復雜背景下的點陣字符識別研究
2021-09-15 11:20:20吳慧瑩范晏君
計算機應用與軟件 2021年9期
吳慧瑩 陳 明 范晏君 黃 帥
(廣西師范大學計算機科學與信息工程學院 廣西 桂林 541004)
0 引 言
食品包裝上的生產日期、保質期和生產批次是保證食品安全的重要信息,食品廠家將這些信息以點陣字符的形式打印在包裝表面。目前,食品包裝行業一般采用噴墨技術對食品進行生產信息標注。但該技術在噴碼機振動不穩定、噴墨不均勻和油墨不足等情況下,容易產生字符傾斜、字符殘缺和字符模糊等問題。為避免這些問題對產品流通和銷售產生影響,需要對點陣字符進行檢測和識別。
傳統檢測過程通常依賴人工完成,不僅檢測效率低、準確度不可靠,而且需要耗費大量的人力資源,增加了生產成本。因此,研究一種高效準確的自動化檢測識別方法來代替人工檢測,不僅有利于提高企業的生產效益,還有利于保證食品的安全。
1 相關工作
通常,研究人員將字符識別算法分為字符定位、字符分割和字符識別三個部分。字符定位和分割用于定位和分割字符所在的區域,字符識別用于對分割好的字符區域進行識別,只有當三個部分都發揮最好的性能時,字符識別算法才能獲得最優的識別效果。字符分割常用的方法有垂直投影法、連通域法等[1-3],這類方法對于連續字符具有較好的分割效果。然而,由于點陣字符的不連續性,直接采取上述方法難以準確分割。針對字符識別而言,目前主要有基于模板匹配的識別方法、基于機器學習的識別方法和基于深度學習的識別方法三類。錢俞好等[4]提出了一種基于MATLAB圖像積分的改進模板匹配算法,首先對圖像進行積分處理再進行模板匹配,不僅減少了內存開銷,而且大大加快了檢測速度,但該方法存在個別字符識別不理想的情況。針對點陣字符不連續的問題,Vandana等[5]利用數學形態學對其進行處理,能較好地分割點陣字符區域,在LED點陣字符上具有較好的識別結果,但該方法在字符分割時未考慮到字符粘連的情況。Ohyama等[6]提出了角點檢測和MQDF(Modified quadratic discriminant function)分類器結合的點陣字符識別方法,但在應用于運動模糊圖像時,其魯棒性還需進一步改進。南陽等[7]提出了一種基于深度學習的方法,使用Arimoto熵對圖像進行閾值化,然后使用卷積神經網絡隱式地提取字符特征,能夠較為完整地保留字符信息,該方法對于字符背景單一的圖像具有較好的識別效果,但不合適樣本數量少且復雜的圖像集。張國云等[8]提出了一種改進的BP網絡,使用該網絡對車牌字符進行識別具有較強的抗干擾能力和識別效果,對本文具有一定參考價值。
本文主要研究如何快速準確地識別牛奶盒包裝頂部的生產日期,這部分信息由噴墨技術產生的點陣字符組成,存在背景復雜、字符不連續和不相關字符干擾等問題。面對此類問題,文獻[1-8]存在一定的局限性,不能達到較好的識別效果。因此,本文提出了一種基于改進的連通域分割與BP神經網絡相結合的字符識別方法。該方法首先對圖像進行預處理,減少噪聲干擾,然后通過數學形態學與特征篩選定位點陣字符區域,接著對字符區域進行基于連通域最小外接矩形等間距分割,最后將分割后的字符送入到BP神經網絡進行識別。在定位與分割過程中,該方法能有效排除干擾區域,準確快速分割粘連字符,提高了字符識別結果的準確性,與傳統方法相比其適應性更強。
2 方法設計
本文以牛奶包裝盒頂部的點陣字符圖像作為目標研究對象。點陣字符識別的研究工作主要分為以下四個部分:(1) 預處理用于去除圖像噪聲、光照不均勻等客觀因素的干擾,增強圖像信息;(2) 字符定位用于獲取感興趣字符所在的區域,排除其他字符、圓形圖案和粗線條等的干擾;(3) 字符分割用于去除因膨脹操作造成的點陣字符間粘連問題,分割出單個字符;(4) 字符識別用于識別分割字符所表示的信息。
2.1 預處理
在灰度圖像中,目標和背景之間有著較大的邊緣差異,故利用這一點對兩者進行分離。首先,將采集到的圖像轉化為灰度圖像;其次,利用Canny算子對灰度圖像進行邊緣檢測,Canny算子能夠有效地平滑圖像、濾除噪聲,且具有很強的魯棒性。預處理后的圖像如圖1所示。

圖1 預處理圖像
2.2 字符定位
為了定位圖像中的點陣字符區域,本文采用數學形態學與連通域分析組合的方式對預處理圖像進行定位,選取行列位置信息和面積大小作為定位特征。經過預處理之后,圖像中依舊存在大量非目標區域,觀察圖1,可發現點陣字符與噪點、中文字符、粗線條等干擾區域的面積差異不明顯,不能直接使用面積特征。膨脹操作可擴大圖像的邊緣,填充黑洞,使得面積特征差異化明顯。因此本文采用矩形結構元素對預處理圖像進行膨脹。設定矩形結構元素大小為220×5,滿足點陣字符區域在水平方向能連接成一個連通域,并使其連通面積盡可能大,同時在垂直方向上避免上下兩行字符粘連形成一個連通域。膨脹操作后的圖像如圖2所示;將其填充為矩形區域,方便統計圖像的行列特征值和面積特征值,填充后的區域如圖3所示;其行列特征和面積特征如圖4和圖5所示。

圖2 膨脹圖像

圖3 填充圖像
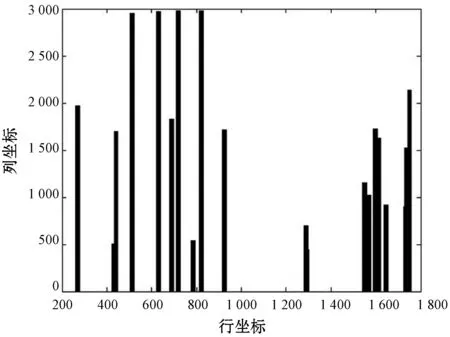
圖4 連通域行列坐標特征
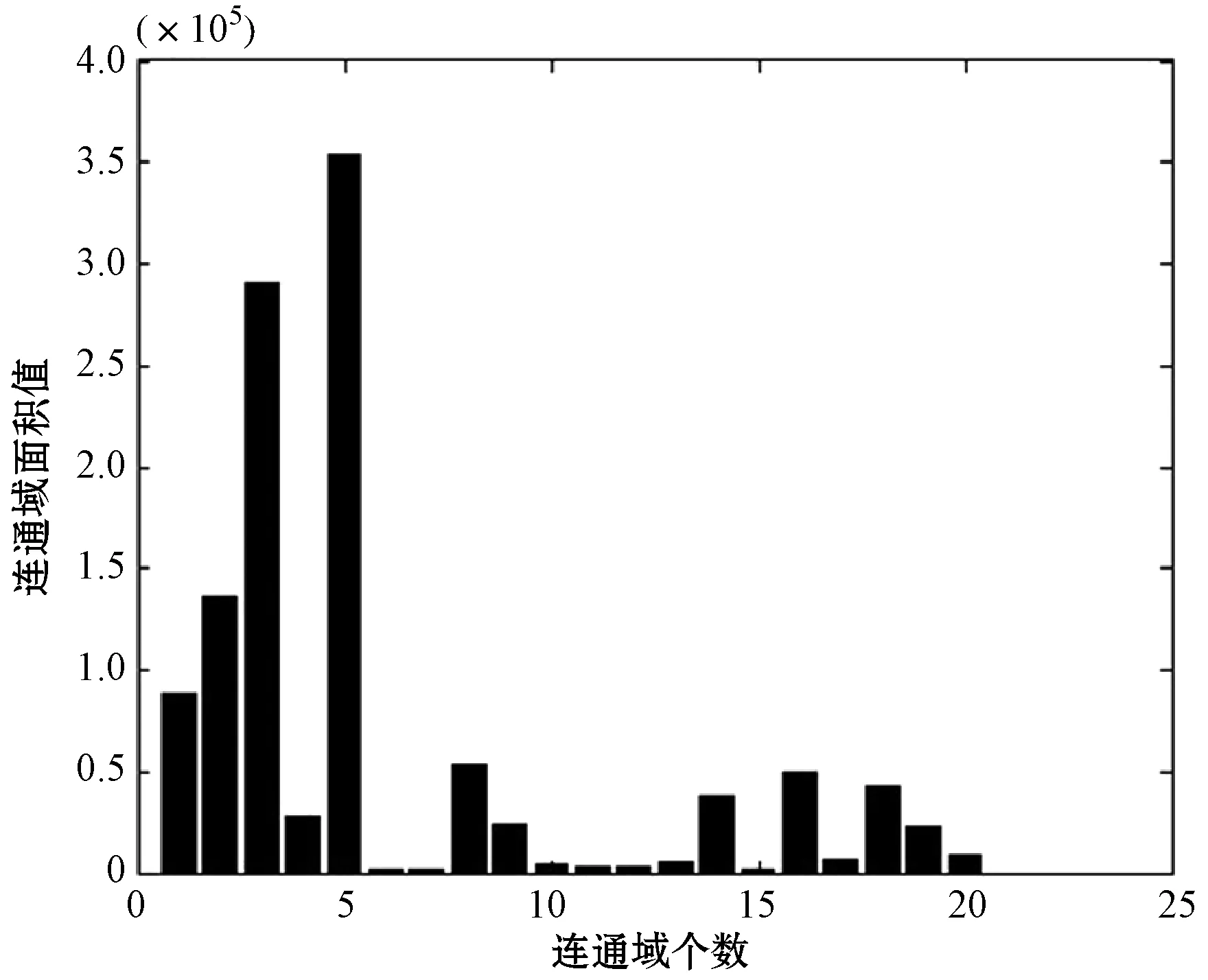
圖5 連通域面積值特征
對數學形態學和連通域分析處理后的圖像進行特征篩選的具體步驟如下:
(1) 根據多次實驗結果,設定行列坐標閾值為(C1,C2)和(R1,R2),面積閾值為S1。填充圖像的點陣字符行列坐標值應在(C1,C2)和(R1,R2)范圍內,其面積應大于S1,而干擾區域面積應小于S1。
(2) 計算特征值。計算填充圖像所有連通域的行列特征值和面積特征值,若特征值在設定閾值內,則輸出該連通域,否則將其濾除。
(3) 定位。特征篩選的結果如圖6所示,將其與預處理圖像取交集,獲得點陣字符圖像,如圖7所示。

圖6 篩選結果

圖7 點陣字符
數學形態學與連通域分析組合的方法可有效地去除噪聲和其他非點陣字符干擾,快速準確地定位到點陣字符區域。
在生產過程中,噴墨機噴墨角度或產品位置易發生變化,導致點陣字符傾斜,如圖8所示。
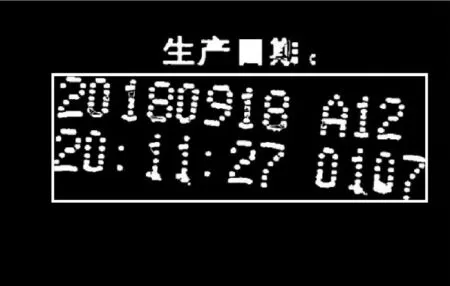
圖8 傾斜字符圖像
針對這種情況,本文采用二階矩[9]與雙線性插值法[10]對圖像進行傾斜校正。點陣字符區域的傾斜角度φ計算如下:
φ=-0.5atan2(2M11,M02-M20)
(1)
式中:M11、M02、M20是篩選結果圖像的二階矩。
再根據仿射變換原理,求出傾斜校正矩陣,矩陣計算過程如下:
(1) 定義齊次變換矩陣M為:
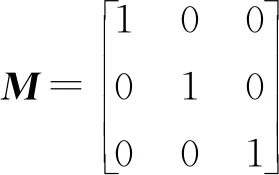
(2)
(2) 利用字符傾斜角φ計算旋轉變換矩陣R:
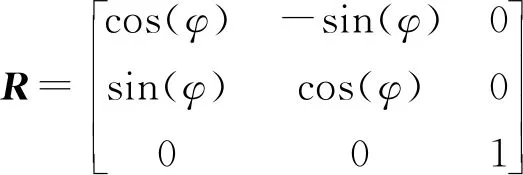
(3)
(3) 選取字符區域的中心點(Px,Py)作為固定點,對矩陣M進行平移變換,將固定點移動到全局坐標系的原點上,然后進行旋轉變換,最后將固定點平移至其原始位置,得到變換矩陣Y:
(4)
將得到的變換矩陣應用于仿射變換中,采用雙線性插值法計算校正后像素點的灰度值。校正結果如圖9所示。
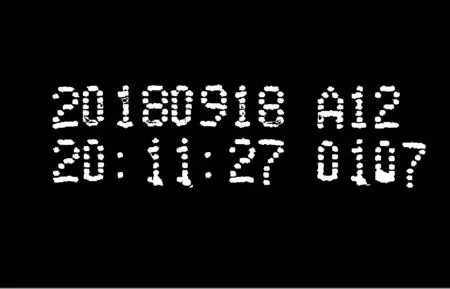
圖9 校正結果
2.3 字符分割
接下來對定位得到的點陣字符進行分割。傳統的連通域分割采用Two-Pass算法[11]對圖像進行兩遍掃描,按照行或者列的方式遍歷像素。第一遍掃描對圖像中像素值相等且位置相鄰的前景像素點進行標記,同一個連通域的像素點可能會有一個或者多個不同的標記,記錄像素點之間的相等關系;第二遍掃描就是將具有相等關系的不同標記像素點賦予相同的標記值并將其合并得到完整的連通域,從而實現連通域分割。該方法適用于不粘連且連續的字符,而本文的點陣字符具有不連續性。針對傳統連通域方法的局限性,本文提出了基于改進的連通域分割方法。該方法在傳統連通分割的基礎上,對連通域最小外接矩形進行二次等間距分割。點陣字符分割流程如圖10所示。

圖10 點陣字符分割流程
分割具體步驟如下:
1) 初次分割。對定位后的點陣字符進行膨脹操作,得到連續的粘連字符。采用傳統的連通域分割方法對其進行初次分割,分割后的連通域由不同的顏色標記,如圖11所示。

圖11 初次分割
2) 交集操作。將初次分割結果與定位后的點陣字符做圖像交集操作,結果如圖12所示。交集結果按水平方向排序,第四個連通域包含“9”和“0”兩個字符,第五個連通域包含“6”“3”“0”三個字符。
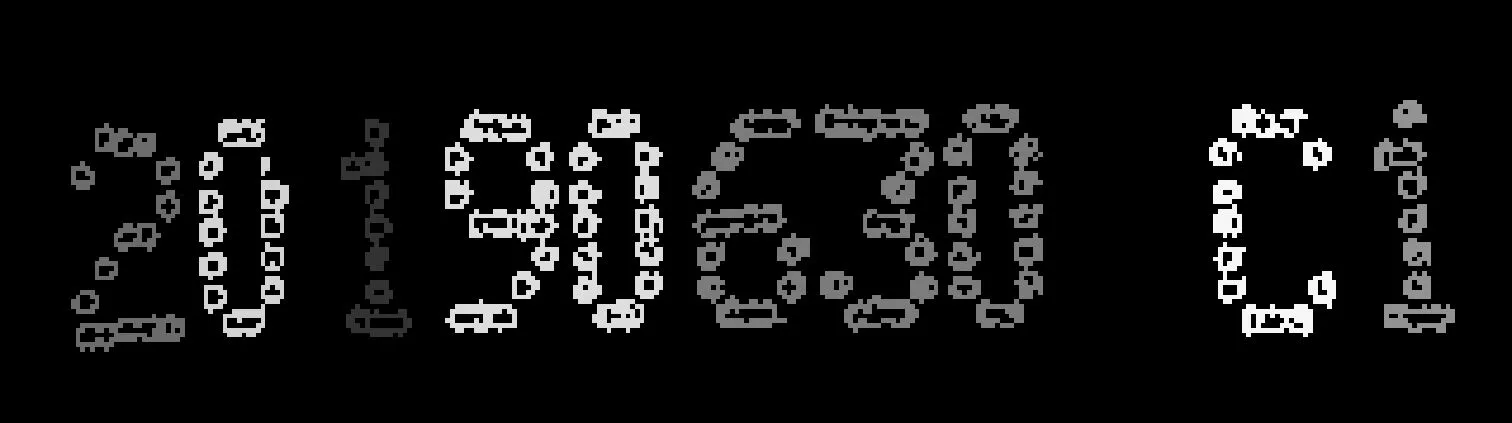
圖12 交集結果
3) 矩形計算。設定一個大小為width1×height1的矩形,作為分割標準。找到并生成交集結果中每個連通域對應的最小外接矩形,如圖13所示,記錄生成矩形的大小,用width2×height2表示。

圖13 連通域最小外接矩形
4) 二次等間距分割。依次判斷最小外接矩形的寬高是否大于標準矩形,如果大于,則按照標準矩形寬高將最小外接矩形劃分為幾個大小近似的矩形,僅當最小外接矩形的大小至少是標準矩形的1.5倍時,才會進行等間隔分割。如果最小外接矩形寬高小于標準矩形,則保持該矩形輸出不變。
5) 單個字符獲取。等間距分割后的圖像如圖14所示。將其與定位后的點陣字符圖像進行交集操作,即可得到單個字符圖像,如圖15所示。

圖14 等間距分割矩形

圖15 單個字符分割圖像
2.4 字符識別
本文方法采用BP神經網絡進行字符識別。BP神經網絡[12]是一種多層前饋神經網絡,由輸入層、隱藏層和輸出層組成,如圖16所示。圖中:w0表示輸入層到隱藏層的權重,w1表示隱藏層到輸出層的權重,N、M、P分別表示輸入層、隱藏層和輸出層的神經元個數。BP神經網絡的工作過程主要分為兩個階段:第一個階段信號正向傳播,從輸入層經過隱藏層,最后到達輸出層;第二個階段誤差反向傳播,誤差從輸出層通過隱藏層向輸入層反向傳遞,并依次調節各層之間的權重。
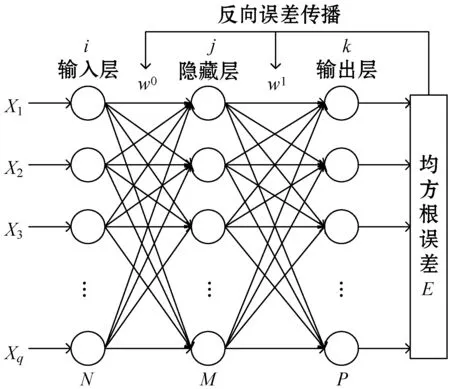
圖16 BP神經網絡
對于訓練數據樣本Xq,經過隱藏層激活函數作用后輸出hjq為:
(5)
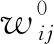
(6)
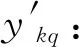
(7)
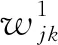
正向傳播完成后,得到的預測值y′與真實值y之間存在誤差,選用誤差平方和表示:
(8)
采用梯度下降法,并通過正向傳播和反向誤差傳播不斷更新各層之間的權重,將誤差降低到最小,權值修正為:
(9)
式中:ΔW(l)表示第l次訓練的權重;α、η分別表示動量系數和比例系數。
3 實 驗
3.1 實驗平臺和數據
本文針對牛奶盒頂部的點陣字符,提出了一種基于改進的連通域分割與BP神經網絡相結合的字符識別方法。為了驗證該方法的性能,本文在VS2015實驗平臺上聯合Halcon視覺庫對其進行仿真實驗。
為了驗證本文算法在圖像背景復雜、字符粘連和字符傾斜等情況下的性能,本文采集了150幅牛奶盒外包裝頂部圖像作為數據集。其中,隨機選取80幅作為訓練圖像,70幅作為測試圖像。每幅圖像共22或23個字符,其內容為生產日期、生產時間、生產流水號和產品序號,由數字“0-9”,字符“A”“C”和特殊字符“:”組成,一共13個類別。
3.2 分類器訓練
BP神經網絡離線訓練分類器過程如下:
1) 訓練集準備。通過采用本文提出的字符分割方法對80幅訓練圖像進行處理,得到單個字符圖像,建立對應的字符標簽,生成字符訓練文件。
2) 由于本文采用BP神經網絡對字符進行識別,因此需要對網絡中各層的神經元個數進行設定。在輸入層,本文將字符圖像統一到8×10的大小進行輸入,因此輸入層共包含80個神經元。在隱藏層,神經元的個數一般為輸入層的兩倍,經本文實驗驗證得將其設置為180個時的效果最好。在輸出層,字符類別決定了神經元的個數,因此輸出層包含13個神經元。
3.3 粘連字符分割對比
為了進一步驗證本文字符分割算法對粘連字符的有效性,實驗一共測試了70幅點陣字符圖像,與傳統分割方法進行對比。例如,針對表1中點陣字符的粘連樣式,文獻[1]采用垂直投影法對其進行處理,在字符間存在空隙的情況下,垂直投影為零,則可以分割字符,但在字符粘連的情況下,垂直投影不為零,則無法進行分割。文獻[2]提出一種改進的垂直投影法,該方法根據字符固定寬度對其進行二次分割,有效提高了分割準確度。文獻[3]采用連通域方法對其進行分割,首先對不同的連通域進行標記,然后根據其坐標信息對字符進行分割,但該方法無法區分同一個連通域的多個字符,即無法分割粘連字符。而本文方法在連通域分割的基礎上進行了二次分割,可以有效地分割同一行的相鄰粘連字符和不同行的粘連字符,如表1所示。
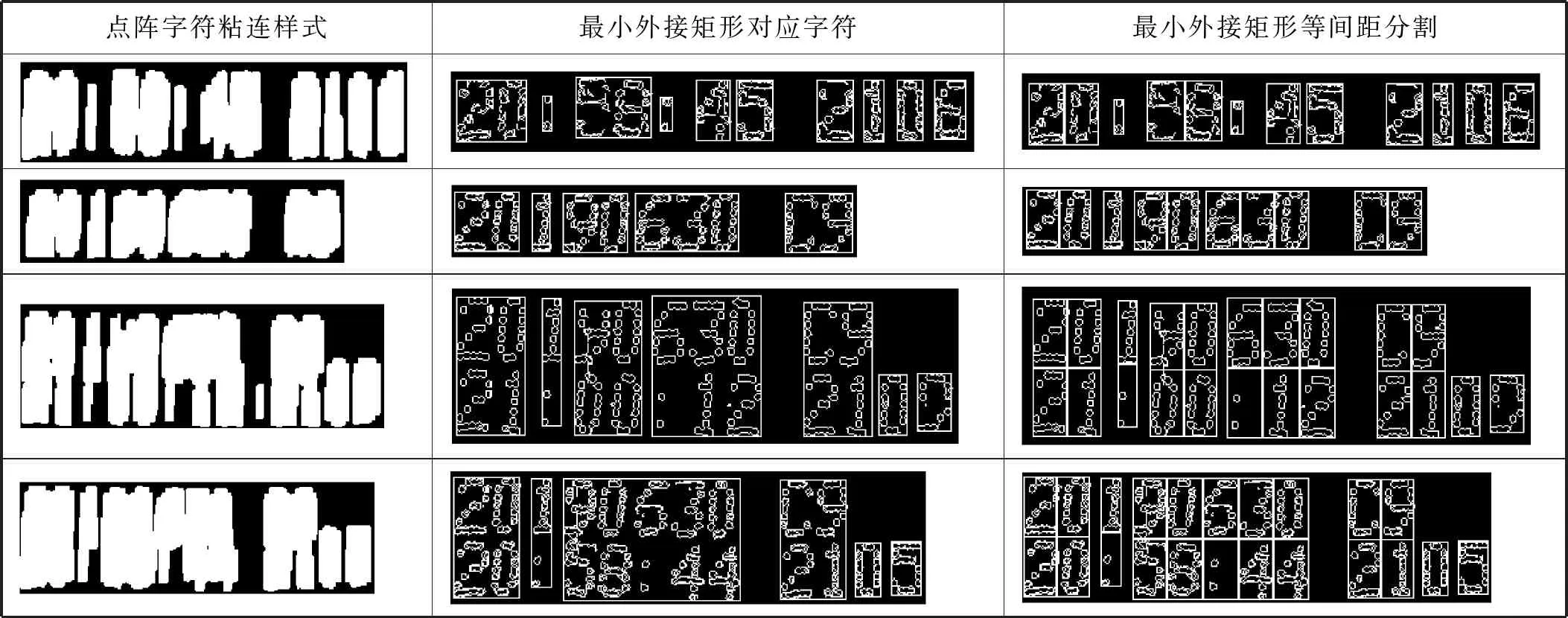
表1 不同粘連類型分割結果
本文采用分割準確性來評估所提出的字符分割方法,如式(10)所示。實驗結果如圖17所示,本文算法的分割準確性達到了98.64%,明顯優于其他三種方法,具有更好的分割效果,可以應用于實際牛奶生產日期字符的分割。
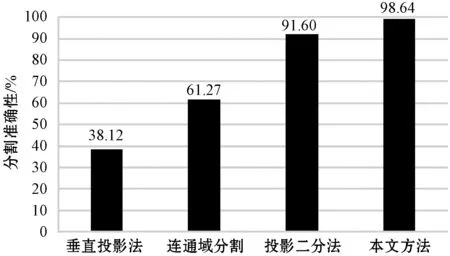
圖17 不同方法間的分割準確性比較
(10)
3.4 點陣字符識別準確率比較
為了驗證本文方法的有效性,本文測試了70幅圖像與文獻[13-15]的方法進行對比,并且采用式(11)對BP神經網絡的字符識別準確性進行評估,實驗結果如圖18所示。
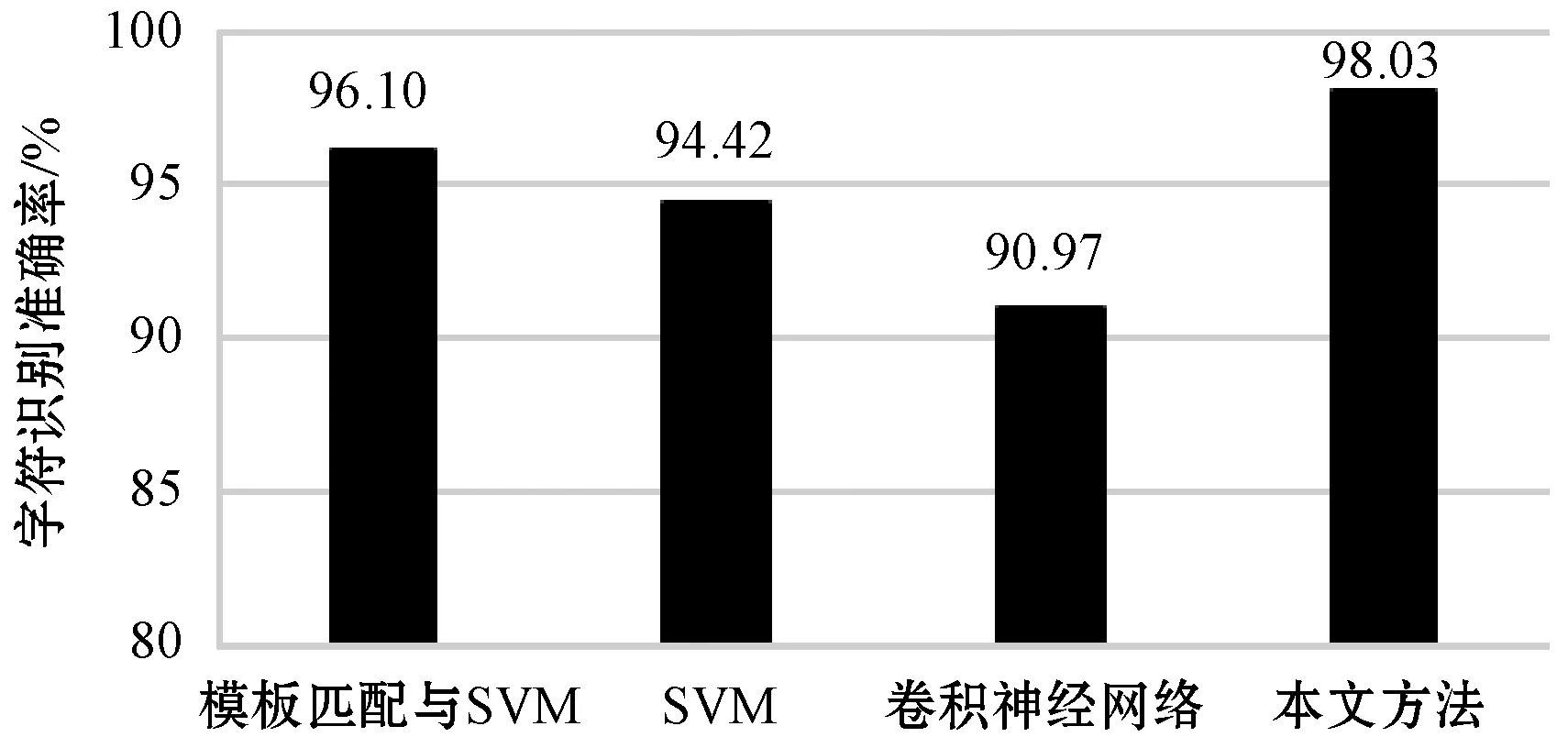
圖18 不同方法識別準確率比較
(11)
文獻[13]提出的基于模板匹配與SVM的點陣字符識別方法,考慮到了字符的離散性質且通過兩次識別操作保證了識別結果的準確性。文獻[14]結合網格統計方法和投影密度法來提取特征向量,然后利用SVM來識別點陣字符。文獻[15]提出了基于卷積神經網絡的點陣字符識別方法,保留了字符的原始特征。上述方法在字符分割階段未考慮字符的粘連性,而本文提出的基于改進的連通域分割與BP神經網絡結合的字符識別方法,綜合考慮了圖像背景的復雜性和點陣字符經形態學處理后的粘連情況,能準確快速地定位和分割字符,從而有效地提高了字符識別準確率。
4 結 語
目前大多數字符識別方法主要針對字符背景單一、字符清晰和字符連續等情況,沒有考慮到點陣字符的不連續性、圖像背景復雜性及字符的粘連性等問題。針對上述問題,本文提出的基于改進連通域分割與BP神經網絡結合的點陣字符識別方法通過數學形態學定位點陣字符區域,有效地去除了干擾區域,然后基于連通域的最小外接矩形對粘連字符進行二次分割,得到較為完整的單個字符。與傳統分割方法相比,本文字符分割方法的準確性提高了7百分點以上。最后將分割好的單個字符輸入到BP神經網絡進行識別,識別準確率達到了98.03%,每幅圖像識別平均耗時大約為220 ms,可快速地對點陣字符進行識別。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
