(xi2,xi3),…,L(xik-1,xik)}。 由于時間序列具有不穩定性和相關聯性的特點,本文提出了APLR _TEO方法,通過提取邊緣極值點并進一步經過自主分段線性表示的關聯規則來選擇合適的關鍵點表示時間序列的整體特征。 自主分段線性方法實現過程:設時間序列為X={x1,x2,…,xn},通過3.2節的度量方法得到邊緣極值點序列為Q={q1,q2,…,qm}。再從邊緣極值點序列中篩選出關鍵點序列Kpts,默認將首尾點q1和qm加入到關鍵點序列,在計算趨勢轉折距離的過程中,默認將最后一個點qm作為圖1的Q3,將第1個關鍵點q1初始化為圖1的Q1。初始化累積分段轉折距離sum_d=0和分段內的最大轉折距離max_d=0,并根據壓縮率設定累積分段閾值ε。遍歷邊緣極值點序列,得到序列中每個點的趨勢轉折距離dk,同時計算累積轉折距離sum_d=d1+d2+…+dk,其中dk是從q2開始計算的趨勢轉折距離,k≤m-2。判斷dk是否大于最大轉折距離max_d,若max_d 基于邊緣極值點度量的自主分段線性方法偽代碼如下所示: 輸入:時間序列X={x1,x2,…,xn},參數u,ε。 輸出:關鍵點序列Kpts。 步驟1初始化時間序列X; 步驟2構造邊緣極值點序列Q,默認將X中的首尾點加入到Q中: fori=1 ton 計算序列X與TEO卷積后的邊緣強度序列Eepts: Eepts←X(i)*TEO(i,u);E_index←i; endfor forj=1 tom 根據邊緣極值點的關聯規則找出與E對應的邊緣極值點序列: Q←X(E_index[j]); endfor returnQ 步驟3構造關鍵點序列Kpts: fori=1 tom 計算Q中每個點的分段趨勢轉折距離di; sum_d+=di; max_d←di; max_index←i;//max_index為索引列表 if(sum_d>ε) iIndex←max_d.index(max(max_d)); Kpts← (max_index[iIndex],Eepts[max_index[iIndex]]); endif endfor returnKpts (1)APLR_TEO方法只需設定2個參數,分別是邊緣算子卷積窗口大小u和累積分段閾值ε。其中,參數u將通過第4節實驗說明其容易確定,在針對不同數據集時,靈活性和適應性很強;而參數ε則是根據壓縮率大小上下浮動的,其變化范圍小,也不難確定。本文方法與文獻[17]中所提及的PLR_KP(Piecewise Linear Representation based on Key Points)方法的3個閾值參數C,P,R相比,需要設定的參數更少,參數的大小更容易確定。 (2)APLR_TEO方法綜合考慮了擬合誤差大小與時間跨度問題。PLR_ITTP(Piecewise Linear Representation based on Important Trend Transition Points)方法[16]對于分段的約束條件只是針對前一重要點和后一趨勢轉折點形成的線段距離大則擁有優先分段權這一局部約束,忽略了序列的全局特征,則會造成圖3a 這種時間跨度小而波形陡的情況,即點A的趨勢轉折距離更大。出于降低擬合誤差考慮,這種分段方式往往會造成更大的擬合誤差。相比較而言,圖3b中B點的趨勢轉折距離小,時間跨度大,最終的擬合誤差也較小,更能準確反映波形趨勢特征。利用這一特征,APLR_TEO解決了PLR_ITTP方法未考慮時間跨度這一全局性的問題,在計算趨勢轉折距離的同時,累加分段距離,并根據累積分段閾值來判斷是否結束該局部分段,從而達到精確地整體分段,降低整個序列擬合誤差的目的。 Figure 3 Time span of trend turning points (3)APLR_TEO方法對時間序列進行了2次掃描選取關鍵點,其時間復雜度為O(n),n是時間序列長度。總體來說,計算成本不高比較容易實現。 為了驗證APLR_TEO方法的有效性,本文在一系列標準時間序列數據集上進行時間序列的擬合誤差度量,分別比較在相同壓縮率和不同壓縮率下幾種分段線性方法的擬合效果。 實驗數據集采用Keogh等[13]提供的公開數據集KData。KData數據集包括了來自不同應用領域的數據集,被廣大時間序列研究者們采用。本文從KData中選取了研究者們常用的10個序列進行方法的對比評估,選取的序列如表1所示。 Table 1 Description of KData dataset 為了驗證APLR_TEO的性能,將本文方法與廖俊等[16]提出的基于極值點的分段線性方法PLR_ITTP、陳帥飛等[17]提出的一種基于關鍵點的時間序列線性表示方法PLR_KP和肖輝等[18]提出的基于時態邊緣算子的時間序列分段線性表示方法PLR_TEO這3種不同的分段線性方法進行對比。 本文提出基于時態邊緣算子的自主分段表示方法APLR_TEO,將時態邊緣算子與時間序列做卷積得到邊緣極值點,并根據一種自主的線性分段方法得到最終的關鍵點序列。方法需要輸入2個參數,參數u表示進行卷積的時態邊緣算子窗口大小,參數ε為累積分段閾值。由于時間序列來自不同領域,彼此的特征值取值范圍有一定差距,為了便于對比實驗,在采用線性分段方法之前首先對時間序列做規范化處理,將序列特征值規范化到[0,1],其規范化公式如式(11)所示: (11) 實驗運行在2.5 GHz CPU,8 GB內存Windows系統的Python 3.5.1環境下,在運行前樣本都已按規范化處理。本文選取了KData中的10個序列進行擬合誤差對比實驗。 以Burst序列為例,該原始序列長度為9 382,原始序列如圖4所示 ,在壓縮率為80%時采用APLR_TEO方法表示得到的擬合序列如圖5所示,可以明顯看出該方法能很好地刻畫出序列的總體趨勢和特征。 Figure 4 Original Burst sequence (9 382 sections) 接下來,為確定時態邊緣算子窗口大小,在KData數據集上進行APLR_TEO方法的性能評估。表2是在壓縮率為80%,u∈{1≤u≤8|u∈N}的條件下,u取不同值時,APLR_TEO的擬合誤差,其中加粗數據即為擬合誤差最小值。從表2可以看出,在測試的10條序列中,有2條序列在u=1時擬合誤差最小;有2條序列在u=2時擬合誤差最小;有3條序列在u=3時取得最小擬合誤差;有3條序列在u=4時取得最小擬合誤差。當u≥5時,擬合誤差值呈上升趨勢,且u取值越大,擬合誤差的增長幅度也越大。因此,在實際的運算過程中取1≤u≤4,在APLR_TEO方法中增加一個記錄環節,即用一個for(u=1;u<5;u++)循環,來記錄當u取何值使得方法的擬合誤差最小。 Figure 5 Fitting Burst sequence (1 876 sections) 在統一壓縮率為80%的條件下,比較PLR_ITTP、PLR_KP、PLR_TEO、APLR_TEO這4個方法在10個通用序列上的擬合誤差,實驗結果如表3所示。從表3中可以看出,當壓縮率為80%時,APLR_TEO方法在其中的9個序列上的擬合誤差都是最小,方法的整體表現優異。這10個序列都是維數在1 000維以上的高維序列,也從側面反映了APLR_TEO方法在高維數據集上所表現出的良好性能。如在Earthquake超高維序列上,APLR_TEO與其他3種方法的擬合誤差對比的差值更明顯,即APLR_TEO方法在高維數據集上的適用性更好。同時,這10個序列分別來自不同領域,本文算法在不同領域時間序列上都表現得十分出色,可見方法本身的適應性也很強。 Table 2 Fitting error of APLR_TEO representation Table 3 Comparison of fitting errors when compression rate is 80% 以Ocean數據集為例,比較PLR_ITTP、PLR_KP、PLR_TEO、APLR_TEO這4種方法在不同壓縮率下的擬合誤差,結果如圖6所示。隨著壓縮率的增大,即分段數減少,擬合誤差隨之增加。而壓縮率越高,擬合誤差的上升幅度越大。在不同壓縮率下,APLR_TEO方法的擬合誤差明顯小于PLR_ITTP、PLR_KP和PLR_TEO這3種方法的。 Figure 6 Comparison of fitting errors under different compression rates 本文將時態邊緣算子(TEO)引入時間序列的分段線性中,提出一種基于時態邊緣算子的時間序列自主線性分段表示方法。該方法利用時態邊緣算子與時間序列做卷積,得到邊緣極值點;再根據鄰域內的趨勢轉折距離來得到關鍵點。該分段算法很好地利用了鄰域內變化明顯的點,通過累計趨勢轉折距離的判斷機制實現了自主線性分段。 在一系列KData數據集上進行了擬合效果評估,實驗結果表明,本文方法有較強的適應性和穩定性,且對噪聲不敏感,能有效地壓縮時間序列。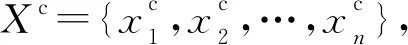
3 時態邊緣算子的自主分段方法
3.1 時序邊緣算子和邊緣點
3.2 邊緣極值點度量
3.3 自主分段線性方法
3.4 方法分析
4 實驗與分析
4.1 數據集描述
4.2 實驗方法
4.3 實驗結果與分析


5 結束語
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04河北畫報(2021年2期)2021-05-25 02:07:46中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04兒童繪本(2020年5期)2020-04-07 17:46:30兒童故事畫報(2019年5期)2019-05-26 14:26:14Coco薇(2016年2期)2016-03-22 02:42:52山東青年(2016年1期)2016-02-28 14:25:23Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
