基于記憶多項式模型的選擇自適應(yīng)預(yù)失真系統(tǒng)
2021-07-01 05:36:50易勝宏張紅升馬小東
自動化與儀表 2021年6期
易勝宏,張紅升,孟 金,馬小東
(重慶郵電大學(xué) 光電工程學(xué)院,重慶400065)
功率放大器(power amplifier,PA)是無線通信系統(tǒng)中的重要模塊,其性能特點備受學(xué)者們的研究,其中比較熱門的研究方向是功率放大器的線性化技術(shù),即預(yù)失真技術(shù)(pre-distortion,PD)。由香農(nóng)定律可知,要提高數(shù)據(jù)傳輸速率,勢必要提高數(shù)據(jù)傳輸帶寬,為了提高頻譜利用率,當(dāng)今對于數(shù)字基帶信號的調(diào)制方式幾乎都是高階調(diào)制方式,比如8PSK,16QAM,64QAM,OFDM 等。這些調(diào)制方式都是非恒定包絡(luò)的,并且其調(diào)制載波數(shù)量高達(dá)幾十個甚至上千個,因此在調(diào)制之后會產(chǎn)生較高的均峰比[1](peak to average power ratio,PAPR)。高PAPR 信號通過功放時,由于功放器件的記憶性和非線性特性,其輸出信號幅度曲線將產(chǎn)生比低PAPR 信號更嚴(yán)重的非線性畸變[2],信號頻譜將展寬至自身頻帶寬度的3倍及以上,嚴(yán)重影響相鄰頻帶的傳輸效率。
解決這種非線性失真的方法包括功率回退法、模擬預(yù)失真法和數(shù)字預(yù)失真法等,其中,數(shù)字預(yù)失真法(digital pre-distortion,DPD)由于其靈活性和低成本性,已被廣泛地應(yīng)用在工程設(shè)計中。目前,常用的數(shù)字預(yù)失真結(jié)構(gòu)包括直接型與間接型[3],直接型結(jié)構(gòu)的收斂速度較快,但收斂后的信號較原始信號的誤差較大;間接型結(jié)構(gòu)的收斂誤差較小,但收斂速度較慢,且容易引入噪聲干擾預(yù)失真效果。針對上述結(jié)構(gòu)的不足,本文采用記憶多項式(memory polynomial,MP)模型,提出新型選擇預(yù)失真結(jié)構(gòu)。通過Matlab 仿真,本文所提出的選擇預(yù)失真結(jié)構(gòu)系統(tǒng)在提高系統(tǒng)收斂速度的同時,降低了系統(tǒng)的收斂誤差。
1 數(shù)字預(yù)失真的基本原理
功率放大器的非線性失真是電子元器件的物理特性所導(dǎo)致的,非線性失真即功放的輸出信號相對于輸入信號產(chǎn)生的非線性形變。通常情況下,可以通過降低輸入功率來保持輸入輸出功率的線性關(guān)系,但這會大大降低功放的效率[4]。數(shù)字預(yù)失真的原理是,預(yù)先將輸入信號進(jìn)行畸變處理,即數(shù)字信號處理,使得畸變后的信號通過功放時,與功放所造成的畸變相補償,使得輸入-輸出信號整體呈現(xiàn)出線性的品質(zhì)。數(shù)字預(yù)失真的原理如圖1所示。
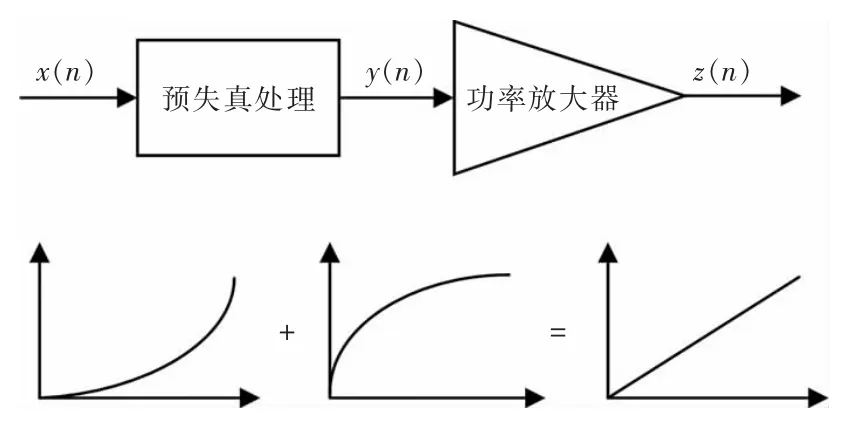
圖1 數(shù)字預(yù)失真原理圖Fig.1 Principle of DPD
圖中,x(n)為預(yù)失真器輸入信號;y(n)為經(jīng)過預(yù)失真處理后的輸出信號;z(n)為功放輸出信號。

式中:h(x)為功放的傳輸函數(shù),預(yù)失真器的傳輸函數(shù)和功放的傳輸函數(shù)互為反函數(shù),記為h-1(x),所以預(yù)失真器的輸出可以表示為

將公式(2)代入公式(1)中,得到公式(3)為
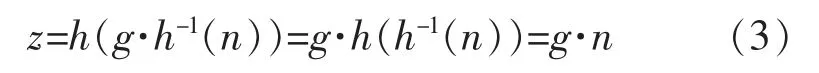
式中:g為常量,表示的是功放的增益因子,可以看出,經(jīng)過預(yù)失真器后,功放的輸出信號相對于輸入信號是整體線性放大的。
2 新型數(shù)字預(yù)失真結(jié)構(gòu)
2.1 現(xiàn)有結(jié)構(gòu)
目前,數(shù)字預(yù)失真系統(tǒng)的結(jié)構(gòu)包括直接型與間接型,直接預(yù)失真模型的原理如圖2所示。
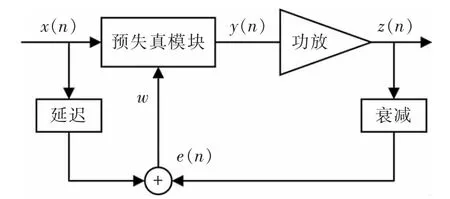
圖2 直接型預(yù)失真結(jié)構(gòu)原理圖Fig.2 Schematic diagram of direct structure
此模型的基本思想是將代價函數(shù)定義為衰減后的功放輸出信號與輸入信號之間的誤差,通過自適應(yīng)算法模塊不斷迭代,替換模型系數(shù),更新預(yù)失真器的參數(shù),使得衰減后的輸出信號與輸入信號之間的誤差(代價函數(shù))值最小化。在理想情況下,預(yù)失真處理和功放的行為是互逆的兩個過程,但此結(jié)構(gòu)存在不穩(wěn)定性,如果均方誤差(mean square error,MSE)不是關(guān)于功放擬模型參數(shù)的二次函數(shù),容易造成局部收斂的情況,導(dǎo)致系統(tǒng)的局部收斂情況[5]。其中x(n)為預(yù)失真器的輸入信號;y(n)為功率放大器的輸出信號;e(n)為x(n)與y(n)經(jīng)過衰減后的誤差信號。
間接型預(yù)失真模型的原理如圖3所示。間接預(yù)失真結(jié)構(gòu)是一種開環(huán)式的預(yù)失真結(jié)構(gòu),計算功放輸入與訓(xùn)練模塊輸出之間的誤差,其中z1(n)為功放輸出經(jīng)過自適應(yīng)算法訓(xùn)練后的輸出,使得預(yù)失真模塊的輸出信號向自適應(yīng)算法輸出信號逼近。間接預(yù)失真模型的優(yōu)點是不需要提前了解功率放大器的非線性特點和估算非線性函數(shù),即可準(zhǔn)確和穩(wěn)定的建立預(yù)失真模型,能穩(wěn)定得到系統(tǒng)全局的最優(yōu)解;缺點是由于間接預(yù)失真結(jié)構(gòu)求取的是功放的后置逆,功放輸出反饋回來的信號經(jīng)過下變頻和AD 轉(zhuǎn)換后會引入噪聲,其預(yù)失真后的輸出信號線性度較差[6],模型參數(shù)會產(chǎn)生一定程度的偏移。
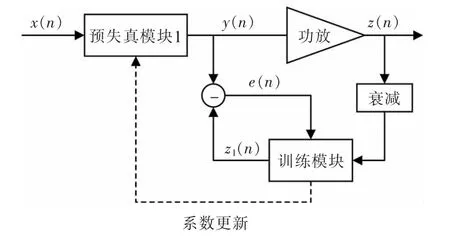
圖3 間接型預(yù)失真結(jié)構(gòu)原理圖Fig.3 Schematic diagram of indirect structure
2.2 改進(jìn)結(jié)構(gòu)
根據(jù)兩種結(jié)構(gòu)的優(yōu)缺點,本文提出一種閉環(huán)的選擇預(yù)失真結(jié)構(gòu),其原理如圖4所示。
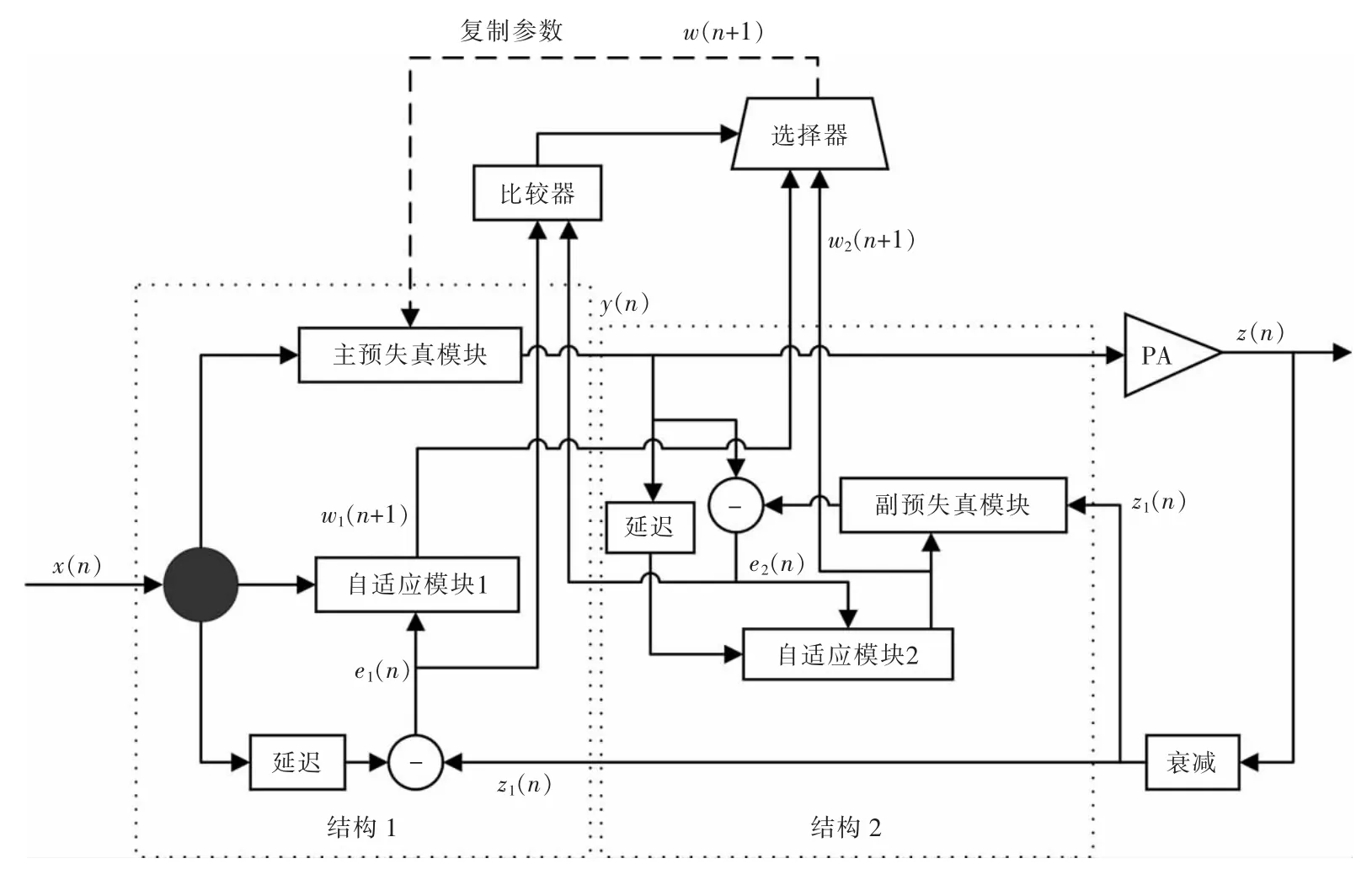
圖4 選擇預(yù)失真結(jié)構(gòu)原理圖Fig.4 Schematic diagram of selective structure
圖中:x(n),y(n),z(n)分別為系統(tǒng)輸入信號、主預(yù)失真模塊輸出信號、系統(tǒng)輸出信號;PA 為功率放大器;z1(n)為系統(tǒng)輸出衰減后的信號;e1(n)為系統(tǒng)輸入信號經(jīng)過延遲后與z1(n)的誤差信號;e2(n)為主預(yù)失真器的輸出信號與z1(n)經(jīng)過副預(yù)失真器處理后的輸出信號的誤差信號。比較器計算e1(n)與e2(n)的幅度大小,并與零值相比較,更靠近零值的誤差信號所對應(yīng)的自適應(yīng)模塊輸出會通過二選一選擇器輸出,作為主預(yù)失真器的復(fù)增益系數(shù)w(n+1),來替代自適應(yīng)模塊1 的迭代復(fù)增益系數(shù)w1(n+1),其中,w2(n+1)為自適應(yīng)模塊2 的迭代復(fù)增益系數(shù)。
2.3 數(shù)學(xué)分析
預(yù)失真系統(tǒng)的輸入信號為x(n),根據(jù)3 條路線的處理途徑,可以得出e1(n)和e2(n)的公式為
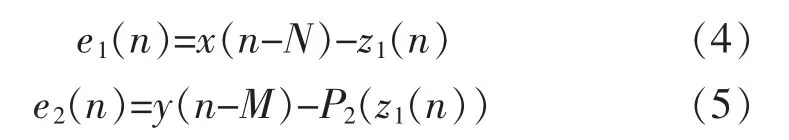
式中:P2(.)為預(yù)失真模塊2 的非線性基函數(shù);N為結(jié)構(gòu)1 延遲的采樣點數(shù);M為結(jié)構(gòu)2 延遲的采樣點數(shù),對于y(n)與z(n),有:
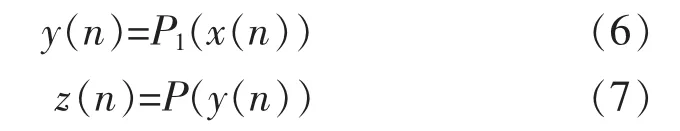
式中:P1(.)為預(yù)失真模塊1 的非線性基函數(shù);P(.)為功率放大器的非線性基函數(shù)。
輸入延遲信號與輸出信號的誤差信號通過NLMS 算法實現(xiàn)對主預(yù)失真模塊的參數(shù)調(diào)整,由于結(jié)構(gòu)1 的模塊較少,結(jié)構(gòu)簡單,延遲較小,故收斂速度較快,但對于非線性特性很強的功率放大器,誤差信號較大,故收斂后的NMSE 也較大[7]。其迭代公式為
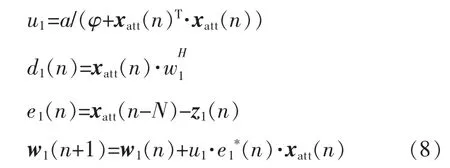
其中:a為一個固定的收斂因子,使算法收斂的a值范圍為0<a<2;φ 是一個很小的常數(shù),一般取0;d1(n)為xatt(n)經(jīng)過抽頭系數(shù)為w1的FIR 濾波器后的輸出信號;xatt(n)為輸出衰減后的反饋信號;x(n-N)為輸入信號的延遲,其中N為延遲項數(shù);u為可變步長因子;w1為主預(yù)失真模塊的模型系數(shù),可以表示為
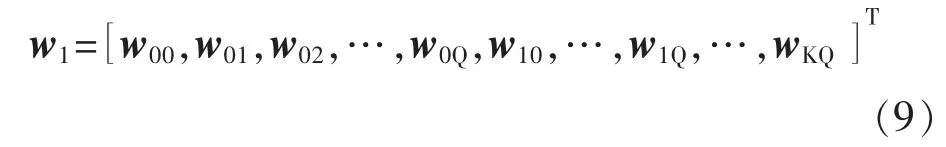
式中:Q為預(yù)失真模型的記憶深度;K為其非線性階數(shù)。同理,將式(5)中的預(yù)失真模塊2 的輸出帶入至自適應(yīng)算法中,則結(jié)構(gòu)2 的自適應(yīng)算法表達(dá)式為
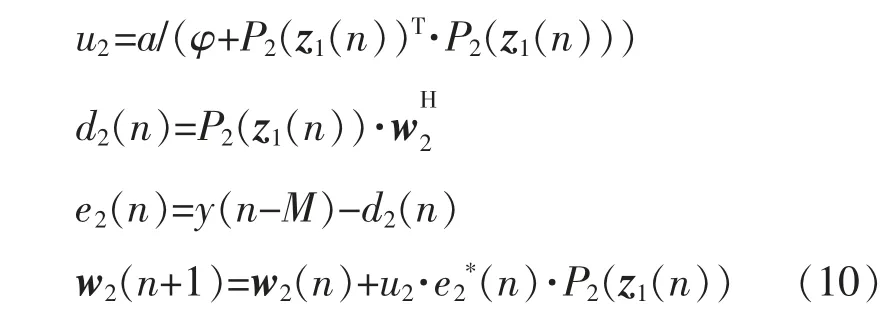
在系統(tǒng)收斂后,e1(n)≈e2(n)≈0,主預(yù)失真模塊與副預(yù)失真模塊均為功率放大器的逆模型,即:
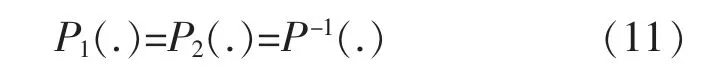
根據(jù)結(jié)構(gòu)2 的特性,其數(shù)據(jù)流動的模塊較多,故收斂速度較慢,但根據(jù)后續(xù)仿真的結(jié)果可以看出,其結(jié)構(gòu)的收斂后的誤差信號相較于結(jié)構(gòu)1 減小了0.5 個數(shù)量級。通過結(jié)合結(jié)構(gòu)1 與結(jié)構(gòu)2 能更好地實現(xiàn)數(shù)字預(yù)失真系統(tǒng)的收斂,通過1 個比較器與1 個選擇器就能實現(xiàn)該結(jié)構(gòu)。
2.4 模型選擇
Volterra 級數(shù)是由意大利數(shù)學(xué)家Vito Volterra的泛函理論演變而來的,它被稱為“有記憶效應(yīng)的泰勒級數(shù)”,是因為它包含了具有自變量的高次項和延遲項,這兩種特點使得此級數(shù)與功放的非線性和記憶性等物理特性不謀而合[8],Volterra 級數(shù)的表達(dá)式為
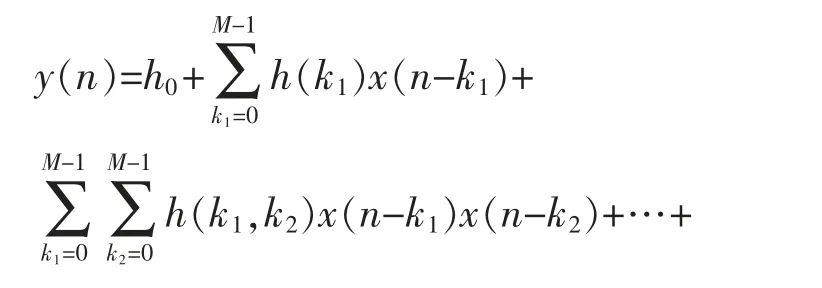
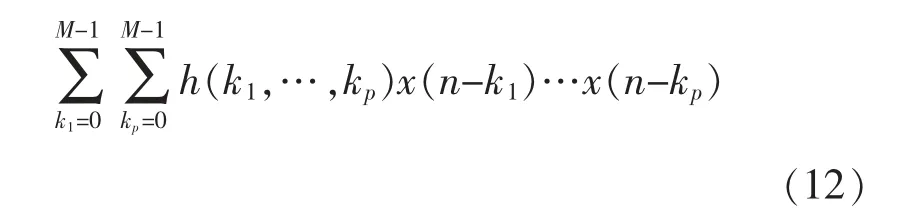
式中:y(n)與x(n)分別為通信系統(tǒng)的輸出信號與輸入信號;M為模型的記憶深度;P為非線性階數(shù);kp為對應(yīng)的記憶項系數(shù)。Volterra 模型包含延遲項和高次項,表現(xiàn)出功放特有的記憶性和非線性,能夠?qū)斎胄盘柕挠洃浄蔷€性的特征描述得十分準(zhǔn)確。但是,考慮到記憶深度為3,非線性階數(shù)為5 時,整個模型的系數(shù)個數(shù)已經(jīng)高達(dá)526 個,可以看出,Volterra 級數(shù)的模型系數(shù)隨著記憶深度和非線性階數(shù)的增加而急劇增加,復(fù)雜度過高。
本文的主預(yù)失真模塊與副預(yù)失真模塊均采用記憶多項式模型,數(shù)學(xué)表達(dá)式為
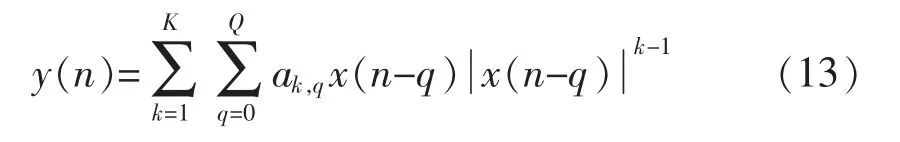
記憶多項式模型由于其較少的模型參數(shù)與延遲項,已經(jīng)被廣泛地應(yīng)用到數(shù)字預(yù)失真技術(shù)的仿真與實現(xiàn)中,由于本文所提出的新型結(jié)構(gòu)包含2 個預(yù)失真模塊,故為了降低模型的復(fù)雜度,本文采用此模塊進(jìn)行仿真,大大降低了以Volterra 級數(shù)為模型的仿真計算量,并且由于非線性階數(shù)為偶數(shù)時,MP模型產(chǎn)生的非線性失真頻段距離中心頻段較遠(yuǎn),可以用一個設(shè)計良好的帶通濾波器濾除[9],功放產(chǎn)生非線性失真的主要因素是其模型的奇數(shù)階所產(chǎn)生的頻譜混疊和互調(diào)失真,故在使用MP 模型時,可以忽略其偶數(shù)階的影響。式(14)可以重寫為
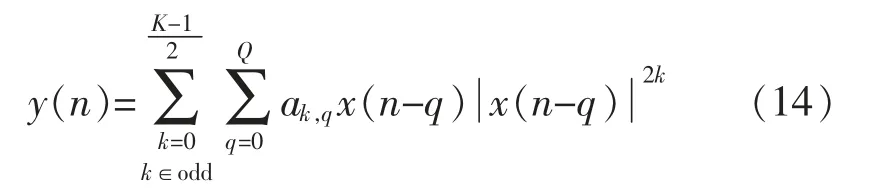
3 仿真分析
本文所提出的選擇數(shù)字預(yù)失真結(jié)構(gòu)采用Matlab進(jìn)行建模仿真。輸入信號采用的是由DMB 信號發(fā)生器所生成的符合國際標(biāo)準(zhǔn)的DMB 基帶信號,其符號速率為3.072 MHz,采樣率為8.192 MHz,信號的采樣點數(shù)為40000 個,設(shè)置收斂因子的值為0.2,預(yù)失真結(jié)構(gòu)采用提出的選擇預(yù)失真結(jié)構(gòu)。在整個仿真過程中,其模型系數(shù)是從實際的功放中提取出來的[10]。在記憶深度為3,非線性階數(shù)為5 的條件下,提取出的模型參數(shù)如下:

根據(jù)提取的模型系數(shù),本文對直接預(yù)失真模型、間接預(yù)失真模型和選擇結(jié)構(gòu)預(yù)失真模型在Matlab中進(jìn)行了仿真實驗,并通過以下幾個方面進(jìn)行比較和分析:①在記憶深度為3 和非線性階數(shù)為5 的仿真條件下對以上3 種結(jié)構(gòu)進(jìn)行仿真;②在輸入功率為2 dBm 的條件下,對3 種結(jié)構(gòu)的收斂速度與收斂后的功率譜密度(power spectrum density,PSD)進(jìn)行分析;③比較每種結(jié)構(gòu)的收斂后的歸一化均方誤差大小。歸一化均方均方誤差的公式為

式中:N表示對輸入信號的采樣個數(shù);y(n)為輸入信號;y(n)mean為輸入信號的均值。下面采用3 種結(jié)構(gòu),對比輸入信號功率為2 dBm 的仿真結(jié)果,其中N取4096。其誤差信號比較如圖5所示。
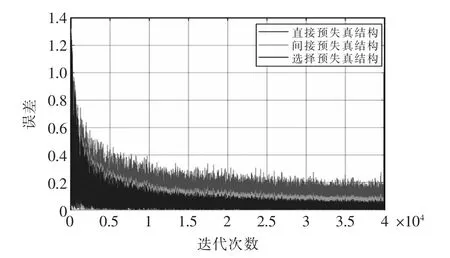
圖5 誤差信號比較Fig.5 Error comparison
采用選擇預(yù)失真結(jié)構(gòu)的預(yù)失真系統(tǒng),約在第25000 個采樣點收斂,其收斂速度與直接型預(yù)失真結(jié)構(gòu)相差無幾,但其收斂后的誤差信號大小遠(yuǎn)小于直接型預(yù)失真結(jié)構(gòu)收斂后的誤差大小,約為0.1 個單位,且比間接型預(yù)失真結(jié)構(gòu)的穩(wěn)態(tài)誤差要小約0.01 個單位。其收斂后的3 種結(jié)構(gòu)的功率譜密度如圖6所示。
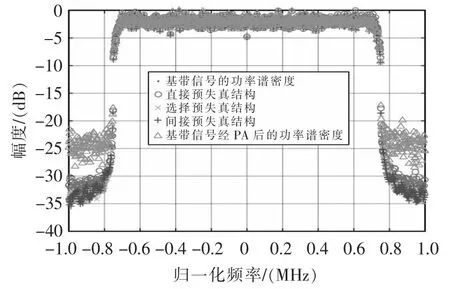
圖6 收斂后3 種結(jié)構(gòu)的功率譜密度Fig.6 Power spectrum densities of three structures
功率譜密度圖能夠非常直觀的描述預(yù)失真系統(tǒng)的效果,其中歸一化頻率的單位為MHz;幅度單位為dB,可以從圖中基帶信號頻段以外的頻段觀察信號的衰減狀況,根據(jù)圖6所示,選擇預(yù)失真結(jié)構(gòu)的帶外抑制效果要好于直接型預(yù)失真結(jié)構(gòu)約3 dB,而與間接預(yù)失真結(jié)構(gòu)的帶外抑制效果相差無幾。下面對3 種結(jié)構(gòu)的歸一化均方誤差進(jìn)行仿真,測試次數(shù)為8 次,仿真結(jié)果如表1所示。

表1 NMSE 測試結(jié)果Tab.1 Test results of NMSE
本文提出的選擇預(yù)失真結(jié)構(gòu)的收斂后歸一化均方誤差值均小于直接型結(jié)構(gòu)和間接型結(jié)構(gòu),分別為7 dB 與2 dB 左右,對于功放模型的擬合度更好。
4 結(jié)語
本文提出了一種新型的選擇預(yù)失真結(jié)構(gòu)系統(tǒng),功放模型采用的是記憶多項式模型。第一個改進(jìn)是合并了兩種結(jié)構(gòu)的特點,利用收斂速度更快的NLMS 自適應(yīng)算法調(diào)節(jié)2 個預(yù)失真模塊的復(fù)增益系數(shù);第二個改進(jìn)是提出了一種通過比較器與一個二選一選擇器所構(gòu)成的新的數(shù)據(jù)迭代方法,其結(jié)構(gòu)簡單,延遲小。仿真結(jié)果表明,相較于現(xiàn)有的預(yù)失真結(jié)構(gòu),改進(jìn)后的預(yù)失真結(jié)構(gòu)的收斂速度與直接預(yù)失真結(jié)構(gòu)相差無幾,但其收斂后的誤差比直接型與間接型兩種結(jié)構(gòu)都小,分別為0.15 個單位與0.03 個單位,且?guī)庖种菩Ч茫瑤馑p相較于以上兩種結(jié)構(gòu)提高了約2 dB。
猜你喜歡
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中華詩詞(2019年7期)2019-11-25 01:43:04
電子制作(2018年11期)2018-08-04 03:25:42
作文周刊·小學(xué)一年級版(2016年27期)2017-06-03 23:21:17
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
海外文摘(2016年4期)2016-04-15 22:28:55
