基于多級語義的判別式跨模態哈希檢索算法
2021-09-09 08:09:18劉芳名
計算機應用 2021年8期
劉芳名,張 鴻
(1.武漢科技大學計算機科學與技術學院,武漢 430065;2.智能信息處理與實時工業系統湖北省重點實驗室(武漢科技大學),武漢 430065)
0 引言
隨著網絡的應用和普及,多媒體數據在信息交互過程中急劇增長,這些多媒體數據種類多樣、數量龐大,通常表達形式各異但描述的是同一事物[1-2]。現實中用戶在查找某一個事物的相關信息時,渴望返回的結果有價值且全面豐富。因此,實現從一種模態數據(如文本)檢索出其他的模態(圖像或音頻)中與之相關數據的跨模態檢索得到研究者的關注。由于數據的規模和維度的增長,對大規模數據集的檢索時,大部分的跨模態檢索方法遭受到高昂的存儲代價和時間損耗。跨模態哈希能夠將高維度數據映射為緊湊的二進制哈希碼并保留數據之間的相關性,此外跨模態哈希采用哈希碼表示高維數據,在降低檢索時間的同時提高了檢索效率。因而跨模態哈希逐漸成為研究熱點,盡管跨模態哈希檢索方法不斷突破,但是由于跨模態數據表達不一致導致的異構鴻溝[3]和不同類型數據在語義描述上存在差別所導致的語義鴻溝[4]是跨模態哈希檢索的難點。
為了解決跨模態數據間的異構鴻溝,一些無監督哈希方法通過潛在的語義信息學習統一哈希碼。盡管消除了異構差異,但是缺乏標簽語義監督信息,不能較好地提高檢索性能。有監督的跨模態哈希方法,如文獻[5]提出的判別性跨模態哈希(Discriminative Cross-modal Hashing,DCH)算法將標簽信息嵌入到哈希碼學習過程使得類內數據彼此靠近,但明顯忽略了數據類間關系。其他大多數方法[6-8]僅關注了跨模態數據類間關系,卻不能聚合類內數據。生成對抗網絡(Generative Adversarial Network,GAN)[9]可以學習數據的真實分布,為了保持數據原始的分布關系,最近許多基于此的跨模態檢索算法被提出。其中生成對抗網絡的半監督跨模態哈希(Semi-supervised Cross-modal Hashing by Generative Adversarial Network,SCH-GAN)[10]在生成對抗網絡基礎上利用強化學習,設計能使用未標記數據相關性分布信息的生成對抗模型,有效提高了半監督跨模態哈希的準確性。引用標簽信息和GAN中對抗思想的自我監督的對抗式哈希(Self-Supervised Adversarial Hashing,SSAH)[11],最大化跨模態語義相關性和不同模態之間的一致性表示。
為了在保留類間關系同時能夠進行類內聚合,文獻[12]中提出的平等指導判別式哈希(Equally-Guided Discriminative Hashing,EGDH)關注語義結構和判別性之間的聯系,使得最終學習到的哈希碼在保留語義相關性的同時具有判別性,實現較高的跨模態檢索精度。然而EGDH算法中采用的是0/1二值相似度矩陣監督信息來指導函數學習,多標簽中豐富的語義信息被忽略了,也使得學習的哈希碼中語義關聯信息減少,降低跨模態檢索精度。
針對判別性哈希碼不能充分聚合類內數據,以及二值相似度矩陣不能包含充足的語義相關信息的問題,本文提出一種基于多級語義的判別式跨模態哈希檢索算法——ML-SDH(Multi-Level Semantics Discriminative guided Hashing)。該算法構建了保留標簽之間的多級語義關聯的多級相似度矩陣,充分利用多標簽類別中有價值的語義關聯信息;同時實現語義結構的保留與判別性哈希碼學習兩者的結合,將哈希學習和多級語義學習嵌入到一個完整的深度學習框架中,探究基于哈希的檢索和分類之間的聯系。通過上述方式保證了該算法學習到的哈希碼不僅具有豐富的多級語義信息,而且能夠更好地凸顯出跨模態數據之間的判別性。實驗結果表明本文算法能夠有效提高跨模態檢索準確率。
1 相關工作
跨模態哈希檢索在建立語義關聯的過程中學習哈希碼,并將哈希檢索的優點運用到跨模態檢索問題中,在大規模的跨模態檢索任務中得到研究者們的關注。目前,跨模態哈希檢索方法可分為無監督方法和有監督方法。
無監督哈希方法從未標記數據的分布中學習哈希函數。傳統的無監督哈希方法,將跨模態數據投影到漢明空間學習相似的哈希碼,如文獻[13]中提出的跨模式相似性敏感哈希(Cross-Modality Similarity-Sensitive Hashing,CMSSH)檢索算法,將哈希函數的學習當成一個二元碼分類問題,最后利用boosting算法來進行求解,學習了相似的哈希碼,但是檢索時間較長。因而學習統一哈希碼的跨模態檢索方法[6-9]被廣泛應用。其中文獻[7]提出的協同矩陣分解哈希(Collective Matrix Factorization Hashing,CMFH)算法使用協同矩陣分解求解公共的潛在語義空間,再根據共同的潛在語義學習統一的哈希碼。雖然減少了檢索時間,但是缺少監督信息,檢索精度也不高。
有監督哈希方法使用帶標簽訓練數據的語義監督信息,比無監督哈希方法提高了檢索進度。文獻[14]使用的語義相關性最大化(Semantic Correlation Maximization,SCM)跨模態檢索算法,結合標簽信息最大化數據的相關性。在文獻[15]中的語義保留哈希(Semantics Preserving Hashing,SePH)使用標簽信息構造一個親和力矩陣,并通過該矩陣的概率分布建模生成統一的哈希碼。成對關系指導的深度哈希(Pairwise Relationship guided Deep Hashing,PRDH)[16]使用成對跨模態數據的關聯信息指導哈希碼生成。以上這些方法僅關注了跨模態數據間關系或跨模態內數據關系,無法在保持多級語義結構的同時提高哈希碼的判別性。本文提出的跨模態哈希檢索模型,使用多級語義指導分類器,在探究哈希碼的語義信息與判別性之間的聯系的同時,能夠指導其他跨模態數據學習保持語義相似性和判別性的統一哈希碼,從而實現跨模態哈希檢索。
2 多級語義的判別式哈希表示
本文提出的基于多級語義的判別式跨模態哈希檢索算法的框架如圖1所示。為了充分使用標簽中的語義信息,首先,本文提出多級語義標簽矩陣;接著利用該多級語義標簽矩陣構建多級語義指導分類器;最后使用該分類器指導不同模態數據學習各自的哈希函數。
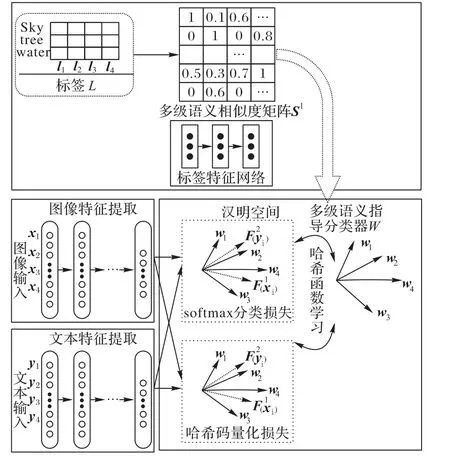
圖1 基于多級語義的判別式跨模態哈希檢索算法框架Fig.1 Framework of cross-modal retrieval based on multi-level semantic and discriminative hashing
2.1 基于多級語義的哈希表示



表1 符號定義Tab.1 Symbol definition
使用標簽中的多級語義信息學習語義指導向量,并建通用分類器W。在這個過程中,相似度損失與文獻[3]提出的基于深度語義相關學習的哈希(Deep Semantic Correlation learning based Hashing,DSCH)算法中相同。標簽網絡的多級語義損失函數計算如下:

第二項為哈希碼量化損失,最后一項保證學習到的哈希碼正負值均衡分布。式(8)離散優化后的哈希碼W是蘊含多級語義的哈希表示。
2.2 分類和多級語義哈希檢索
跨模態數據中的語義信息是實現基于哈希檢索的關鍵,多級語義相似度哈希碼中蘊含了跨模態數據中豐富的語義信息,有助于實現高效的跨模態檢索。判別分類方法將哈希碼當作可區分的特征,使得最終的哈希碼具有判別性。語義相似度矩陣中蘊含了語義相關信息,可用于實現基于哈希的檢索,分類器可以用于數據保持判別性。因此,實現判別性和語義關聯相結合就是實現分類和基于哈希的檢索相結合。


算法1總結了多級語義的判別式跨模態哈希檢索算法。整個算法過程分為兩部分:多級語義結構的分類器W的學習和跨模態數據哈希函數F1(θ2;xi),F2(θ3;yj)的學習。也就是需要優化θ1、θ2、θ3。根據語義相似度損失函數J1和反向傳播算法更新θ1。根據式(6)計算wm更新W。依據更新的W和式(11)、(12),使用反向傳播算法分別更新θ2、θ3。
算法1 基于多級語義的判別式跨模態哈希檢索算法。
輸入:訓練樣本文本數據X,圖像數據Y,標簽L,哈希編碼長度c,參數λ、γ、μ、η,學習率r1、r2、r3。
輸出:文本和圖像數據學習哈希函數過程中的超參數θ2、θ3,哈希碼H1、H2。
1)隨機初始化超參數θ1、θ2、θ3
2)重復
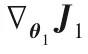
②根據式(8)計算wm并更新W。
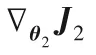
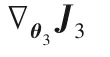
3)直到收斂
4)根據式(13)和式(14)計算,輸出H1、H2。
3 實驗與結果分析
為了驗證本文算法的有效性,本文在NUS-WIDE和mirflickr-25k兩個基準數據集上進行實驗,并和跨模態檢索算法CMFH[8]、SCM[14]、SePH[15]、DCMH(Deep Cross-Modal Hashing)[11]、PRDH[16]、EGDH[12]進行兩個跨模態檢索任務的實驗比較:圖像檢索文本、文本檢索圖像。
3.1 數據集描述
mirflickr-25k數據集[17],包含25 000個數據樣本,每個樣本中包含圖片文本標簽對,每個樣本被標注成24種語義概念中的多種類別,這些樣本都是多標簽數據。與DCMH[9]一致,本文也刪除mirflickr-25k中無標簽數據,保留20015個帶標簽的數據樣本作為實驗數據集。其中每個樣本文本模態用1 386維詞袋(Bag-of-Words Vector,BoWV)向量表示。
NUS-WIDE數據集[18],最初包含269 648個樣本實例,同樣是多類別標簽數據樣本集合,每個實例都是帶有標簽的圖像,都使用81個類別的標簽進行標注。本文與DCMH[11]類似,選用前10個最常用語義標簽的186 577個帶標簽的圖像文本實例樣本對作為的數據集。每個樣本數據文本模態用2 000維BoWV向量表示。
在mirflickr-25k數據集上進行實驗,隨機選取5 000個樣本作為訓練集,2 000個數據對作為測試集,其余的樣本作為驗證集。在NUS-WIDE數據集上進行實驗時,同樣隨機選取5 000個樣本作為訓練集,選用2 000個樣本對作為測試集,其余的樣本作為驗證集。
為了與基于淺層結構的CMFH、SCM、SePH哈希方法公平比較,在實驗中使用由預訓練的快速卷積神經網絡模型(Convolutional Neural Networks Fast,CNN-F)[19]網 絡 提 取 的4 096維圖像特征作為基于淺層結構的方法的圖像輸入數據。
3.2 參數設置
標簽特征網絡由三層前饋神經網絡組成:第一層為輸入層;第二層包含4 096個神經元;最后一層神經元個數與哈希碼bit位數相同,標簽網絡的輸出用于構建多級語義指導分類器。圖像特征網絡與CNN-F結構相同,只將最后一層神經元個數改為c,并將激活函數設置為tanh函數。和大多數使用深度網絡框架實現跨模態檢索的方法相同,本文使用在ImageNet[20]數據集上進行預訓練的CNN-F前七層初始化圖像特征提取網絡。文本網絡由三層神經網絡構成:第一層為輸入層,第二層包含4 096個神經元,最后一層神經元個數與哈希碼位數相同。
將學習率r1、r2和r3設置為10-6~10-2,θ1、θ2、θ3參數隨機初始化。在文本檢索圖像和圖像檢索文本檢索任務中,將哈希碼長度選取為16 bit、32 bit、64 bit不同位數時,分別與其他對比算法的檢索結果進行比較。
3.3 評價標準
跨模態哈希算法的檢索性能使用平均準確率(mean Average Precision,mAP)、topK-precision曲線和查準率查全率(Precision-Recall,PR)曲線評估。mAP和topK-precision曲線用于測量漢明排序準確度,漢明排序是根據查詢數據和檢索集中數據的漢明距離進行排序。mAP衡量所有查詢樣本的平均檢索精度,是平均準確率(Average Precision,AP)的均值,可以被定義成如下:

其中:R表示輸入查詢數據后檢索到的樣本個數,Q表示被檢索到的數據中與查詢數據相關的樣本總數,M(r)表示被檢索到的數據中前r個結果的準確率,δ(r)表示第r個數據是否與查詢數據相關。PR表示查準率和查全曲線。topK-precision曲線用于測量返回的前K個數據準確率。
3.4 實驗結果分析
參數λ、γ、μ、η一般設置為1,不做進一步對分析。本文將對其做敏感性分析,讓超參數分別從{0.001,0.01,0.1,1,2}中選取不同值進行實驗,某一參數進行實驗時,其他參數將固定其取值。圖2是在mirflickr-25k數據集上,哈希碼長度被設為16 bit時,超參數λ、γ、μ、η從{0.001,0.01,0.1,1,2}中選取不同值的mAP的曲線。
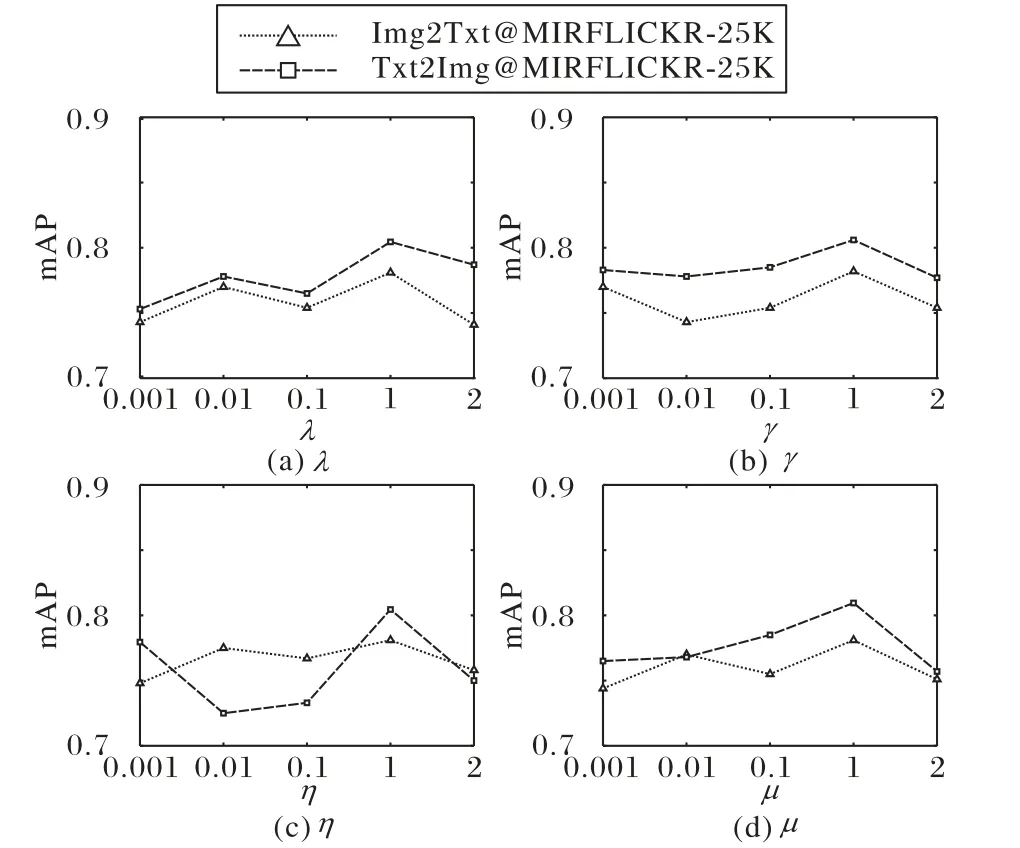
圖2 參數分析Fig.2 Parameter analysis
分析圖2,發現超參數取值在[0.01,2]區間時,取得更好的效果,此時圖像和文本模態數據量化生成的哈希碼保留了更多的語義信息以及判別性。通過以上分析能夠發現參數在[0.01,2]內,mAP值結果不敏感,也就是此時已經具有較好的性能,因而實驗將超參數λ、γ、μ、η均設置為1,可以證明實驗結果的正確性。
表2和表3展示了在mirflickr-25k和NUS-WIDE數據集上進行兩個跨模態檢索任務,當哈希碼長度選取不同位數時,各種檢索算法的mAP值。在選取不同長度的哈希碼時,本文算法的mAP值都比其他對比算法的檢索結果有提升,說明本文提出的算法確實提高了檢索性能。
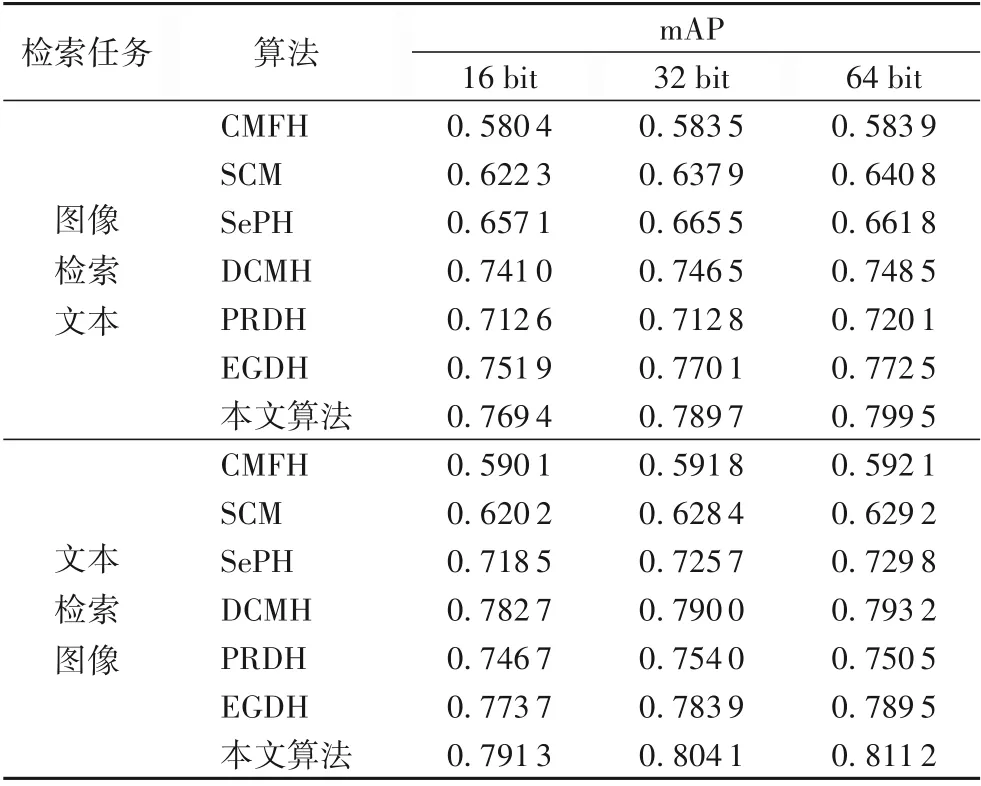
表2 在mirflickr-25k數據集上各算法的mAP值Tab.2 mAPof different algorithmson mirflickr-25k dataset
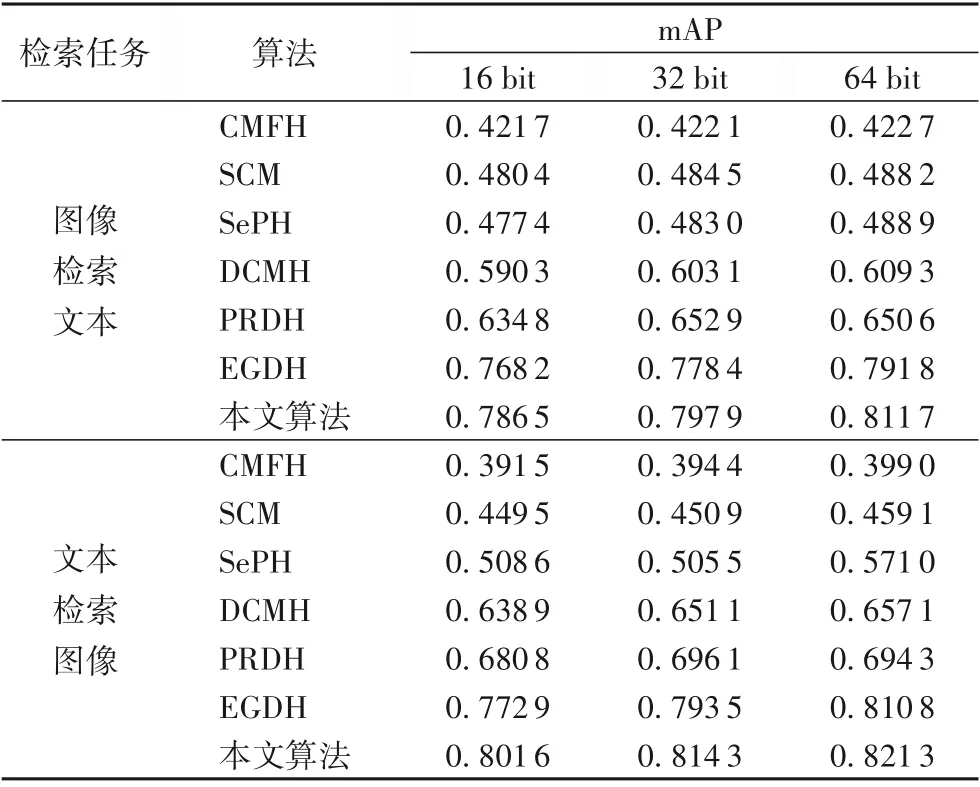
表3 在NUS-WIDE數據集上各算法的mAP值Tab.3 mAPof different algorithmson NUS-WIDE dataset
與基于淺層結構的哈希算法(CMFH、SCM、SePH)相比,本文算法的mAP值明顯較高。這是因為深層結構在特征提取方面具有更好的性能。與PRDH比較,本文算法在兩數據集上的mAP值明顯增長5%以上,因為本文構建的語義結構和判別性分類之間的聯系,對于聚合類內數據和保留完成的語義結構起到了作用。與沒有使用判別信息的算法(CMFH、SCM、SePH、DCMH)相比較,本文算法的性能明顯提升,這是因為本文算法學習的哈希碼具有更好的語義判別性能,實驗結果表明本文提出的算法具有更好的優越性。與EGDH相比,本文算法在mirflickr-25k和NUS-WIDE數據集上mAP增長幅度從1.05%到2.87%。在兩個數據上的進行兩種檢索任務時實驗結果表明:本文算法的平均準確率的均值比DCMH、EGDH算法將高出2.73%、18.1%、1.15%和1.96%,與PRDH比平均分別高出了6.14%、13.7%。因為本文算法使用了多級語義信息,而語義信息是提升跨模態檢索性能的關鍵,實驗結果也證明了本文算法的有效性。
圖3給出了在哈希碼長度設為32 bit時,各對比算法在mirflickr-25k數據集上對于圖像檢索文本和文本檢索圖像任務的PR和topK-precision曲線。從最終的實驗結果可以發現,在任一個檢索任務中,本文提出算法的PR曲線(六角星曲線表示)都位于其他算法的右上方,說明本文算法的查準率、查全率均優于其他對比算法。本文提出算法的topK-precision曲線位于其他算法的上方,說明使用本文所提出算法進行跨模態檢索的結果中,檢索結果的前K個數據與查詢數據相關的準確率更高。
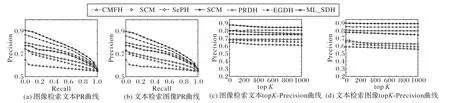
圖3 在mirflickr-25k數據集上哈希碼長度為32時PR曲線和top K-precision曲線Fig.3 PR curvesand top K-precision curveswith hash code length of 32 bit on mirflickr-25k dataset
圖4展示了在哈希碼長度設為32 bit時,各對比算法在NUS-WIDE數據集上對于圖像檢索文本和文本檢索圖像任務的PR和topK-precision曲線。從實驗結果可以總結:本文算法比其他算法檢索的結果具有更高的檢索精度。本文算法的topK-precision和PR曲線均在最上方(六角星曲線表示),表明本文算法在漢明排序和進行哈希查找時明顯優于具有代表性的其他算法。這是因為在大規模數據集上,本文算法仍可以在保持類間多級語義關系同時又能聚合類內數據,減小了哈希碼的種類數,提高跨模態檢索的性能。
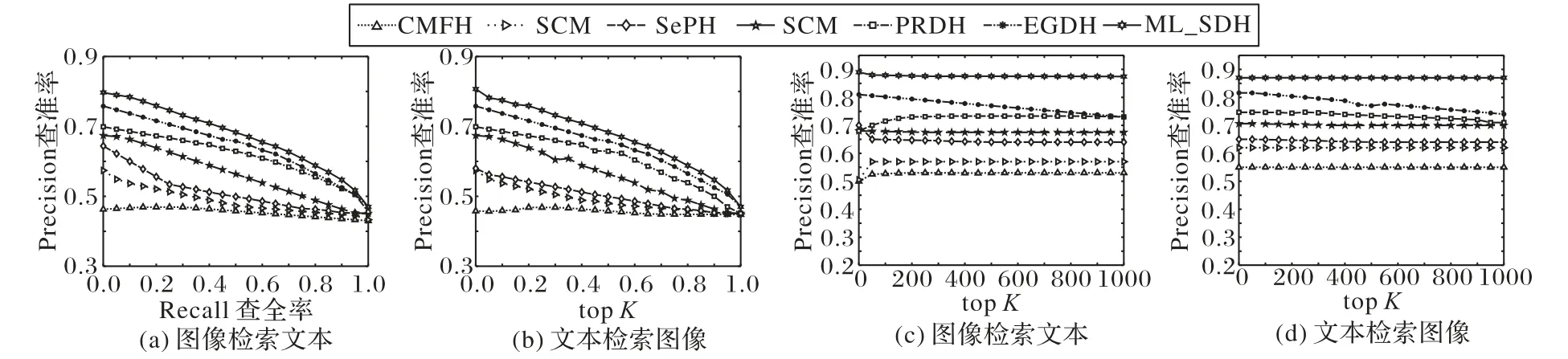
圖4 在NUS-WIDE數據集上哈希碼長度為32時的PR曲線和top K-precision曲線Fig.4 PR curvesand top K-precision curveswith hash code length of 32 bit on NUS-WIDE dataset
4 結語
本文提出了基于多級語義的判別式跨模態哈希檢索算法,該算法考慮到跨模態多標簽數據中的多級語義信息對于檢索結果的重要性,使用了多級語義相似度矩陣學習語義指導向量,構建多級語義指導分類器。該分類器指導不同模態數據學習各自的哈希函數,使得最終學習的哈希碼既保持了判別性也保持了類內和類間關系,實現了分類和多級語義哈希檢索的結合。本文在mirflickr-25k和NUS-WIDE兩個基準數據集上進行了實驗,與幾種前沿的跨模態檢索算法比較,實驗結果表明本文算法在mAP值等檢索精度上有明顯提升。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
計算物理(2014年2期)2014-03-11 17:01:39
外語學刊(2011年1期)2011-01-22 03:38:33
外語學刊(2010年2期)2010-01-22 03:31:03
