模糊先驗引導的高效強化學習移動機器人導航
2021-08-31 02:42:44劉浚嘉謝榮理
機械與電子 2021年8期
劉浚嘉,付 莊,謝榮理,張 俊,費 健
(1.上海交通大學機械系統與振動國家重點實驗室,上海200240;2.上海交通大學醫學院附屬瑞金醫院,上海 200025)
0 引言
經過機械、電子、控制、計算機等領域長達數十年的發展,機器人在服務行業的應用逐漸興起。與工業界中的情況類似,日漸高昂的人工成本以及老齡化等社會問題,極大地增加了人們研究與開發服務機器人的熱情。服務機器人相較于較成熟的工業機器人,具有多任務、非結構環境和安全可靠等復雜要求[1]。盡管基于現有技術設計的服務機器人還遠不能滿足人們對美好生活的向往,但已經引領了社會與人類生活的新潮流。
要想使服務機器人走進家庭,就要使其具備主動完成人類指定任務的能力。在現有技術支撐的前提下,一個可行的任務就是在復雜房屋中高效地到達人類指定的目標位置。高效準確的主動目標導航是一切服務的基礎,因此,人們對移動服務機器人的自主導航能力有更高的要求。移動服務機器人需要能夠根據周圍環境的變化采取相應的措施來提高移動機器人的避障、導航能力。此外,考慮到成本因素,應僅使用RGB-D傳感器完成上述要求[2]。因此,研究者們逐漸對將強化學習算法與機器人導航方法相結合產生興趣,旨在以學習的方式使機器人能夠通過與真實環境交互,自主探索并學習得到完成任務的最佳策略。
1 數據高效強化學習算法
深度強化學習(deep reinforcement learning,DRL)在游戲與棋類任務中的成功,是建立在使用大量數據對大型神經網絡進行訓練之上的,也就是使Model-based RL(MBRL)算法也具有這一特性。目前,先進的智能體通常都具有很高的樣本復雜度,以近期在游戲中性能最強的幾種算法為例,MuZero[3]和Agent57[4]在每場Atari游戲中,均需要借助10~50年的經驗,OpenAI Five[5]更是利用了相當于人類45 000年的經驗來實現其卓越的性能。這些都是在模擬環境中通過大規模顯卡(GPU)與CPU集群的并行訓練才實現的。在現實中,這顯然是不切實際的,與虛擬環境中的游戲不同,許多顯示任務收集交互數據的成本很高,高頻、高強度的交互甚至會導致系統的損壞,這在機器人領域是格外值得關注的。此外,從仿生學角度來講,這種利用大規模數據進行并行學習的方式也不符合人類學習的直覺,相比之下,人類近乎單線程的學習是十分高效的,通常可以僅通過很少的例子就掌握相關知識。要想DRL算法能夠大規模應用到機器人的智能控制中,提高數據效率成為不可避免的技術路線[6]。
導致DRL算法數據利用效率低的原因有很多,Yu[7]列舉了影響數據效率的5個方面:探索策略、優化方法、環境模型學習、經驗遷移與抽象化。本文結合這篇文章的觀點,將影響因素總結為以下幾點:
a.探索策略。常用的ε-greedy和Gibbs采樣等基礎探索策略是比較盲目且低效的。
b.環境模型學習。MBRL相較于Model-free RL(MFRL)在策略學習的同時,利用同一組數據學習一個環境模型,會在數據的利用效率上有所提升。
c.狀態與動作空間維度。DRL算法是將深度學習技術應用于傳統強化學習的函數擬合與優化中,而神經網絡的參數量和擬合能力與輸入輸出維度成指數級相關性,維度越高,神經網絡所需的參數量越多,擬合難度越大。
目前對高效強化學習的研究主要從2個方面入手:引入概率神經網絡或專家先驗的軟約束。MBPO[8]是一種以貝葉斯神經網絡為擬合工具的MBRL算法,將模型的誤差以概率的形式考慮到策略的學習中,使其不完全依賴模型對未來狀態預測,從而實現策略在可信區間內的魯棒預測學習;此外,也可以通過引入專家示范作為軟約束,從不完美的示范數據中得到大致的探索方向[9],從而對強化學習的策略學習起到引導作用。二者均能夠提高訓練數據的利用效率,從而加速學習進程。
2 模糊先驗引導的數據高效強化學習算法
2.1 融合控制框架
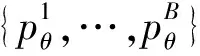
(1)
MBPO采用Soft Actor Critic (SAC)[10]作為其策略優化算法,SAC在每一次策略估計時,估算值函數為
(2)
作為動作的評價指標,并在策略提升環節通過最小化期望KL散度Jπ(φ,D)=Est~D[DKL(π|exp{Qπ-Vπ})]來訓練策略。本文在其基礎上,結合先驗知識,提出了能夠有效避免無意義探索的融合控制器,如圖1所示。
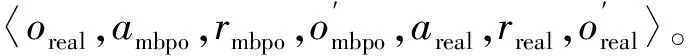

圖1 模糊先驗引導融合控制框架
(3)
(4)
IPK的動作可以確保機器人以很大概率避開障礙物,并且避免在訓練的初期在與目標方位完全相反的方向進行無意義的探索,而MBPO子系統仍可以在IPK的先驗安全約束下,以一定程度的精度改進整體的融合策略。因此,上述融合控制器就實現了學習過程中的安全探索。此外,它實現僅通過1次交互,而獲得2種不同的經驗,這顯然會比單純的MBPO更加高效。
2.2 先驗與強化學習的融合方式
在初始化探索過程之后,MBPO將以高斯策略作為主要學習策略,該策略輸出符合高斯分布的動作分布均值和方差。相應地,IPK子系統也進入了新的階段:融合控制器。盡管MBPO通過僅查詢短期推出的模型來解耦任務范圍和模型范圍,但是它仍然受到達到目標的可能性的限制,尤其是在稀疏獎勵問題中。由于IPK的基礎控制器是基于規則的,因此,可以很方便地為其評估性能,從而形成了解決稀疏獎勵問題所提倡的內在激勵。從初始Replay Buffer及其任務長度的記錄中,可以將數據還原為完整格式。在每個時間步上,都可以得到動作前后的目標向量,然后可以容易地估計出每個動作與預期方向的偏差。這些偏差可以描述為高斯分布。此外,SAC的原始行為也是高斯分布。因此,需要提出一種可行的方法,能夠將這2種有用的信息同時應用起來。
一個非常樸素的想法就是將基本控制器輸出的高斯分布與SAC動作分布融合在一起。卡爾曼濾波器是一種融合多個傳感器的測量信息,且比任何一個傳感器都更準確的常用方法。如圖2所示,本文使用卡爾曼濾波器對2個控制器的輸出進行融合,并獲得新的融合分布。此過程在SAC的重參數化技巧之前進行。
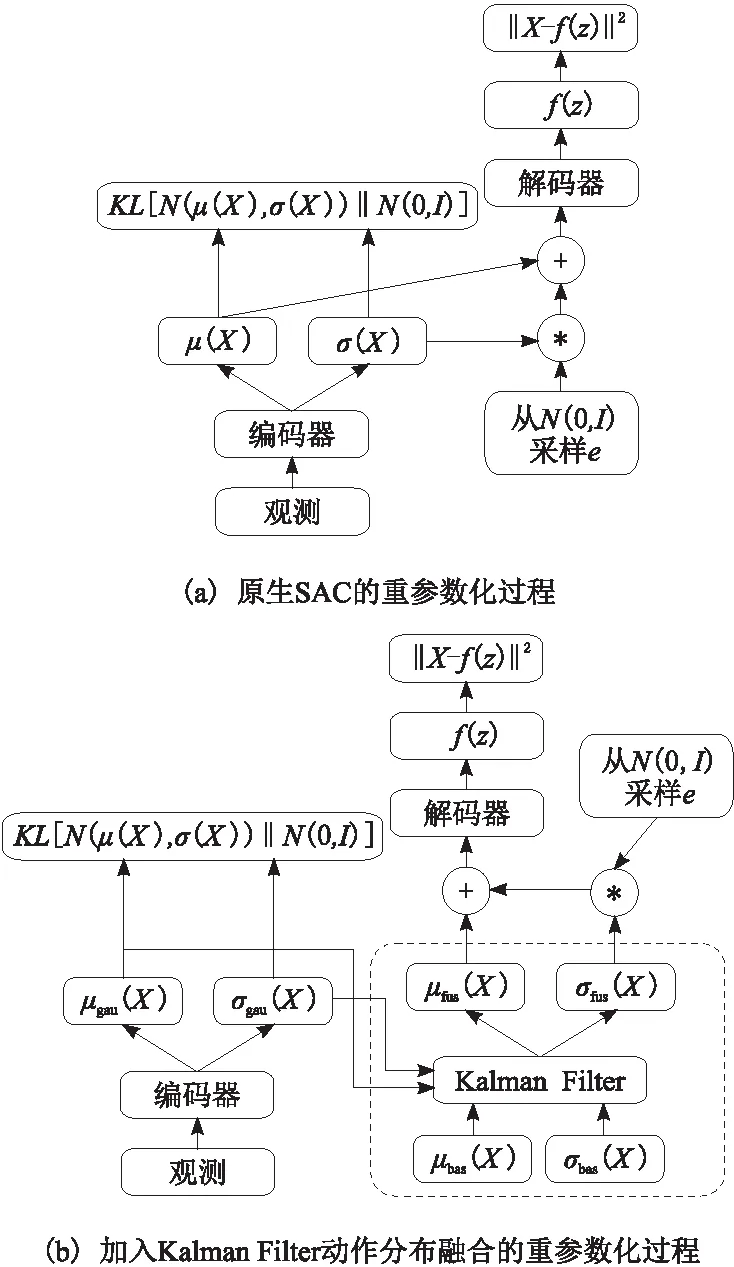
圖2 模糊先驗引導融合控制器的動作分布融合原理與原生SAC的比較
(5)
(6)
3 實驗驗證
3.1 分布式DD-PPO強化學習點導航基準
針對強化學習以及所提出的數據高效強化學習控制器的仿真性能驗證,本節采用Matterport3D[11]以及AI Habitat2020挑戰賽中的PointNav[12]任務作為控制器算法的評價標準,并在Habitat[13]模擬器中繼續實驗。PointNav任務使用了成功率、sPL和DTS(distance to goal)的評價指標。sr表示在多次實驗中找到目標的概率,定義為
(7)
N為總實驗次數;Sui為一個二進制值,表示第次實驗的成功或失敗。sPL同時包含了對成功率和路徑長度的考量,定義為
(8)
在第i次實驗中,本文使用模擬器提供的最短路徑長度作為Li,而機器人的路徑長度為Pi。DTS是每次實驗結束時,智能體到目標物體邊界的距離,也是機器人離任務成功的距離。
本節復現了Habitat挑戰賽官方給出的基線算法——DD-PPO[14]。該算法以PPO(proximal policy optimization)[15]為核心,對其訓練方式進行了更改,以實現去中心化的分布式PPO(decentralized distributed,PPO)。DD-PPO利用分布式數據并行地將PPO無縫擴展到數百個GPU組成的服務器集群。這些GPU集群是完全去中心化的,不含有中央服務器,這種做法可以使分布式算法不受集群規模限制。去中心化分布式的具體實現方式是將每一個Worker的參數使用PPO計算策略梯度,并將這些梯度分享給其他Workers,即
(9)
由于該算法的官網沒有給出專門針對Matterport3D數據集的預訓練模型參數,本文只能依靠現有設備進行復現。通過使用2塊Nvidia GTX 2080Ti顯卡,分布式運行6天、共計超過70 M(百萬)步。經過長時間的訓練,即使僅使用2塊顯卡也可以得到不錯的效果。其中,DTS最后達到1.2 m左右,即機器人在任務終止時到目標點的平均距離是1.2 m;sr和sPL分別達到了約83.7%和0.68。很明顯,該結果還并未完全達到收斂,但考慮到時間成本與算力限制,本文只能將這個結果作為數據高效強化學習的對比。由于對比更加關注訓練效率、速度,因此并不影響本文得到正確且合理的結論。
3.2 模糊先驗引導的高效強化學習
本節使用與DD-PPO相同測試環境與作圖方式,旨在展示本文所提出的數據高效強化學習算法的高效性。圖3展示了引入模糊先驗引導的Model-based算法、原生的MBPO算法以及分布式DD-PPO算法對比。表1整理了3種算法對應的收斂位置時的累積回報與訓練時長。本文所使用的模糊先驗,或稱作基礎控制器,正是上一節訓練得到的DD-PPO模型。然而,與現有的遷移學習方法不同,本文以融合的方式使新的強化學習控制器能夠在具備一定性能的基礎控制器引導下,加速學習進程。值得強調的是,該基礎控制器還可以使用調參后的TEB等傳統無圖點導航方法,甚至可以僅給出一些顯而易見的避障規則。
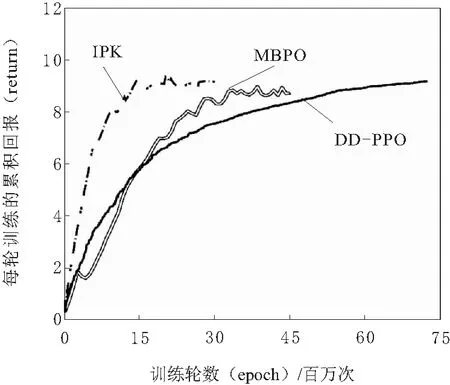
圖3 模糊先驗引導的數據高效強化學習的性能對比

表1 3種算法收斂位置時的累積回報與訓練輪數
由圖3的對比結果可知,Model-based的強化學習方法相較于普通的Model-free方法確實有數據高效的優勢,符合理論預期。而本文提出的模糊先驗引導的IPK算法,能夠較另2種方法大幅提升訓練速度,相當于在一名知識水平尚可的教師指導下學習。IPK是DD-PPO先驗與Model-based的MBPO算法的融合,其出色的訓練速度是建立在二者基礎上的,因此能得到這樣的效果并不意外。當然,這其中也有本文所提出的融合方式的貢獻。在具體的實驗中,作為模糊先驗基礎控制器的DD-PPO首先進行初始化探索,通過模擬器的反饋,對自身性能以及動作誤差有大致的了解。將這種誤差考慮到后續的動作輸出中,使其以高斯分布的形式輸出動作的概率分布。再將MBPO的高斯概率輸出,與該基礎控制器輸出分布進行動態Kalman融合,即得到融合動作分布。對該分布進行采樣,其結果即為融合動作。顯然,該融合動作收到模糊先驗基礎控制器的軟約束,同時也保證了MBPO學習控制器能夠在這個安全限制下進行充分的探索。
4 結束語
本文所提出的數據高效強化學習控制器具有以下特點:
a.能夠以概率的形式融合先驗,使強化學習的策略學習建立在一定先驗知識的及基礎上,實現高效訓練。
b.強化學習的自主探索受到先驗控制器的軟約束,確保了機器人在自主探索時的安全性。
c.實際的動作是由融合控制器輸出的,提升了控制系統的魯棒性。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
