基于jupyter的大數據分析工具在網絡優化領域的應用研究
2021-07-20 08:54:36蔡林
中國新通信 2021年9期
關鍵詞:大數據
蔡林

【摘要】 ? ?目的:介紹Jupyter Notebook在網絡優化領域的應用情況。方法:集成Hadoop、Spark、Jupyter Notebook 等開源工具,搭建網絡優化分析平臺,基于真實案例驗證其在網絡優化領域應用的可行性。結果:通過搭建大數據計算環境,成功實現多數據接入、分布式運算、分布式存儲、交互式應用及結果展示等功能,并基于該平臺完成網絡整體問題分析、問題原因定位分析、問題處理方案分析、問題處理效果分析等大數據分析任務。結論:結合網絡優化的大數據分析需求,搭建便于使用的大數據分析環境,提升基于大數據的網絡優化分析能力。
【關鍵詞】 ? ?大數據 ? ?Jupyter Notebook ? Hadoop ? ?Spark ? ?分布式計算 ? ?網絡優化
引言:
隨著無線通信網絡的快速發展,網絡優化信息化、智能化建設進入了突飛猛進的發展階段,積累了大量的MR(測量報告)、PM(性能數據)、NRM(網絡資源管理)、工參等基礎數據。這些數據資源的價值還未能充分的挖掘,如何從各維度大量數據中發現可用的信息,加速網絡優化信息化、智能化進程是迫在眉睫的任務。通過對網優大數據特性及網優工作協作方式與Jupyter Notebook進行結合性研究,實現有效的且適用于網優的大數據分析,以滿足網絡優化分析需求。
一、 jupyter與網絡優化分析處理的結合
1.1 Jupyter Notebook[1] 技術與網絡優化分析應用結合
Jupyter是一個可交互的記事本,支持了Python[2]、Julia、JavaScript、R等等編程語言達40 多種。它是一個開源的Web 應用程序,在其環境中可以運行代碼和記錄代碼,可以對數據進行清洗,可以通過可視化視圖查看數據結果,可以進行大數據相關的數模轉換、模型構建、機器學習訓練等。
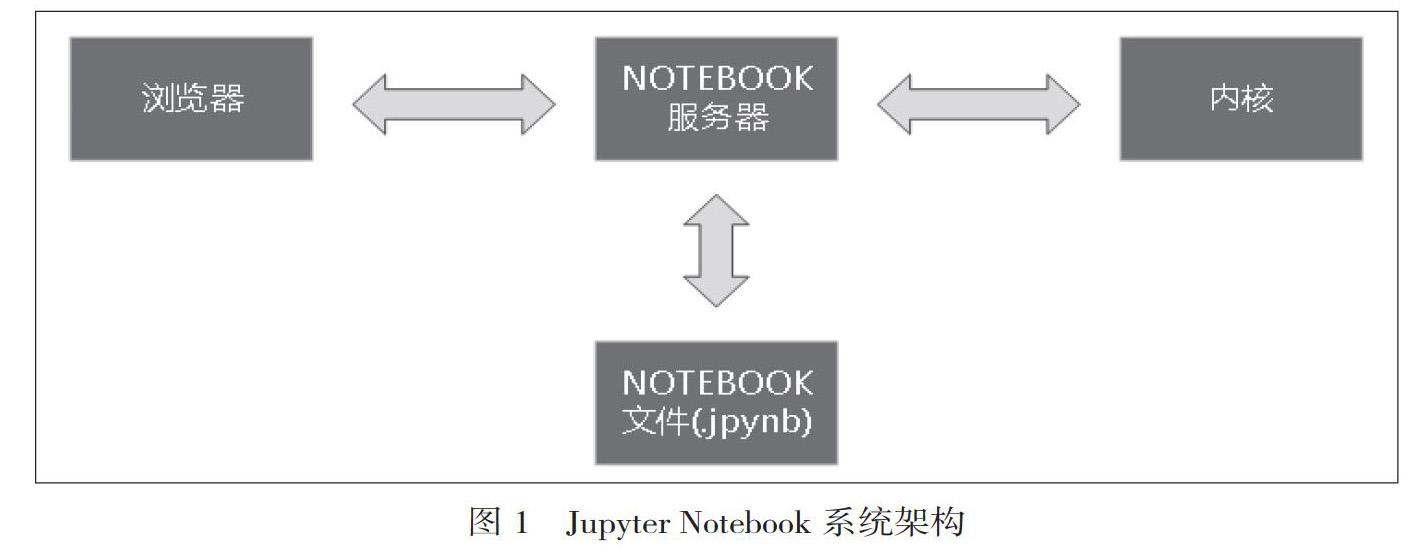
如圖1所視,Jupyter Notebook的系統架構包括人機交互、瀏覽器、服務器、核心、文件等,其中服務器為核心構件。網優分析人員通過瀏覽器連接到服務器,在Web中編寫代碼并將代碼發送到內核,由內核執行,于將結果反饋到Web頁面。個人編寫的代碼保存在服務器中,可共享給其他人員使用。
1.2 JupyterHub[3]技術與網優工作流程結合
JupyterHub支持多個用戶(包括管理人員、網優人員和維護人員等)同時構建自己的工作空間和計算環境,共享或使用其他人的資源,以達到聯機協作的目的。
1.3 HDFS[4]與jupyter結合作大數據存儲
Hadoop分布式文件系統(HDFS)是指被設計成適合運行在通用硬件(commodity hardware)上的分布式文件系統(Distributed File System),用于存儲網絡優化分析所需的各類型各維度數據。
1.4 Spark[5]與jupyther結合作大數據計算
Spark 提供了80多個高級運算符。一方面,Spark提供了支持多種語言的API,使得用戶開發Spark程序十分方便。另一方面,Spark是基于Scala語言開發的,使得Spark應用程序代碼非常簡潔。同時由于spark基于內存,在網優大數據處理領域,性能比hadoop快。
二、基于jupyter的網絡優化分析平臺架構
網絡優化分析平臺的建設面向基于大數據的網絡分析優化需求,以網優問題分析定位為主要目的,結合MR、PM、NRM、CM等數據特點,主要以滿足網絡優化問題定位為主。網絡優化分析平臺的總體架構圖見圖2,包括網優數據的采集解析、基于不同數據類型的分布式存儲、各類型數據不同維度的分布式運算、各類型數據的組合應用層以及用戶界面應用。
2.1 用戶界面
界面提供給網優工作人員進行網優工作信息交互,實現網絡信息的內部組合形式與網優人員可以接受的按照既定業務邏輯形式之間的轉換。
2.2 應用層
應用層為網優人員提供了自行代碼編寫、程序調試及結果展示的功能,利用JupyterHub實現多個網優人員的Notebook管理,同時也提供了HIVE、PIG等傳統的大數據統計分析工具供網優人員選擇。
2.3 分布式運算
基于Spark框架,利用Spark Streaming、Spark SQL、GraphX、MLlib等核心組件,實現網絡優化各類型各維度數據統計。
2.4 分布式存儲
網絡優化分析大數據平臺采用HDFS作為分布式存儲的文件系統,HDFS有著高容錯性(fault-tolerant)的特點,而且它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。從而支持網優人員在HBase[6]或HDFS上對數據進行查詢、編輯等操作。
三、應用案例
3.1 4G MR競對深度分析
本案例對超過300億條MR測量記錄進行按天各運營商覆蓋優劣分析。首先將數據(.xml格式)采集解析清洗并轉換為parquet [7] 格式存儲到HDFS中,然后根據查重條件對數據進行聚合統計,得到按天的各行政區劃各場景的運營商覆蓋率、優于競爭對手的小區數、劣于競爭對手的小區數,得到覆蓋率優于或劣于競爭對手的行政區劃數、場景數,計算任務利用Spark分布式計算框架來完成,通過jupyter連接數據庫,可以對數據進行開發,數據建模,最后利用Python包matpoltlib圖形化展示各運營商各行政區劃、各場景的覆蓋率、優于或劣于競爭對手小區數的對比分析結果,支持快速定位覆蓋率差的行政區或場景,支持快速定位優于或劣于競爭對手的行政區或場景,作為支撐后續基于覆蓋優化的天饋調整、參數調整及網絡規劃工作的依據。
3.2 4G分頻段對比分析
本案例對超過30億條PM數據、超過300億條的MR測量記錄、超過1千萬條NRM數據進行按天分析。首先對數據進行數據采集解析清洗存儲到HDFS中,然后根據NRM匹配出有效的工參數據,再按照工參數據中的頻段屬性進行分頻段聚合統計,得到按天的各頻段按頻段、按行政區劃、按場景、按基站的干擾類、接入類、保持類、容量類、移動類、負荷類、語音類、覆蓋類指標數據,計算任務利用Spark分布式計算框架來完成,通過jupyter連接數據庫,可以對數據進行開發,數據建模,最后利用Python包matpoltlib圖形化展示4G分頻段的各類指標,支持按指標類的不同行政區域對比、不同場景對比,支持按行政區劃、按場景的不同類指標對比,支持按行政區域、按場景的某一類內多個指標對比,作為支撐后續指標差原因分析、指標優化分析、參數調整、負荷均衡、硬件擴減容、LICENSE調整、頻段調整、PCI調整、鄰區調整的依據。
四、結束語
基于Jupyter Notebook的網絡優化大數據分析應用,構建易于使用的網絡優化分析大數據平臺,能夠快速高效為網優人員提供大數據分析計算環境,解決日常網絡優化的大量數據分析處理問題。同時由于網絡優化分析平臺的信息安全級別要求較高,使得基于開源產品建設的平臺維護難度較大,需要進行有效的完全管理后才能作進一步的推廣。
參 ?考 ?文 ?獻
[1] Jupyter.The Jupyter notebook 5.4.0 documentation[EB/OL].https://jupyter-notebook.readthedocs.io/en/5.4.0/.
[2] Python. 3.9.1 documentation[EB/OL].https://docs.python.org/3/.
[3] Jupyter.JupyterHub-JupyterHub documentation [EB/OL]. https://jupyterhub.readthedocs.io/en/stable/.
[4] Hadoop A.Hadoop-Apache hadoop 3.2.2[EB/OL]. http://hadoop.apache.org/docs/r3.2.2/.
[5] S p a r k . O v e r v i e w -Documentation[EB/OL]. http://spark.apache.org/docs/latest/.
[6] Apache.Apache HBase-Apache HBase? Home [EB/OL]. https://hbase.apache.org/.
[7] Parquet.Apache parquet[EB/OL].http://parquet.apache.org/documentation/latest/.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
