基于圖卷積算法的信貸風險防控研究
2021-07-02 11:49:06倪琦瑄
市場周刊 2021年6期
倪琦瑄
(南京財經大學,江蘇 南京210023)
一、引言
風險貫穿金融工作信貸業務的始終,防范風險是金融工作永恒的主題。當前,受新冠疫情的影響,國內經濟發展增速放緩,金融機構風險管理顯得尤為重要。信貸風險防控本質上是對信貸用戶信用的一種評估方式,通過綜合分析客戶的各種信息,進而對客戶是否能按時還款做出有效的評估,這種分析方式很大程度上依賴于客戶信息的特征挖掘。傳統信貸防控風險通過復雜網絡分析法,采用構建鄰接矩陣的方式描繪復雜網絡,從而去挖掘社會網絡的淺層特征,如節點的度、中心性、網絡密度等。隨著大數據時代的到來,許多金融科技公司積累了數億的個人用戶及商戶場景,在此基礎上,應充分有效運用現有的數據資源,突破傳統信貸服務模式,形成大數據信貸風險防控能力。因此,論文探討大數據時代下信貸風險防控研究所面臨的諸多挑戰,介紹基于圖卷積算法(GCN)的信貸風險防控研究方法,并對信貸風險防控提出建議與展望。
二、大數據時代下信貸風險防控的挑戰
(一)用戶信息的傳染性,使得傳統的人工數據分析難以鑒別有效特征
傳統的信貸防控方式嚴重依賴于專業的數據分析人員進行人工分析檢驗,但事實上,每一位數據分析人員其經驗和精力都相對有限,數據分析人員的主觀意識也會對結果造成一定的影響,因此,此類方式在可擴展性和準確性上都存在一定的局限性。同時,許多在同一條產業鏈上的企業都相互關聯,當其中一家企業出現問題時,其他相關企業也會受到牽連,這種傳染性也加大了出現信貸風險的可能性,使得傳統的人為分析難以有效預測。而基于圖卷積這類深度學習框架的網絡表示學習方法,可以自發式地挖掘信貸用戶信息的非線性關系,從而極大地提高信貸風險防控的準確度。
(二)用戶關系的稀疏性以及用戶數量的大規模性,使得傳統分析法難以應對時間與空間挑戰
傳統的復雜網絡分析法將金融機構收集到的用戶信息整合抽象為復雜網絡的形式,即信貸用戶網絡,利用鄰接矩陣的方式描繪網絡的復雜結構。在互聯網金融快速發展的當下,用戶數目出現上百萬甚至上百億的爆發式增長,同時,用戶連接呈現冪律分布的特點,即網絡中大部分節點只有少量的連接,而小部分的關鍵節點具有較多的連接。由于網絡中大部分節點連接的稀疏性,傳統的鄰接矩陣方法存在嚴重的計算機存儲資源浪費的現象,也難以挖掘網絡中更高階更復雜的關系。在具體的信貸風險分析過程中,其在時間與空間復雜度上都面臨極大的挑戰。
(三)用戶屬性特征的高維性,使得傳統分析法難以挖掘其隱式關系
信息社會背景下,用戶的一切行為都可以轉化為各種類型的數據信息,包括結構數據信息與非結構數據信息,傳統的復雜網絡分析法,通過對信貸客戶的關聯關系進行建模,構造信貸用戶網絡,再利用網絡中的一些表層信息,例如節點的出度和入度,去觀測網絡中的關鍵用戶,或者是通過計算各類節點中心性,以判斷節點在網絡中的位置。這種方法重視了網絡中的顯式連接,考慮了用戶之間的交互行為關系,但忽略了網絡中的非結構關系。在互聯網快速發展的當下,客戶的屬性特征也展現出前所未有的多元化,如何從大量冗余信息中提取更有用的關鍵信息,挖掘屬性與屬性之間的隱式關系,是當前需要考慮的一個問題。與此同時,深度學習方法例如圖卷積,同時重視結構數據信息與非結構數據信息,能夠高效挖掘海量信息中的非顯性關系。
三、基于圖卷積算法的信貸風險防控方法
(一)圖卷積算法概述
圖卷積算法(GCN)旨在將節點映射到潛在空間,并保留豐富的結構信息和屬性特征,為網絡分析任務提供了一種新的解決方法,已在許多現實應用場景中驗證了其挖掘網絡特征的有效性。其數學模型定義如下:

F
表示網絡的屬性特征矩陣,A
表示網絡的鄰接矩陣,W
和W
分別為兩層的參數矩陣,Z
表示通過學習得到的隱層向量表示。其模型流程如圖1所示,通過輸入網絡的屬性特征矩陣和鄰接矩陣,疊加兩層的圖卷積層,再設置相應的分類或預測任務目標函數,根據目標函數進行梯度下降更新,優化模型中的各類參數,反復迭代至收斂,即可得到最終的網絡分析結果。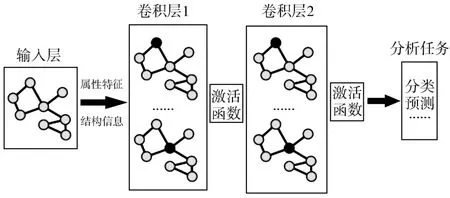
圖1 圖卷積流程示意圖
(二)信貸用戶網絡構建
信貸風險管理通常考慮用戶的兩個方面,一是其內部的基本信息屬性,二是其在社會中與其他個人用戶或企業用戶的交互行為。在進行基于圖卷積算法的信貸風險分析前,首先需要構造信貸用戶網絡以刻畫用戶之間的交互信息,其關聯可以從原始的客戶數據中提取,其中用戶、商戶、公司等作為網絡中的節點,用戶之間的社交行為、消費互動、位置關系、業務關聯等作為節點之間的連接。通過這種方式,可以將原始用戶數據抽象成如圖2所示的可視化網絡。其結構關系信息由鄰接矩陣A
=a
進行描繪,當a
=1時,表示用戶i
和用戶j
之間存在某種關聯,反之,則沒有連接。此外,除用戶之間的關聯信息外,每個用戶也包含著豐富的屬性信息,其屬性信息則可以由特征矩陣F
=[f
,f
,f
,…,f
]加以描繪,如個人的性別、年齡、收入區間、過往借貸史等信息,網絡中的每個節點對應一組代表屬性信息的向量f
,其中N
表示網絡中的用戶總數。對于大規模信貸用戶網絡而言,單純的鄰接矩陣方式存在難以挖掘更深層次聯系的問題,而單一的屬性特征矩陣又由于現實用戶屬性存在大量冗余,其每一維特征之間的關聯難以直接辨別。因此,在構建信貸用戶網絡之后,仍需要更有效的方式去挖掘信貸用戶網絡中的更深層次的信息。針對網絡中各種顯示連接或隱式屬性關系,采用圖卷積的方式可以有效對客戶的財務狀況、還款意愿、履約能力等各方面的因素綜合量化,挖掘客戶之間的深層信息,從而根據不同的風險等級制定相應的個性化策略。
圖2 信貸用戶網絡構建示意圖
論文以銀聯商務信貸用戶數據集為例,該數據集來源于2018年銀聯商務所舉辦的“信貸用戶逾期預測”算法大賽,以1∶2的逾期與未逾期用戶比例選取6450條用戶信息,其屬性信息包括描繪用戶基本屬性、消費力信息、理財習慣以及信用信息共計40維的特征向量。論通過分析用戶行為數據之間的相似度,對于擁有相似用戶消費偏好的用戶,為其構建連邊。
(三)基于圖卷積算法的信貸風險分析建模與應用
在信貸用戶網絡中,節點周圍鄰居的信用資質可以影響甚至反映其自身信用資質。圖卷積算法其根本思想在于通過節點和節點之間的連接信息以聚合鄰居節點的屬性信息到當前節點上,從而得到包含用戶關聯結構信息和其屬性特征信息的節點表示。在具體分析中,論文疊加了兩層的圖卷積層,將網絡的屬性特征矩陣F
以及鄰接矩陣A
作為模型的輸入,根據不同的分析任務,設置相對應的目標函數,最終即可得到相關的分析結果,論文主要針對以下兩個方面進行分析。1.反欺詐
反欺詐是信貸風險控制的重要一環,目的是檢驗出帶有欺詐意圖的客戶,在現實生活中,有時一些企業或個人會隱藏自身與其他用戶之間的關系,將自身偽裝成信用良好的客戶。傳統的應對策略往往是通過線下面談或人工電話等手段進行多方數據的交叉驗證。這些傳統手段通常耗費大量的人力和物力資源。論文在圖卷積模型的最后一環設置相應的鏈路預測目標函數,即可有效對于網絡中的缺失連接或是虛假連接進行比對,從而進行反欺詐,提升信貸安全性。其目標函數具體如下:

該目標函數為交叉熵函數,通過計算網絡中用戶隱層向量表示的內積來重構網絡中的原始連接,不斷優化后可以有效預測網絡中未知連接的存在。
論文將銀聯商務信貸用戶網絡的真實連接以3∶7的比例劃分為測試集和訓練集,將已確定的真實連接作為圖卷積模型的輸入,通過迭代訓練得到隱層表示,將其表示向量的內積結果作為每對節點即每組用戶對之間存在連接的可能性,以預測被隱藏的測試集中的連接,其最終準確率可以達到79.2%。在現實反欺詐過程中,通過將預測的連接結果與現有數據進行對比,可以有效發現網絡隱層信息與現有信息的差別,從而精準定位用戶之間被掩藏的關聯。
2.信用評估
如何有效劃分用戶信用度的高低也是信貸風控需要著重考慮的問題。通過構建信貸關系復雜網絡,利用圖卷積算法進行關系網絡中每個用戶的表示學習,區別于傳統的復雜網絡分析法,金融機構可以由此得到帶有用戶深層特征的表征向量。通過對部分信用度良好的用戶進行打分,同時確立相應的不良信用庫,將不同的用戶標注信用評分作為其標簽信息,以預測標簽與已知標簽的交叉熵函數作為其目標函數,可以有效對網絡中未標注信用信息的用戶進行評估。其信用評估預測目標函數設置如下:

y
表示真實的已標注信用等級標簽的用戶的標簽集合,Y
表示該網絡(L
×N
)維的標簽矩陣,Z
表示模型中最終所學習得到的隱層表示。通過計算其隱層表示與現有標簽的損失值,可以有效訓練該分類模型。論文以銀行商務信貸數據集為例進行了信用評估的試驗驗證,以1∶2的逾期與未逾期用戶比例選取了20%的數據集作為訓練集進行訓練,隱藏余下80%的數據集標簽作為驗證集,逾期用戶其信用標簽為0,未逾期則標簽為1,在每次迭代訓練后,得到網絡中帶有少量標簽監督的每個用戶節點的表示向量,通過Softmax函數計算其每個標簽的得分作為預測結果,與真實數據對比計算交叉熵作為損失值反向更新模型中的參數矩陣,經過200次迭代訓練后,最終準確率可以達到74.6%。
四、對策和展望
(一)提升數字化風險防控意識
通過充分利用論文所述的圖卷積方法可以幫助企業實現高效的信貸風險管理。在“互聯網+”時代,金融企業急需轉變傳統思維,加強數字化信貸風險防控意識,將所掌握的用戶的基本情況、消費行為、理財偏好等多方信息整合收集,提升信貸風險防控環節的數據利用率,構建大數據風險防控體系,通過動態增量式的學習方式持續優化金融企業的信貸分析模型,引入更多的新興技術以增強其風險分析的有效性和準確性。
(二)打通平臺信息,共享數據倉庫
當前,運用圖卷積等大數據相關技術進行信貸風控分析,面臨的一個問題是用戶數據的分散性。由于缺乏有效的信息共享機制,會導致用戶信息缺失和重復取證的人力資源浪費現象,現實互聯網金融用戶信息的復雜性和大規模性使得構建共享數據倉庫日趨重要。文中所使用的數據集樣本數量較少,屬性特征以及結構信息也不充分,在現實大規模數據分析中可以通過自然語言處理、情感分析等深度學習方式綜合考慮互聯網時代的更多信息如用戶的網購記錄、社交發言等,以建立健全個人用戶及企業用戶的共享數據倉庫。
(三)加強大數據管理
一方面,大數據風險控制依靠圖卷積等深度學習高新技術,去除了人為的主觀影響,帶來了高效的新型信貸風險分析方法;另一方面,隨著金融科技行業的發展,大量的互聯網用戶信息被收集,其本身也具有一定的風險性。如用戶隱私泄露問題,其對互聯網技術的安全管理提出了更高的要求,一旦出現用戶信息被非法截取或篡改,將會對用戶隱私和權益造成巨大傷害。另外,互聯網海量信息的涌入使得用戶數據的真實性受到影響,直接決定后期信用評估結果的可靠性。因此,機構需創新數據安全防范措施,在信息的收集、管理、使用等環節都要有第三方監督以及嚴格的制度規范,同時,也應加強科研投入提升信息鑒別能力,提升管理人員水平,以便切實保障用戶信息的真實性和安全性。
猜你喜歡
環球時報(2022-04-25)2022-04-25 17:20:21
今日農業(2021年15期)2021-10-14 08:20:18
人大建設(2020年3期)2020-07-27 02:48:40
今日農業(2019年14期)2019-09-18 01:21:44
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
