基于FPGA的通用卷積層IP核設計
2021-07-25 03:04:07安國臣袁宏拓韓秀璐王曉君侯雨佳
河北科技大學學報 2021年3期
安國臣 袁宏拓 韓秀璐 王曉君 侯雨佳
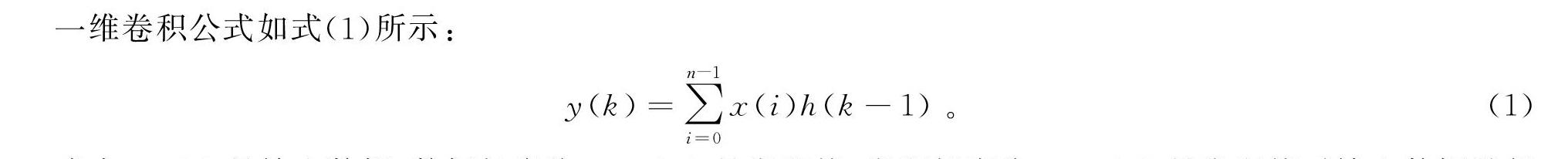

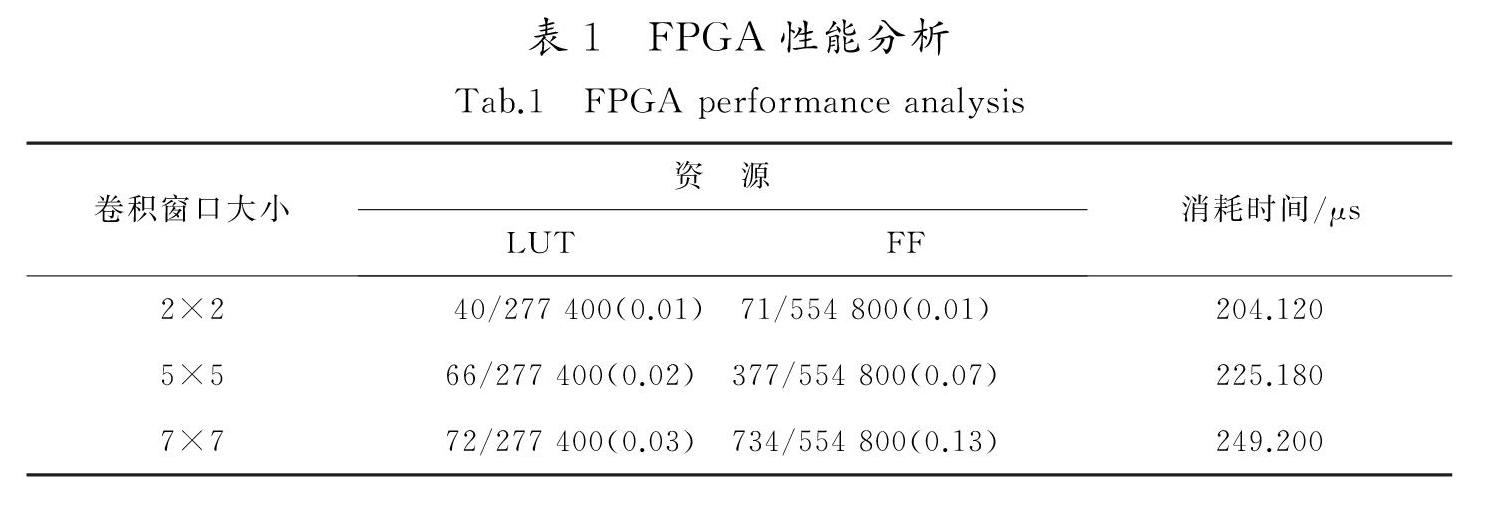
摘 要:針對目前卷積神經網絡在小型化、并行化過程中遇到的計算速度不夠、可移植性差的問題,根據卷積神經網絡和FPGA器件的特點,提出了一種利用VHDL語言參數化高速通用卷積層IP核的設計方法。利用卷積層的計算方式,將卷積核心設計為全并行化、流水線的計算模塊,通過在卷積核心的每一行連接FIFO的方式改善數據流入的方式,減少地址跳轉的操作,并加入控制核心使其可以隨圖像和卷積窗口大小調整卷積層參數,生成不同的卷積層,最后將卷積層與AXIS協議結合并封裝成IP核。結果表明,在50 MHz的工作頻率下,使用2×2大小的卷積核對100×100的圖像進行卷積計算,各項資源利用率不超過1%,耗時204 μs,計算速度理論上可以達到最高5 MF/s。因此,設計方案在增加卷積模塊可移植性的同時又保證了計算速度,為卷積神經網絡在小型化器件上的實現提供了一種可行的方法。
關鍵詞:集成電路技術;卷積神經網絡;FPGA;卷積層;設計參數化
中圖分類號:TP274;TP391 文獻標識碼:A
doi:10.7535/hbkd.2021yx03005
Design of universal convolutional layer IP core based on FPGA
AN Guochen1, YUAN Hongtuo1, HAN Xiulu1, WANG Xiaojun1, HOU Yujia2
(1.School of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang,Hebei 050018,China;
2.Shijiazhuang Foreign Education Group,Shijiazhuang,Hebei050022,China)
Abstract:Aiming at the problems of insufficient computing speed and poor portability in the miniaturization and parallelization of convolutional neural network,this paper proposes a design of high-speed universal convolutional layer IP core using VHDL language based on the characteristics of convolutional neural network and FPGA devices.Layer based on convolution calculation,convolution core design is put forward for the parallel calculation and pipeline module,through each line in the convolution of the core connect to FIFO to improve the data flow,reduce the operating address jump,and join the control core to make it can adjust the convolution with images and convolution window size to layer parameters,generate different convolution layer,finally,the convolution layer is combined with the AXIS protocol and encapsulated into IP core.Under the working frequency of 50 MHz,the convolution calculation of 100×100 images with 2×2 convolution check is carried out.The utilization rate of each resource is less than 1%,and the time is 204 μs.The theoretical calculation speed can reach the maximum of 5 MF/s.The IP core structure of the convolutional layer not only increases the portability of the convolutional module,but also ensures the computing speed,which provides a feasible implementation method for the implementation of convolutional neural network on miniaturized devices.
Keywords:
integrated circuit technology;convolutional neural network;FPGA;convolution layer;design parameterization
隨著深度學習研究的發展,卷積神經網絡在語音識別[1]、圖像理解[2]、目標跟蹤[3-4]等領域發揮著重要作用。卷積神經網絡既需要在原理和結構上繼續研究以達到更好的性能指標和遷移能力,也需要更好地把現有神經網絡適用到各種實時性、小型化的場合[5]。越來越多的神經網絡加速結構被提出,如將卷積層二值化[6]以減少FPGA的運算量、專用的加速SOC[7]使CNN峰值計算性能在100 MHz下達到42.13GFLOPS等。基于此提出了一種參數化設計的通用卷積層IP核加速結構,該結構適用范圍更廣。
所提出的通用卷積層IP核設計,屬于加速器設計通用化,是卷積神經網絡加速器設計研究與發展的一個重要方向[8]。該設計通過VHDL語言的參數化設計[9],對一種卷積層加速結構[10-11]進行重構,使其由一種定長卷積加速結構改進為可以生成不同大小卷積窗口的通用卷積核。可移植性方面,通過參數配置IP核,預先配置其窗口大小,被卷積信號或圖像大小,即可生成一維、二維不同大小的卷積層,滿足不同的卷積計算需要。計算速度方面,優化數據流入方式,避免了地址的跳轉,引入并行化和流水線思想,在數據傳輸不間斷的情況下,一個時鐘周期即可輸出一個有效計算結果。該設計支持AXI4-Stream協議,硬件開發人員可以快速調用該卷積層IP核完成卷積層的開發,不必再把精力浪費到內部卷積結構的設計上。
1 卷積層原理
卷積層有一維卷積層、二維卷積層和多維卷積層,同一種卷積層根據卷積窗口大小的不同也不同,這里主要介紹一維卷積層和二維卷積層。
1.1 一維信號卷積
一維卷積通常被用于時間序列的處理,一維卷積神經網絡(1-dimensional convolutional neural network,簡稱1DCNN)多用于工業故障診斷[12]、醫療診斷[13]等需要對時間序列進行處理的場合。
圖1為一維卷積示意圖,k個點的時間序列和n個點的卷積核做卷積運算,時間序列從左到右滑動,每次滑動對應數據相乘相加輸出一個卷積結果,作為下一層卷積層或者池化層的輸入。一維卷積運算又等效于FIR濾波器的直接型結構。
一維卷積公式如式(1)所示:
y(k)=∑n-1i=0x(i)h(k-1)。(1)
式中:x(i)是輸入數據,數據長度為k;h(n)是卷積核,卷積長度為n;y(k)是卷積核對輸入數據進行卷積后的輸出,數據長度為k,在邊帶不補零的情況下,數據長度為k-n+1。
1.2 二維圖像卷積
二維卷積神經網絡(2-dimensional convolutional neural network,簡稱2DCNN)多用于計算機視覺的處理[14-15],通過卷積核模擬人類大腦的神經元對卷積層輸入進行局部感知,模擬人腦神經元感知到生物電信號的反應并將感知結果輸出。
圖2為二維卷積層示意圖,一個卷積核模擬的神經元在輸入圖像上滑動,遍歷所有圖像數據,每滑動一次,對應的圖像數據和卷積核權值相乘求和輸出。
二維卷積公式如式(2)所示:
y(p,q)=∑m-1j=0∑n-1i=0x(i,j)h((p-i),(q-j))。(2)
式中:x(i,j)為輸入數據,一般為圖像數據;圖像大小為p×q;h((p-i),(q-j))為卷積核;卷積核的窗口大小為m×n;y(p,q)為輸出數據,數據長度為p×q,在邊帶不補零的情況下,數據長度為(p-m+1)×(q-n+1)。
2 FPGA構架分析
從1988年提出的LeNet-5模型到經典的VGG-16模型,卷積層由最初的2層增加到了13層,甚至在152層的ResNet網絡中達到了50層。卷積層數的增加意味著計算量的增加,卷積層的計算量在CNN中占比高達90%[16]。因為神經元和感受野之間的局部連接特點,同一個卷積層下的卷積核是可以并行計算的,同一個卷積核的所有感受區域也是可以并行計算的,所以卷積層可以有很高的并行性。
為了兼顧速度和資源,卷積層一般采用并行加流水線相結合的方式。在某一個感受野內的計算是并行的,即1次計算1個卷積結果。同一個卷積窗口在輸入圖像上的滑動是流水線式的,即所有數據依次進入卷積窗口進行計算,既增加了并行度、提高了計算速度,又相對節省資源。
對于一個感受野中的單次卷積運算,以5×5大小的卷積窗口為例,對于FPGA并行結構的卷積核,在流水線結構下,1個運算周期可以輸出1個卷積結果;對于基于馮諾依曼結構或者哈佛結構的通用中央處理器,1次卷積需要執行25次乘法和24次加法,共計49次計算,加上每次卷積中必須的地址跳轉等操作,至少需要50個運算周期才能輸出1個卷積結果。通過對比可知,在相同頻率下,5×5大小的卷積窗口,基于FPGA的卷積核的計算速度是基于通用中央處理器的50倍以上。
由于傳統的FPGA電路定制化的特點,針對固定結構設計的卷積核很難移植到其他算法結構中[17-20],甚至在同一個算法結構中,一個3×3的卷積核也很難擴展成5×5的卷積核。為了解決卷積層加速結構不便移植的缺點,提出了如圖3所示的通用卷積層加速結構。由圖3可知,該卷積層加速結構的通用性在于僅需在通過生成卷積層時,配置幾個簡單的參數,即可生成含有指定大小卷積窗口的卷積層。3×3,5×5,7×7甚至是類似于3×5非正方形的卷積窗口和1×N大小的一維卷積窗口,都可以通過簡單的配置生成。
該卷積層加速結構支持AXI4-Stream協議,通過AXI4總線獲取數據。卷積層結構主要分為3個部分,分別是控制核心區、數據緩存與預處理區和并行計算區。控制核心區負責接收和產生狀態信號,通過AXI4總線與外部交互并且通過控制內部FIFO的使能信號控制數據的預處理和計算。數據緩存與預處理區在控制信號的控制下,將輸入的數據流分別存入不同的FIFO中,每一行都配有一個FIFO。并行計算區不接受控制核心區的控制,在時鐘、使能和復位的控制下獨立地進行乘累加操作。
3 通用卷積層IP核設計
通用卷積層IP核模塊運用類屬參數語句generic和生成語句generate相結合的方式進行參數化設計。通過在生成IP核時配置參數,將要生成的IP核信息傳遞進入生成語句,生成特定大小的并行計算電路。計算時,將圖像的大小信息輸入控制核心模塊,由控制核心負責切換卷積核的運行狀態。
[4] PEI Xia,LI Dong,WANG Lijun,et al.Deep visual tracking:Review and experimental comparison[J].Pattern Recognition.2018,76:323-338.
[5] 李彥冬,郝宗波,雷航.卷積神經網絡研究綜述[J].自動化學報,2016,36(9):2508-2515.
LI Yandong,HAO Zongbo,LEI Hang.A review of convolutional neural networks[J].Acta Automatica Sinica,2016,36(9):2508-2515.
[6] 蔣佩卿,吳麗君.基于FPGA的改進二值化卷積層設計[J].電氣開關,2019(6):8-13.
JIANG Peiqing,WU Lijun.Design of improved binarization convolutional layer based on FPGA[J].Electric Switchgear,2019(6):8-13.
[7] 趙爍,范軍,何虎.基于FPGA的CNN加速SoC系統設計[J].計算機工程與設計,2020,41(4):939-944.
ZHAO Shuo,FAN Jun,HE Hu.Design of CNN acceleration SoC system based on FPGA[J].Computer Engineering and Design,2020,41(4):939-944.
[8] 陳桂林,馬勝,郭陽.硬件加速神經網絡綜述[J].計算機研究與發展,2018,56(2):240-253.
CHEN Guilin,MA Sheng,GUO Yang.A review of hardware-accelerated neural networks[J].Journal of Computer Research and Development,2018,56(2):240-253.
[9] 孫延騰,吳艷霞,顧國昌.基于VHDL語言的參數化設計方法[J].計算機工程與應用,2010,46(31):68-71.
SUN Yanteng,WU Yanxia,GU Guochang.Parametric design method based on VHDL language[J].Computer Engineering and Applications,2010,46(31):68-71.
[10]劉志成,祝永新,汪輝,等.基于FPGA的卷積神經網絡并行加速結構設計[J].微電子學與計算機,2018.35(10):80-84.
LIU Zhicheng,ZHU Yongxin,WANG Hui,et al.Design of convolutional neural network parallel acceleration structure based on FPGA[J].Microelectronics & Computer,2018,35(10):80-84.
[11]陳煌,祝永新,田犁,等.基于FPGA的卷積神經網絡卷積層并行加速結構設計[J].微電子學與計算機,2018,35(10):85-88.
CHEN Huang,ZHU Yongxin,TIAN Li,et al.Design of convolutional layer parallel acceleration structure of convolutional neural network based on FPGA[J].Microelectronics & Computer,2018.35(10):85-88.
[12]安晶,艾萍,徐森,等.一種基于一維卷積神經網絡的旋轉機械智能故障診斷方法[J].南京大學學報(自然科學),2019(1):133-142.
AN Jing,AI Ping,XU Sen,et al.An intelligent fault diagnosis method for rotating machinery based on one-dimensional convolutional neural network[J].Journal of Nanjing University(Natural Science),2019(1):133-142.
[13]黃佼,賓光宇,吳水才.基于一維卷積神經網絡的患者特異性心拍分類方法研究[J].中國醫療設備,2018(3):11-14.
HUANG Jiao,BIN Guangyu,WU Shuicai.Patient - specific cardiopap classification based on one-dimensional convolutional neural network[J].China Medical Devices,2018(3):11-14.
[14]王禮賀,楊德振,李江勇,等.卷積神經網絡在目標檢測中的應用及FPGA實現[J].激光與紅外,2020,50(2):252-256.
WANG Lihe,YANG Dezhen,LI Jiangyong,et al.Application of convolutional neural network in target detection and FPGA implementation[J].Laser and Infrared,2020,50(2):252-256.
[15]江澤濤,劉小艷,胡碩.基于CNN的紅外與可見光融合圖像的場景識別[J].計算機工程與設計,2019,40(8):2289-2294.
JIANG Zetao,LIU Xiaoyan,HU Shuo.Scene recognition of infrared and visible fusion images based on CNN[J].Computer Engineering and Design,2019,40(8):2289-2294.
[16]HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).New York:IEEE,2016:770-778.
[17]王婷,陳斌岳,張福海.基于FPGA的卷積神經網絡并行加速器設計[J].電子技術應用,2021,47(2):81-84.
WANG Ting,CHEN Binyue,ZHANG Fuhai.Design of convolutional neural network parallel accelerator based on FPGA[J].Application of Electronic Technique,2021,47(2):81-84.
[18]張旭欣,張嘉,李新增,等.二值VGG卷積神經網絡加速器優化設計[J].電子技術應用,2021,47(2):20-23.
ZHANG Xuxin,ZHANG Jia,LI Xinzeng,et al.Accelerator optimization design of binary VGG convolutional neural network[J].Application of Electronic Technique,2021,47(2):20-23.
[19]張帆.圖像卷積實時計算的FPGA實現[J].電子設計工程,2021,29(1):132-137.
ZHANG Fan.FPGA implementation of image convolution real-time computation[J].International Electronic Elements,2021,29(1):132-137.
[20]范軍,鞏杰,吳茜鳳,等.基于FPGA的RNN加速SoC設計與實現[J].微電子學與計算機,2020,37(11):1-5.
FAN Jun,GONG Jie,WU Xifeng,et al.Design and implementation of RNN accelerated SoC based on FPGA[J].Microelectronics & Computer,2020,37(11):1-5.
