基于Matlab的聽音識曲系統的設計與實現
2021-07-12 08:35:46徐清釧趙彥鈞張丹露
科技視界 2021年18期
徐清釧 趙彥鈞 張丹露 弓 創 楊 光
(黃河科技學院,河南 鄭州 450000)
0 引言
隨著信息時代的發展,語音識別技術在生活中的應用越來越廣泛,國內有很多機構都在研究這方面的工作。“聽音識曲”研究是當前的熱門領域,本文通過研究原有的聽音識曲系統,掌握識別的基本原理,并使用Matlab程序搭建一個簡易的聽音識曲系統。
1 系統整體架構
整體流程分是:運行GUI界面,然后擇曲庫的路徑導入曲庫,在導入曲庫后可以選擇識別方式,最后點擊開始識別等待識別輸出結果即可。圖1即為整體流程。

圖1 整體流程
2 音頻指紋提取
整個提取的過程是:添加曲庫的音樂文件、對轉換過格式的文件進行預加重、分幀、加窗、快速傅里葉變換、梅爾濾波器設計、輸出梅爾系數。音頻指紋提取整體流程如圖2所示。

圖2 音頻指紋提取整體流程
2.1 分幀加窗
音頻信號處理之前要進行截短處理[7],通過函數來完成分幀效果。
加窗分幀操作通過窗函數實現,每移動一次窗函數就得到一幀的音樂片段。把音頻段分割成大小為20 ms的幀,音樂片段之間需要重疊1/3,并使用相同長度的窗函數對每一幀平滑處理。時域波形和頻譜圖如3所示。

圖3 時域波形和頻譜圖
本系統使用漢寧窗,用ωN(n)表示窗函數,用N表示窗函數的長度,其表達式如式(1)所示:
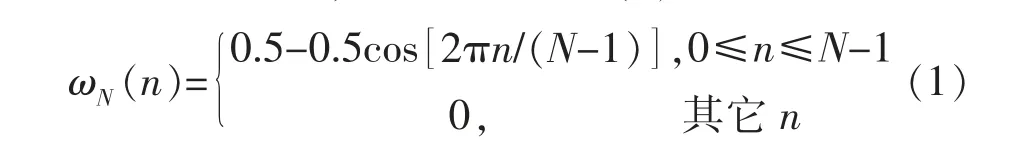
2.2 音頻指紋劃分
將經過FFT變換的音頻信號,按照幀長、幀移和峰值幅度進行分幀,每一幀都是音頻指紋的特征,將其劃分為30個不同的子代可以更好更準確地提取指紋信息。若音頻匹配比較粗糙的話,可以分割更多幀長,以達到后期更好的匹配效果。音頻指紋劃分的公式如式(2)所示:

式中,Fmin為最小頻率值,即310Hz,Fmax為最大頻率值,即2100 Hz,M表示子帶個數,f(m)表示第m子帶的起始頻率,同時也是第m-1子帶的終止頻率。
2.3 MFCC算法原理
梅爾倒譜系數[6],這個參數的計算首先就要對語音信號通過一個高通濾波器預加重處理,然后對音頻信號進行分幀,以及梅爾濾波器、窗函數的設計和傅里葉變換的應用。
3 音頻識別算法
3.1 DTW算法應用
待識別片段與曲庫中的音樂片段絕大多數不一致,一首完整的音樂大概300 s,而識別過程中,識別過程在15 s左右,兩段音頻長度不同,因此在一定程度上需要特殊的算法,對特征參數序列(見圖4)重新進行時間的校準。所以可以選用DTW算法[3]。
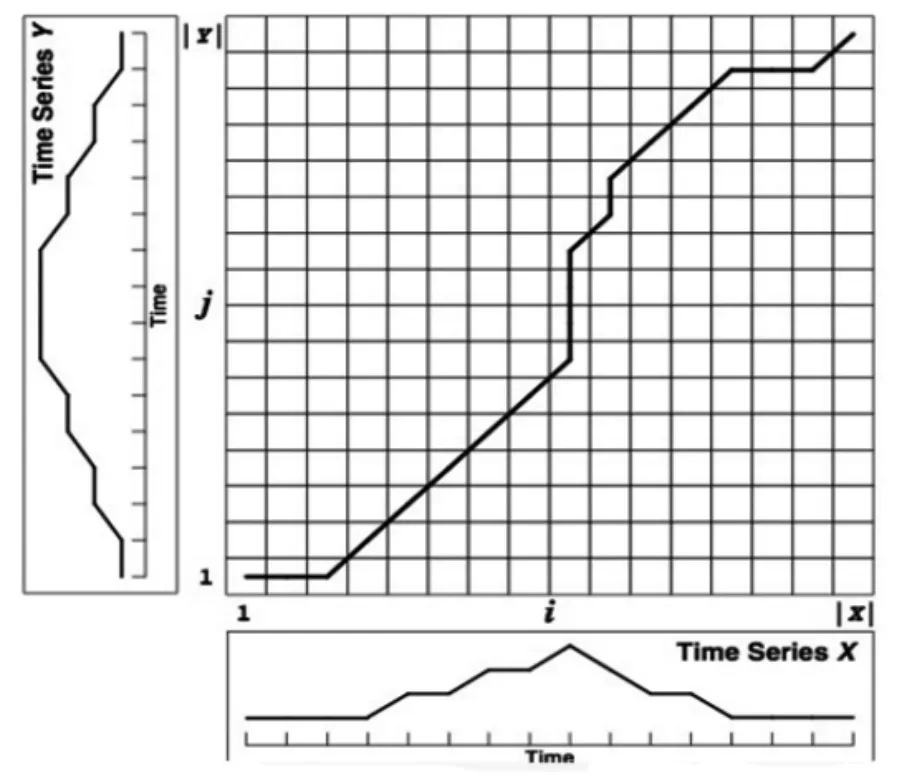
圖4 特征參數序列
3.2 最小似然距離擬合匹配
此擬合算法首先生成一個i×j的矩陣,i是矩陣的行數,j是矩陣的列數,人們稱它為似然距離,用p表示,似然系數用q表示,因為系數矩陣的特征值具有獨特性,所以每一幀音頻的似然系數是不同的,分別對每一首待識別的音頻進行計算,求出似然系數,并將與所建立音樂庫里的歌曲的似然系數值作差再取絕對值,能得到一個最小值,這個最小值就是最小似然距離(見圖5),并通過此算法篩選出這個最小值,它對應的歌曲就是識別的結果。原理公式如式(3):

圖5 最小似然距離

式中,p為;q為;i為;j為。
4 GUI界面設計
GUI界面是該系統的操作界面(見圖6),可以根據界面上的文字提示來逐步完成對音樂的識別:打開MATLAB平臺,點擊運行即可。

圖6 GUI界面
點擊曲庫路徑按鈕,可以自行跳轉到所建立的音樂庫路徑,任意點擊音樂庫里的一首歌,可以將全部歌導入到檢索曲庫里。
點擊選擇音樂,選擇一首待識別的音樂對該首音樂提取特征,生成索引值,與最初的模板庫里多個索引信息建立的索引庫進行匹配。
5 歌曲識別率
由于“聽歌識曲”系統主要針對歌曲進行設計,因此,隨機挑選出當下較熱門的5首流行歌曲進行測試。為了避免誤差以及確保驗證系統的穩定性,每首歌曲分別進行十次測試,記錄下正確次數并且取平均值,計算正確率,系統在音樂文件識別上的正確率可以達到100%,在錄音文件的識別上正確率達50%~60%。具體識別結果見表1、表2。

表1 音樂文件識別率

表2 錄音文件識別率
6 結語
本文所設計的“聽音識曲”系統,可以幫助人們識別一首不知名的音樂片段,使人們不再為錯失一首好聽的音樂而煩惱。系統主要完成了將音頻信號轉化成音頻特征、樂庫的建立、特征匹配系統的搭建和GUI頁面的生成等工作;基本達到了預期的要求,能夠滿足人們的需要。當然,系統在設計方面還存在一些缺陷,譬如說,通過錄音的方式進行識別的準確率還不夠高,如果需要提高準確率,還要用一些更專業的錄音設備和對濾波除噪聲算法進行更深層次的研究,對MFCC、DTW以及最小似然距離擬合匹配算法的優化,減少其他噪聲的干擾;本文中的曲庫做得還不夠豐富,只有一少部分的音樂,能夠識別的樂曲有限。今后,可以從增加樂庫歌曲信息與反應時間兩方面進行優化,盡可能多地增加樂曲,盡可能少地縮短識別時間,盡量使用更加專業的錄音設備,將錄音識別方式識別歌曲的準確率上再做一些提升。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
小天使·一年級語數英綜合(2020年3期)2020-12-16 02:56:12
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
藝術啟蒙(2018年7期)2018-08-23 09:14:16
兒童繪本(2017年24期)2018-01-07 15:51:37
家庭影院技術(2017年9期)2017-09-26 03:41:45
東方藝術·大家(2016年6期)2016-09-05 07:30:56
