基于SAS-DBEN的海洋環境多因素預測方法
2021-09-14 02:48:15王嘉琳金宇悅李志剛
電腦知識與技術 2021年22期
王嘉琳 金宇悅 李志剛

摘要:激勵函數對深度神經網絡的非線性逼近性能具有重要影響,其選擇與任務相關。針對這一問題,提出基于自適應選擇算法的深度置信回聲狀態網絡模型,并應用于海洋環境多因素時間序列預測。該模型集成了14種激勵函數,通過預測性能比較實現自適應選擇功能。仿真結果表明,該模型能夠正確選擇出最優激勵函數,具有良好的海洋數據多因素預測能力。
關鍵詞:海洋環境數據;時間序列預測;深度置信回聲狀態網絡;自適應選擇算法;激勵函數
Abstract: Activation function (AF) has an important effect on the nonlinear approximation performance of deep neural networks. The choice of AFs is task-related. For this problem, a deep belief echo-state network based on self-adaptive selection (SAS-DBEN) is proposed for ocean-related multi-factor time series prediction. In this model, 14 activation functions are integrated, and the self-adaptive selection is implemented by comparing the prediction performance. Experimental results show that SAS-DBEN can select the optimal AF correctly and has a good multi-factor prediction ability of ocean data.
Key words: ocean environment data; time series prediction; deep belief echo-state network; self-adaptive selection algorithm; activation function
1 引言
近年來,我國多個近岸海域污染嚴重。如何加強對海洋污染的應對,維護海洋環境長久穩定,是當前急需解決的問題。葉綠素是影響海洋環境污染的主要因素。藻類植物作為葉綠素的主要提供者,其增殖過程受多種海洋環境因素共同影響,是一種極其復雜的非線性過程[1]。鑒于此,本文研究多因素預測葉綠素和藍綠藻的方法。
目前,深度學習已成為數據預測領域的主流方法。深度置信回聲狀態網絡(Deep Belief Echo-state Network, DBEN)由于其強大的特征提取功能和非線性回歸能力,已成功應用于海洋領域[2]。實際上,激勵函數在深度神經網絡中具有關鍵作用。通過激勵函數,網絡可以在任何給定的深度學習架構中,實現層結構之間的復雜函數計算和非線性映射[3]。
鑒于DBEN良好的預測能力以及激勵函數在DNN中的重要作用,提出了一種結合自適應選擇算法(Self-adaptive Selection, SAS)和DBEN的新型海洋環境多因素預測模型SAS-DBEN。該模型提供了一種自適應的通用功能,使模型具有靈活性,有利于提高海洋環境多因素預測精度。
2 海洋環境多因素預測模型
2.1 建立激勵函數池
SAS-DBEN通過比較不同激勵函數下的預測性能來確定最優激勵函數。首先,建立激勵函數池F={f1, f2, …, fM}(m=1,2, …, M),對所考慮的函數進行封裝和標記,為后續自適應激勵機制和函數調用做準備。這里,我們考慮了14種激勵函數集成到SAS-DBEN框架下的激勵函數池中,具體激勵函數如表1所示。
2.2 海洋環境特征提取
建立激勵函數池后,我們將經過數據預處理后的數據集注入SAS-DBEN模型中。該模型以DBN作為特征提取器,與可見層v和隱藏層h相關的能量函數表達如下:
2.3 非線性逼近
準確的海洋環境數據預測取決于深度神經網絡中的非線性回歸機制。SAS-DBEN采用了基于儲備池計算理論的非線性逼近方法,儲備池狀態更新和網絡輸出表示為:
其中,W表示內部權重矩陣,I表示輸入權重矩陣,Wback表示反饋權重矩陣,O表示輸出權重矩陣,m(t)表示時間步長為t時刻的儲備池輸入信號,x(t)和y(t)分別表示儲備池的狀態和輸出,σ(?)表示儲備池內部的激活函數,本章采用Tanh函數作為回歸階段神經元中的激活函數。
2.4 自適應激勵機制
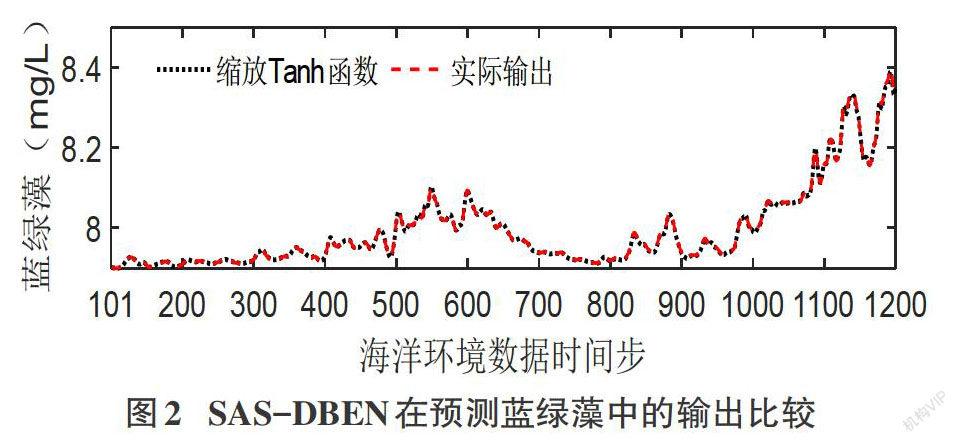
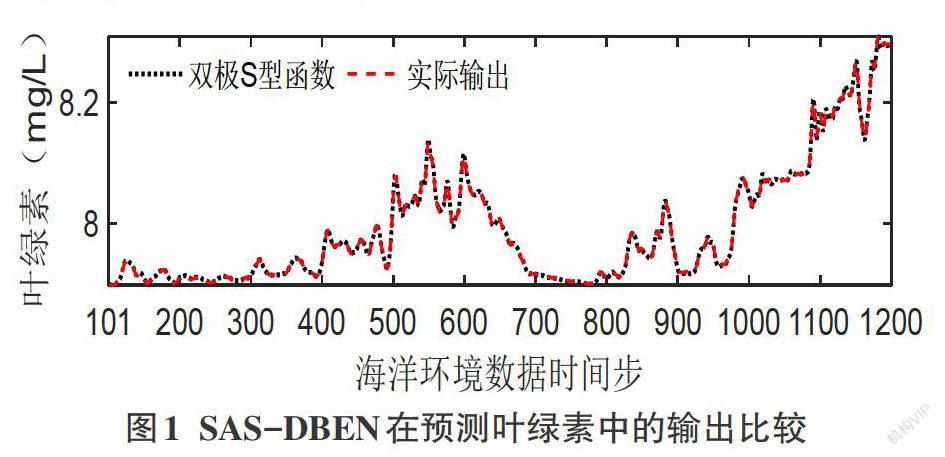
在訓練過程中,通過自適應激勵機制,模型可以根據輸入數據的特征選擇適用于該數據的激勵函數。本文以歸一化均方根誤差(Normalized Root Mean Squared Error, NRMSE)作為最優激勵函數的度量標準。按照激勵函數池中的標記順序,分別對m個誤差數值進行比較,置換出較小誤差值繼續比較,得出最優激勵函數,完成自適應激勵函數選擇,這也意味著SAS-DBEN模型訓練結束。
3 實驗
3.1 實驗數據
本實驗采用海、陸、空、天四維立體化海洋監測網獲取的海洋數據,考慮了10種與海洋環境高度相關的因素作為模型的輸入,即1/10波浪周期、平均波浪周期、氣溫、相對濕度、磷酸鹽、氨氮、水溫、pH值、葉綠素和藍綠藻。采用上述因素進行2組仿真實驗,預測葉綠素和藍綠藻的動態變化趨勢,實現多輸入單輸出預測。將數據的70%用于模型訓練,30%用于模型測試。為緩解網絡初始化對儲備池狀態造成的影響,舍棄了訓練和測試時間序列中的前100個數據。
