基于云計算的腦卒中預防康復與護理大數據平臺的設計與實現
2021-08-09 05:18:04王閏劉秋美張圓
新型工業化 2021年2期
王閏,劉秋美,張圓
(牡丹江醫學院附屬紅旗醫院,黑龍江 牡丹江 157011)
0 引言
腦卒中表現為高發病率、高致殘率、高病死率,嚴重的影響了患者的生活,成為社會發展的負擔。當前,我國醫療資源分布不均,對腦卒中的預防、康復、護理的全民參與存在一定的困難。心腦血管疾病80%是可預防的,積極控制危險因素和個體化治療是降低其發生的根本途徑[1]。通過預防、康復、護理等慢病管理模式和策略,降低發病率、病死率、病殘率是醫療健康發展的規劃目標。近些年來,大數據、人工智能、精準醫療等醫工結合技術快速發展,在衛生醫療領域發揮的作用越來越大。一些研究運用大數據技術于慢性高危疾病的評估及個體化干預、隨訪。國家衛生部于2009年起動了“國家腦卒中防治工程”并建立“中國卒中數據中心”[2]。在此基礎上,該中心建立涵蓋社區、鄉鎮、醫院門診與住院的多個數據庫,存儲500萬個篩查對象和高危人群的信息資料,為腦卒中的預防、康復、護理提供信息服務,充分利用大數據技術,為新醫療發揮作用。云計算技術是一種新興的計算模型,基于公開的標準和服務為基礎,以互聯網為中心,提供安全、快速、便捷的數據存儲與網絡計算服務[3]。在腦卒中智慧醫療服務中,基于分布式、并行處理、網格計算云端技術,應用腦卒中檢測方法與模式,連接臨床數據庫,開展腦卒中疾病的預防、康復、護理的干預,對于提高腦卒中患者的生活質量,降低腦卒中的病死率、發病率有重大的意義。
本文探討基于云計算的腦卒中大數據平臺的構建,為智慧醫療體系提供借鑒。
1 腦卒中大數據平臺構建需求分析
1.1 腦卒中大數據平臺的數據集成化、自動化、特征化
腦卒中數據來源于參與的醫院,數據采集須標準化與規范化。在采集過程中,須保證數據采集的自動化水平,即數據采集、交換、處理自動化,覆蓋完全化、數據大規模化、信息價值最大化[5-7]。因此,在腦卒中數據管理中,必須要制定嚴格的腦卒中數據標準,確保數據存儲過程中安全、穩定,為后續的腦卒中預防、康復、護理提供數據支持。腦卒中大數據分析要圍繞臨床質控、科研支撐、公共服務等目標。
1.2 腦卒中大數據特征化
腦卒中大數據平臺中的數據要具備一定的特征參量的提取能力,腦卒中的大數據來源多元化,包括患者影像數據、患者基本信息數據、家庭、社區等。數據既有結構化的也有非結構化、半結構化的,數據復雜;數據的使用需求既有決策使用、分析使用、開發使用等不同需求;數據類型也包括患者病史、用藥、各種體檢等信息數據。因此,數據必須進行清洗等處理,是按腦卒中大數據的特征參量化、結構化,使之能夠作為數據分析的目標。
1.3 用戶需求分析
基于云計算的腦卒中預防、康復、護理醫療服務大數據平臺使面向腦卒中個體化信息服務的系統,用戶主要是患者(家屬)、醫療機構、平臺管理員。患者用戶在使用大數據應用平臺中獲取康復過程中的幫助信息,更好的為身體康復服務;醫療機構人員在使用大數據平臺過程中,實現智能診斷服務,精準醫療服務[4];系統管理員是維護系統正常運作的工作人員,系統管理員可對系統的使用權限予以設定、對系統的平穩運行實施技術維護。
2 腦卒中大數據平臺的設計
2.1 平臺系統架構
每天各個醫院、社區、家庭、個人都會產生海量醫療信息數據,為保障腦卒中大數據平臺的數據共享與協同訪問,對腦卒中大數據平臺有嚴格的技術要求:并發處理能力、并發訪問能力。傳統的關系型數據庫無法滿足大規模、高頻率的數據存儲與訪問,基于腦卒中大數據分析的海量數據存儲與處理要求,本系統架構采用Hadoop分布式框架,以HBase數據庫作為腦卒中大數據存儲系統,本系統架構如圖1所示。
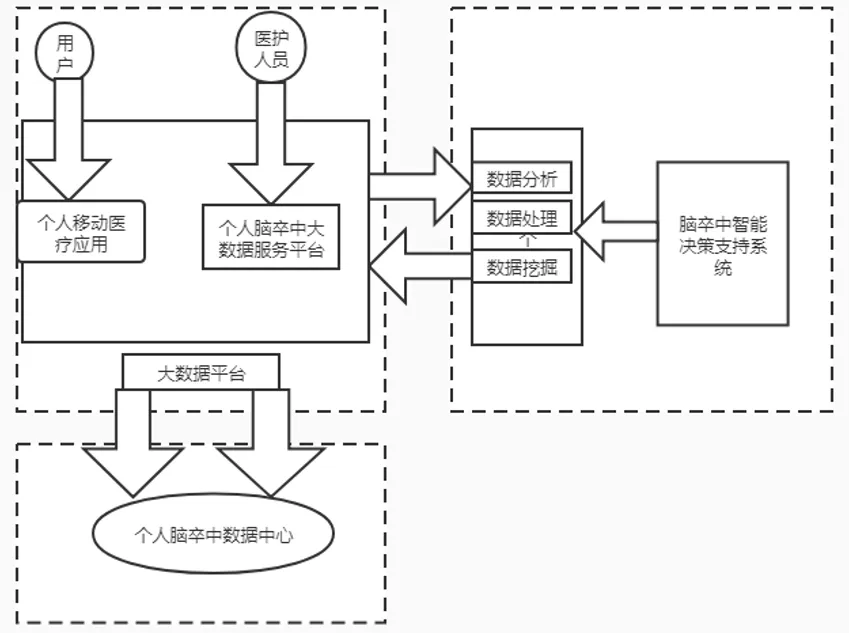
圖1 系統架構圖
2.2 數據庫設計
傳統的關系型數據庫無法滿足大規模、海量數據的存儲處理要求,采用HBase數據庫可解決海量數據的讀取、存儲瓶頸問題。利用基于Hadoop云計算的分布式系統集群優勢實現大數據的并行計算[5-8]。數據庫需要高效的存儲讀寫策略,存儲管理技術中涉及數據結構化、半結構化、非結構化的集成統一管理。
數據庫的數據結構模型采用衛生部《城鄉居民健康檔案基本數據集》規定的數據元素。應用規范化、一致性的數據劃分原則,實現完善的個人健康數據中心,合理的為醫院、社區、家庭、個人數據交換、共享和深入數據挖掘提供基礎服務。根據衛生部《城鄉居民健康檔案基本數據集》的信息,確立數據元模型,如表1所示。

表1 數據元模型
2.3 數據傳輸協議與接口設計
由于數據來源于不同醫療機構、家庭、個人,不同機構的數據庫采用的表結構不同,因此,為便于數據庫的可擴展性、數據庫之間異構差異透明傳輸,本大數據平臺采用SOAP訪問協議,采用SOAP Web Service技術實現同步傳輸。接口設計需著眼于數據傳輸的同步性實現。用戶可用的業務邏輯接口需要實現從醫療機構-大數據平臺的數據同步傳輸。腦卒中數據挖掘過程需要平臺使用者與平臺
3 腦卒中大數據平臺的分析系統
腦卒中患者的數據信息海量存儲、交換、分析,為腦卒中預防、康復、護理等醫療服務提供決策支持,系統平臺的數據分析處理技術主要包括大數據的預處理、數據挖掘算法、數據分析接口等技術。
3.1 大數據的預處理
腦卒中數據來源多元化,數據結構復雜化、多樣化,既有結構化數據,也有非結構化數據,也有半結構化數據,此外,數據還具有多樣性、動態性等參量特征。腦卒中的數據挖掘分析需要對腦卒中的大數據進行清洗、去除空缺、去除噪聲數據,完成數據文本、數值與預定義的掩碼相一致。
3.2 數據挖掘處理算法
腦卒中數據挖掘算法即數據的分類算法涉及聚類、分類等技術,應用數據挖掘技術實現腦卒中的數據聚合與分類[6-10]。基于腦卒中數據挖掘技術完成數據的分析過程,構建數據篩查、腦卒中患者的治療模型,圍繞特定的目標人群和醫院、個體化的康復、預防與護理服務。應用統計學分析中的關聯、回歸、神經網絡、機器學習等算法技術,尋找腦卒中數據中的參量特征相關性、關聯性,應用異常檢測、預測、關聯分析,實現多維度、組間數據中的關系,為腦卒中患者的預防、康復、護理提供智能決策診斷服務。
4 結論
本文對應用數據挖掘技術的腦卒中預防、康復、護理醫療服務大數據平臺構建研究,研究中初步研究了系統需求、系統架構、關鍵技術[11-13]。基于云計算的腦卒中預防、康復護理醫療大數據平臺的實現,最終可為腦卒中的醫療服務提供幫助。
隨著我國人口老齡化的進程加快,腦卒中發病率越來越高,如何利用現代化智慧醫療技術,提高腦卒中患者的智能化診療水平,控制腦卒中患者的發病機會和提高康復水平,是我國醫療服務的重要研究方向。基于云計算的腦卒中預防、康復、護理醫療大數據服務平臺,在優化醫療服務、促進我國健康信息服務和智能化水平發揮重要的作用。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
特別健康(2018年2期)2018-06-29 06:13:44
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
信息通信技術(2015年6期)2015-12-26 01:16:46
中國衛生(2014年6期)2014-11-10 02:30:50
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:33:14
