基于多重注意力的金融事件大數(shù)據(jù)精準畫像
2021-07-22 17:02:30陳劍南杜軍平寇菲菲
計算機與生活 2021年7期
陳劍南,杜軍平,薛 哲,寇菲菲
北京郵電大學(xué) 智能通信軟件與多媒體北京市重點實驗室,計算機學(xué)院,北京 100876
隨著經(jīng)濟生活的不斷發(fā)展,金融事件數(shù)據(jù)開始大量累積,金融事件時刻影響著人們的生活與發(fā)展。如何從這些海量的金融事件數(shù)據(jù)中找到蘊含的潛在規(guī)律,并對金融事件大數(shù)據(jù)信息進行科學(xué)分析是一個重要的問題。金融事件大數(shù)據(jù)的精準畫像是解決該問題的有效手段。金融領(lǐng)域交叉現(xiàn)象突出,金融領(lǐng)域與計算機領(lǐng)域的交叉,使得可以利用大數(shù)據(jù)處理的技術(shù)來解決金融領(lǐng)域所出現(xiàn)的大數(shù)據(jù)難題。隨著知識圖譜技術(shù)的興起,大數(shù)據(jù)畫像技術(shù)有了較大發(fā)展。利用知識圖譜的技術(shù)可以對大數(shù)據(jù)信息進行數(shù)據(jù)挖掘,同時利用知識圖譜技術(shù)構(gòu)建金融事件的精準畫像,從而將金融事件文本數(shù)據(jù)轉(zhuǎn)換為圖結(jié)構(gòu)數(shù)據(jù),這樣可以通過精準畫像來從海量金融數(shù)據(jù)中獲取重要的信息,掌握金融事件的發(fā)展規(guī)律,為之后處理金融相關(guān)的業(yè)務(wù)提供重要的信息支持。作為知識圖譜構(gòu)建的關(guān)鍵技術(shù),實體的關(guān)系提取一直是自然語言處理中的重點。在金融事件大數(shù)據(jù)中,存在著實體關(guān)系種類復(fù)雜繁多、中文金融事件大數(shù)據(jù)特征松散等問題。針對以上問題,本文進行了深入的研究與實驗。
基于中文金融事件大數(shù)據(jù)的特點以及知識圖譜構(gòu)建中的關(guān)鍵技術(shù),本文提出基于多重注意力的金融事件大數(shù)據(jù)實體關(guān)系抽取算法(financial event big data entity relationship extraction algorithm based on multiple attention mechanism,REMA)來進行金融事件大數(shù)據(jù)實體關(guān)系的抽取,并利用所提取的實體關(guān)系屬性來構(gòu)建金融事件大數(shù)據(jù)的知識圖譜,從而完成金融事件大數(shù)據(jù)的精準畫像。
本文的主要貢獻如下:
(1)充分利用了實體關(guān)系抽取任務(wù)的特點,加入了文本與實體對之間的位置特征信息,使得特征提取更加充分,提升關(guān)系抽取的準確率。
(2)利用字級別的注意力機制與句子級別的注意力機制相結(jié)合,通過多重注意力機制來提升實體關(guān)系抽取的準確率。
(3)利用實體關(guān)系的抽取來對金融事件大數(shù)據(jù)進行精準畫像。
1 相關(guān)工作
對于實體關(guān)系抽取的研究,國內(nèi)外學(xué)者做了大量的工作。實體關(guān)系抽取通常作為分類任務(wù)來進行處理,同時實體關(guān)系抽取一般被分為有監(jiān)督、半監(jiān)督、弱監(jiān)督和無監(jiān)督四種類型[1-4]。文獻[5]利用Bootstrapping 方法對實體關(guān)系進行相應(yīng)的抽取。文獻[6]提出使用弱監(jiān)督的方法進行實體關(guān)系的提取,這樣在非結(jié)構(gòu)化數(shù)據(jù)集上取得了較好的效果。文獻[7]利用了基于矩陣分解的無監(jiān)督算法來進行實體關(guān)系抽取,突破了數(shù)據(jù)格式的束縛。但傳統(tǒng)方法對于數(shù)據(jù)集的依賴比較大,導(dǎo)致誤差并不穩(wěn)定。隨著深度學(xué)習的迅速發(fā)展,實體關(guān)系的抽取方法得到極大的改進。文獻[8]首次引入了卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)利用分類的思想進行實體關(guān)系的抽取,借用了卷積網(wǎng)絡(luò)的優(yōu)點充分抽取文本數(shù)據(jù)的特征。文獻[9]結(jié)合實體關(guān)系抽取任務(wù)的特點將句子按照實體對進行分割并進行池化操作,從而能夠提取更多上下文特征。文獻[10]則利用殘差網(wǎng)絡(luò)進行文本信息深度特征提取,從而提升關(guān)系抽取的效果。文獻[11]則引入注意力機制,并利用雙向長短時記憶網(wǎng)絡(luò)進行聯(lián)合訓(xùn)練,實驗表明這種算法在有監(jiān)督訓(xùn)練下取得不錯效果。文獻[12]利用不同尺度的卷積核對文本數(shù)據(jù)進行特征抽取,從而提升實現(xiàn)實體關(guān)系提取的效果。文獻[13]則利用雙向長短時記憶網(wǎng)絡(luò)提取文本句子的特征依賴關(guān)系。文獻[14]則使用了參數(shù)共享的方法進行深度特征的提取,在相應(yīng)數(shù)據(jù)集上取得不錯的效果。文獻[15]則是將實體關(guān)系抽取問題轉(zhuǎn)換為一個序列標注問題,利用深度神經(jīng)網(wǎng)絡(luò)模型進行三元組抽取。
本文提出的基于多重注意力的金融事件大數(shù)據(jù)實體關(guān)系抽取算法在雙向長短時記憶網(wǎng)絡(luò)的基礎(chǔ)上,充分利用了實體關(guān)系提取任務(wù)的特點,通過文本位置特征來增強文本特征向量的深度提取,同時利用了字級別的注意力機制以及句子級別的注意力機制來構(gòu)建多重注意力機制,從而提取了文本信息的潛在特征。該算法解決了有監(jiān)督中文實體關(guān)系抽取中準確率較低的問題。
2 基于多重注意力的實體關(guān)系抽取算法
本章主要介紹基于多重注意力的實體關(guān)系抽取算法的結(jié)構(gòu)。
2.1 REMA 算法的結(jié)構(gòu)
實體關(guān)系抽取作為自然語言處理的一個重要研究內(nèi)容,是利用相關(guān)的算法從文本數(shù)據(jù)中抽取出實體對之間的潛在關(guān)系。其中實體關(guān)系可以表示為一個三元組
本文提出一種基于多重注意力的金融事件大數(shù)據(jù)中實體關(guān)系抽取的算法。如圖1 所示,模型的結(jié)構(gòu)分為向量表示層(embedding layer)、雙向長短時記憶層(bidirectional long short-term memory layer)與多重注意力機制層(multiple attention layer)。具體而言,向量表示層融合了文本數(shù)據(jù)的向量特征以及文本中字與相應(yīng)的兩個實體名距離的位置特征,該層作為整個系統(tǒng)結(jié)構(gòu)的輸入層。雙向長短時記憶層則是利用雙向長短時記憶網(wǎng)絡(luò)來提取文本上下文信息的特征,這種網(wǎng)絡(luò)結(jié)構(gòu)能夠解決長文本信息中出現(xiàn)的長距離依賴的問題。多重注意力機制層則是利用字節(jié)別注意力機制以及句子級別注意力機制來更好地提取關(guān)鍵文本的權(quán)重特征,這樣能夠充分考慮到文本信息中對于該文本中實體關(guān)系抽取結(jié)果的影響因素。下面將詳細描述每層的具體功能與實現(xiàn)原理。
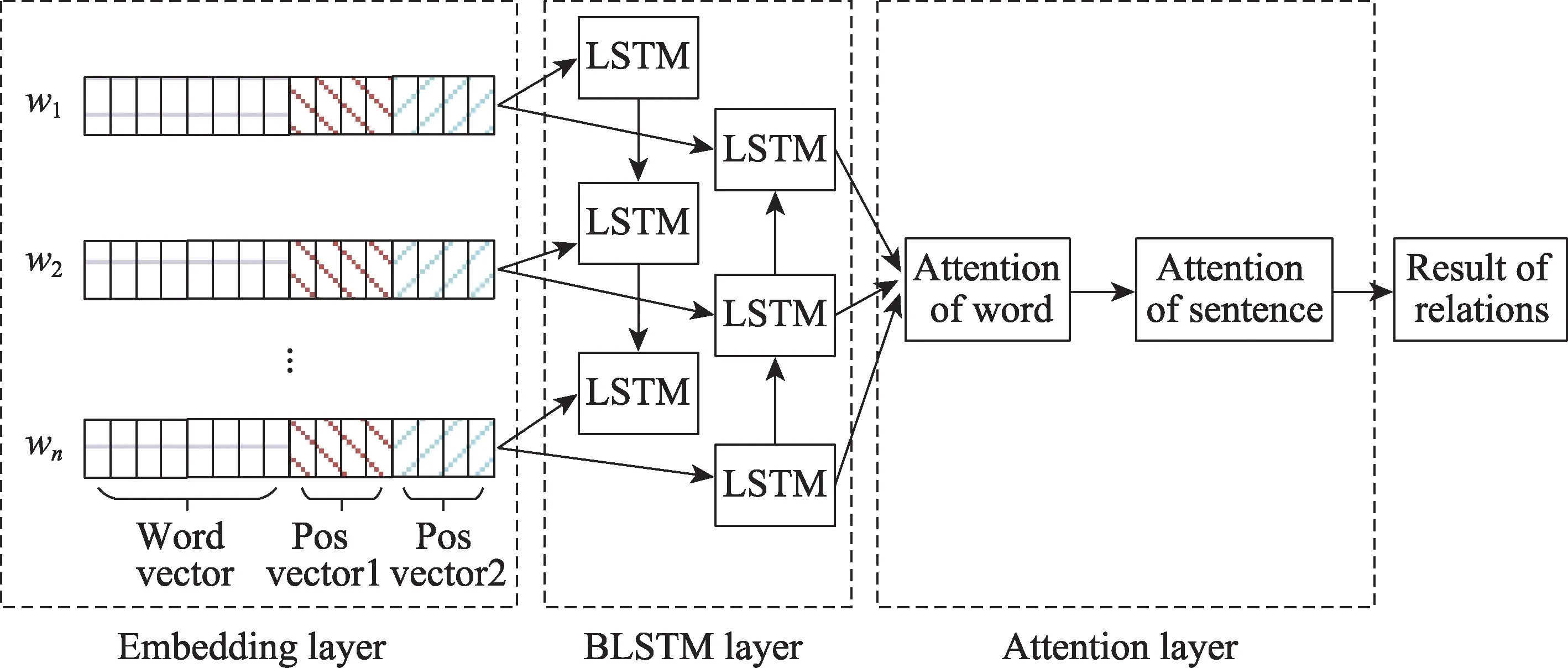
Fig.1 Financial events entity relationship extraction with multiple attention mechanism圖1 基于多重注意力的金融事件實體關(guān)系抽取
2.2 金融事件大數(shù)據(jù)向量表示層
本層網(wǎng)絡(luò)中的向量由兩部分組成,分別是詞嵌入向量與位置信息向量,其向量作為雙向長短時記憶網(wǎng)絡(luò)層的輸入向量。對于詞嵌入向量,其中一個文本句子由多個漢字組成,這樣可以描述為Sen=[w1,w2,…,wn],其中wi表示句子中的第i個漢字,n表示該句子由n個漢字組成。對于每個漢字wi根據(jù)初始化結(jié)果可以得到其相應(yīng)的詞嵌入向量Word=[v1,v2,…,vm],這樣對于金融大數(shù)據(jù)文本中的句子可以得到一個詞嵌入向量矩陣,如式(1)所示。

根據(jù)實體關(guān)系抽取的特點,可以從文本句子中根據(jù)每個漢字與該句子兩個實體名的距離來提取該句子的位置信息。其中wi與wj為該句子中兩個實體名,則對于該句子中第k個漢字wk其位置信息可以表示為式(2)所示。
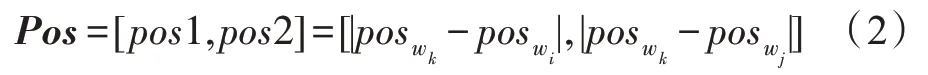
其中,posik表示第k個漢字與第i個漢字在該句子中的位置關(guān)系。對于一個句子中n個漢字,通過結(jié)合式(2)融合位置特征,則得到如式(3)所示的特征向量。
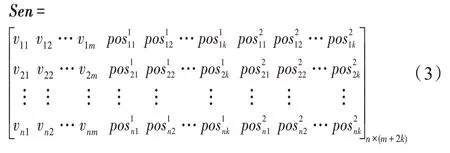
其中,m為句子中漢字的詞嵌入向量特征的長度,k為句子中漢字的位置詞嵌入向量的特征長度。通過以上方法可以得到相應(yīng)的雙向長短時記憶網(wǎng)絡(luò)層的輸入向量。
2.3 金融事件大數(shù)據(jù)雙向長短時記憶網(wǎng)絡(luò)層
金融事件大數(shù)據(jù)雙向長短時記憶網(wǎng)絡(luò)是通過雙向長短時記憶網(wǎng)絡(luò)來處理金融事件大數(shù)據(jù)文本中出現(xiàn)長時間依賴的問題。其中長短時記憶網(wǎng)絡(luò)(long short-term memory,LSTM)對于該問題有很好的處理效果,其基本結(jié)構(gòu)如圖2 所示。長短時記憶網(wǎng)絡(luò)模型在隱藏層引入了相應(yīng)的記憶單元,這樣有效解決了數(shù)據(jù)在長時間范圍內(nèi)的相互依賴。在長短時記憶網(wǎng)絡(luò)基礎(chǔ)上,本文引入雙向長短時記憶網(wǎng)絡(luò)的技術(shù),這也是本文所提出的REMA 方法的重要組成部分,通過前向時序以及后向時序的長短時記憶網(wǎng)絡(luò)提取金融事件大數(shù)據(jù)的上下文特征信息。

Fig.2 Structure of long short-term memory network model圖2 長短時記憶網(wǎng)絡(luò)模型結(jié)構(gòu)圖
如圖2 所示,ht-1為上一個長短時記憶網(wǎng)絡(luò)單元的隱藏層的輸出結(jié)果;Ct-1則是上次一個長短時記憶網(wǎng)絡(luò)單元的狀態(tài)結(jié)果;xt則是本文的字向量輸入結(jié)果;ft為遺忘門的輸出結(jié)果,其中σ為sigmoid激活函數(shù);it與則為輸入門的輸出結(jié)果,其中tanh 為激活函數(shù);ot為輸出門的輸出結(jié)果;Ct為當前單元的狀態(tài)值;ht為當前單元的隱藏層的輸出。整個長短時記憶網(wǎng)絡(luò)輸出結(jié)果如式(4)所示。


2.4 金融事件大數(shù)據(jù)多重注意力機制層
注意力機制是一種對于不同區(qū)域數(shù)據(jù)進行權(quán)重分配的機制,其特點是通過選擇性地對某些信息進行關(guān)注,從而更好地進行信息特征的提取。本文利用注意力機制的主要作用是計算不同漢字以及不同句子對于實體關(guān)系分類結(jié)果的權(quán)重值來提升金融大數(shù)據(jù)實體關(guān)系的抽取效果。對于本文所使用的多重注意力機制算法是將字級別的注意力機制與句子級別的注意力機制進行融合,這兩種注意力機制均是基于“QKV”模型進行優(yōu)化,該模型如圖3 所示。

Fig.3 Attention mechanism structure diagram圖3 注意力機制結(jié)構(gòu)圖
對于該模型其中Query 矩陣是一個由均勻分布進行隨機采樣的向量矩陣queryk×1,其中k為雙向長短時記憶網(wǎng)絡(luò)隱藏層的輸出向量維度,而Key 矩陣是一個由句子中的中文分詞的詞向量所生成的特征矩陣,Value 矩陣則是一個由雙向長短時記憶網(wǎng)絡(luò)隱藏層輸出向量組成的矩陣,由此可以得到實體關(guān)系抽取中的字級別注意力輸出向量,如式(6)、式(7)所示。

其中,softmax 函數(shù)是用來進行向量歸一化的操作;key_wordn×k為字級別注意力機制的Key 向量矩陣;query_wordk×1為字級別注意力機制中Query 向量矩陣;att_w_wordn×1為句子級別注意力機制的權(quán)重值,針對雙向長短時記憶網(wǎng)絡(luò)隱藏層輸出的n維向量的權(quán)重分布;value_wordn×k為雙向長短時記憶網(wǎng)絡(luò)隱藏層的輸出向量矩陣;att_r_wordk×1則是字級別注意力機制的輸出向量矩陣。
通過字級別注意力層處理后已經(jīng)獲取了句子中不同漢字對于關(guān)系抽取分類結(jié)果的權(quán)重值,接著利用實體關(guān)系抽取的特點——同一個實體對以及實體關(guān)系分類結(jié)果可能存在于多個句子中。根據(jù)這個特點可以對該實體對以及標簽在多個句子中進行權(quán)重計算,最終確定每個句子對于最終結(jié)果標簽的分類權(quán)重值。同一個實體對以及相應(yīng)的關(guān)系標簽存在于m個句子中,句子級別的特征輸入向量為valuem×k,即Value 矩陣特征向量。句子級別的注意力機制中的Key 矩陣向量是利用valuem×k進行線性變化得到的,這樣直接繼承字級別的輸出向量的特征,同時根據(jù)式(6)、式(7),可以得到句子級別的注意力機制的輸出特征,如式(8)、式(9)所示。

其中,sen_ak是用作線性變化的向量矩陣;value_senm×k為字級別注意力機制輸出的向量矩陣,同時為句子級別注意力機制的輸入向量矩陣;query_senk×1為句子級別注意力機制中的Query矩陣;att_w_senm×1為句子級別注意力機制中的句子權(quán)重分類的權(quán)值;att_r_senk×1為句子級別注意力機制的輸出向量矩陣。
通過多重注意力機制層輸出的特征向量經(jīng)過softmax 網(wǎng)絡(luò)即得到實體關(guān)系分類結(jié)果特征。
3 實驗與結(jié)果
本章詳細描述REMA 實驗結(jié)果以及結(jié)果分析情況。
3.1 實驗評價指標
本實驗使用準確率(precision)、召回率(recall)以及F1 值(F1-score)作為金融大數(shù)據(jù)實體關(guān)系抽取的對比實驗的評價指標。其中評價指標的判別情況如表1 所示。

Table 1 Evaluation index discrimination table表1 評價指標判別表
表1 中,TP 表示實際為真,同時預(yù)測為真的個數(shù);FP 表示實際為假,但是預(yù)測為真的個數(shù)(即為誤差率);FN 表示實際為真,但預(yù)測為假的個數(shù)(即為漏報率);TN 表示實際為假,但是預(yù)測為假的個數(shù)。模型的準確率、召回率和F1 值的計算公式如式(10)、式(11)、式(12)所示。

3.2 實驗評價指標REMA 實驗數(shù)據(jù)集
本文從“新浪新聞”“騰訊新聞”“鳳凰新聞”“網(wǎng)易新聞”等互聯(lián)網(wǎng)新聞平臺爬取金融版塊的金融事件新聞文本數(shù)據(jù),并且將新聞文本按事件話題進行分類,分別抽取“中美貿(mào)易戰(zhàn)”“沙特俄羅斯石油爭端”“經(jīng)濟危機”等金融事件,同時將新聞數(shù)據(jù)文本切分為句子形式。使用的數(shù)據(jù)集包括訓(xùn)練集與測試集兩部分,訓(xùn)練集大小比測試集大小為8∶2,其中訓(xùn)練集包括160 000個金融事件的句子,測試集包括40 000個金融事件句子,對金融事件句子進行相應(yīng)的標注,每句子包含兩個實體名以及一個關(guān)系,其中金融事件大數(shù)據(jù)中實體關(guān)系總共分為12 個類別。其數(shù)據(jù)集的詳細分布如表2 所示,金融事件大數(shù)據(jù)實體關(guān)系類別的分布如表3 所示。其中訓(xùn)練集與測試集中標簽占比基本一致,保證數(shù)據(jù)的一致性。
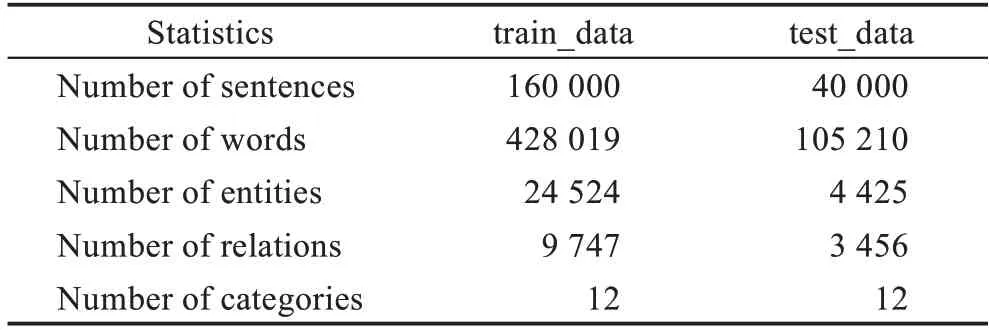
Table 2 Data set corpus structure表2 數(shù)據(jù)集分布情況
3.3 REMA 實驗參數(shù)設(shè)置
對于REMA 網(wǎng)絡(luò)框架,其中原始文本的字嵌入向量的長度設(shè)置為70 維,第一個位置信息嵌入向量為5 維,第二個位置信息嵌入向量為5 維,字級別注意力機制向量權(quán)重維度為128 維,句子級別注意力機制向量權(quán)重維度與句子數(shù)量相等,而對于雙向長短時記憶網(wǎng)絡(luò)隱藏層的輸出維度為128 維。模型訓(xùn)練的batch_size 的大小設(shè)置為64,學(xué)習率設(shè)置為0.001,訓(xùn)練時dropout 設(shè)置為0.5。雙向長短時記憶網(wǎng)絡(luò)中隱藏層輸出的激活函數(shù)使用tanh 函數(shù),優(yōu)化器選用Adam。

Table 3 Entity relationship classification表3 實體關(guān)系分類情況
3.4 REMA 實驗和結(jié)果
本節(jié)使用準確率、召回率以及F1 值等指標對金融事件數(shù)據(jù)集進行實體關(guān)系抽取的效果的評價,詳細對不同方法進行實體關(guān)系抽取進行對比。本文分別使用CNN、CNN+ATT、BLSTM、BLSTM+ATT 這四種方式進行對比實驗,實驗結(jié)果如表4 所示。

Table 4 Comparative experimental results of REMA on financial event dataset表4 REMA 在金融事件數(shù)據(jù)集上的對比實驗結(jié)果
從表4 可以明顯看出,本文所提出的REMA 方法在實體關(guān)系抽取中的性能要優(yōu)于其他的對比實驗中的方法。CNN 是一種利用卷積神經(jīng)網(wǎng)絡(luò)進行關(guān)系分類的算法,利用字嵌入矩陣獲取句子的特征向量,然后作為輸入投入到卷積神經(jīng)網(wǎng)絡(luò)進行有監(jiān)督的分類訓(xùn)練。CNN+ATT 是在利用卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)上加入注意力機制進行句子文本特征的提取,因此其效果要好于普通的CNN 算法。BLSTM 對于類似于文本序列這種動態(tài)的序列問題的處理有著較好的效果,BLSTM 可以從序列的前向與后向獲取特征信息,這樣能夠較好地獲取到文本上下文特征。在BLSTM的基礎(chǔ)上引入注意力機制,則是增強文本語義提取的效果,提升了模型的整體性能。本文所提出的REMA 算法則是在文本信息中增加了位置信息,同時除了字級別的注意力機制外,還結(jié)合了句子級別的注意力機制,故模型整體效果更好,其準確率提升了5.6 個百分點,召回率提升了4.6 個百分點,F(xiàn)1 值提升了5 個百分點。
3.5 REMA參數(shù)對于模型性能影響實驗與結(jié)果
REMA 方法的主要訓(xùn)練參數(shù)的一個批次投入訓(xùn)練的句子數(shù)量即batch_size的取值以及雙向長短時記憶網(wǎng)絡(luò)隱藏層的輸出維度大小即blstm_size 的取值。本文在金融事件數(shù)據(jù)集下分別進行這兩個參數(shù)的對比實驗,并根據(jù)準確率(precision)、召回率(recall)以及F1-score 這三個指標進行比較,實驗結(jié)果分別如圖4 與圖5 所示。其中batch_size 的取值分別是32、64、96、128、160,而blstm_size 分別為16、32、64、128、256、512。

Fig.4 Effect of model parameter batch_size on REMA圖4 REMA 模型參數(shù)batch_size對于模型性能的影響情況
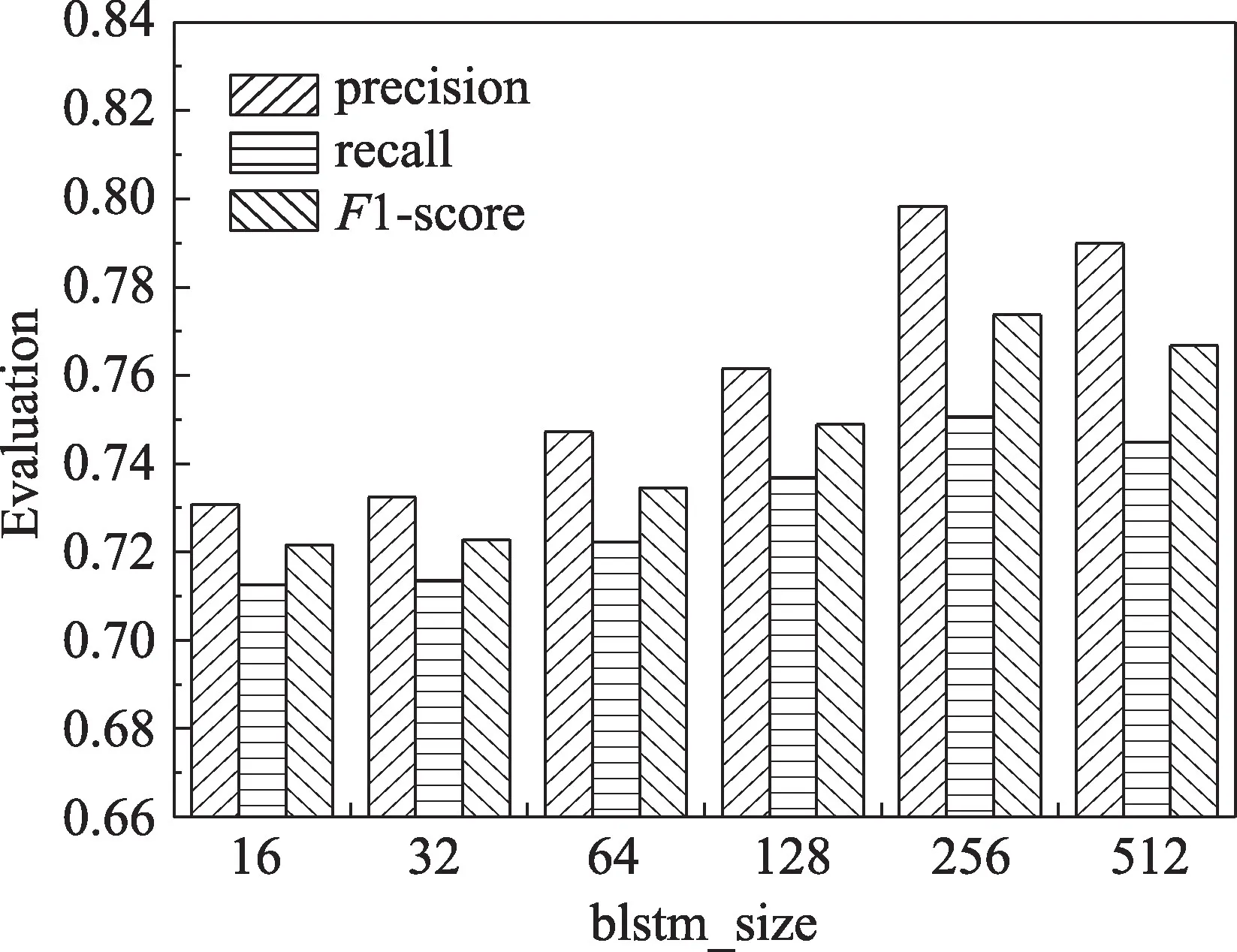
Fig.5 Effect of model parameter blstm_size on REMA圖5 REMA 模型參數(shù)blstm_size對于模型性能的影響情況

Fig.6 Big data portrait results of Sino-US trade war financial events圖6 中美貿(mào)易戰(zhàn)金融事件大數(shù)據(jù)畫像結(jié)果
圖4 中,從準確率、召回率以及F1 值這三個指標來看,batch_size 對于整個模型在實體關(guān)系抽取的效果的影響并不明顯,從batch_size 為32 到batch_size為160 這個過程中的F1 值提升不到1 個百分點。
如圖5 從F1 值可以發(fā)現(xiàn),雙向長短時記憶網(wǎng)絡(luò)隱藏層的維度為256 時效果最好。同時,從雙向長短時記憶網(wǎng)絡(luò)隱藏層的維度為16 到雙向長短時記憶網(wǎng)絡(luò)隱藏層的維度為512 的測試過程可以看出,一開始雙向長短時記憶網(wǎng)絡(luò)隱藏層的維度增加時,模型的整體效果也隨之提升,但當雙向長短時記憶網(wǎng)絡(luò)隱藏層的維度為256 時效果達到峰值,隨著雙向長短時記憶網(wǎng)絡(luò)隱藏層的維度繼續(xù)增長,模型的效果會有所下降。
3.6 金融事件大數(shù)據(jù)畫像實驗和結(jié)果
利用基于多重注意力的實體關(guān)系抽取算法來獲取金融事件大數(shù)據(jù)的實體關(guān)系,并利用Neo4j 圖數(shù)據(jù)庫進行金融事件大數(shù)據(jù)的知識圖譜的構(gòu)建,從而進行金融事件大數(shù)據(jù)的精準畫像,本節(jié)選取了數(shù)據(jù)集中有關(guān)“中美貿(mào)易戰(zhàn)事件”的金融數(shù)據(jù)集,根據(jù)本文所提出的算法提取實體對之間的關(guān)系,并最后利用Neo4j 圖數(shù)據(jù)庫模型進行知識圖譜的構(gòu)建并完成畫像。圖6 是“中美貿(mào)易戰(zhàn)”金融事件大數(shù)據(jù)精準畫像的結(jié)果。
4 總結(jié)
本文提出了基于多重注意力的金融事件大數(shù)據(jù)實體關(guān)系抽取算法(REMA)。在雙向長短時記憶網(wǎng)絡(luò)的基礎(chǔ)上,利用實體關(guān)系抽取任務(wù)的特點同時結(jié)合多重注意力機制思想,引入字級別的注意力機制以及句子級別的注意力機制,其中前者利用了中文文本中不同漢字對于實體關(guān)系抽取的結(jié)果的權(quán)重值,后者則是利用了不同句子對于實體關(guān)系抽取結(jié)果的權(quán)重值。REMA 算法模型分為特征表示層、雙向長短時記憶網(wǎng)絡(luò)層、多重注意力機制層。通過REMA 算法可以對金融事件大數(shù)據(jù)文本中的實體關(guān)系信息進行有效提取,實驗表明REMA 算法在金融事件數(shù)據(jù)集中進行實體關(guān)系抽取有著更高的準確率、召回率以及F1 值。利用提取的金融事件實體關(guān)系結(jié)果結(jié)合知識圖譜技術(shù)可以對金融事件大數(shù)據(jù)進行精準畫像,從而直觀詳細地了解事件發(fā)展的態(tài)勢以及相關(guān)的事件屬性關(guān)系,并為人們進行金融決策提供良好的數(shù)據(jù)支撐。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
金橋(2018年12期)2019-01-29 02:47:36
知識經(jīng)濟·中國直銷(2018年12期)2018-12-29 12:22:40
電子制作(2018年18期)2018-11-14 01:48:06
中國工程咨詢(2016年10期)2016-01-31 03:12:10
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
金融法苑(2014年2期)2014-10-17 02:53:24
語文知識(2014年1期)2014-02-28 21:59:13
