BERT 跨語言詞向量學習研究
2021-08-07 07:42:16王玉榮李艷玲
計算機與生活 2021年8期
王玉榮,林 民,李艷玲
內蒙古師范大學 計算機科學技術學院,呼和浩特 010022
隨著互聯網多語言信息的發展,不同語言的知識共享與聯系日益緊密,如何有效地表示不同語言文本所隱含的動態特征信息,已成為當下的研究熱點。文本詞向量能夠表示文本語義、語法和結構等特征信息,跨語言詞向量是單語文本詞向量在多語言環境下的一種自然擴展。它認為具有相同概念的不同語言的詞向量在向量空間中的距離非常接近,使得跨語言詞向量可以在不同語言間進行詞義推理和特征共享[1]。通過多語言的知識可以構建動態的共享特征空間,使得有利于發現跨語言相關知識的對齊效果,增強相關但不同的分類知識域間的聯系。
近年來,跨語言詞向量被應用于多個自然語言處理(natural language processing,NLP)任務中,如面向任務的對話系統[2-3]、詞性標注[4-6]、命名實體識別[7-8]、信息檢索[9]、依存分析[10]和個性化對話代理[11]。與其他跨語言模型相比,如基于多語言本體的跨語言模型[12],跨語言詞向量模型有兩大優勢。第一,跨語言詞向量模型能夠對跨語言語義信息進行建模,準確計算跨語言詞語相似度等信息,是跨語言詞典構建[13]、跨語言信息管理[14]、跨語言信息檢索[15]等多種跨語言應用的基礎[16]。第二,跨語言詞向量支持語言之間的模型轉移,為遷移學習提供了橋梁。例如,跨語言遷移學習的一個重要研究方向是[17-20],通過提供公共的表示空間,實現資源豐富的語言和資源貧乏的語言之間的模型轉移[1]。
大多數跨語言詞向量模型都使用單語詞向量模型,并將其擴展到雙語以及多語言環境中。單語詞向量模型成為很多跨語言詞向量模型的一個重要的初步工作。
早在Bengio等[21]提出的神經網絡語言模型(neural network language model,NNLM)及Mikolov[22]提出的Word2Vec 特征表示學習模型,將文本訓練成為用分布式詞向量表示的詞向量,能有效捕捉隱含在單詞上下文的語法、語義信息,在許多需要這些語言特征建模的應用任務中取得了較好的效果,如情感分析[23]、依存分析[24]、機器翻譯[25]等任務。但該模型的缺陷是:(1)只考慮固定大小窗口內的單詞,在獲取句子上下文語義信息方面存在困難;(2)獲得的詞向量具有聚義現象,將處于不同語境的詞匯多種語義綜合表示成一個詞向量,不能表達一詞多義,是一種靜態的詞向量。為了有效學習詞匯的多重含義,Peters等[26]提出基于雙向LSTM(long short-term memory)的深度語境化詞向量模型ELMo(embedding from language models),對單詞的復雜特征,以及單詞使用時語境中的變化進行建模。Devlin等[27]提出了BERT(bidirectional encoder representations from transformers)模型。它摒棄了雙向LSTM 的循環網絡結構,把Transformer[28]編碼器當作模型的主體結構,并利用注意力機制對句子進行建模。BERT 模型的突出優勢是通過海量語料的訓練,得到了一組適用性十分廣泛的詞向量,同時還能在具體任務中進一步動態優化(fine-tuning),生成上下文語境敏感的動態詞向量,解決了以往Word2Vec、Glove(global vectors for word representation)等模型的聚義問題。BERT 預訓練模型的出現,使靜態的跨語言特征共享空間走向了動態的跨語言特征共享空間,解決了在多語言環境中一詞多義的問題。例如,“蘋果”這個詞的向量在英漢跨語言詞向量空間中,可以根據不同的上下文與英文的“fruits”類詞匯或“enterprises”類詞匯向量接近。
因而本文重點分析基于BERT 的跨語言詞向量學習方法,按照訓練方式的不同分為有監督學習和無監督學習,并對各類訓練方法的原理進行分析和比較。結合闡述的文獻,以構建基于BERT 的蒙漢文跨語言詞向量進行展望。
1 預訓練模型BERT 和跨語言詞向量模型相關概念及訓練數據需求
BERT 模型通過預訓練和微調的方式得到語義更豐富的詞向量表示,能夠克服傳統詞向量的聚義現象,通過微調的方法將模型應用到特定的下游任務,提升泛化能力[29]。在預訓練方面,通過堆疊Transformer模型的編碼器部分構建基礎模型,如圖1 所示。通過掩蔽語言模型(masked language model,MLM)和預測下一句(next sentence prediction,NSP)兩個任務聯合訓練達到捕獲詞級和句子級上下文語義向量表示的目的,其中掩蔽語言模型真正實現了雙向語言模型的效果[30]。在遷移到下游任務方面,BERT 借鑒了OpenAI 的GPT(generative pre-training)預訓練模型的做法,設計了比GPT 更通用的輸入層和輸出層[30]。
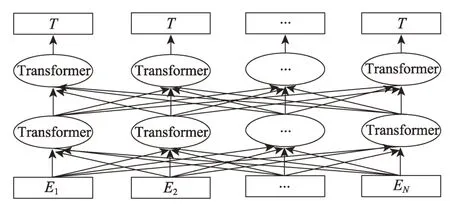
Fig.1 Model structure of BERT圖1 BERT 模型結構
Mikolov 等[22]觀察發現,不同語言的詞向量在向量空間中有著相似的幾何排列,如圖2 所示,左圖為英語,右圖為西班牙語。不論是數字詞匯還是動物詞匯,英語和西班牙語詞向量的分布非常相似。基于這一發現,提出一種線性映射的方法實現源語言向量空間到目標語言向量空間的轉換。后續,學者們通過雙語詞典學習該轉換[31],又通過自學習減少詞典的規模[32],最終通過無監督初始化啟發式學習[33-34]和對抗性學習[35-36]實現源語言詞向量到目標語言詞向量的映射。此外,通過從單語設置轉換到雙語設置[23]構建共享的雙語向量空間,可以在不同語言間進行擴展和概括語義任務[37],例如,語義相似性[38]計算、同義詞檢測或單詞類比計算[39]等。
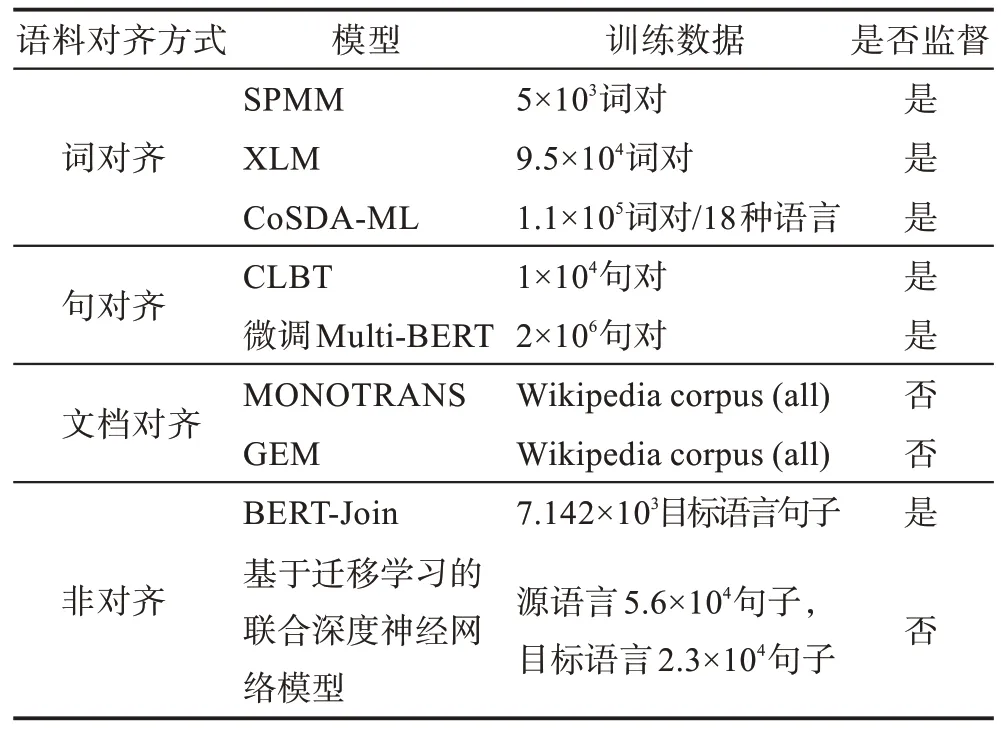
Ruder 等[1]將跨語言詞向量按照語料對齊方式分為基于詞對齊、基于句子對齊、基于文檔對齊的學習方法。其中基于詞對齊的方法是所有方法的核心和基礎。為方便理解,圖3 分別給出了不同對齊語料的示例,其中圖3(a)是詞對齊的平行語料示例,圖3(b)是句對齊的平行語料示例,圖3(c)是類似于文檔對齊的語料示例。
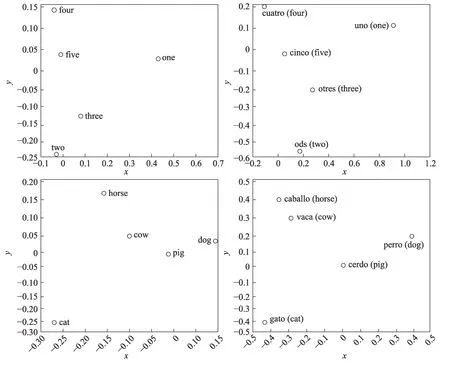
Fig.2 English and Spanish word embedding representation圖2 英語、西班牙語詞向量表示

Fig.3 Examples of alignment of different types of corpus圖3 不同類型語料對齊示例
有監督的學習方法一般需要大量的標注數據,對于英文和中文而言,存在各種任務的標注數據集,而對于資源缺乏的語言,獲取這樣大量的數據比較困難。半監督的學習方法可以緩解這一問題,使用較少的標注數據進行訓練。無監督學習不需要任何人工標注的數據。本文將有監督學習方法和半監督學習方法一起進行分析,對所需的語料單獨進行歸納總結。下面分別從有監督學習及無監督學習兩方面對基于BERT 的跨語言詞向量學習方法的主要研究展開詳述。
2 基于BERT的有監督跨語言詞向量學習方法
2.1 有監督跨語言詞向量學習方法
2.1.1 基于共享空間映射的方法
跨語言詞向量映射是學習雙語詞向量的有效方法[22]。其基本思想是利用單語語料庫獨立訓練不同語言的詞向量,通過線性變換將它們映射到同一個共享空間。Mikolov 等[22]提出的映射方法包含一個雙語詞典和對應的向量,其中xi∈X是源語言詞向量,yi∈Y是目標語言詞向量。學習任務是找到一個變換矩陣W,使Wxi無限接近yi。訓練優化公式如式(1)所示:

為提高模型的性能,研究者們在矩陣和向量上加了許多約束。Xing 等[40]提出源語言和目標語言的詞向量長度需要先進行歸一化操作。Faruqui 等[41]使用典型相關分析(canonical correlation analysis,CCA)將源語言和目標語言的向量映射到共享空間,最大限度地提高兩種單語向量空間映射的相關性。之后,在跨語言詞向量學習過程中,為了降低種子詞典的規模,許多研究者提出采用自學習的策略在迭代中擴充詞典。
為了解決不同語言、不同領域的詞匯分布差異問題,樊艷[42]提出了基于多個矩陣的軟分段映射模型(soft piecewise mapping model,SPMM),其中每個矩陣對源語言向量空間中的每個主題分布進行建模。在SPMM 中,訓練集中的每個實例(xi,yi)∈D(雙語訓練的詞典),對應著一組權重值構成的向量
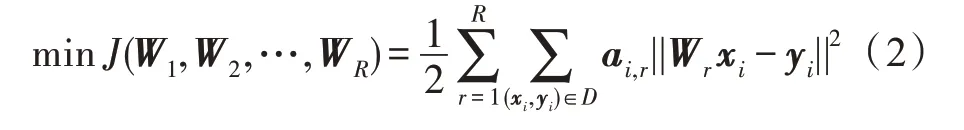
其中,W1,W2,…,WR代表R個映射矩陣,每個實例(xi,yi)對應著一個用于學習第r個映射矩陣Wr的權重值ai,r。并提出一種自動詞典擴充算法,在迭代中提升詞典數量。在每一次迭代中,首先在源語言和目標語言詞匯中進行采樣,得到集合DS(源語言詞匯集)和DT(目標語言詞匯集)。DS和DT中的每個詞是以概率正比于它在語料庫中的頻率進行采樣得到的。在維基百科的可比語料上相比前人的方法有了一定的提高,在非同一語系英文-中文、低資源的越南語-英語跨語言術語翻譯下游任務中有明顯的提升。并證明在跨領域知識體系遷移任務中,預訓練模型BERT 的效果最好。該方法適用于語言差距較大的跨語言任務中,非同一語系的詞匯在向量空間中的分布差異較大,需要多個矩陣進行細粒度的映射。利用源語言向量空間的詞向量分布信息,可以學習到每個聚類的權重,使得細粒度的映射可以在跨語言、跨領域中進行知識的遷移。該方法能夠緩解雙語詞典語料缺乏問題,但需要高質量的初始詞典,文中主要采用了公開的詞典[43],并在維基百科的可比語料上做了自動詞典擴充。
用雙語詞典生成法來學習跨語言詞向量,克服了需要大規模語料的問題,但是對種子詞典的要求比較高,需要高質量的種子詞典。Wang 等[44]提出了基于詞對齊的跨語言BERT 映射,在學習上下文跨語言詞向量時在單詞級別上進行監督而不再是詞典級別上。其主要思想是:首先,通過無監督的詞對齊工具獲得一組包含上下文信息的詞對;然后,用預訓練好的BERT 模型獲得詞向量表示;最后,找到一個合適的線性映射矩陣W,使得源語言詞向量空間與目標語言詞向量空間的距離盡可能接近。在依存分析的下游任務中,該方法遠超過了之前使用靜態跨語言嵌入的模型,平均增益為2.91%,相比其他跨語言模型,所需的訓練數據、計算資源和訓練時間要少得多,但實現了極具競爭力的結果。該方法能夠在有限的雙語語料上較快地獲取跨語言上下文相關的詞向量。但只是單一地解決了資源稀少語言學習詞向量的問題,沒有很好地體現跨語言語義融合的詞向量。因為該方法只是把目標語言詞向量映射到源語言詞向量,使得目標語言的詞向量盡量與源語言詞向量對齊,而對于學習跨語言語義融合詞向量模型的貢獻還是較少。
2.1.2 基于聯合學習方法
Klementiev 等[45]將跨語言表征的學習視為一個多任務學習問題。聯合優化源語言和目標語言模型以及跨語言正則化術語,使得在并行語料庫中對齊單詞的詞向量在向量空間中更加相近。Castellucci等[46]提出BERT-Joint 模型,在多語言BERT 模型上設計了一種聯合學習方法,應用于多語言聯合文本分類和序列標注工作。通過多語言BERT(multilingual BERT,Multi-BERT)模型的[CLS]詞項的最終隱狀態h0的固定維數序列來實現文本分類,通過詞項對應的最終隱狀態對該詞項進行標注。為實現該目標,作者在模型上添加了句子級分類矩陣,分別實現了文本分類和序列標注功能。該方法在英文基準數據上得到了較好的結果。在跨語言方面,用翻譯器實現源語言詞匯和目標語言詞匯對齊,在有少量標注的意大利語數據集上得到了較好的效果。但該模型的跨語言詞向量學習完全依賴Multi-BERT 模型,通過機器翻譯源語言的訓練數據實現多語言的任務,實質上訓練數據的意圖標簽和語義槽填充值并沒有改變,因此并沒有實現真正意義上的任務遷移。此外,利用機器翻譯會丟失源語言本身的語法等內部信息,翻譯結果需花費大量的時間去矯正,這也不利于該方法的訓練。
Multi-BERT 雖然能夠學習跨語言詞向量,但其訓練過程仍是一種語言接著另一種語言的訓練,源語言和目標語言單獨進行編碼,二者之間沒有交互,產生的句子表示之間關聯性差,擬合后得到的分數也會低。陸金梁等[47]提出一種基于Multi-BERT 跨語言聯合編碼的詞向量學習方法。在預訓練好的Multi-BERT 模型基礎上使用少量的平行語料進行二次訓練,將其應用到譯文質量估計任務中,并分析了該模型在句子級跨語言任務上的效果,如圖4 所示。該模型預訓練的任務與BERT 一樣,包括掩蔽詞匯預測和是否為互譯文句的預測兩個任務。在預訓練過程中與BERT 模型不同的是,源語言句子中沒有掩蔽詞匯,掩蔽詞匯都在目標語言句子中,即在知道源語言句子的情況下預測目標語言句子中掩蔽的詞匯。該方法在德語->英語、中文->英文的譯文質量估計上都得到了較好的效果。在跨語言詞向量學習方面,以中文單詞和英文單詞為例,用平行語料進行二次訓練的Multi-BERT 得到的詞向量在向量空間中的相似度遠高于用單語語料二次訓練的Multi-BERT 得到的詞向量。他們通過觀察從源語言句子到目標語言句子的注意力權重分配,發現該方法使得在兩種語言中具有相似語義的單詞注意力分布基本一致。通過聯合編碼的預訓練方法,可以幫助相互注意在不同語言間具有關系的單詞,尤其是具有相似語義的單詞。
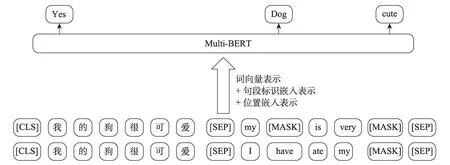
Fig.4 Multi-BERT quadratic training method using parallel corpus圖4 使用平行語料的Multi-BERT 二次訓練方法

Fig.5 Pre-training cross-lingual models圖5 跨語言模型預訓練
Lample 等[48]將平行數據的跨語言監督納入到學習跨語言的語言模型(cross-lingual language model pretraining,XLM)中。結合掩蔽語言模型(masked language modeling,MLM)和翻譯語言模型(translation language modeling,TLM)實現半監督的跨語言詞向量學習,如圖5 所示。掩蔽語言模型基本與Devlin 等[27]提出的想法一樣,類似于完形填空任務。與其不同的是,掩蔽語言模型使用由任意數量的句子組成的文本流代替成對的句子。翻譯語言模型的輸入是平行的翻譯句子,并隨機掩蔽源語言句子和目標語言句子中的一些詞匯。在訓練中,預測源語言句子中掩蔽的詞匯時,該模型不僅能注意到源語言詞匯上下文信息,還能夠注意到目標語言的上下文信息。該方法以高出4.9%的準確率刷新了XNLI(cross-lingual natural language inference)[49]的記錄。該方法的翻譯語言模型,在預測掩蔽詞匯的時候不僅捕獲了該語言詞匯的語義、語法信息,而且捕獲了另一種語言的深層次信息。
2.1.3 基于偽雙語語料的方法
基于偽雙語語料的詞向量學習方法使用雙語詞典,隨機替換源語言語料庫中的單詞來構建偽雙語語料庫。Xiao 等[50]首次提出該方法,使用初始種子詞典,創建一個聯合跨語言詞匯表,其中每個翻譯對占據相同的向量表示。他們通過提供源語言和目標語言語料庫的上下文窗口使用最大邊界損失(max-margin loss,MML)[51]對這個模型進行訓練。Qin 等[52]在該方法的基礎上,提出跨語言零樣本學習的多語言文本混合(code-switching)數據增強方法(multi-lingual codeswitching data augmentation for zero-shot cross-lingual,CoSDA-ML),實現更好地微調Multi-BERT。該模型通過混合上下文信息來一次性對齊源語言和多目標語言的詞表示。如圖6 所示,首先使用數據增強的多語言文本混合對Multi-BERT 進行微調,即將“It's a very sincere work”數據,變化成“It's a 非常aufrichtig work”。微調結束后,直接將其應用到零樣本遷移測試。其中,數據增強方法包括選句子、選詞和替換已選詞三個步驟。經過CoSDA-ML 微調后在多語言環境中語義相近詞的向量變得更接近并相互重疊。但該方法的局限在于需要高質量的多語言的雙語詞典,對于資源稀少的語言還是有一定的困難。
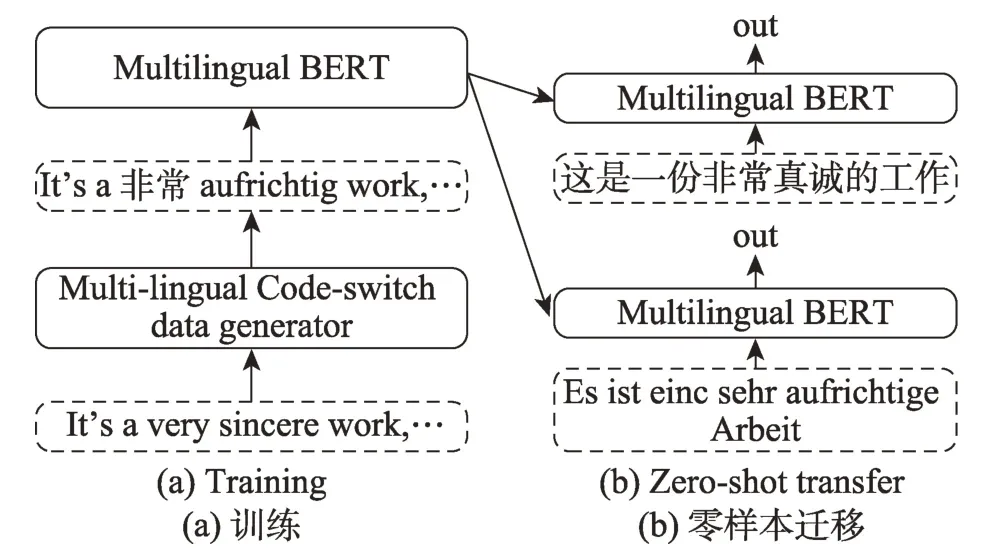
Fig.6 Training and zero-shot transfer圖6 訓練和零樣本遷移過程
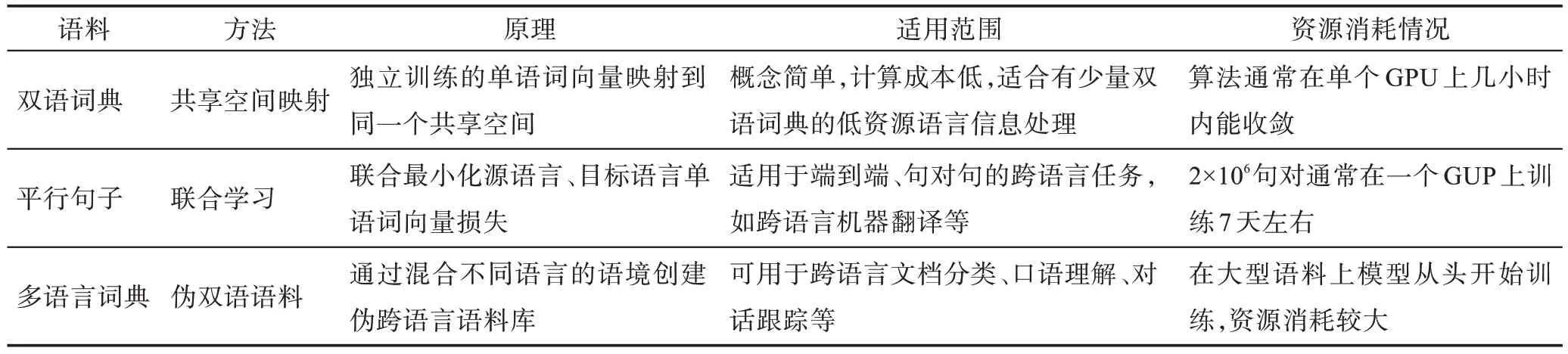
Table 1 Comparison of supervised cross-lingual word embedding learning methods based on BERT表1 基于BERT 的有監督跨語言詞向量學習方法對比
2.2 基于BERT 的有監督跨語言詞向量學習方法的分析與比較
基于共享空間映射的跨語言詞向量學習方法通過利用豐富的雙語詞典或詞對齊語料實現有效的跨語言詞向量學習。但該方法存在一個缺點,一次只考慮一對源語言和目標語言,因此導致每種目標語言要有單獨的模型。近年來,隨著多語言BERT 的盛行,基于聯合學習的跨語言詞向量學習方法頗受研究者的青睞。通過預訓練和微調,實現多語言詞向量的語義對齊,并且克服了共享空間映射方法的缺點,成為目前較為流行的跨語言詞向量學習方法。在實際應用中,偽雙語語料方法的成本較高,在大型單語語料上從頭開始訓練。相比之下,基于共享空間映射方法的計算效率高,因為它利用了預訓練的單語詞向量。基于共享空間映射的方法、基于聯合學習的方法和基于偽雙語語料的方法看起來非常不同,但它們有時非常相似,事實上,它們是等價的[1],等價性證明這里不做贅述。根據上文的論述,表1 是對基于BERT 的有監督跨語言詞向量學習方法的大致歸納總結。
3 基于BERT的無監督跨語言詞向量學習方法
3.1 無監督跨語言詞向量學習方法
上文介紹的基于BERT 跨語言詞向量學習方法需要一些平行語料或雙語詞典,但這對資源稀缺的語言還是比較難獲得。Multi-BERT 在完全無監督的情況下能進行跨語言遷移,改變了跨語言詞向量學習方法。通過聯合訓練Transformer 模型來執行多種語言的掩蔽語言建模,然后在下游任務上進行微調。Wu 和Dredze[53]發現,Multi-BERT 的跨語言泛化能力基于三個因素:(1)種子詞典的共享詞匯;(2)多種語言語料的聯合訓練;(3)深度的跨語言表征。Artetxe 等[54]提出單語言的跨語言遷移模型(crosslingual transfer of monolingual model,MONOTRANS),通過將單語種模型遷移到詞匯級別的新語言中的方法來反駁此假設。首先,使用L1未標注的語料訓練BERT 模型,訓練任務為掩蔽的語言模型和下一句話的預測;然后,凍結訓練好的BERT模型的Transformer主體結構(embedding 層和softmax 層除外),用L2未標注數據訓練新的BERT 模型,訓練任務與上一步相同;其次,使用L1的標注數據在下游任務中,微調第一步訓練好的模型,微調過程中凍結embedding 層;最后,使用第二步得到的embedding 層替換第三步的embedding 層,得到新的模型,應用于L2中相同的下游任務,如圖7 所示。在標準的跨語言分類基準和新的跨語言問答數據集上,該方法與Multi-BERT 有一定的競爭力。該方法中的詞匯表是在各自的單語語料庫上訓練的,沒有為每種語言構建單獨的詞匯表,即沒有共享子詞匯的概念,成功地反駁了Multi-BERT 跨語言泛化能力的三個因素。他們還發現,在跨語言預訓練的模型中貢獻較大的是每種語言的有效詞匯,而不是有一個聯合的詞匯表或多種語言的共享詞匯表。無需共享詞匯只需要單語語料,對資源信息缺乏的語言是個較好的方法,是無監督學習跨語言詞向量的一個新臺階。
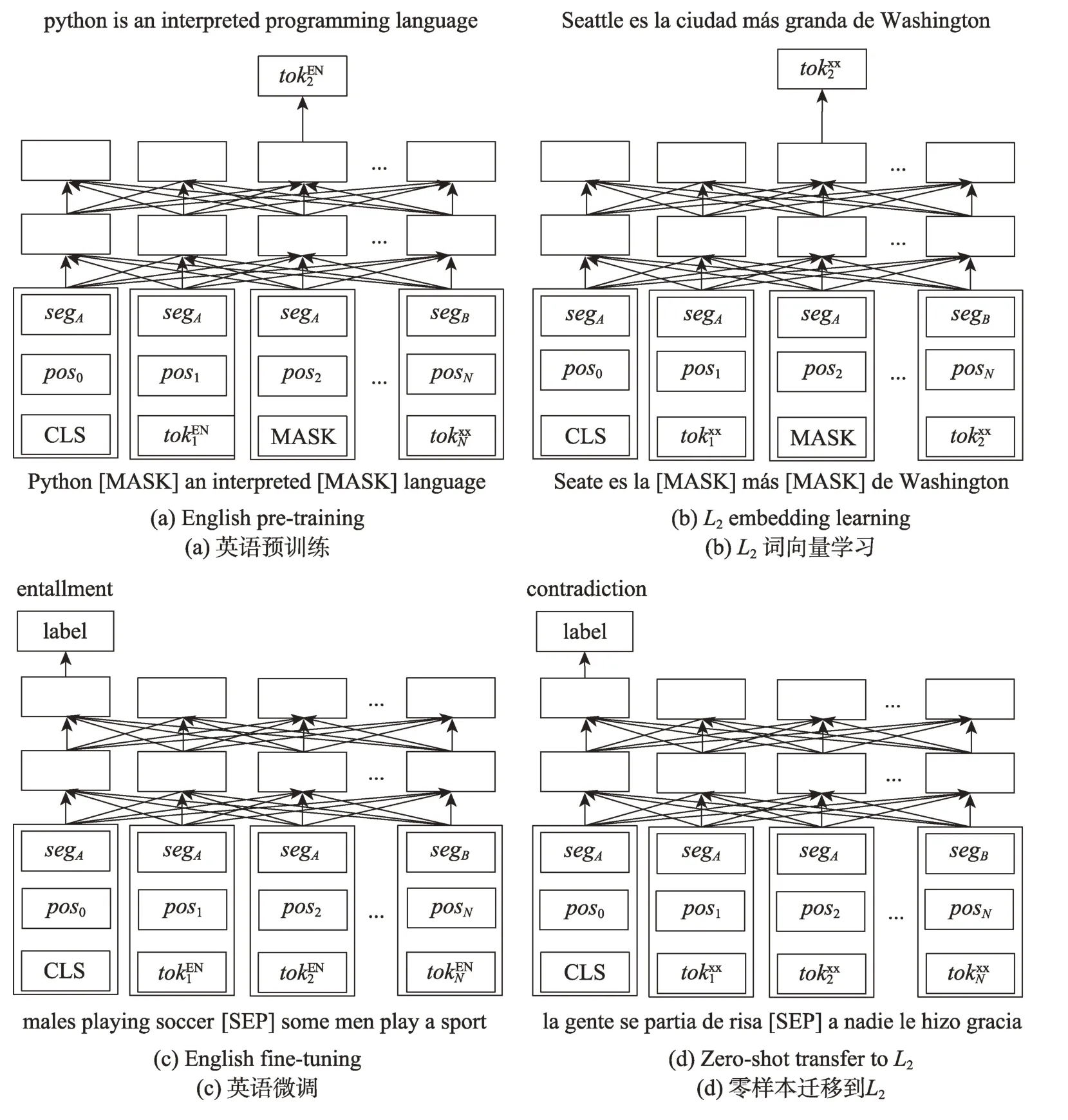
Fig.7 Zero-shot cross-lingual transfer圖7 零樣本跨語言遷移
跨語言模型,在大量的跨多種語言的單語或雙語資源上進行了預先訓練,并對它們進行微調以適應下游的跨語言任務,取得了良好的效果[55]。然而在微調過程中可能會改變模型參數,削弱跨語言的泛化能力。為了緩解這一問題,Liu 等[56]提出一種持續學習的方法,在微調下游的跨語言任務時,能夠保持預先訓練過模型的原始跨語言能力。假設:模型已經學習了n-1 個任務,并且需要學習第n個任務。梯度情景記憶(gradient episodic memory,GEM)的主要特性是情景記憶Mk,它存儲觀察到示例的一個子集任務k(k∈[1,n])。第k個任務的內存損失定義為:

為了在學習第n個任務的同時保持模型在前n-1 個任務中的性能,GEM 將前n-1 個任務的損失作為不等式約束。在觀察第n個任務的訓練樣本(x,y) 時,GEM 的作用是最小 化L(fθ(x,n),y),其中,Mk),k 此外,在少數民族語言跨語言詞向量學習方面,孔祥鵬等[57]提出了一種基于遷移學習的聯合深度神經網絡模型,通過共享權重的方法學習跨語言詞向量表示,應用于維吾爾語命名實體識別。首先用中文訓練BERT 語言模型獲得中文的語義詞向量表示,將詞向量輸入到空洞卷積神經網絡減少神經元層數和參數,再通過雙向門控循環單元進行上下文語義信息提取,最后通過條件隨機場(conditional random fields,CRF)得到最優標簽序列。中文實體識別模型訓練好后,采用共享深度神經網絡隱藏層的方法捕捉維吾爾語字符之間的語義依賴關系,從而提高命名實體識別的性能,其準確率為91.39%,召回率為90.11%,F1 值達到了90.75%。該方法中跨語言詞向量學習主要依賴于BERT 的語義學習和神經網絡權重的共享。模型在中文信息上學到的表示信息遷移到維吾爾語上,實現了從維吾爾語詞向量到中文詞向量的對齊。 對于資源缺乏的語言來說,獲取大量的標注數據進行有監督訓練是比較困難的,因此如何從已訓練好的高資源語言遷移到一個低資源的語言,并且不需要標注數據成為一個新的挑戰。無監督的跨語言學習方法無需人工標注數據且具有領域無關性,適合有大規模開放的無結構化數據的語言,但這種訓練方法對硬件的消耗也比較大。表2 是對以上各種基于BERT 的無監督跨語言詞向量方法給出的其適用范圍和資源消耗情況。 Table 2 Comparison of unsupervised cross lingual word embedding learning methods based on BERT表2 基于BERT的無監督跨語言詞向量學習方法對比 基于BERT 的有監督跨語言詞向量學習方法通過豐富的對齊語料,實現從源語言詞向量到目標語言詞向量的遷移。但需要大量的標注數據或高質量的種子詞典。而基于BERT 的無監督的跨語言詞向量學習方法不需要任何監督數據,并證明部分無監督方法能獲得與有監督方法相媲美的結果,從而得到了許多研究者的青睞。表3 是對基于BERT 的有監督和無監督跨語言詞向量學習方法的大致歸納總結,表4 是按照訓練語料多少排序的跨語言詞向量模型。 Table 3 Comparison of cross-lingual word embedding learning methods based on BERT表3 基于BERT 的跨語言詞向量學習方法對比 Table 4 Cross-lingual word embedding model sorted according to the number of training corpus表4 按照訓練語料多少排序的跨語言詞向量模型 跨語言詞向量的質量評估,通常分為兩類:內在評估方法和外在評估方法[1]。內在評估是度量兩種語言詞向量的相似性,直接評估詞之間的語法、語義關系。其方法是:先用詞向量計算兩個詞對的余弦相似性值,然后計算其與人工標注的相似性值的斯皮爾曼等級相關系數。該方法雖然簡單、快速,但是存在幾個明顯的缺點:(1)人為標注的相似性值過于主觀;(2)數據集評估的是語義相似性而不是基于某個任務上的相似性;(3)沒有標準的分割;(4)詞向量在下游任務上的相關度不高;(5)沒有考慮詞匯的聚義現象[16]。外在評估是將訓練好的跨語言詞向量作為NLP 下游任務的輸入特征,通過下游任務的表現來評估跨語言詞向量的質量。 本文主要對基于BERT 的跨語言詞向量學習方法進行了介紹。按照詞向量訓練方法的不同,將其分為有監督學習和無監督學習兩類。在有監督的學習方法中,重點概述了基于詞對齊的跨語言詞向量學習方法,分為基于映射的學習方法、基于聯合學習方法、基于偽雙語語料學習方法。在無監督的方法中主要論述基于多語言BERT 的跨語言詞向量學習的方法和一些無需共享詞典和聯合學習的學習方法。在無監督跨語言詞向量學習方法中,一個典型的辦法是利用對抗性訓練[34]映射共享語義空間,但作者并沒有找到先用BERT 預訓練模型學習單語詞向量,再用對抗性訓練學習跨語言詞向量的方法。此外,跨語言詞向量映射的自學習[33]方法也是一種無監督的跨語言詞向量學習方法,但學習單語詞向量時并沒有用到BERT 模型。 跨語言詞向量將不同的語言映射到一個共享語言特征低維度稠密的向量空間,在不同語言間進行知識轉移,從而在多語言環境中能有效捕捉隱含在單詞上下文中的語法、語義信息。對于資源信息缺乏的語言,跨語言詞向量模型是一種研究方向,它能很好地學習跨語言詞向量表示。 蒙古文帶標注數據資源稀少,屬于低資源語言,無法構建成熟的動態蒙古文詞向量模型,構建基于BERT 的蒙漢文跨語言詞向量模型是一種研究方向,但同時伴隨著新的挑戰,需要進一步探索和研究,重點有如下問題亟待解決: (1)一詞多義的表達。蒙古文與土耳其文、日文、朝鮮文一樣,是一種粘著性語言,具有復雜的形態變化結構。在實際應用中常會有一詞多義現象。例 如,“這一句中兩個的含義不同,第一個是“頂”的意思,第二個是“頭”的意思,這句話的中文意思為“到了山頂后我頭疼了”。因而必須要考慮如何構建上下文語境敏感的動態詞向量模型和蒙古文復雜的形態變化結構。 (2)子詞的融合。BERT 模型的出現,將子詞級的信息納入跨語言詞匯表征的學習中,但學習蒙古文詞向量需要將這些子詞進行融合,需要考慮用什么樣的融合方法才能表達單詞的真實語義。 (3)多音詞。蒙古文有一些多音詞,一種形式對應多種拼寫、發音、意義,如這個詞有“hvta”“hvda”“hqta”“hqda”“hvte”“hvde”“hqte”“hqde”等8種不同拼寫方式,其中“hqta”(意思:城市)和“hvda”(意思:親家)是正確的拼寫(微軟輸入法鍵盤映射),但輸入者往往只關注它的形式而不關心其正確的鍵盤映射。“”這句話也會因這個的多義性產生歧義句“我來到市里的家了”和“我來到親家的家里了”兩個意思。這些問題在蒙古文中較常見,構建蒙漢文跨語言詞向量模型時需考慮進去。 (4)功能詞的表述。跨語言詞向量模型與其他單語詞向量模型一樣,對功能詞不太敏感,例如“給我一支筆”和“給我這支筆”。這種功能詞對跨語言對話系統中尤為重要,需要考慮進去。 (5)數據集的獲取。目前大多數跨語言詞向量模型都基于雙語詞典或平行數據,蒙古文屬于低資源語言,獲取這樣的數據集比較困難。一個重要的相關研究方向是在多語言預訓練模型的基礎上,用少量的平行數據進行微調。 (6)語言差異性。蒙古文和中文不屬于同一個語系,差異性較大。將兩種語言映射到一個共享語義空間還需要考慮語內翻譯和語際翻譯。語內翻譯多指詞對應翻譯,比較嚴謹,準確復現了原文本內容,語際翻譯偏向于意譯,更加靈活,也能體現出語言文化和語言表達方式的不同。因此模型的約束條件中,既要體現語內翻譯中詞匯的對應正確性,也要涵蓋語際翻譯中的文本語義一致性。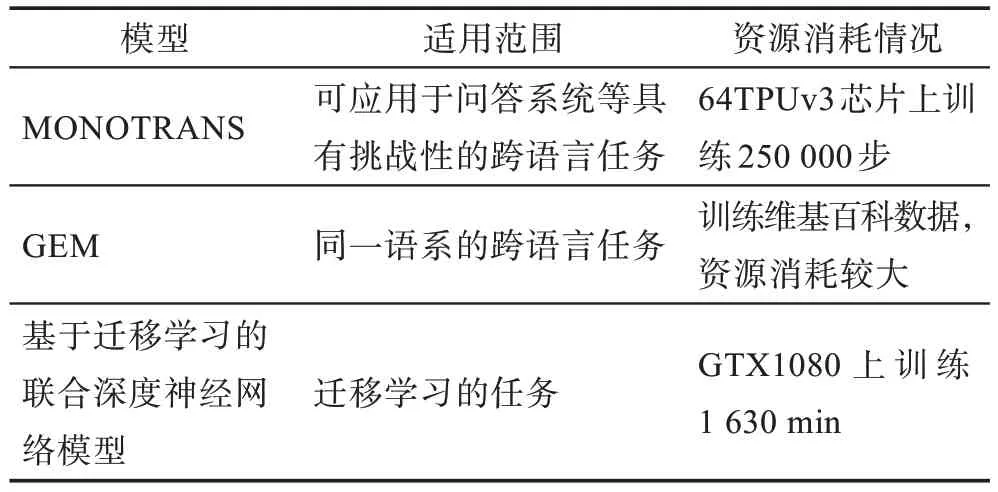
3.2 基于BERT 的有監督和無監督的跨語言詞向量學習方法的對比與分析

4 跨語言詞向量學習的評估方法
5 總結與展望
5.1 總結
5.2 展望
猜你喜歡
人大建設(2020年4期)2020-09-21 03:39:12
文苑(2020年4期)2020-05-30 12:35:30
開放教育研究(2020年2期)2020-03-31 01:54:14
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
現代語文(2016年21期)2016-05-25 13:13:44
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
大連民族大學學報(2015年2期)2015-02-27 08:28:11
