
基于深度學(xué)習(xí)的短文本情感分析
2021-08-04 21:51:54周孝輝
中國新通信 2021年8期
周孝輝

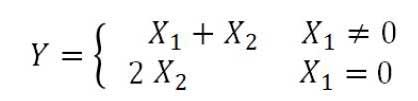
【摘要】? ? 近些年中國電影市場飛速發(fā)展,僅2021年春節(jié)檔電影票房就破百億,國內(nèi)用戶選擇影片觀影時會參考豆瓣電影評分,也會表發(fā)影評并打分,由于智能手機的普及,人們大多習(xí)慣在各類手機APP或者網(wǎng)站上發(fā)表評論,這類評論多為短文本,本文旨在通過對影評的情感分析,結(jié)合用戶對電影的評分計算出一個更符合用戶真實想法的電影評分。該評分可以供用戶和影院參考,協(xié)助其做出觀影決策和排片。相比傳統(tǒng)CNN模型,膠囊網(wǎng)絡(luò)在小型數(shù)據(jù)集上可以取得更好的效果,并且有更好的魯棒性以及擬合特征能力。我們先用網(wǎng)絡(luò)爬蟲技術(shù)爬取豆瓣影評數(shù)據(jù)并進(jìn)行預(yù)處理,然后將處理好的數(shù)據(jù)輸入到ALBERT層進(jìn)行序列化,再將ALBERT層輸出的文本特征分別輸入到Bi-GRU層和膠囊網(wǎng)絡(luò)層獲取句子全局特征和局部特征并進(jìn)行特征融合,再經(jīng)過全連接層進(jìn)行線性降維,然后將全連接層的輸出結(jié)果輸入到Softmax層進(jìn)行分類得到對應(yīng)情感類別,最后結(jié)合電影的星級評分計算電影的綜合評分。
【關(guān)鍵字】? ? 短文本? ? 情感分析? ? Bi-GRU? ? 膠囊網(wǎng)絡(luò)
引言:
情感分析,也稱為觀點挖掘、意見挖掘、極性分類,本質(zhì)上是一個情感分類問題,主要研究人們對實體的看法、態(tài)度和情感,是自然語言處理領(lǐng)域中的一個重要研究方向。傳統(tǒng)的情感分析方法主要是基于機器學(xué)習(xí),需要復(fù)雜的特征工程,且泛化能力較差,近年來崛起的深度學(xué)習(xí)方法很好的彌補了基于機器學(xué)習(xí)方法的缺陷,成為了情感分析的主流方法。
主流的深度學(xué)習(xí)方法,大多基于CNN模型或者RNN模型,存在著諸多不足:CNN獲取信息能力取決于卷積核窗口長度,捕獲能力有限,且不能學(xué)習(xí)上下文信息;RNN容易出現(xiàn)梯度消失或者梯度爆炸現(xiàn)象。由于這些原因,膠囊網(wǎng)絡(luò)(Capsule Network)、長短期記憶網(wǎng)絡(luò)(LSTM)、門控循環(huán)單元(GRU)、雙向長短期記憶網(wǎng)絡(luò)(Bi-LSTM)等變體開始流行。本文提出一種基于深度學(xué)習(xí)的短文本情感分析方法。
一、模型結(jié)構(gòu)
情感分析屬于自然語言處理領(lǐng)域,本文提出的模型結(jié)構(gòu)如圖1所示,主要分為以下模塊:
1.文本預(yù)處理模塊:通過網(wǎng)絡(luò)爬蟲技術(shù)爬取豆瓣影評T,進(jìn)行清洗和預(yù)處理操作使文本結(jié)構(gòu)化得到數(shù)據(jù)T1,預(yù)處理操作包括去特殊符號、去英文、去數(shù)字、去停用詞和中文分詞。
2.詞向量嵌入模塊:使用預(yù)訓(xùn)練好的ALBERT模型對結(jié)構(gòu)化數(shù)據(jù)進(jìn)行序列化,得到文本對應(yīng)的序列S。
3.征提取模塊:包括Bi-GRU層、膠囊網(wǎng)絡(luò)層和特征融合層,其中Bi-GRU層提取文本的全局特征,將序列S分別輸入前向GRU層和后向GRU層中進(jìn)行訓(xùn)練得到向量表示和,將兩者疊加得到向量F1;膠囊網(wǎng)絡(luò)層用于提取文本的局部特征,將序列S輸入到膠囊網(wǎng)絡(luò)層,使用動態(tài)路由算法進(jìn)行特征提取,得到特征向量F2;特征融合層,將特征向量F1和F2向量進(jìn)行特征融合,得到新的特征向量F3。
4.全連接層:用于將上一層輸出F3全連接至本層的輸出神經(jīng)元,輸出一個特征向量V。
5.Softmax分類層:用于將全連接層輸出的特征向量V進(jìn)行歸一化,得到文本對應(yīng)每一類的概率矩陣M,M的最大值索引即文本對應(yīng)的情感標(biāo)簽,包括好評,中評和差評,分別對應(yīng)數(shù)值“5”,“3”和“1”。
6.輸出層:綜合用戶對影片的評分和文本對應(yīng)的情感標(biāo)簽對影片進(jìn)行評價,用戶對影片的打分為X1,如果評分缺失設(shè)定X1為0,基于情感分析的影評評分為X2,影片的最終評分計算公式如下:
二、算法介紹
2.1 文本預(yù)處理
2.1.1網(wǎng)絡(luò)爬蟲
網(wǎng)絡(luò)爬蟲技術(shù),也叫爬蟲程序,是自動搜索并下載互聯(lián)網(wǎng)資源的程序或腳本。通常可以分為四類:主題網(wǎng)絡(luò)爬蟲、通用網(wǎng)絡(luò)爬蟲、增量式爬蟲和深層網(wǎng)絡(luò)爬蟲。本方法使用的主題爬蟲能只抓取預(yù)定義主題相關(guān)的頁面,避免了無效信息的干擾。
網(wǎng)絡(luò)爬蟲可以用JAVA、PHP、Python等各種語言實現(xiàn),由于Python擁有腳本語言中最豐富的類庫,我們使用Python的Selenium庫模擬主流瀏覽器的運行,實現(xiàn)模擬登陸、自動翻頁,自動點擊等交互操作。
2.1.2去停用詞
文本中存在著大量與文章主題無關(guān)的字母、標(biāo)點、助詞等,如“你”、“了”、“的”等,進(jìn)行預(yù)處理時將這些刪除以免對文本分類結(jié)果造成影響。
2.1.3中文分詞
詞對于中文來說是表示語義的最小單元,和英文用空格隔開不同,詞與詞之間沒有天然分隔,對于計算機理解較困難,分詞尤為重要。我們選用的jieba分詞工具,是一種免費開源的分詞工具,支持精確模式、全模式和搜索引擎模式三種分詞模式:精確模式, 試圖將句子最精確地切開,適合文本分析;全模式,把句子中所有的可以成詞的詞語都掃描出來,速度非常快,但是不能解決歧義;搜索引擎模式,在精確模式的基礎(chǔ)上,對長詞再詞切分,提高召回率,適合用于搜索引擎分詞。
2.2 ALBERT
常用的Word2Vec模型只考慮了文本的局部信息,Pennington等為了克服其缺陷提出的Glove模型,雖然同時考慮了局部與整體信息,但本質(zhì)上仍然是靜態(tài)的詞向量,舍棄了大量的位置信息。Devlin等人2018年提出的BERT(Bidirectional Encoder Representations from Transformers)是一種動態(tài)詞嵌入技術(shù),在NLP領(lǐng)域的11個方向大幅刷新了精度,但是其所需訓(xùn)練時間較長,會導(dǎo)致內(nèi)存不足等問題。
ALBERT(A Lite BERT)模型是基于BERT模型的一種輕量級預(yù)訓(xùn)練語言模型,其和BERT一樣采用雙向Transformer獲取文本特征表示,但通過嵌入層參數(shù)因式分解和跨層參數(shù)共享大幅減少了模型參數(shù),降低了訓(xùn)練時的內(nèi)存開銷并提升了訓(xùn)練速度。
2.3 Bi-GRU
RNN(Recurrent Neural Network)容易出現(xiàn)梯度消失或者梯度爆炸現(xiàn)象,LSTM(Long Short-Term Memory)和Bi-GRU(Bidirectional Gated Recurrent Unit)通過引入門控機制緩解了這兩個問題。GRU相較LSTM只有更新門zt和重置門rt兩個門控單元,模型訓(xùn)練時間更短。
本方法使用的Bi-GRU,是一種雙向的基于門控的循環(huán)神經(jīng)網(wǎng)絡(luò),由前向GRU和后向GRU組成,通過兩個方向遍歷文本,得到包含文本上下文的信息,解決了GRU模型只能包含上文信息的問題,同時速度相比其他序列模型有一定提升。
2.4 膠囊網(wǎng)絡(luò)
2011年Hinton等首次提出膠囊網(wǎng)絡(luò)的概念,其用向量膠囊代替卷積神經(jīng)網(wǎng)絡(luò)中的神經(jīng)元、動態(tài)路由機制代替池化操作、Squash函數(shù)代替ReLU激活函數(shù),在圖像識別領(lǐng)域取得了很好的效果。
近年來,人們開始嘗試將膠囊網(wǎng)絡(luò)用于自然語言處理領(lǐng)域,并逐步取得不錯的效果,本方法中膠囊網(wǎng)絡(luò)的動態(tài)路由算法可以動態(tài)學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)層之間的關(guān)系并保留句子中出現(xiàn)概率較小的語義特征,保證特征信息的完整性,且其相比CNN有更好的魯棒性以及擬合特征能力。
三、結(jié)束語
本文提出了一種基于深度學(xué)習(xí)的短文本情感分析方法,本方法使用ALBERT預(yù)訓(xùn)練的動態(tài)詞向量代替?zhèn)鹘y(tǒng)的靜態(tài)詞向量,提升了詞向量的表征能力,為之后的分類奠定了很好的基礎(chǔ),很大程度上提高了分類的準(zhǔn)確性;本文使用Bi-GRU負(fù)責(zé)全局特征提取,相比常用的單層或者雙層神經(jīng)網(wǎng)絡(luò)可以得到更好的效果;本文使用膠囊網(wǎng)絡(luò)負(fù)責(zé)局部特征提取,保證特征信息的完整性,速度和魯棒性相比傳統(tǒng)方法有一定提高。
參? 考? 文? 獻(xiàn)
[1] Pawe? Cichosz. A Case Study in Text Mining of Discussion Forum Posts: Classification with Bag of Words and Global Vectors[J]. International Journal of Applied Mathematics and Computer Science,2018,28(4).
[2] LAN Z,CHEN M,GOODMAN S,et al.ALBERT:a lite BERT for self-supervised learning of language representation.
[3]冀文光. 基于Attention-Based Bi-GRU模型的文本分類方法研究[D].電子科技大學(xué),2019.
[4]薛煒明,侯霞,李寧.一種基于word2vec的文本分類方法[J].北京信息科技大學(xué)學(xué)報(自然科學(xué)版),2018,33(01):71-75.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
