基于深度信念網絡的鐵譜圖像智能識別方法與試驗驗證*
2021-07-23 01:34:16樊紅衛胡德順高爍琪張旭輝曹現剛
潤滑與密封 2021年7期
關鍵詞:模型
樊紅衛 胡德順 高爍琪 張旭輝 曹現剛
(1.西安科技大學機械工程學院 陜西西安 710054; 2.陜西省礦山機電裝備智能監測重點實驗室 陜西西安 710054)
機械設備中的傳動齒輪在長期運行過程中,受到潤滑油、負載變化等因素的影響,經常會出現磨損現象。磨損原因主要有主、從動輪表面粗糙度和硬度不匹配[1];潤滑油黏度過低[2];負載加重和循環次數增加[3]。據統計,齒輪傳動失效引起的機械故障在總故障中占比約80%,其中磨損約占40%。一旦發生磨損故障,不僅會加劇系統的振動噪聲,還會降低傳動精度和效率,甚至引發斷齒等嚴重的機械事故[4]。
機械磨損檢測技術已有很長的發展歷史,主要有放射性檢測、磨粒分析、振動檢測、光學檢測、電學檢測、磁學檢測、聲學檢測、壓痕方法等[5],這些技術在各自領域取得了良好效果。如,張雪英等[6]通過振動信號的小波閾值降噪與遺傳算法優化的支持向量機實現了齒輪磨損識別;SHI等[7]提出了一種改進的磨粒電感檢測法,彌補了普通電感法檢測非鐵磁性金屬顆粒能力不足的問題。
磨粒分析中的鐵譜分析應用廣泛,是機械磨損檢測的重要手段。PENG等[8]提出了一種高斯背景混合模型和斑點檢測算法,對潤滑油中磨損顆粒進行檢測,提取了磨粒形狀和尺寸特征,實現了磨粒在線監測。WU等[9]提出了一種恢復方法來減少在線鐵譜圖像中散焦模糊問題,用卷積神經網絡構造退化模型,實驗驗證了所提出的恢復策略能有效提取磨粒特征,具有更高計算效率。WANG等[10]提出了一種用于識別典型磨損碎片的集成化方法,利用反向傳播神經網絡作為第一級分類,利用卷積神經網絡作為第二級分類,實驗證明了其識別率明顯提高。SUN[11]總結了柴油機中常見磨粒特征,將故障機制與磨粒特征結合,建立了磨損評價體系,利用鐵譜分析對柴油機進行監測,取得了良好效果。張珊珊等[12]將鐵譜與激光粒度分析技術綜合應用于磨粒識別,既能判斷磨損類型,又能判斷磨損程度。CAO等[13]提出了一種數據重構與特征提取方法,對監測數據進行重構后表征了數據變化趨勢,提取了磨損狀態特征并進行了磨損預測,實驗結果表明改進的模型能提供更早的異常警報,預測性能良好。LI等[14]針對基于傳統梯度算法的前饋神經網絡易陷入局部極小值問題,提出了基于極限學習機的鐵譜磨粒圖像識別方法,獲得了較好分類效果。閆建陽等[15]提出了一種磨粒圖像多特征融合識別方法,提取了鐵譜圖像磨粒紋理、顏色和幾何特征,歸一化后運用SVM與D-S證據理論實現了鐵譜圖像識別,準確度高。WANG等[16]提出了基于卷積神經網絡的鐵譜圖像識別方法,對鐵譜圖像進行端到端分類,可用ms級的速度處理圖像,實現在線監測。安超等人[17]提出了基于Mask R-CNN的鐵譜磨粒智能識別方法,克服了傳統方法在復雜圖像背景下對相似磨粒識別難題。
上述研究對磨粒鐵譜圖像的智能識別提供了不同思路,但尚未見將深度信念網絡用于磨損狀態識別。本文作者提出一種基于深度信念網絡的鐵譜圖像智能識別方法,利用鐵譜技術制備磨粒圖像集來訓練網絡模型,研究模型中各參數變化對其性能的影響以確定最佳模型,從而實現機械磨損故障類型智能識別。
1 鐵譜圖像智能識別算法的基本原理
1.1 受限玻爾茲曼機
1986年,HINTON和SEJNOWSKI[18]提出了一種基于能量的隨機神經網絡即玻爾茲曼機,該模型是一種無監督訓練模型,具有強大的特征提取能力,能夠提取輸入數據中深層次、復雜的高級特征。但是,模型可見層與隱含層內神經元全連接,訓練時間較長。因此,SMOLENSKY[19]改進提出了一種限制的玻爾茲曼機,即受限玻爾茲曼機(Restricted Boltzmann Machine,RBM)。RBM同樣具有可見層和隱含層,每層包含若干個神經元,不同于玻爾茲曼機的是RBM層內無連接,結構如圖1所示。

圖1 受限玻爾茲曼機模型
當RBM模型中權重w、可見層偏置b和隱含層偏置c給定,且可見層v和隱含層h的狀態給定時,模型的能量為
(1)
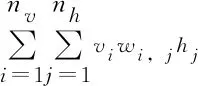
基于模型能量函數,可得RBM模型的概率分布:
(2)
進一步可得到隱含層和可見層神經元被激活的概率為
(3)
(4)
式中:Sigmoid(x)是激活函數,表達式為
(5)
RBM模型的訓練目標是不斷學習模型中各參數,使RBM所表示的邊緣概率分布P(v)盡可能接近訓練數據所表示的分布,即最大化似然函數:
(6)
式中:θ為訓練目標參數,包含w、b、c;v(i)為第i個樣本數據;m為訓練樣本數量。

(7)
對式(7)進行偏導數計算得到:
(8)
(9)
(10)
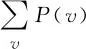
CD算法利用訓練樣本初始化可見層狀態,利用式(3)計算隱含層神經元激活概率,從而確定隱含層神經元狀態,然后利用式(4)計算可見層神經元激活概率,從而確定可見層神經元狀態,完成CD-1算法,將該過程循環k次即實現可見層神經元的k次重構,即完成CD-k算法。
1.2 深度信念網絡
深度信念網絡(Deep Belief Network,DBN)是HINTON等于2006年提出的基于RBM的學習模型[21]。DBN的實質是將若干個RBM串聯起來構成一個DBN,其中,上一個RBM的隱含層即為下一個RBM的可見層,上一個RBM的輸出即為下一個RBM的輸入,結構如圖2所示。
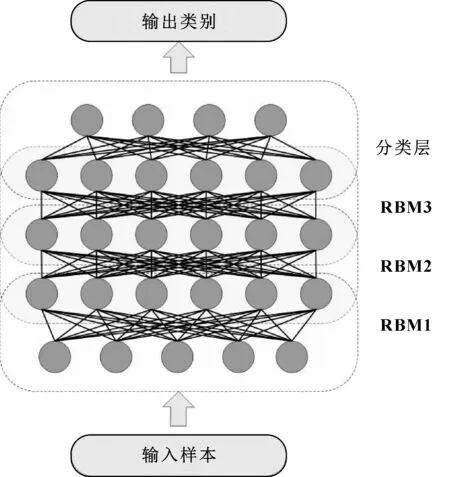
圖2 DBN模型結構
DBN模型的訓練分為2個階段:第一階段是預訓練,先用訓練樣本訓練第一個RBM,并用訓練好的第一個RBM參數初始化DBN第一層參數,然后將第一個RBM的輸出結果作為第二個RBM的訓練樣本來訓練第二個RBM,訓練完后用第二個RBM參數初始化DBN的第二層參數,以此類推,直到最后一層;第二階段是微調,初始化DBN所有層參數后,利用帶標簽的訓練集有監督地訓練DBN,微調DBN各層參數。DBN模型的訓練過程如下:
第一步:初始化DBN模型結構;
第二步:根據設定的DBN模型結構劃分其中RBM模型;
第三步:利用CD-k算法對每個RBM模型進行參數訓練;
第四步:利用訓練完畢的RBM參數初始化DBN模型中每層參數;
第五步:利用帶標簽的數據集有監督地訓練DBN整體模型。
2 磨粒鐵譜圖像智能識別算法的實現
文中通過鐵譜分析技術,結合DBN模型,實現對機械設備潤滑油中磨粒鐵譜圖像的智能識別。從鐵譜圖像制備到最終故障識別的流程如圖3[21]所示。

圖3 鐵譜圖像智能識別流程
基于DBN的鐵譜圖像智能識別主要有以下步驟:
(1)利用鐵譜儀制備鐵譜圖像數據集,并對圖像進行預處理,然后設置訓練集與測試集;
(2)搭建DBN模型框架,根據輸入數據維度和輸出故障類別數確定網絡輸入層和輸出層的神經元個數,初始化其中各參數,包括學習率、激活函數、優化器等,利用鐵譜圖像數據集對模型中關鍵參數進行研究,確定DBN模型的最佳參數設置;
(3)利用鐵譜圖像逐層訓練每一層RBM模型,用訓練完的RBM模型參數初始化同層DBN神經元的權重與偏置,將上一層RBM輸出作為下一層RBM輸入,逐層無監督訓練每一層RBM模型;
(4)預訓練完畢后,利用帶標簽的鐵譜圖像數據集有監督地微調整個DBN模型,優化各神經元的權重和偏置;
(5)微調結束后,DBN模型即可用于鐵譜圖像的智能識別,實現磨損故障診斷。
由以上鐵譜圖像識別過程可知,DBN將無監督預訓練和有監督微調有機結合,實現了鐵譜圖像數據深層特征的自動提取和故障類別自動識別,較傳統故障識別方法極大地提高了故障診斷的準確率和效率。
3 齒輪箱磨粒鐵譜圖像智能識別試驗
3.1 鐵譜圖像制備
為了制備鐵譜圖像,搭建了齒輪傳動系統,如圖4[22-23]所示,對該系統中齒輪傳動部件運行一段時間后的油液進行收集,用于制備鐵譜圖像。

圖4 齒輪傳動系統
該齒輪傳動系統由變頻電機驅動,磁粉制動器模擬負載,包含二級行星輪系和二級直齒輪減速器,利用600XP150齒輪油進行潤滑。潤滑油收集完畢后,利用YTF-8分析式鐵譜儀對油液進行譜圖制備[22-23],鐵譜儀平臺如圖5[22-23]所示,是一種典型的分析式鐵譜儀,由制譜系統和顯微成像系統兩部分組成,所得鐵譜圖像存于上位機中。

圖5 鐵譜分析平臺
根據機械設備磨損的磨粒特征,可將磨粒分為正常磨粒、切削磨粒、嚴重滑動磨粒、滾動磨粒等,相應的鐵譜圖像及其特征總結如表1所示。

表1 磨粒鐵譜圖像與特征
由于鐵譜圖像制備過程復雜耗時,譜圖質量較難控制,故譜圖數量通常有限,不足以用來訓練深度學習模型,因此需要對圖像數據進行擴充。通過數據增強方法可以快速擴充樣本,包括平移、旋轉、對比度增強、翻轉等方法。文中通過混合使用以上4種方法對原始鐵譜圖像數據集進行擴充,原始小樣本以指數速率擴充成大樣本,在樣本數量上滿足了深度信念網絡模型訓練要求。此外,對采集到的鐵譜圖像進行了背景色處理,極大提高了前景和背景的辨識度。
3.2 鐵譜圖像智能識別研究
采用Python語言,基于TensorFlow框架搭建了DBN模型,其輸入層神經元個數為3 600,第一層隱含層神經元個數為2 000,第二層隱含層神經元個數為1 000,第三層隱含層神經元個數為100,輸出層神經元個數為4,損失函數采用交叉熵,優化器選擇Adam,然后利用鐵譜圖像數據集(包含訓練集40 000張,測試集8 000張,訓練集每個類別10 000張,測試集每個類別2 000張)對模型重要參數進行研究,包括激活函數、Dropout值、學習率和批訓練數,從而完成對齒輪工作狀態(包含正常狀態、切削磨損、嚴重滑動磨損、滾動磨損)的智能診斷。
3.2.1 激活函數與Dropout值
設DBN模型中激活函數分別為Sigmoid和Relu,研究其在不同Dropout值下的表現。圖6示出了激活函數為Sigmoid,而Dropout值分別為0.2、0.4、0.6時訓練結果。
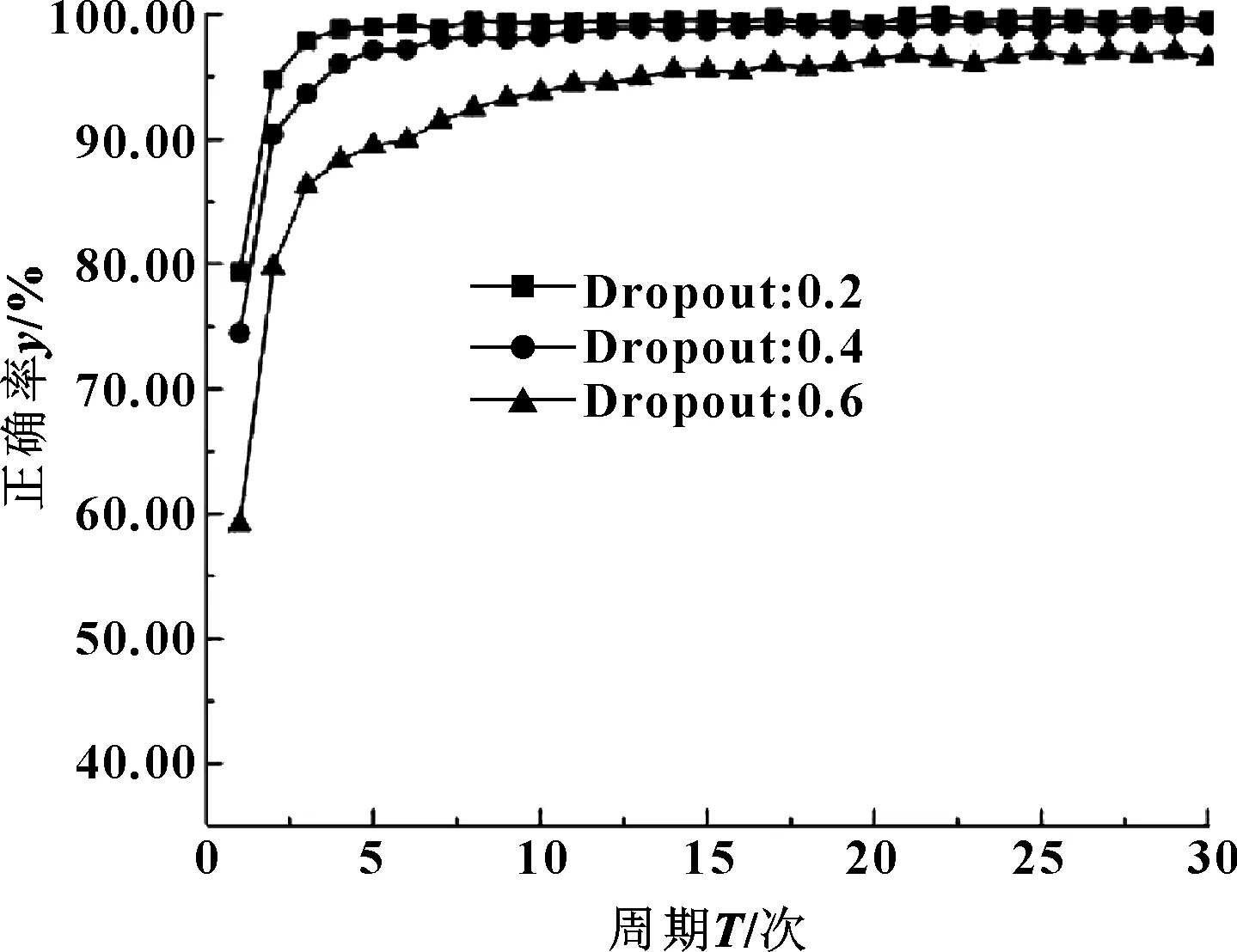
圖6 Sigmoid下不同Dropout值對比曲線
圖7示出了激活函數為Relu,而Dropout值分別為0.2、0.4、0.6時訓練結果。
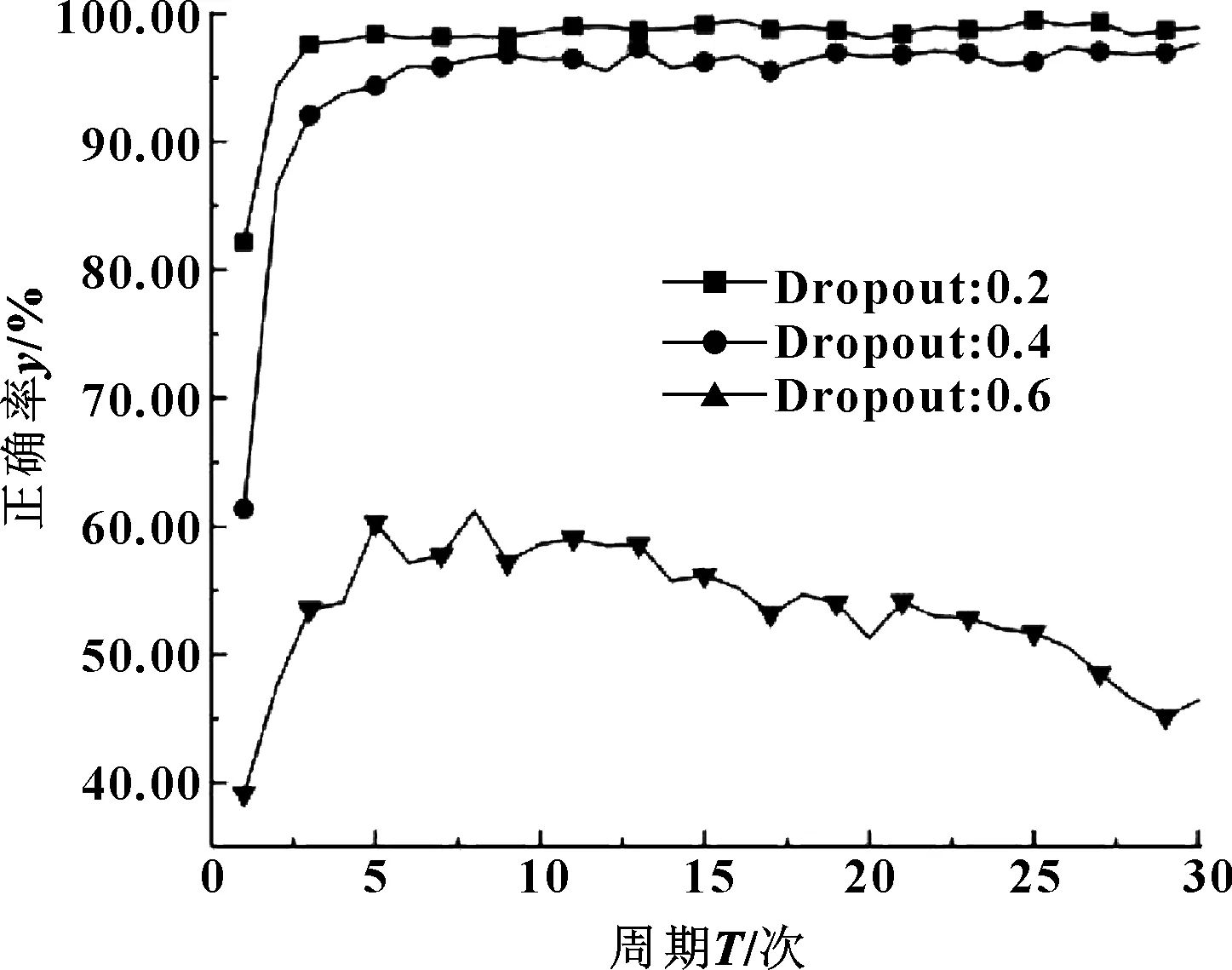
圖7 Relu下不同Dropout值對比曲線
表2和表3給出了以上2種情況下模型訓練的各項參數設置及量化結果。

表2 Sigmoid下不同Dropout值的結果對比

表3 Relu下不同Dropout值的結果對比
觀察圖6和圖7,結合表2和表3中數據,發現同一激活函數下Dropout值越大,DBN識別正確率越低,其中激活函數為Sigmoid,Dropout值為0.2和0.4時,正確率逼近100%,可能發生了過擬合,Dropout值為0.6時正確率和耗時較理想;激活函數為Relu,Dropout值為0.6時識別正確率過低,為0.2時耗時較大,為0.4時正確率和耗時較理想。將兩者橫向比較發現,激活函數為Sigmoid、Dropout值為0.6和激活函數為Relu、Dropout值為0.4的識別正確率和耗時均接近。由于Relu函數可避免梯度消失且簡單快捷,故文中激活函數選取Relu,Dropout值取0.4。
3.2.2 預訓練學習率
設DBN預訓練學習率分別為0.001、0.01、0.1、1.0,研究其對模型性能的影響,圖8所示為訓練結果。
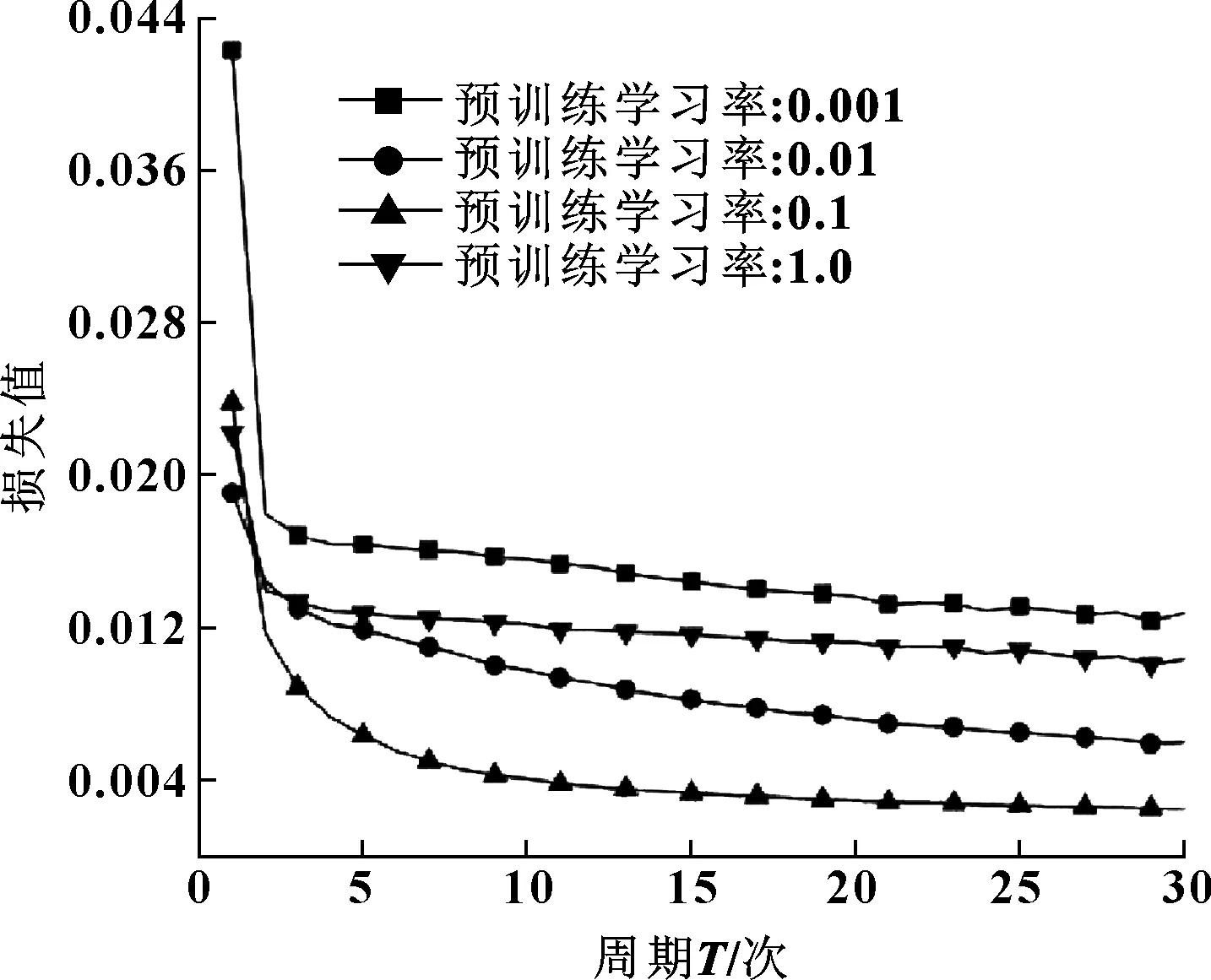
圖8 不同預訓練學習率對比曲線
圖8給出了不同預訓練學習率下損失函數的變化趨勢,表4給出了訓練時各項參數設置及量化結果。
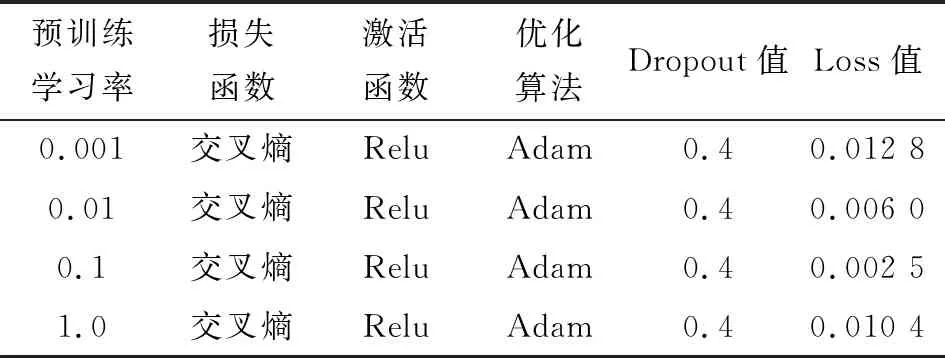
表4 不同預訓練學習率的結果對比
結合圖8和表4,發現4種不同預訓練學習率中,0.1是較合適的值,它在前5個訓練周期內即可達到0.001、0.01、1.0訓練30個周期時的效果,甚至更好,且它訓練完30個周期的Loss值比另外3個均低,故文中預訓練學習率設為0.1。
3.2.3 微調學習率
設DBN微調學習率分別為0.000 01、0.000 1、0.001、0.01,研究其對模型性能的影響,圖9所示為訓練結果。
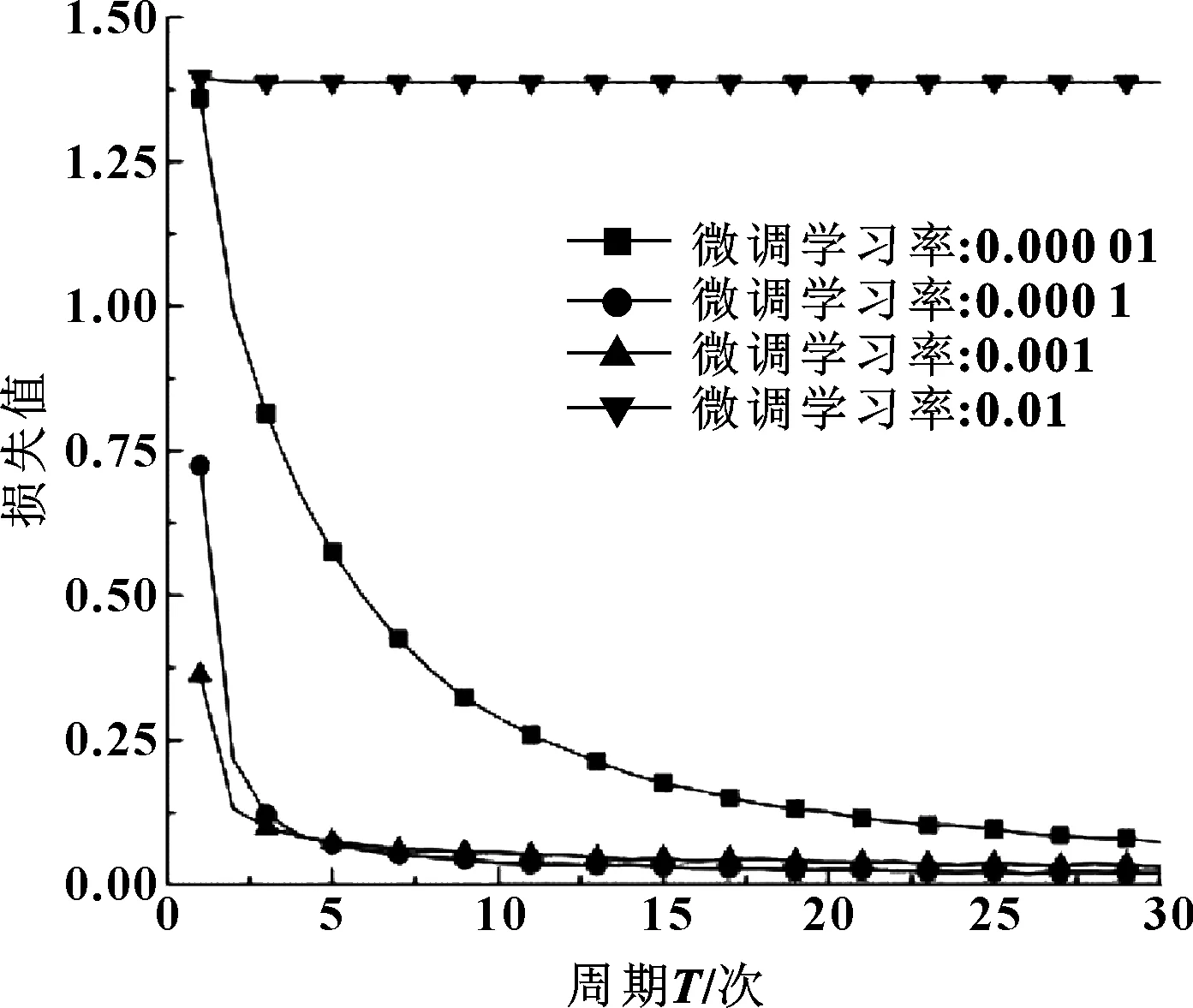
圖9 不同微調學習率對比曲線
圖9給出了不同微調學習率下損失函數的變化趨勢,表5給出了訓練時各項參數設置及量化結果。

表5 不同微調學習率的結果對比
結合圖9和表5發現,當微調學習率為0.01時效果最差,Loss值基本不變;當微調學習率為0.000 01時,雖Loss值逐漸減小,但下降速率很慢;當微調學習率為0.001或0.000 1時,Loss值迅速下降,達到穩定狀態耗時小,基本在前5個周期內可穩定。因微調學習率為0.000 1時Loss值最小,故文中微調學習率取為0.000 1。
3.2.4 批訓練數
設DBN批訓練數分別為8、16、32、64,研究其對模型性能的影響,圖10所示是訓練結果。

圖10 批訓練數對比曲線
圖10給出了不同批訓練數下識別正確率的變化趨勢,表6給出了訓練時各項參數設置及量化結果。

表6 不同批訓練數的結果對比
通過圖10和表6發現,隨著批訓練數增大,識別率逐漸提高,且訓練時間遞減。在合理范圍內增大批訓練數具有以下優點:(1)計算機內存利用率提高,大矩陣乘法并行化效率提高;(2)每運行一個周期所需迭代次數減少,對相同數量數據集處理速度更快;(3)在一定范圍內批訓練數越大,其確定的下降方向越準,引起訓練震蕩越小。對比發現,批訓練數為64時訓練時間最短且各指標最好,故文中批訓練數定為64。
綜上,文中DBN模型的最優參數如表7所示。

表7 DBN模型最優參數
表8給出了采用精確率、召回率、F1-score和訓練時間作為DBN模型評價指標的具體結果。

表8 DBN模型最終結果
如表8所示,精確率、召回率和F1-score被作為評判DBN模型的指標。其中,精確率表示分類為正的樣本中有多少是真正的正樣本,召回率表示正樣本中有多少被分類正確,而F1-score是精確率和召回率的調和平均數。由表8可知,最佳的DBN模型訓練所需時間為3.3 h,精確率、召回率和F1-score值均達到99%以上且極度相近,證明了文中提出的面向鐵譜圖像智能識別的DBN模型達到了最佳狀態。
4 結論
(1)提出了一種基于DBN的設備磨粒鐵譜圖像智能識別方法。利用DBN特征提取能力提取了鐵譜圖像特征,利用Softmax分類器實現了故障準確分類,克服了BP神經網絡等傳統方法的局限性,提高了鐵譜圖像識別與磨損故障診斷的正確率和效率。
(2)利用鐵譜圖像數據集對DBN模型中激活函數、Dropout值、學習率和批訓練數等關鍵參數進行了量化研究。當激活函數取定時,Dropout值越小正確率越高,但應防止過擬合;預訓練和微調的學習率為0.1和0.000 1時效果最佳;隨著批訓練數增大,訓練時間逐漸下降,模型識別正確率逐漸提升。
(3)經對采集的鐵譜圖像進行背景色處理、數據增強等操作后,構造了鐵譜圖像數據集,利用該數據集訓練DBN模型并完成測試,結果表明DBN識別率高達99%以上,證明該方法具有潛在工程應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
