基于K-means算法的企業(yè)信用無(wú)監(jiān)督分類(lèi)研究
2021-09-14 00:14:25施天虎韋詩(shī)玥
電腦知識(shí)與技術(shù) 2021年22期
關(guān)鍵詞:分類(lèi)
施天虎 韋詩(shī)玥


摘要:企業(yè)信用分類(lèi)的應(yīng)用,能夠?yàn)樯虡I(yè)銀行降低信貸業(yè)務(wù)的風(fēng)險(xiǎn),隨著市場(chǎng)競(jìng)爭(zhēng)的不斷加劇,機(jī)器學(xué)習(xí)和大數(shù)據(jù)的應(yīng)用,越來(lái)越多的計(jì)量方法不斷革新,并廣泛運(yùn)用到信用分析領(lǐng)域。本文設(shè)計(jì)了一個(gè)基于K-means算法的企業(yè)信用無(wú)監(jiān)督分類(lèi)方法,通過(guò)對(duì)企業(yè)信息進(jìn)行大數(shù)據(jù)分析,提取企業(yè)信用相關(guān)的內(nèi)容,再使用K-means算法對(duì)企業(yè)數(shù)據(jù)進(jìn)行聚類(lèi),對(duì)目標(biāo)企業(yè)根據(jù)其聚類(lèi)所在簇來(lái)評(píng)估信用等級(jí),以此對(duì)企業(yè)的信用進(jìn)行分類(lèi)。
關(guān)鍵詞:企業(yè)信用;信貸風(fēng)險(xiǎn);K-means算法;分類(lèi);特征選擇
Abstract: The application of corporate credit classification can reduce the risk of credit business for commercial banks. With the continuous intensification of market competition, the application of machine learning and big data, more and more measurement methods continue to innovate and are widely used in the field of credit analysis. This paper designs an unsupervised classification system for corporate credit based on the K-means algorithm. Through big data analysis of corporate information, the content related to corporate credit is extracted, and then the K-means algorithm is used to cluster the companies, and the target companies are based on their The clusters where the clusters are located are used to evaluate the credit rating and thus classify the credit of the enterprise.
Key words: Corporate credit; Credit Risk; K-means algorithm; classification; Feature selection
1引言
金融行業(yè)積累了大量的企業(yè)脫敏數(shù)據(jù)信息,企業(yè)的有效劃分及標(biāo)識(shí)在企業(yè)信用評(píng)估、企業(yè)風(fēng)險(xiǎn)監(jiān)測(cè)中具有重要作用并受到各大平臺(tái)的重點(diǎn)關(guān)注[1]。金融場(chǎng)景中企業(yè)作為信貸主體的數(shù)據(jù)覆蓋互聯(lián)網(wǎng)、政府、線上應(yīng)用等來(lái)源的方方面面,數(shù)據(jù)量大,來(lái)源廣泛、涉及企業(yè)的維度豐富[2]。企業(yè)信用分類(lèi)的應(yīng)用,為商業(yè)銀行降低企業(yè)信貸業(yè)務(wù)風(fēng)險(xiǎn),創(chuàng)新風(fēng)險(xiǎn)管理理念,探索出一條行之有效的解決辦法[3]。隨著大數(shù)據(jù)、人工智能的發(fā)展和市場(chǎng)競(jìng)爭(zhēng)日益加劇,大量基于機(jī)器學(xué)習(xí)的信用評(píng)估分類(lèi)方法提出并廣泛應(yīng)用于企業(yè)信用分析[4]。本文將企業(yè)脫敏數(shù)據(jù)信息進(jìn)行特征選擇,提取信用分類(lèi)相關(guān)的內(nèi)容,再使用K-means算法對(duì)數(shù)據(jù)進(jìn)行聚類(lèi),按聚類(lèi)簇劃分信用等級(jí)。
2 關(guān)鍵技術(shù)
2.1 K-means算法
2.2 特征選擇
特征選擇是重要的數(shù)據(jù)預(yù)處理方法,在數(shù)據(jù)中選出重要特征可以降低數(shù)據(jù)維度、去除多余的變量,提高算法的精度和效率。
本文使用皮爾森相關(guān)系數(shù)[6]對(duì)數(shù)據(jù)進(jìn)行特征選擇,皮爾森相關(guān)系數(shù)能夠獲取特征和變量之間的線性相關(guān)系,其計(jì)算公式如下:
3 基于K-means算法的企業(yè)信用無(wú)監(jiān)督分類(lèi)
3.1 提取相關(guān)特征
計(jì)算數(shù)據(jù)所有特征與信用分類(lèi)的皮爾森相關(guān)系數(shù),根據(jù)結(jié)果判斷該特征是否與信用分類(lèi)相關(guān)。設(shè)企業(yè)的信用類(lèi)別為C={x1,x2,...,xn},特征項(xiàng)為T(mén)={t1,t2,...,tn},相關(guān)閾值為x,當(dāng)該特征項(xiàng)與信用類(lèi)別的皮爾森相關(guān)系數(shù)大于閾值x即滿(mǎn)足下式時(shí)選用該特征。
3.2 使用K-means算法聚類(lèi)
在選取到相關(guān)特征后,使用K-means算法對(duì)企業(yè)數(shù)據(jù)進(jìn)行聚類(lèi)。K-means算法聚類(lèi)效果的好壞很大程度上取決于初始聚類(lèi)中心的選擇,若選取的K個(gè)中心點(diǎn)中有離群點(diǎn)或者各中心點(diǎn)相互距離較近,則常導(dǎo)致聚類(lèi)的效果不佳。針對(duì)這個(gè)問(wèn)題,本文使用基于最大距離和密度相結(jié)合的初始中心選取方法。其過(guò)程如下:
Step1:設(shè)置密度閾值q,隨機(jī)選擇一個(gè)樣本密度小于q的點(diǎn)作為第一個(gè)初始中心點(diǎn)K1。
Step2:在所有滿(mǎn)足樣本密度的點(diǎn)中,選擇離K1最遠(yuǎn)的點(diǎn)作為第二個(gè)初始中心點(diǎn)K2。
Step3:同上方法尋找第三個(gè)點(diǎn),以此類(lèi)推,直至獲得K個(gè)初始中心點(diǎn)。
用此方法可以使聚類(lèi)初始中心間的距離較大,且避免存在離群點(diǎn)。
在將數(shù)據(jù)進(jìn)行聚類(lèi)后得到K個(gè)簇,以簇內(nèi)企業(yè)數(shù)據(jù)占比最多的信用類(lèi)別來(lái)表示該簇的類(lèi)別,對(duì)目標(biāo)企業(yè)計(jì)算其到各簇中心的距離,距離最近簇所表示的信用類(lèi)別即表示對(duì)該企業(yè)預(yù)測(cè)的信用類(lèi)別。
4 實(shí)驗(yàn)與分析
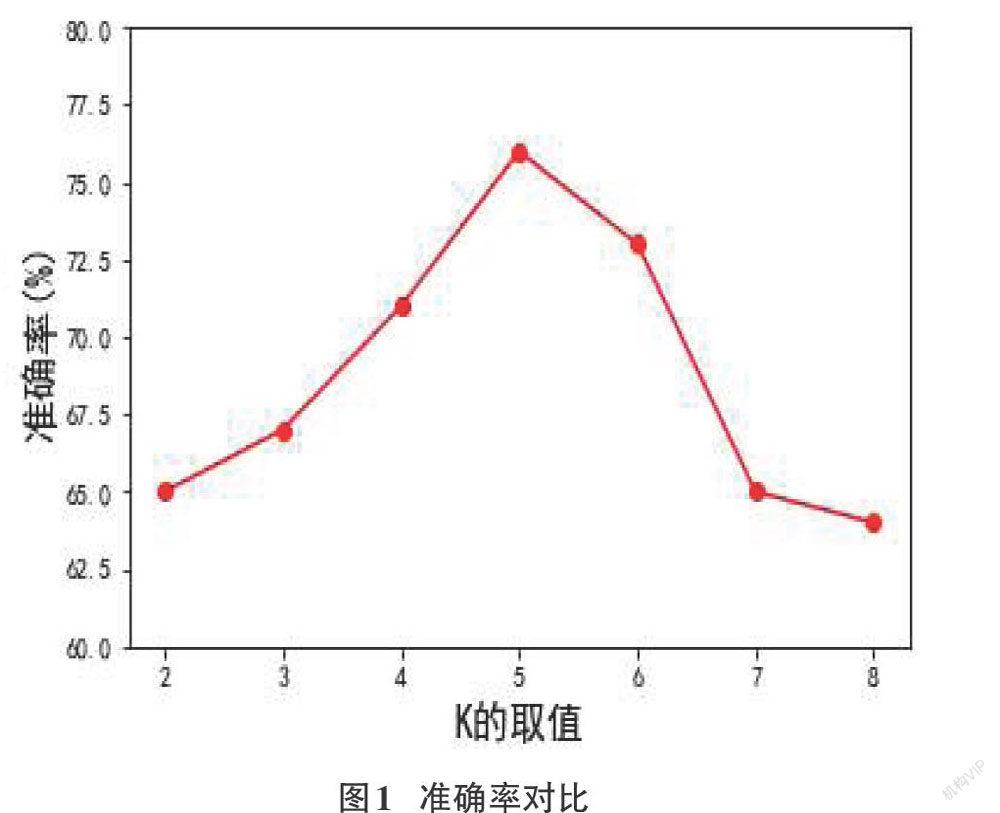
本文采用浪潮公司發(fā)布的企業(yè)脫敏數(shù)據(jù)進(jìn)行仿真實(shí)驗(yàn),從數(shù)據(jù)集中取1萬(wàn)條數(shù)據(jù),數(shù)據(jù)集共36個(gè)特征。實(shí)驗(yàn)結(jié)果如下圖所示:
從圖1可以看出,在K取值為5時(shí),本文算法擁有最佳準(zhǔn)確率,表示分類(lèi)效果最好。
5結(jié)束語(yǔ)
本文設(shè)計(jì)了一個(gè)基于K-means算法的企業(yè)信用無(wú)監(jiān)督分類(lèi)方法,首先提取企業(yè)信息中與信用分類(lèi)相關(guān)的特征,再將企業(yè)數(shù)據(jù)使用改進(jìn)中心點(diǎn)選取的K-means算法進(jìn)行聚類(lèi),通過(guò)判斷目標(biāo)企業(yè)所在簇判斷其信用類(lèi)別,為企業(yè)信用評(píng)估提供參考。
參考文獻(xiàn):
[1] Simon Rogers,MarkGirolami.機(jī)器學(xué)習(xí)基礎(chǔ)教程[M].郭茂祖,譯.北京:機(jī)械工業(yè)出版社,2014.
[2] 李恩,劉立新.小微企業(yè)信用評(píng)價(jià)指標(biāo)體系研究綜述[J].征信,2013,31(1):67-70.
[3] 張杏枝.基于機(jī)器學(xué)習(xí)的信用評(píng)分模型研究[D].重慶:西南大學(xué),2019.
[4] 張萌.基于層次分析法的商務(wù)領(lǐng)域企業(yè)信用評(píng)價(jià)模型的構(gòu)建[J].中國(guó)商論,2019(14):232-233.
[5] 黃曉輝,王成,熊李艷,等.一種集成簇內(nèi)和簇間距離的加權(quán)k-means聚類(lèi)方法[J].計(jì)算機(jī)學(xué)報(bào),2019,42(12):2836-2848.
[6] 馬克勤,楊延?jì)桑丶t武,等.結(jié)合最大最小距離和加權(quán)密度的K-means聚類(lèi)算法[J].計(jì)算機(jī)工程與應(yīng)用,2020,56(16):50-54.
【通聯(lián)編輯:梁書(shū)】
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫(huà)刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
