基于大津算法和深度學習的開集聲紋識別自適應閾值計算方法
2021-07-15 02:01:04李旭東周林華
吉林大學學報(理學版) 2021年4期
李旭東, 周林華
(長春理工大學 理學院, 長春 130022)
聲紋識別是根據人體自身聲音特征識別身份的一種生物認證技術[1]. 基于聲紋識別的數據集, 聲紋識別可分為閉集和開集兩類. 關于閉集聲紋識別的研究目前已取得了許多成果, 但關于開集聲紋識別的研究報道較少且難度較大. 在實際應用中, 很難選擇出一個閾值判斷測試樣本是否存在于訓練集中, 而所選閾值是否合適直接影響模型識別的準確性. 目前較經典的閾值有固定閾值[2-3]、 自適應動態閾值[4]和RS閾值[5-6]. 開集聲紋識別系統中基于得分規整法[7-8]、 兩級決策的說話人辨認法[9]等方法已取得了一定的成果, 但實際應用中還存在特征參數提取、 模型算法的缺陷、 閾值計算等諸多問題. 因此, 本文結合深度置信網絡(DBN)從Mel倒譜系數(MFCC)中提取語音深層特征, 通過Gauss混合模型(GMM)計算特征的相似度值, 并在此基礎上提出一種基于大津算法的自適應閾值計算方法, 最后計算出測試集上的精確度和召回率作為本文方法的性能評價指標.
1 基于大津算法的閾值計算
大津算法(Otsu)[10-12]是在判別分析或最小二乘原理基礎上推導出來的. 基于Otsu算法的思想, 將空間分布有一定距離的兩組不同隨機變量產生的隨機數集合分為A,B兩部分, 遍歷閾值得到的類間方差越大, 表示分割效果越好.
對于總數為N的隨機數集合, 用L表示隨機數的最大值,ni表示隨機數為i的個數,pi表示隨機數為i的概率, 則
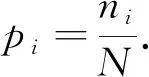
(1)
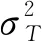
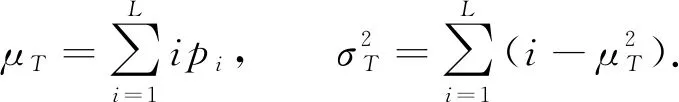
(2)
將屬于集合A的數占總隨機數的比例記作ω0, 其平均值記作μ0, 則
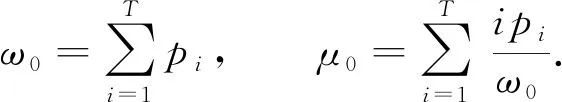
(3)
將屬于集合B的數占總隨機數的比例記作ω1, 其平均值記作μ1, 則
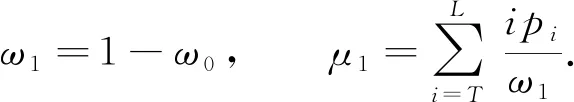
(4)
集合A,B的方差表示為
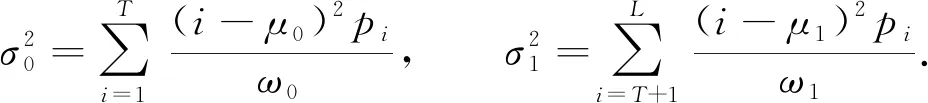
(5)
從而可得隨機數集合的類內方差為

(6)
類間方差為
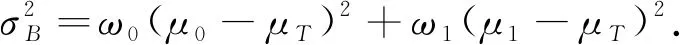
(7)
最佳閾值T是使分離度η(T)最大時的數值, 表示為
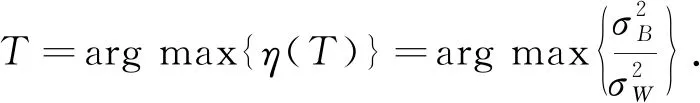
(8)
2 深度特征提取與GMM相似度值計算
2.1 基于深度置信網絡的深度聲紋特征提取
深度置信網絡是由多層受限Boltzmann機(RBM)堆疊再加一層分類器而形成的一種深度學習模型, 深度置信網絡可發現特征之間的相互聯系, 選擇并組合特征, 從而提高特征的表征能力, 因此可作為聲紋特征的深度特征提取器[13-14]. RBM是一種基于統計熱力學原理的神經網絡, 通常情況下, 聲紋特征提取采用Gauss-Bernoulli RBM模型[15].
2.1.1 Gauss-Bernoulli RBM模型
RBM由兩層神經元構成: 一層是顯層神經元vi, 用于表示輸入數據; 另一層是隱層神經元hj, 用于表示通過對輸入數據學習得到的內在特征.兩層神經元間全連接, 同一層神經元間無連接.如果一個RBM有n個顯層神經元,m個隱層神經元, 則Gauss-Bernoulli RBM的能量定義為
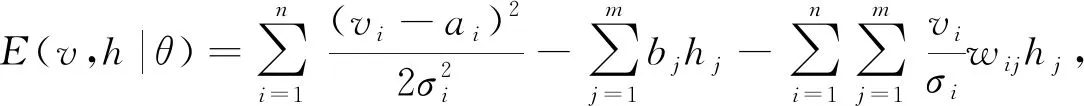
(9)
其中θ={wij,ai,bj,σi}是RBM的參數,wij表示第i個顯層神經元與第j個隱層神經元之間的權重,ai和bj表示對應的偏置,σi表示顯層神經元的標準差.基于式(9)的能量函數, 可得(v,h)的聯合概率分布為
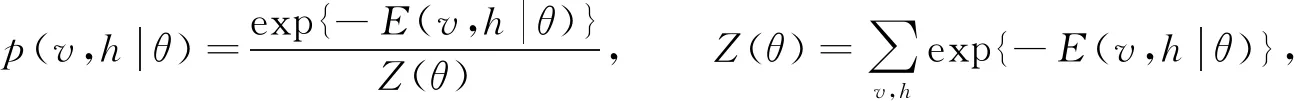
(10)
其中Z(θ)為配分函數, 用于歸一化, 通過顯層神經元和隱層神經元所有可能分配的能量計算.訓練RBM時, 由于顯層神經元之間和隱層神經元之間是條件獨立的, 因此v和h的條件分布如下:
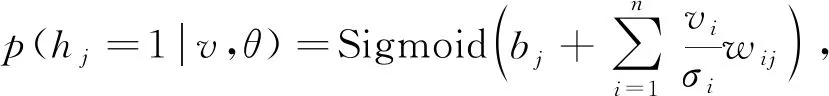
(11)
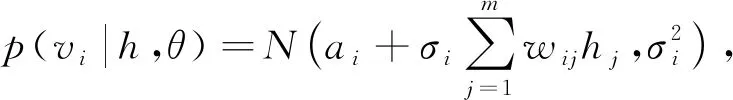
(12)
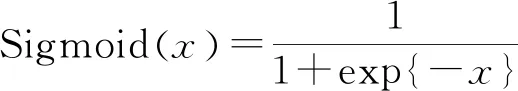
為解決RBM的訓練速度問題, 基于對比散度算法(CD)[16]得到RBM各參數的更新準則:
Δwij=ε(〈vihj〉data-〈vihj〉recon),
(13)
其中ε表示學習率, 〈〉data表示模型的期望, 〈〉recon表示通過Gibbs采樣初始化數據得到的樣本分布期望.
2.1.2 RBM的訓練
對一個多層DBN訓練時, 先通過從語音中提取的MFCC作為第一個RBM的輸入, 并采用無監督學習方式逐一訓練RBM, 將訓練好的RBM堆疊在一起, 作為DBN的預訓練. 然后利用BP(back propagation)算法對DBN各層參數進行微調, 將誤差反向傳遞對其進行修正.
2.1.3 聲紋深度特征提取
對輸入的原始24維MFCC特征做歸一化預處理, 使每個說話人的特征分布滿足μi=0及σi=1, 從而避免訓練樣本分布的重新估計. 深度神經網絡由3個RBM構成, 網絡結構為24-256-256-256, 輸出層是Softmax函數, 聲紋深度特征輸出層取最后一個隱藏層, 經過此網絡即可將24維的MFCC特征轉化為256維的深度聲學特征. 聲紋深度特征提取網絡如圖1所示.

圖1 聲紋深度特征提取網絡Fig.1 Voiceprint deep feature extraction network
2.2 GMM相似度值計算
將DBN提取到的深度聲學特征作為Gauss混合模型的輸入, 每個說話人的語音信號都在特定空間形成了特定分布, 可用這些分布描述說話人的個性特征. 通過訓練GMM可得到屬于集內說話人與屬于集外說話人的具有很高區分度的GMM相似度值.
GMM是一個可以用權重系數和為1的若干個Gauss分布表示一個說話人不同語音的模型[17-18]. 設某個說話人的輸入語音特征為X={x1,x2,…,xN},xi是D維特征矢量, 則以該語音特征訓練混合度為M的GMM可表示為

(14)
其中:wk為對應pk(xi|θk)的加權因子;pk(xi|θk)為第k個單Gauss分布模型, 且滿足

(15)
式中uk是均值,Σk為協方差矩陣.因此, GMM可用參數θ={wk,uk,Σk}表示.
由于模型中存在隱變量不易進行參數求解, 因此通常采用最大期望(EM)算法進行參數求解:
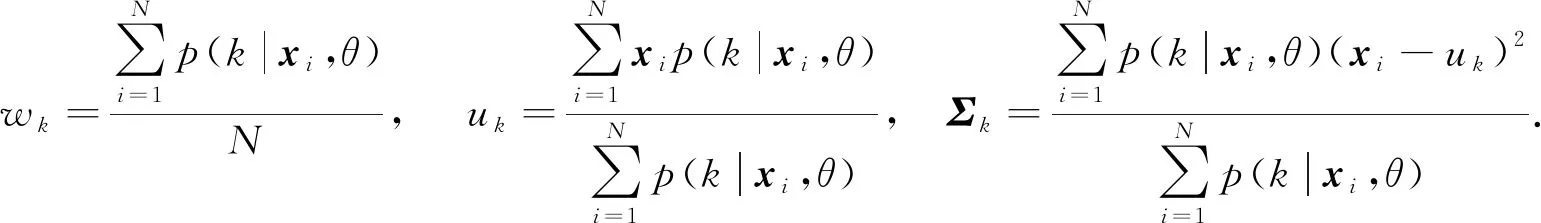
(16)
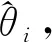
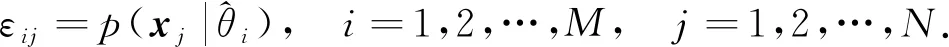
(17)
3 基于大津算法的開集說話人識別實驗
3.1 語音數據集及聲學特征
實驗所用音頻為清華大學CSLT公開的中文語音數據(THCHS-30). 為找到效果最佳的模型及模型所對應的參數, 本文將數據分為訓練集、 開發集和測試集, 其中訓練集8人(8人均為集內), 每人8條音頻; 開發集與訓練集為相同的8人, 每人20條音頻; 測試集3人(1人集內, 2人集外), 每人60條音頻. 實驗分為5組, 每組實驗依次選擇2人作為集外說話人, 其余8人輪流作為目標說話人建模, 共進行40次實驗.
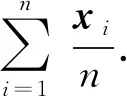
3.2 基于DBN-GMM的大津算法閾值確定方法
在某說話人的DBN-GMM中, 經檢驗屬于該說話人的特征相似度值近似服從正態分布, 而其他說話人的特征相似度值近似服從伽馬分布, 如圖2所示. 由于實際能參與訓練的語音較少, 特征相似度值不足以準確表征相似度值的分布情況, 故根據該說話人與其他說話人的相似度值所服從的分布產生兩個隨機數集合, 如圖3所示. 由圖3可見, 相似度值直方圖存在兩個波峰, 根據大津算法原理必存在能最合理劃分集內與集外的最佳閾值.
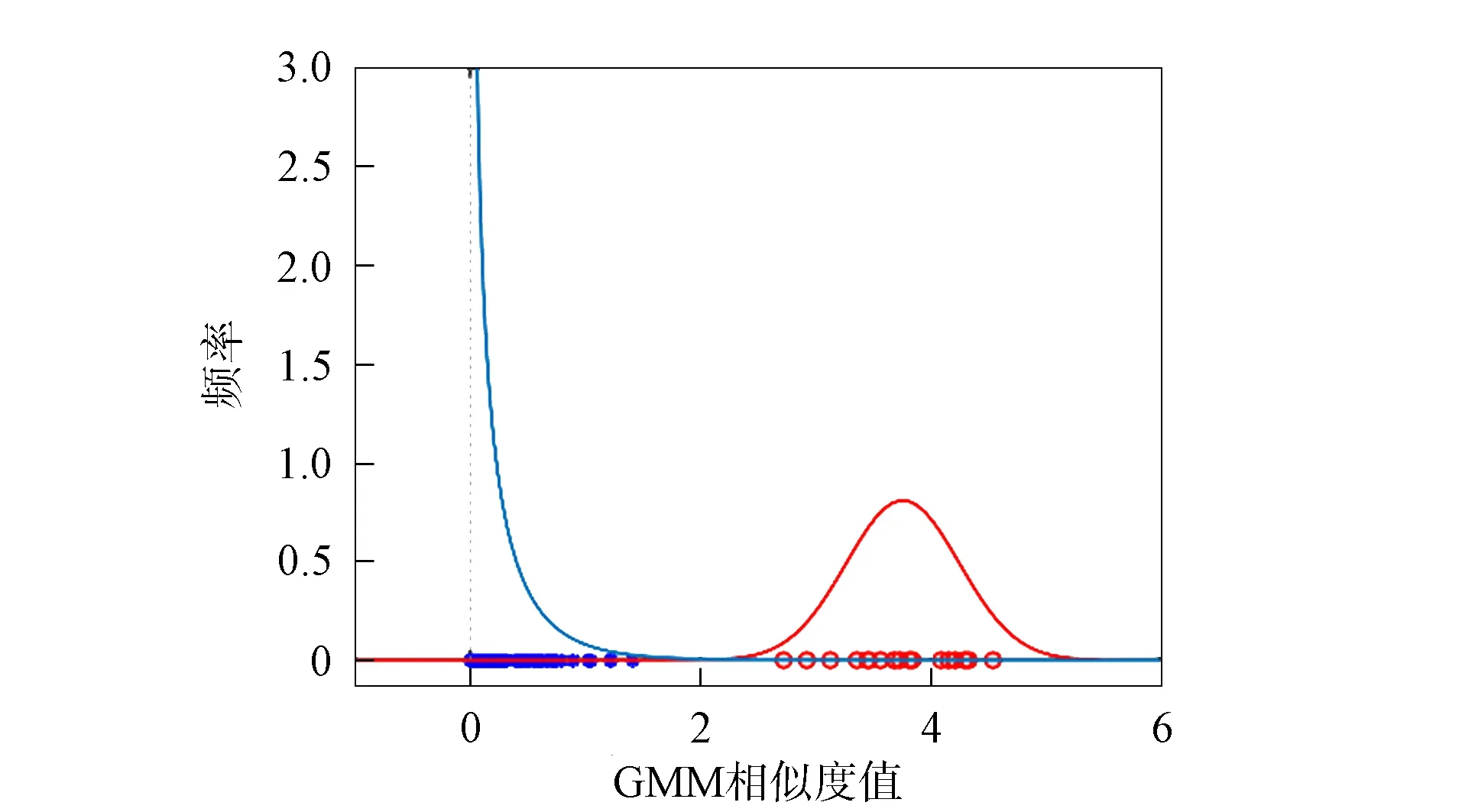
圖2 集內外相似度值分布Fig.2 Distribution of similarity values of inside and outside set
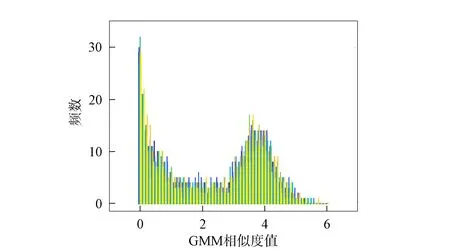
圖3 相似度值直方圖Fig.3 Histogram of similarity values
基于DBN-GMM的大津算法閾值確定方法實現步驟如下:
1) 將24維基本聲學特征MFCC經DBN訓練得到256維深度聲學特征;
2) 將256維深度聲學特征作為GMM的輸入, 計算特征的相似度值, 記集外特征相似度值的均值為L1, 集內信號相似度值的均值為L2, 并根據相似度值檢驗集內與集外相似度值符合的分布;
3) 根據該說話人與其他說話人相似度值符合的分布各產生10 000個隨機數, 限制條件為其他說話人產生隨機數的最大值不大于該說話人相似度值的最小值, 該說話人產生隨機數的最小值不小于其他說話人相似度值的最大值;
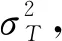
5) 在區間(L1,L2)內遍歷T, 并重復步驟4)計算出分離度η(T);
6) 取分離度η(T)最大時的T, 即為所求最佳閾值.
3.3 實驗結果與分析
為驗證本文算法對集內說話人和集外說話人的識別能力, 采用精確度和召回率作為評價指標, 計算公式為
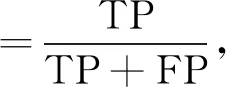
(18)
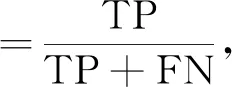
(19)
其中TP表示將屬于集內說話人的樣本正確預測為集內說話人樣本的數量, FP表示將屬于集外說話人的樣本錯誤預測為集內說話人樣本的數量, FN表示將屬于集內說話人的樣本錯誤預測為集外說話人樣本的數量.
精確度反映對集外說話人的拒識能力, 召回率反映對集內說話人的識別能力. 圖4為Otsu和EER的精確度對比, 圖5為Otsu和EER的召回率對比. 由圖4和圖5可見: 在與大津算法計算閾值算法相同的實驗環境下, 等錯誤率計算閾值的算法對于集內說話人的識別率為99.18%, 對集外說話人的拒識率為98.54%; 本文算法對集內說話人的識別率為99.32%, 對集外說話人的拒識率為100%. 因此, 本文提出的自適應閾值計算方法無論是對集內說話人的識別還是集外說話人的拒識都優于傳統的等錯誤率法.
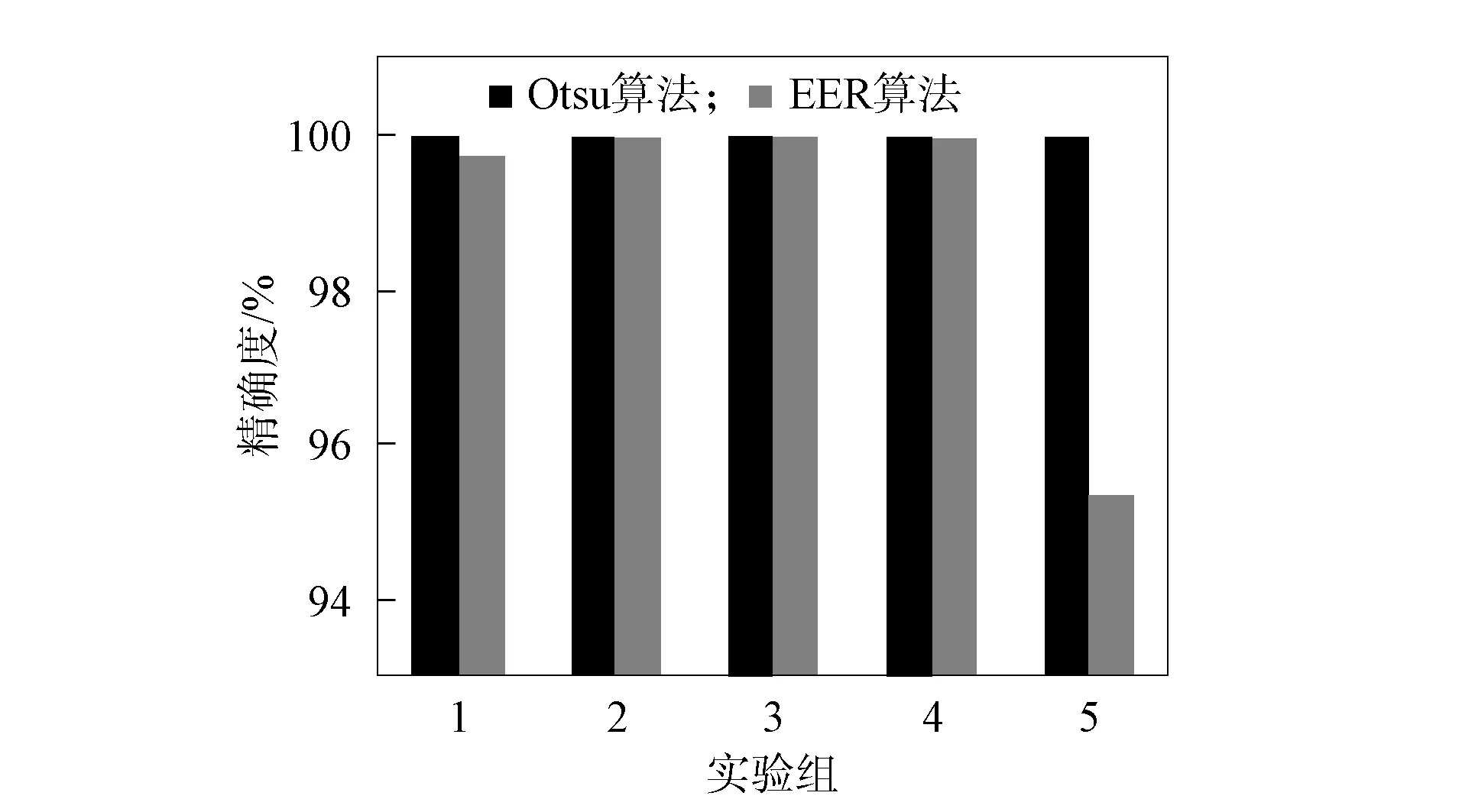
圖4 Otsu和EER的精確度對比Fig.4 Accuracy comparison of Otsu and EER
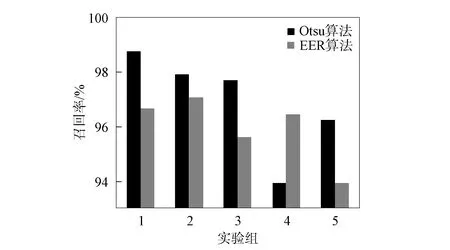
圖5 Otsu和EER的召回率對比Fig.5 Comparison of recall rate of Otsu and EER
綜上所述, 本文研究了開集聲紋識別閾值的計算方法, 提出了一種基于大津算法的開集聲紋識別動態閾值計算模型. 首先, 構建DBN模型作為深度聲學特征提取器, 通過GMM計算特征的相似度值; 其次, 采用大津算法計算特征相似度值的最大分離度確定閾值; 最后, 在CSLT公開的語音數據庫進行測試驗證. 實驗結果表明, 本文計算閾值的算法較等錯誤率計算閾值的算法具有更高的識別準確率, 該方法可行、 有效.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
