DNA存儲(chǔ)中的糾錯(cuò)方法綜述
2021-09-10 05:55:28昝鄉(xiāng)鎮(zhèn)姚翔宇陳智華劉文斌
關(guān)鍵詞:方法
昝鄉(xiāng)鎮(zhèn), 姚翔宇, 許 鵬, 陳智華, 謝 戀, 劉文斌*
(廣州大學(xué) a.計(jì)算科技研究院; b. 黃埔研究院, 廣東 廣州 510006)
隨著分布式、云計(jì)算和物聯(lián)網(wǎng)技術(shù)的發(fā)展,人類每天產(chǎn)生的數(shù)據(jù)總量呈現(xiàn)出指數(shù)增長(zhǎng)的趨勢(shì).據(jù)國(guó)際數(shù)據(jù)公司(IDC)預(yù)測(cè),2025年,全球數(shù)據(jù)信息總量將達(dá)到175 ZB[1].傳統(tǒng)的磁、光、電等存儲(chǔ)技術(shù)已無(wú)法滿足未來(lái)呈指數(shù)增長(zhǎng)趨勢(shì)的數(shù)據(jù)存儲(chǔ)需求[2-3].與此同時(shí),作為生命信息存儲(chǔ)介質(zhì)的DNA分子在存儲(chǔ)容量、穩(wěn)定及能耗方面有著巨大的優(yōu)勢(shì)[4-5].據(jù)估計(jì),DNA分子的存儲(chǔ)密度可達(dá)到~107GB/mm3,比傳統(tǒng)存儲(chǔ)介質(zhì)提高了6個(gè)數(shù)量級(jí).正是基于上述原因,DNA分子有望成為解決海量大數(shù)據(jù)存儲(chǔ)困境的一種極具潛力的存儲(chǔ)介質(zhì)[6-7].
20世紀(jì)60年代,Wiener[8]和Neiman[9]提出了用DNA分子存儲(chǔ)數(shù)據(jù)的想法,標(biāo)志著DNA存儲(chǔ)研究的正式開(kāi)始.隨著合成和測(cè)序技術(shù)的成熟與推廣,2012年,哈佛醫(yī)學(xué)院的Church等[10]第一次在體外實(shí)現(xiàn)了0.65 MB數(shù)據(jù)的DNA存儲(chǔ).此后的每一年,《Nature》 《Science》等權(quán)威期刊都有相關(guān)研究成果的報(bào)道[10-14].歐美發(fā)達(dá)國(guó)家已經(jīng)將DNA存儲(chǔ)列入國(guó)家發(fā)展戰(zhàn)略.2020年11月,微軟公司與西部數(shù)據(jù)公司、Twist生物科技公司以及Illumina公司結(jié)成聯(lián)盟,用于推進(jìn)DNA數(shù)據(jù)存儲(chǔ)領(lǐng)域的發(fā)展.美國(guó)半導(dǎo)體產(chǎn)業(yè)協(xié)會(huì)(SIA)發(fā)布的《半導(dǎo)體10年計(jì)劃》也將DNA數(shù)據(jù)存儲(chǔ)列為未來(lái)海量數(shù)據(jù)存儲(chǔ)的重要選項(xiàng).我國(guó)兩會(huì)公布的《中華人民共和國(guó)國(guó)民經(jīng)濟(jì)和社會(huì)發(fā)展第十四個(gè)五年規(guī)劃和2035年遠(yuǎn)景目標(biāo)綱要》也明確指出,要加快布局DNA存儲(chǔ)等前沿技術(shù).
然而,DNA存儲(chǔ)過(guò)程會(huì)不可避免地引入一些錯(cuò)誤,這些錯(cuò)誤對(duì)DNA數(shù)據(jù)的準(zhǔn)確恢復(fù)提出了嚴(yán)峻的挑戰(zhàn).因此,DNA存儲(chǔ)研究必須要解決的一個(gè)關(guān)鍵問(wèn)題是如何在DNA數(shù)據(jù)恢復(fù)的過(guò)程中發(fā)現(xiàn)錯(cuò)誤并糾正錯(cuò)誤.本文主要介紹了DNA存儲(chǔ)過(guò)程中錯(cuò)誤的類型及其分布復(fù)雜性,DNA存儲(chǔ)糾錯(cuò)技術(shù)的主要進(jìn)展,并對(duì)其發(fā)展趨勢(shì)進(jìn)行了展望.
1 DNA存儲(chǔ)信道復(fù)雜性
DNA存儲(chǔ)過(guò)程主要包括4個(gè)步驟:將計(jì)算機(jī)數(shù)據(jù)編碼成DNA序列,合成DNA序列,PCR擴(kuò)增與存儲(chǔ),測(cè)序并恢復(fù)存儲(chǔ)數(shù)據(jù).DNA存儲(chǔ)主要涉及3種生物技術(shù):DNA序列合成技術(shù)、PCR擴(kuò)增技術(shù)以及測(cè)序技術(shù).DNA存儲(chǔ)過(guò)程可以理解為一個(gè)信道模型,該信道模型主要由上述3種技術(shù)引起一些錯(cuò)誤.這些錯(cuò)誤可以分成兩類:序列內(nèi)錯(cuò)誤和序列間錯(cuò)誤.
序列內(nèi)錯(cuò)誤主要是指DNA分子序列存在堿基的插入、刪除和替換等錯(cuò)誤[15-17].DNA分子在合成時(shí)可能會(huì)發(fā)生堿基的替換、插入和刪除等錯(cuò)誤;PCR擴(kuò)增階段,可能發(fā)生替換錯(cuò)誤;DNA分子在測(cè)序讀取階段,可能會(huì)發(fā)生堿基的替換、插入和刪除等錯(cuò)誤.研究表明,使用二代測(cè)序技術(shù),每個(gè)堿基發(fā)生錯(cuò)誤的概率為1%~2%[17], 而使用三代測(cè)序技術(shù)每個(gè)堿基發(fā)生錯(cuò)誤的概率為10%~15%[18-19].此外,插入或刪除錯(cuò)誤會(huì)導(dǎo)致DNA序列的長(zhǎng)度與標(biāo)準(zhǔn)序列長(zhǎng)度發(fā)生偏差.實(shí)驗(yàn)表明,使用三代測(cè)序技術(shù)大約88%的reads長(zhǎng)度不正確[20].
序列間錯(cuò)誤主要是指DNA分子的缺失,以及DNA分子拷貝數(shù)分布不均勻[21].DNA編碼序列在合成階段,由于合成的不均勻性,DNA分子會(huì)被合成幾百甚至幾千個(gè)拷貝;DNA分子在PCR擴(kuò)增階段也會(huì)發(fā)生拷貝數(shù)不均勻的現(xiàn)象,甚至有些序列會(huì)直接丟失[22-23];在測(cè)序階段,各個(gè)序列拷貝分布的不均勻性,將會(huì)導(dǎo)致測(cè)序數(shù)據(jù)中各序列對(duì)應(yīng)的讀長(zhǎng)(reads)也存在不均勻性,甚至?xí)G失某些序列的讀長(zhǎng).
可以看出,DNA存儲(chǔ)過(guò)程中每個(gè)階段都會(huì)發(fā)生DNA分子序列內(nèi)的錯(cuò)誤以及序列間的錯(cuò)誤,這些錯(cuò)誤相互疊加,增加了DNA存儲(chǔ)解碼過(guò)程的復(fù)雜性(圖1).

圖1 DNA存儲(chǔ)信道的復(fù)雜性Fig.1 The complexity of DNA storage channel
有兩個(gè)原因直接導(dǎo)致了DNA存儲(chǔ)信道的復(fù)雜性:一個(gè)是技術(shù)原因,即技術(shù)水平存在缺陷;另一個(gè)是生物序列本身的一些約束沒(méi)有遵循.生物序列約束主要包括GC含量、均聚物長(zhǎng)度以及回文結(jié)構(gòu).DNA序列中GC分布不均勻、GC含量過(guò)低或者過(guò)高會(huì)導(dǎo)致DNA序列PCR擴(kuò)增分布不均勻;長(zhǎng)度大于4的均聚物的出現(xiàn)會(huì)導(dǎo)致DNA序列在合成或測(cè)序時(shí)發(fā)生堿基錯(cuò)誤;DNA序列存在的回文子序列會(huì)導(dǎo)致該序列在PCR擴(kuò)增時(shí)出現(xiàn)發(fā)夾等二級(jí)結(jié)構(gòu),進(jìn)而影響PCR擴(kuò)增的效率[24-25].
2 DNA存儲(chǔ)糾錯(cuò)技術(shù)
目前,DNA存儲(chǔ)糾錯(cuò)主要聚焦于兩個(gè)方面,即設(shè)計(jì)遵循生物序列約束的編碼策略以及魯棒的糾錯(cuò)算法.
2.1 遵循生物序列約束的編碼策略
編碼DNA序列時(shí)遵循生物序列約束,有助于減少DNA存儲(chǔ)過(guò)程中產(chǎn)生的錯(cuò)誤,并提高解碼效率[26].文獻(xiàn)[27]建議編碼DNA序列時(shí)遵循如下約束[27]:
(1)GC均勻分布且GC含量值介于40%~60%;
(2)均聚物的長(zhǎng)度小于4;
(3)DNA序列不存在回文結(jié)構(gòu).
在設(shè)計(jì)遵循生物序列約束的策略方面,人們普遍采用隨機(jī)化的策略.
Church等[10]使用二進(jìn)制編碼策略(即0用A或G表示,1用C或G表示)來(lái)控制GC含量,避免均聚物及回文序列的出現(xiàn).該二進(jìn)制模型比較簡(jiǎn)單,雖然能較好地滿足生物序列約束,但是該方法編碼效率不高.為了提高編碼效率并遵循序列約束,Goldman等[28]及Bornholt等[29]開(kāi)發(fā)了一種三進(jìn)制的編碼策略,即將數(shù)據(jù)轉(zhuǎn)換為三進(jìn)制數(shù)字0、1、2的表示形式,然后根據(jù)編碼表將三進(jìn)制數(shù)字轉(zhuǎn)變成DNA堿基,見(jiàn)表1.Goldman等[28]設(shè)計(jì)的編碼表,每個(gè)數(shù)字有多個(gè)對(duì)應(yīng)的DNA堿基,當(dāng)前數(shù)字對(duì)應(yīng)的DNA堿基依賴于前一位數(shù)字確定的DNA堿基.然而,使用二進(jìn)制和三進(jìn)制模型編碼DNA序列的研究比較少,目前的研究領(lǐng)域普遍采用四進(jìn)制編碼DNA序列,即兩個(gè)二進(jìn)制位對(duì)應(yīng)一個(gè)堿基.
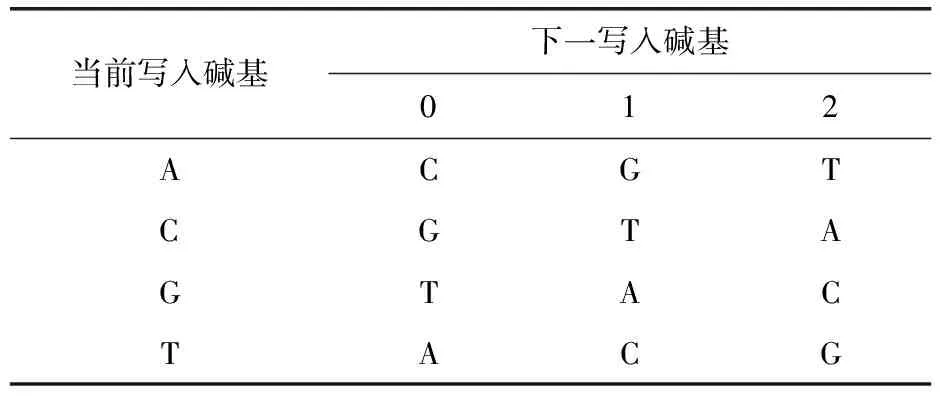
表1 三進(jìn)制編碼表
四進(jìn)制編碼策略容易出現(xiàn)GC含量過(guò)高及均聚物較多的問(wèn)題.為了解決這些問(wèn)題,目前主流的方法是先將二進(jìn)制數(shù)據(jù)與一個(gè)符合要求的隨機(jī)二進(jìn)制序列做異或運(yùn)算,形成一個(gè)二進(jìn)制的結(jié)果序列,然后再對(duì)此二進(jìn)制結(jié)果序列進(jìn)行四進(jìn)制編碼[20, 30].
DNA噴泉碼方法[26-27,31-32].通過(guò)隨機(jī)選擇二進(jìn)制分組數(shù)據(jù)進(jìn)行異或形成復(fù)合序列(液滴),然后將復(fù)合序列按四進(jìn)制編碼策略轉(zhuǎn)換成DNA序列.如果DNA序列符合生物序列約束,則留下等待后續(xù)合成,否則直接舍棄并繼續(xù)下一個(gè)復(fù)合序列(液滴)的生成.DNA噴泉碼充分利用了噴泉碼的無(wú)速率特性,省去了約束映射的冗余性.Wang等[33]采用混合的編碼策略,即隨機(jī)排列DNA序列里的堿基與可變長(zhǎng)度映射策略相結(jié)合的方法,來(lái)滿足GC含量及均聚物的約束.其中,可變長(zhǎng)度映射策略的構(gòu)建方法如下:①根據(jù)可變映射規(guī)則將不符合生物序列約束的二進(jìn)制數(shù)據(jù)分組轉(zhuǎn)換為codeword序列,例如,二進(jìn)制序列‘1100-00-00-1101-01-111100-0’轉(zhuǎn)換為‘01-1-1-02-2-001-1’;②將codeword序列每個(gè)數(shù)字與其前一個(gè)數(shù)字相加并對(duì)4求余,進(jìn)而得到codeword序列對(duì)應(yīng)的四進(jìn)制序列,即‘01-1-1-02-2-001-1’轉(zhuǎn)換為‘01-2-3-31-3-330-1’;③將四進(jìn)制序列中的0映射為A堿基,1映射為T堿基,2映射為C堿基,3映射為G堿基,由此得到符合生物序列約束的DNA序列,即‘01-2-3-31-3-330-1’編碼成DNA序列‘AT-C-G-GT-G-GGA-T’.需要說(shuō)明的是,上述步驟中可變映射規(guī)則的構(gòu)建是通過(guò)構(gòu)建一個(gè)包含3個(gè)狀態(tài)、4個(gè)數(shù)字(代表DNA的4個(gè)堿基),且連續(xù)出現(xiàn)的0不能超過(guò)2的狀態(tài)轉(zhuǎn)換圖FSTD(4,0,2),進(jìn)而進(jìn)行Huffman編碼得到的,見(jiàn)圖2.

圖2 可變長(zhǎng)度的映射規(guī)則Fig.2 Variable-length constrained mapping rule
Zhang Yi團(tuán)隊(duì)[13]、Yazdi等[34]及Xue 等[35]采用一種將用戶二進(jìn)制數(shù)據(jù)與滿足0、1均衡的給定二進(jìn)制序列(調(diào)制碼序列)進(jìn)行調(diào)制的思想,來(lái)滿足GC均衡及均聚物的約束.具體方法為將待編碼二進(jìn)制序列與調(diào)制碼序列逐列對(duì)齊,然后將每列按照調(diào)制規(guī)則轉(zhuǎn)換成一個(gè)DNA堿基,進(jìn)而得到該二進(jìn)制序列調(diào)制后的DNA序列(表2).
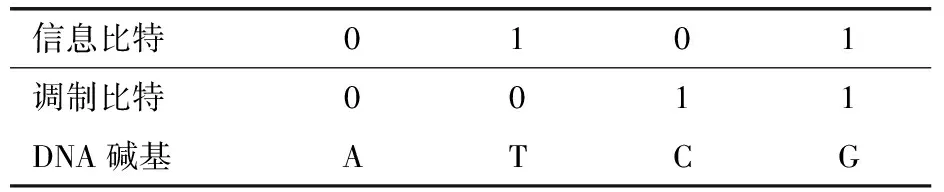
表2 調(diào)制規(guī)則
需要指出,上述所有方法除Church等[10]的方法外,均不能完全解決編碼序列存在二級(jí)結(jié)構(gòu)的問(wèn)題.
2.2 DNA序列數(shù)據(jù)糾錯(cuò)技術(shù)
2.2.1 序列丟失糾錯(cuò)
目前,研究人員主要通過(guò)在編碼階段增加冗余序列來(lái)解決DNA存儲(chǔ)中序列的丟失問(wèn)題.3種代表性的異或方法如圖3所示.
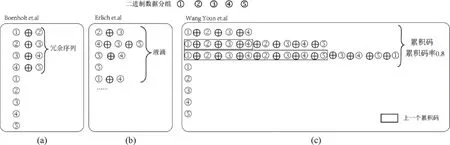
圖3 3種代表性的異或方法Fig.3 Three typical XOR methods
根據(jù)添加冗余序列方式的不同,DNA序列丟失的解決方法可以分為兩類.第一類主要是通過(guò)“序列異或”的思想產(chǎn)生冗余序列或復(fù)合序列.Bornholt等[29]采用連續(xù)兩個(gè)二進(jìn)制序列進(jìn)行異或產(chǎn)生第三個(gè)冗余序列的方法來(lái)解決丟失(圖3a).采用這種方法,任意一個(gè)序列丟失,可以通過(guò)該序列相關(guān)聯(lián)的其他兩個(gè)序列異或得出.然而,該種方法序列冗余度比較大.
為了降低冗余,2017年,Erlich等[27]在噴泉碼思想的基礎(chǔ)上提出了DNA噴泉碼算法(圖3b).其方法為①隨機(jī)選擇多個(gè)二進(jìn)制數(shù)據(jù)分組進(jìn)行異或操作生成復(fù)合序列(也叫液滴);②合成并存儲(chǔ)復(fù)合序列(液滴);③PCR擴(kuò)增并測(cè)序每個(gè)復(fù)合序列;④將已經(jīng)分解出的二進(jìn)制分組依次異或包含該二進(jìn)制分組的液滴,直至分解出所有二進(jìn)制分組數(shù)據(jù).盡管該方法可以以很高的DNA邏輯存儲(chǔ)密度(1.57 bit/nt)復(fù)現(xiàn)數(shù)據(jù),但是該方法編碼和解碼的復(fù)雜度與數(shù)據(jù)大小并不是線性相關(guān),相比編碼解碼更復(fù)雜.Ping等[36]認(rèn)為盡管Erlich等宣稱DNA噴泉碼丟失4%的液滴(指DNA編碼合成的序列)不會(huì)影響源數(shù)據(jù)的恢復(fù),但是丟失更多的數(shù)據(jù)將有可能導(dǎo)致整個(gè)源數(shù)據(jù)無(wú)法恢復(fù).因此,存儲(chǔ)永久性的數(shù)據(jù)就必須有足夠量的冗余.
考慮到DNA噴泉碼中潛在的解碼失敗和冗余地址(降低凈信息密度)可能會(huì)阻礙其在DNA擴(kuò)展性存儲(chǔ)中的實(shí)際應(yīng)用,Wang等[33]提出了累積碼的概念,即在源文件二進(jìn)制分組數(shù)據(jù)的基礎(chǔ)上,添加一定量的冗余校驗(yàn)序列.冗余校驗(yàn)序列生成的方法為(圖3c):根據(jù)累積碼率,選擇一定量的二進(jìn)制分組數(shù)據(jù)(注意:圖例中選擇二進(jìn)制分組的數(shù)量為5*0.8=4),將其與前一個(gè)冗余校驗(yàn)序列一起進(jìn)行異或運(yùn)算.使用該方法,可以通過(guò)冗余校驗(yàn)序列和丟失序列相關(guān)的其他二進(jìn)制序列進(jìn)行異或運(yùn)算,即可恢復(fù)丟失的序列.
第二類通過(guò)使用糾錯(cuò)碼(Error Correcting Codes, ECCs)來(lái)實(shí)現(xiàn)缺失序列的恢復(fù).該類方法主要是通過(guò)在一個(gè)數(shù)據(jù)塊內(nèi)添加一些冗余序列(又叫外碼)來(lái)實(shí)現(xiàn),參見(jiàn)圖4.基本思想是通過(guò)將缺失序列的位信息轉(zhuǎn)變成替換錯(cuò)誤,然后通過(guò)糾錯(cuò)碼來(lái)實(shí)現(xiàn)糾正[20, 37-38].具體方法是①首先將數(shù)據(jù)塊內(nèi)的二進(jìn)制數(shù)據(jù)分組按列排放,形成一個(gè)矩陣;②依次向矩陣每一行的左側(cè)(或右側(cè))使用糾錯(cuò)碼添加r位冗余位信息.解碼時(shí)先將數(shù)據(jù)塊內(nèi)的二進(jìn)制數(shù)據(jù)根據(jù)各自的Index值依次排列好,缺失序列用等長(zhǎng)的隨機(jī)二進(jìn)制數(shù)據(jù)替換,然后依次對(duì)矩陣的每行使用糾錯(cuò)碼糾正缺失序列對(duì)應(yīng)的位信息,直至缺失序列完全恢復(fù)為止.考慮到目前DNA合成技術(shù)一次最多可以同時(shí)合成DNA鏈的數(shù)量為224=16 777 216,Meiser等[37]最先針對(duì)圖4框架中一個(gè)數(shù)據(jù)塊內(nèi)二進(jìn)制分組數(shù)據(jù)的個(gè)數(shù)k、二進(jìn)制分組數(shù)據(jù)的大小(包括分組數(shù)據(jù)數(shù)據(jù)塊內(nèi)的序號(hào)ID)、外碼的個(gè)數(shù)以及每個(gè)符號(hào)所占位數(shù)等參數(shù)的組合進(jìn)行了研究,并給出了每種參數(shù)組合下每條編碼序列包含的堿基個(gè)數(shù).目前,該類方法使用的糾錯(cuò)碼主要為Reed-Solomon碼(RS碼).
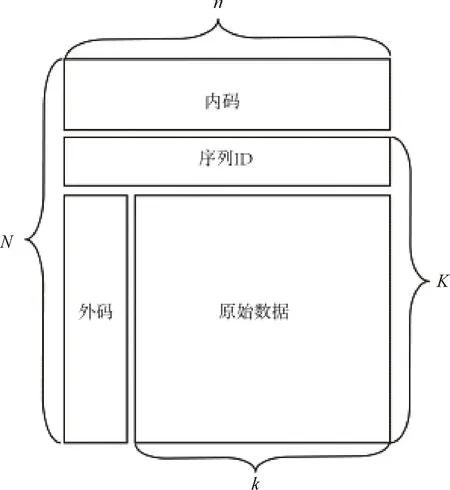
圖4 外碼和內(nèi)碼框架Fig.4 The framework of outer code and inner code
2.2.2 序列內(nèi)堿基錯(cuò)誤糾錯(cuò)
(1)基于多序列比對(duì)思想上的糾錯(cuò)
前面已經(jīng)指出,每個(gè)DNA序列在DNA存儲(chǔ)信道中都會(huì)有多個(gè)拷貝.研究人員利用DNA序列的多拷貝性來(lái)糾正DNA序列內(nèi)的堿基錯(cuò)誤,即替換、插入和刪除等錯(cuò)誤.該算法實(shí)現(xiàn)糾錯(cuò)不要求參與比對(duì)的讀長(zhǎng)具有相同的長(zhǎng)度.該算法的基本思想是,把屬于同一序列的多個(gè)拷貝聚類(或分組)到一起,然后使用多序列比對(duì)軟件(比如MUSCLE,MAFFT等[39-40])比對(duì)同一序列的多個(gè)拷貝,然后按照多數(shù)投票原則確定出一個(gè)一致性的序列,見(jiàn)圖5.該類方法可以糾正序列內(nèi)堿基的插入、缺失和替換等錯(cuò)誤.
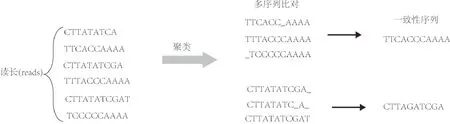
圖5 聚類和多數(shù)投票示例Fig.5 Schematic diagram of clustering and majority voting
Goldman等[28]采用4倍重疊冗余來(lái)解決序列的堿基錯(cuò)誤問(wèn)題,即每個(gè)序列產(chǎn)生3個(gè)重疊的冗余序列,各個(gè)冗余序列和前一序列有3/4的重疊.然而該方法的DNA邏輯存儲(chǔ)密度只有0.33 bit/nt,難以實(shí)際推廣.為了降低合成成本,李彥敏等[41]沒(méi)有使用重疊片段的編碼思想,而是通過(guò)在序列內(nèi)增加序列索引重復(fù)的方式提高后續(xù)聚類的精度,進(jìn)而實(shí)現(xiàn)糾錯(cuò).但是,該方法只能適應(yīng)錯(cuò)誤率較低的情形.
Yadiz等[34]糾正序列內(nèi)堿基錯(cuò)誤的方法分成兩個(gè)階段,如圖6所示.第一階段,根據(jù)每個(gè)讀長(zhǎng)(reads)的索引值(序列號(hào))對(duì)reads進(jìn)行分組,然后使用多序列比對(duì)軟件對(duì)每個(gè)分組包含的讀長(zhǎng)進(jìn)行比對(duì),然后使用多數(shù)投票算法得到一致性序列(碼字);第二階段,迭代使用BWA[42]比對(duì)算法以及均聚物查找算法,修正第一階段產(chǎn)生的一致性序列(碼字).需要說(shuō)明的是,第一階段生成一致性序列的方式是通過(guò)逐個(gè)確定均聚物的方式而產(chǎn)生的.該方法完成糾錯(cuò)需要較高的測(cè)序深度(200X).
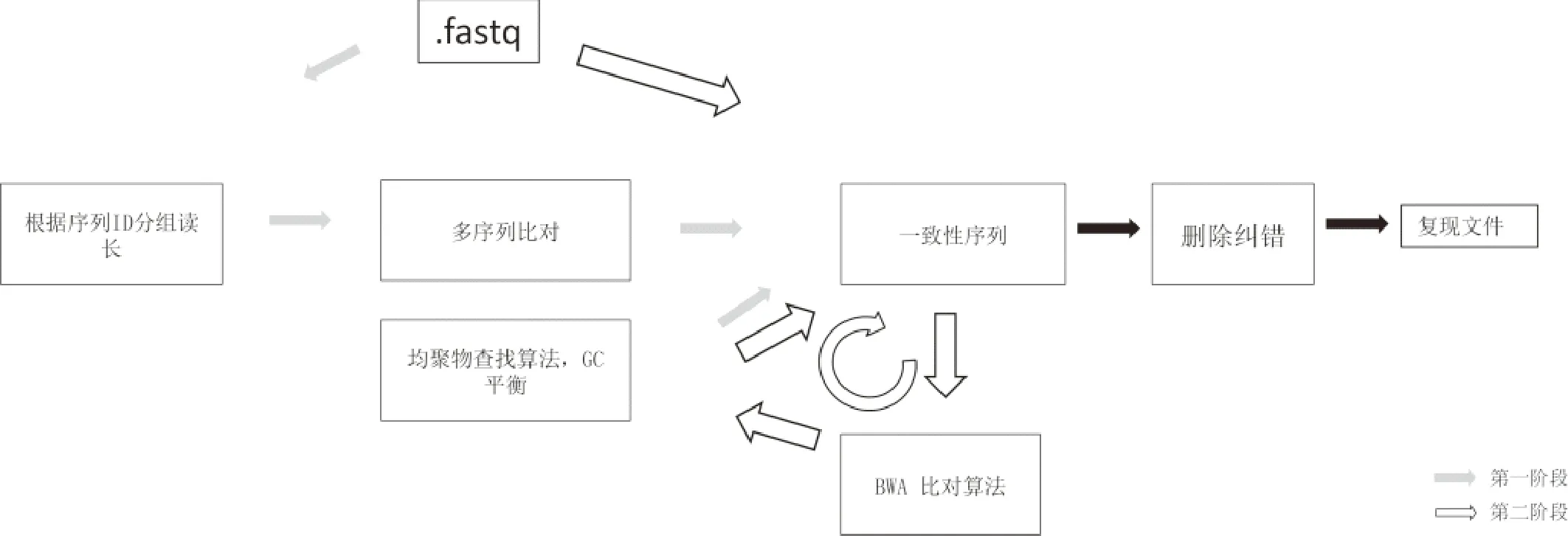
圖6 序列比對(duì)及均聚物校正示意圖Fig.6 Sequence alignment and homopolymer correction
Organick等[20]、Antkowiak等[30]以及Jeong等[26]通過(guò)改進(jìn)聚類算法,提高了產(chǎn)生一致性序列的準(zhǔn)確度. Organick等[20]、Antkowiak等[30]使用局部敏感哈希辦法聚類測(cè)序得到讀長(zhǎng)(reads),該種聚類方法相比以漢明距離為基礎(chǔ)的Jaccard相似性聚類方法,具有更快的時(shí)間性能.該方法的基本思想是,首先獲取各讀長(zhǎng)在給定隨機(jī)數(shù)矩陣上的簽名,然后通過(guò)比較簽名的相似性完成讀長(zhǎng)的聚類.Jeong等[26]首次將序列各堿基的Q-score值納入聚類算法考慮的因素.
(2)基于傳統(tǒng)通信糾錯(cuò)碼上的糾錯(cuò)
傳統(tǒng)通信糾錯(cuò)碼可以糾正二進(jìn)制數(shù)據(jù)分組上的錯(cuò)誤,尤其擅長(zhǎng)糾正替換錯(cuò)誤,且具有完備的數(shù)學(xué)理論基礎(chǔ).由于DNA存儲(chǔ)信道和傳統(tǒng)通信信道相比,都是將計(jì)算機(jī)二進(jìn)制數(shù)據(jù)經(jīng)過(guò)一系列變換最終再轉(zhuǎn)變成二進(jìn)制數(shù)據(jù),這就使得用傳統(tǒng)通信糾錯(cuò)碼去糾正二進(jìn)制分組數(shù)據(jù)里的錯(cuò)誤成為可能.
目前,糾正DNA序列內(nèi)堿基替換錯(cuò)誤的方法,主要采用通信領(lǐng)域里性能較好的糾錯(cuò)碼來(lái)實(shí)現(xiàn)檢錯(cuò)和糾錯(cuò)的目的.這些糾錯(cuò)碼包括Reed-Solomon碼(RS碼)[37, 43-44]、BCH碼[45-46]、Raptor Code碼[47]、漢明碼[12, 48]、LDPC碼[44, 49-50],等等,其中,主流的是使用RS碼(圖4中的內(nèi)碼是指RS糾錯(cuò)碼).使用這些糾錯(cuò)碼的方法是①針對(duì)二進(jìn)制分組數(shù)據(jù),使用上述糾錯(cuò)碼對(duì)應(yīng)的生成矩陣產(chǎn)生冗余位信息;②將冗余位信息融入到二進(jìn)制分組形成待編碼二進(jìn)制序列;③將待編碼二進(jìn)制序列按照四進(jìn)制編碼策略轉(zhuǎn)換成DNA序列;④在將測(cè)序得到的DNA序列轉(zhuǎn)換為二進(jìn)制序列后,使用糾錯(cuò)碼的一致性校驗(yàn)矩陣進(jìn)行矩陣運(yùn)算,從而檢錯(cuò)和糾錯(cuò).然而,上述糾錯(cuò)碼糾錯(cuò)的能力越強(qiáng),即糾錯(cuò)的數(shù)量越多,冗余度就越高.例如,BCH(255,47)碼可以糾正替換錯(cuò)誤率達(dá)16%的錯(cuò)誤,但是冗余度達(dá)到82%.
Xue等[35]在Levenshtein碼的基礎(chǔ)上,開(kāi)發(fā)了一個(gè)既能實(shí)現(xiàn)GC平衡,又能解決堿基插入/缺失/替換錯(cuò)誤的編碼方法.該方法構(gòu)建levenshtein碼的方法為(圖7)①將每一個(gè)長(zhǎng)度為(2n-3「log2n?-2)的二進(jìn)制分組數(shù)據(jù)拆分成長(zhǎng)度為n和長(zhǎng)度為(n-3「log2?n-2)的兩個(gè)子串;②從最后一位開(kāi)始,將長(zhǎng)度為n的二進(jìn)制分組數(shù)據(jù)子串逐位取反直至該子串含1的數(shù)量為n/2,標(biāo)記為奇串;③將奇串的統(tǒng)計(jì)信息、校驗(yàn)信息以及長(zhǎng)度為(n-3「log2n?-2)的二進(jìn)制分組數(shù)據(jù)子串合并,構(gòu)成偶串;④將奇串和偶串調(diào)制成DNA序列.解碼時(shí),當(dāng)有一位插入/缺失/替換錯(cuò)誤發(fā)生時(shí),奇串和偶串的對(duì)應(yīng)信息會(huì)出現(xiàn)沖突,此時(shí)根據(jù)奇串的長(zhǎng)度與標(biāo)準(zhǔn)長(zhǎng)度的差值以及當(dāng)前解碼出的二進(jìn)制字符串的S值和H值,可以準(zhǔn)確地推算出發(fā)生堿基錯(cuò)誤的位置并給予糾正.然而,該方法一個(gè)碼字只能解決一位插入/刪除/替換錯(cuò)誤,且碼字較長(zhǎng).
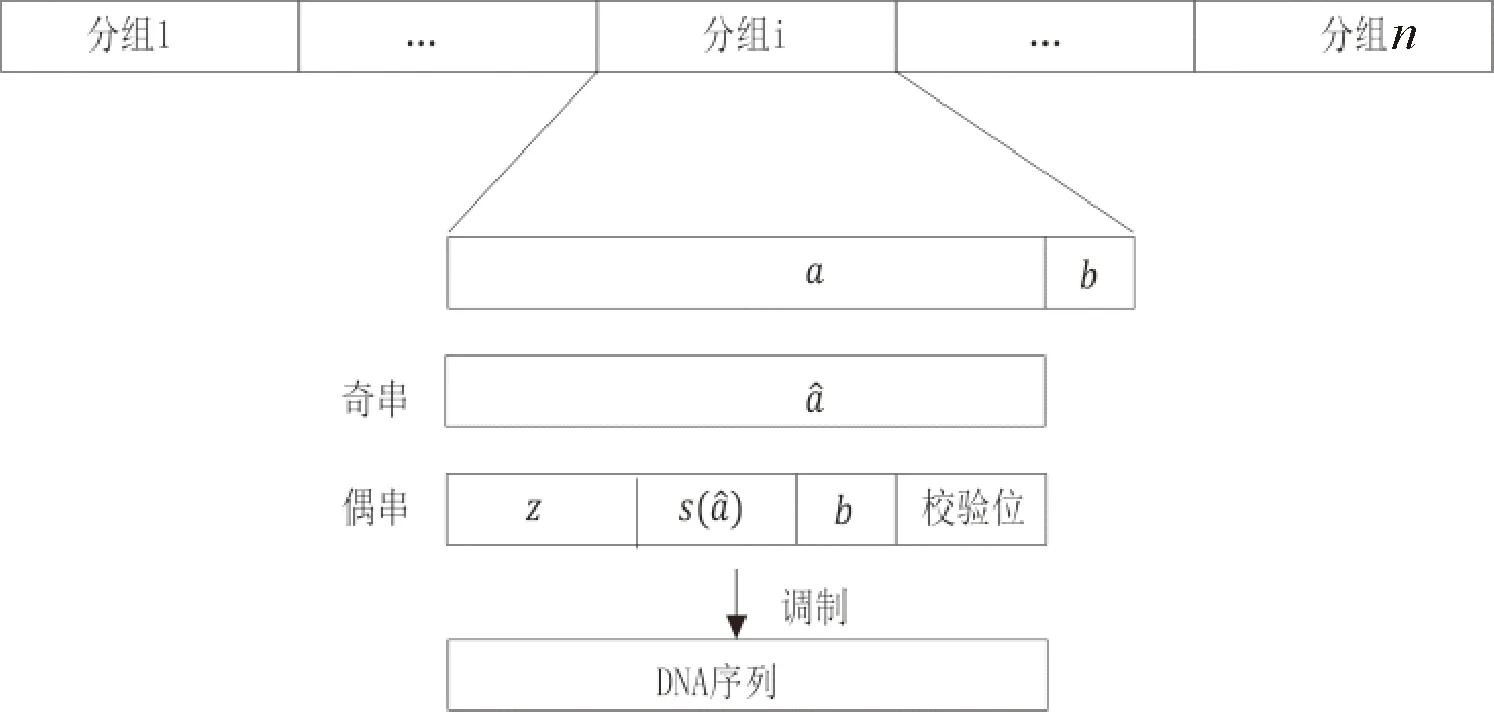
圖7 Levenshtein碼的構(gòu)建Fig.7 Construction of Levenshtein code
(3)基于算法角度實(shí)現(xiàn)糾錯(cuò)
糾正DNA序列內(nèi)錯(cuò)誤的難點(diǎn)是糾正序列里的插入和刪除等錯(cuò)誤,因?yàn)楹茈y分辨出DNA序列內(nèi)具體哪些堿基發(fā)生了這些錯(cuò)誤.因此,糾正錯(cuò)誤的關(guān)鍵在于準(zhǔn)確地識(shí)別出發(fā)生插入/刪除錯(cuò)誤的位置.目前,研究人員大都通過(guò)設(shè)計(jì)一套有一定規(guī)律的編碼策略來(lái)編碼DNA序列.該編碼策略對(duì)插入/刪除非常敏感且不需要額外的堿基進(jìn)行存儲(chǔ).
Blawat等[46]設(shè)計(jì)了一套編碼表,即每個(gè)字節(jié)對(duì)應(yīng)兩個(gè)DNA編碼(圖8a),然后將所有字節(jié)的DNA編碼分成兩類,編碼DNA序列時(shí),交替使用各字節(jié)的第一類編碼和第二類編碼.當(dāng)插入/缺失錯(cuò)誤發(fā)生時(shí),第一類DNA編碼和第二類DNA編碼交替出現(xiàn)的規(guī)律將會(huì)打破,由此可以定位發(fā)生插入/刪除的編碼位置(圖8b).然而該算法只能檢測(cè)插入/缺失錯(cuò)誤,不能糾錯(cuò).

圖8 Blawat設(shè)計(jì)的編碼表及可檢測(cè)插入/缺失錯(cuò)誤的示例Fig.8 The code table by Blawat and an illustration of insertion/deletion detecting
Press等[51]設(shè)計(jì)了一個(gè)名為HEDGES的算法,同時(shí)結(jié)合RS碼,用于糾正DNA序列內(nèi)的插入/刪除/替換錯(cuò)誤(圖9).其方法:①將源文件二進(jìn)制數(shù)據(jù)劃分成等長(zhǎng)度的二進(jìn)制信息,然后對(duì)每個(gè)二進(jìn)制信息添加索引(即序列ID),形成一系列待編碼二進(jìn)制序列;②將待編碼二進(jìn)制序列的每個(gè)二進(jìn)制位數(shù)值、位置下標(biāo)索引、序列index以及該位前面連續(xù)幾個(gè)位信息進(jìn)行hash操作最終變成一個(gè)DNA堿基,由此得到一個(gè)待編碼二進(jìn)制序列對(duì)應(yīng)的DNA序列.當(dāng)插入/刪除/替換錯(cuò)誤發(fā)生時(shí),上述編碼規(guī)律將會(huì)打破,通過(guò)查找樹(shù)結(jié)構(gòu)可以判斷該二進(jìn)制位是否發(fā)生錯(cuò)誤及發(fā)生什么錯(cuò)誤,并最終將出錯(cuò)二進(jìn)制位信息予以糾正.實(shí)驗(yàn)結(jié)果表明,該方法能夠處理約1.2%的增刪錯(cuò)誤.然而該方法的編碼率不高,糾正3%的錯(cuò)誤,編碼率將降低到0.6以下.
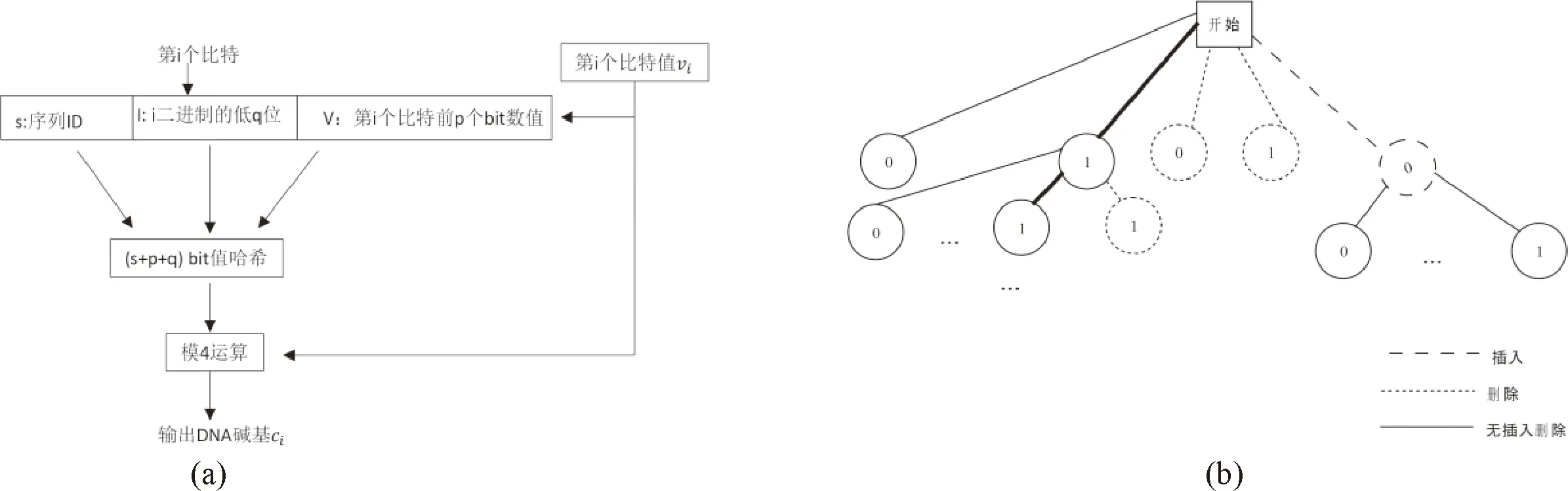
圖9 HEDGES編碼與解碼Fig.9 Schematic diagram of HEDGES encoding and decoding
天津大學(xué)的Song 等[52]在De Bruijn圖的基礎(chǔ)上,構(gòu)建了同一序列多個(gè)拷貝的De Bruijn圖,然后通過(guò)基于貪心的搜索策略,搜索原序列對(duì)應(yīng)的最可能路徑.該算法與第一類算法相比,不需要聚類,因此具有更快的時(shí)間性能(圖10).該方法可以解決序列內(nèi)的插入、刪除、替換等錯(cuò)誤.但是,該方法De Bruijn圖的構(gòu)建過(guò)度依賴于序列索引(即序列ID).如果屬于同一序列的每個(gè)拷貝index都出現(xiàn)錯(cuò)誤,該方法將不能構(gòu)建De Bruijn圖.
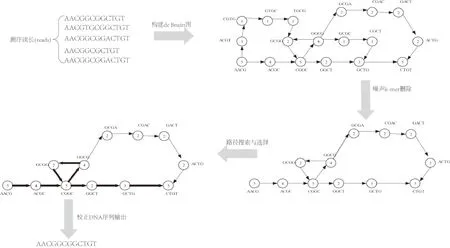
圖10 de Bruijn 圖算法框架Fig.10 The framework of de Bruijn graph
Sharma等[53]通過(guò)定義堿基異或規(guī)則(表3)實(shí)現(xiàn)了糾正堿基替換錯(cuò)誤的目的.其方法是①將每一個(gè)DNA編碼序列從左到右4個(gè)堿基為一組切分該編碼序列;②依次將每個(gè)切分第一字符拼接起來(lái)形成第一個(gè)編碼序列,同時(shí)將每個(gè)切分后續(xù)3個(gè)字符拼接起來(lái)形成第二個(gè)編碼序列;③依次將每個(gè)切分第一個(gè)字符與該切分后續(xù)3個(gè)字符做異或操作,將所有切分異或操作結(jié)果依次拼接起來(lái),形成第三個(gè)編碼序列;④解碼時(shí),根據(jù)得到的屬于同一序列的3個(gè)片段,兩兩異或推導(dǎo)出3個(gè)原編碼序列,根據(jù)一致性最終確定原編碼序列.然而,該方法的冗余度比較高,冗余度為75%.
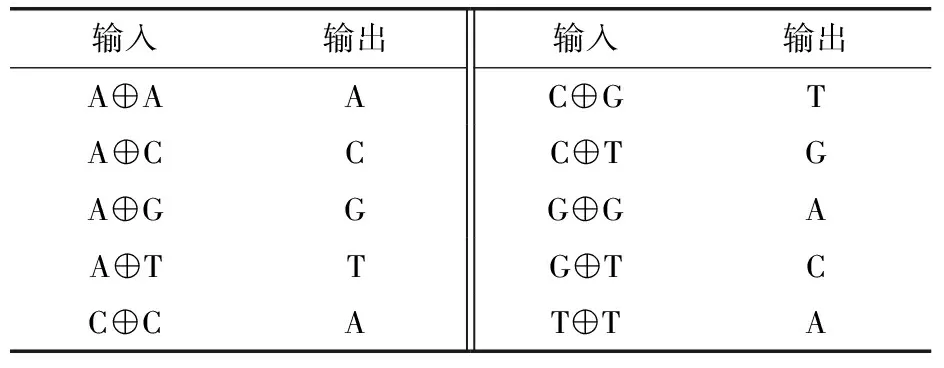
表3 堿基異或表
3 DNA糾錯(cuò)技術(shù)展望
DNA數(shù)據(jù)存儲(chǔ)是一種新興的非易失性存儲(chǔ)技術(shù),具有前所未有的密度、耐用性和復(fù)制效率.盡管DNA存儲(chǔ)與傳統(tǒng)存儲(chǔ)技術(shù)相比,具有較明顯的優(yōu)勢(shì),但是現(xiàn)階段DNA存儲(chǔ)距離真正的大規(guī)模應(yīng)用還有很長(zhǎng)的距離.未來(lái)DNA存儲(chǔ)要做到真正大規(guī)模的應(yīng)用,使用成本較低、通量較大,但同時(shí)錯(cuò)誤率較高的DNA合成技術(shù)及DNA測(cè)序技術(shù)再所難免.因此,未來(lái)DNA存儲(chǔ)糾錯(cuò)技術(shù)可能呈現(xiàn)出以下兩個(gè)變化.
(1)編碼DNA序列時(shí)嚴(yán)格遵循生物序列約束.在滿足GC平衡及無(wú)均聚物的同時(shí),尤其要避免DNA二級(jí)結(jié)構(gòu)的形成.因此,未來(lái)的糾錯(cuò)算法可能包括DNA二級(jí)結(jié)構(gòu)子序列的查找算法以及DNA二級(jí)結(jié)構(gòu)的替換算法,從源頭上嚴(yán)格保證DNA編碼序列滿足生物序列約束,盡可能減少后續(xù)DNA存儲(chǔ)過(guò)程中的錯(cuò)誤.
(2)未來(lái)的DNA存儲(chǔ)糾錯(cuò)算法應(yīng)能適應(yīng)錯(cuò)誤率更高的環(huán)境,同時(shí)具有良好的時(shí)間性能.目前的DNA存儲(chǔ)糾錯(cuò)算法能夠適應(yīng)的堿基錯(cuò)誤率最高為15%左右(使用三代測(cè)序).隨著人們對(duì)DNA存儲(chǔ)成本的要求越來(lái)越低及對(duì)存儲(chǔ)通量的要求越來(lái)越高,未來(lái)DNA存儲(chǔ)糾錯(cuò)算法可能要適應(yīng)錯(cuò)誤率高達(dá)20%以上的環(huán)境.針對(duì)高噪聲環(huán)境,設(shè)計(jì)魯棒的糾錯(cuò)算法,同時(shí)滿足處理海量DNA數(shù)據(jù)時(shí)間性能上的要求,是未來(lái)DNA存儲(chǔ)糾錯(cuò)算法的方向.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
 廣州大學(xué)學(xué)報(bào)(自然科學(xué)版)2021年2期
廣州大學(xué)學(xué)報(bào)(自然科學(xué)版)2021年2期
- 廣州大學(xué)學(xué)報(bào)(自然科學(xué)版)的其它文章
- 人工智能賦能網(wǎng)絡(luò)安全應(yīng)用
- 粵港澳大灣區(qū)非物質(zhì)文化遺產(chǎn)空間格局與影響因素
- 基于聚合酶鏈置換反應(yīng)的2D-LASM混沌文本加密算法
- 金融發(fā)展、產(chǎn)業(yè)結(jié)構(gòu)變動(dòng)與實(shí)體經(jīng)濟(jì)增長(zhǎng)
——基于VAR模型的實(shí)證分析 - 數(shù)字普惠金融對(duì)城鄉(xiāng)居民收入分配的門檻效應(yīng)研究
- Quaternionic-valued wavelet transform and orthogonal decomposition