基于改進的多模態神經網絡圖像描述方法
2021-09-15 11:20:20李柯徵王海涌
計算機應用與軟件 2021年9期
李柯徵 王海涌
(蘭州交通大學電子與信息工程學院 甘肅 蘭州 730070)
(蘭州交通大學甘肅省人工智能與圖形圖像處理工程研究中心 甘肅 蘭州 730070)
0 引 言
硬件的發展推動了人工智能的發展,作為人工智能分支的自然語言處理(Natural Language Processing, NLP)和計算機視覺(Computer Vision, CV)逐漸成為近幾年廣大研究者們研究的熱點。NLP主要研究的是理解自然語言,常用于實現命名實體識別、文本分析、機器翻譯、語音識別等。CV則主要研究的是圖像分類、對圖像中的目標進行檢測、圖像的語義分割、圖像修復等。
互聯網技術的飛速發展以及數碼設備的快速普及,帶來了圖像數據的迅速增長,使用純人工來鑒別圖像內容變得十分困難。同時,隨著深度神經網絡的興起,處理日漸繁多的圖像數據成為一種可能,因此,如何通過計算機自動提取圖像所表達的信息成為了研究人員所關注的熱點。圖像描述是指機器自動生成描述圖像的自然語言,它能夠實現圖像到文本信息的多模態轉換,是一項融合了NLP和CV的綜合任務。最早的圖像描述模型是由Farhadi等[1]提出的,該模型給定二元組(I,S),其中:I表示圖像;S表示摘要句子。能夠完成從圖像I到摘要句子S的多模態映射I→S。圖像描述的研究雖然仍處于初級階段,但是它在圖像檢索、機器人問答、輔助盲人等方面有著很好的應用前景,具有重要的現實意義。
Socher等[2]用深度神經網絡分別學習圖像和文本模態表示,然后映射到多模態聯合空間;Kulkarni等[3]將圖像中的對象、屬性和介詞等相關信息表示成三元組,然后使用預先訓練好的N-gram語言模型生成流暢的文本描述句子;Mao等[4]提出的多模態循環神經網絡(Multimodal Recurrent Neural Network,M-RNN)使用CNN對圖像建模、RNN對句子建模,并利用多模態空間為圖像和文本建立關聯;Vinyals等[5]提出了谷歌NIC模型,該模型將圖像和單詞投影到多模態空間,并使用長短時記憶網絡生成摘要;Zhou等[6]提出一種基于text-conditional注意力機制的方法,該方法強調關注描述句子中的某個單詞,使用文本信息改善局部注意力;Zhang等[7]將強化學習應用在圖像的文本描述生成中。然而,現有方法依然存在梯度消失導致的模型描述性能不佳、缺失語義信息,以及模型結構無法關注圖像中的重點而導致模型與圖像特征之間語義信息關聯性不足等問題。
為了改善目前圖像描述方法所存在的問題,本文以多模態循環神經網絡M-RNN為基線模型,提出在圖像處理部分加入卷積注意力模塊(Convolutional Block Attention Module,CBAM)[8]使模型更關注圖像中的重點,并使用門控循環單元(Gated Recurrent Unit,GRU)來優化M-RNN的語言處理部分。改進后的模型在描述性能上得到了有效的提升,并且改善了模型與圖像特征之間語義信息關聯性不足的問題。
1 相關工作
1.1 多模態循環神經網絡M-RNN
M-RNN可以為輸入的圖像生成描述句子來解釋圖像的內容,是一種基于概率的神經網絡模型。該模型將圖像描述生成分為兩個分支任務,使用CNN提取圖像特征,使用RNN建立語言模型。M-RNN中的圖像部分采用AlexNet[9]結構提取圖像特征(在Mao等[10]后續的研究中,模型里的CNN采用了VGGNet[11]結構,實驗證明在M-RNN模型中VGGNet的效果要好于AlexNet),語言部分使用RNN處理詞向量,之后在多模態層將圖像特征與語言特征相結合,最后經過Softmax層預測產生描述單詞。
M-RNN模型的每個時間步包含了5層:兩個詞嵌入層,循環層,多模態層,Softmax層。在圖像描述任務中,它們發揮了至關重要的作用:詞嵌入層可以將輸入的one-hot編碼的詞向量轉化為稠密詞向量,之后循環層對稠密詞向量進行序列化處理,在多模態層會融合語言模型和圖像處理得到的特征向量,最后經過Softmax層生成預測單詞的概率分布。
1.2 VGG-16網絡
VGG-16網絡是常用的VGGNet模型,由13個卷積層和3個全連接層疊加而成,主要用來提取圖像特征。將VGG-16網絡中的Softmax層移除,并把第15層與M-RNN中的多模態層進行連接,即可把抽取的圖像特征在多模態層和語言特征進行融合。VGG-16網絡如圖1所示,其中FC表示全連接層。
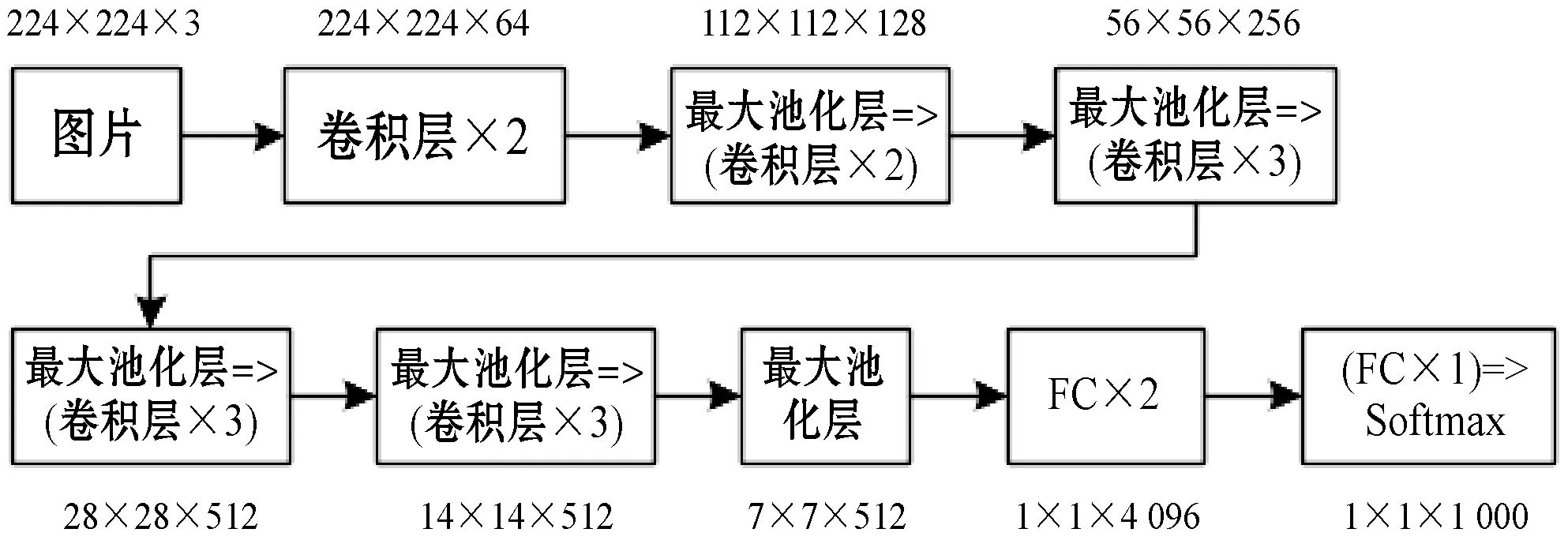
圖1 VGG-16網絡圖
1.3 注意力機制
人類的視覺注意力是一種特有的大腦信號處理機制,可以幫助人類獲得需要重點關注的目標區域,以獲取更多目標區域的細節信息,注意力機制則是對人類視覺注意力的模擬。已經有很多研究表明將注意力機制應用到圖像描述任務當中,可以顯著提高語義表示的準確性。
Anderson等[12]使用了自下而上和自上而下的組合注意力機制,讓每個圖像區域關聯相應的特征向量并確定相應的特征權重,從而計算目標對象與其他顯著圖像區域之間的注意力權重;Aneja等[13]提出一種用于圖像描述的使用注意力機制的卷積模型;Wang等[14]使用了一種視覺CNN和語言CNN相結合的方法(CNN+CNN),并利用分層的注意力機制連接了兩個CNN;靳華中等[15]提出了一種結合局部和全局特征的帶有注意力機制的圖像描述生成模型。
2 本文方法
本文方法是一種基于M-RNN改進的圖像描述方法,為了改善模型的描述性能和模型與圖像之間關聯性不足的問題,針對M-RNN的語言模型和圖像特征提取兩方面進行了改進。由于M-RNN中的語言模型部分使用了RNN,在訓練的過程中,RNN的神經元更新容易出現梯度消失的問題,從而使模型不擅長處理較長的上下文文本,所以本文提出在M-RNN中使用GRU門控循環單元來優化文本序列的生成。而對于圖像特征提取部分,M-RNN僅僅使用了VGG-16網絡來提取圖像特征,無法對圖像中的關鍵部分進行重點關注,會導致生成的圖像描述文本與圖像表達的重點出現偏差,所以提出在VGG-16網絡中引入CBAM卷積注意力模塊來解決這一問題。
2.1 使用GRU優化序列生成
GRU是由Cho等[16]提出的一種RNN模型,該模型在RNN的基礎上使用更新門和重置門來處理信息流,其中更新門用來決定要忘記哪些信息以及哪些新信息需要被添加,重置門用來決定有多少信息需要被遺忘。其結構如圖2所示。

圖2 GRU內部結構
GRU不僅可以解決普通RNN梯度消失而導致的缺乏長期記憶的問題,而且其構造較之于常用的長短時記憶網絡LSTM更加簡單且參數更少,所以在進行訓練數據量大的任務時,速度更快,因此本文引入了GRU來優化文本序列的生成。將經過詞嵌入層處理的詞向量wt和上一隱層的激活值ht-1作為GRU的輸入,得到時間步t的激活值ht,隨后將ht在多模態層與詞向量wt和圖像特征I融合,最后通過Softmax層預測文本,在經過n個時間步后,得到文本序列。以下是GRU單元的內部更新公式:
(1)
zt=σ(Wzwt+Uzht-1)
(2)
(3)
rt=σ(Wrwt+Urht-1)
(4)
式中:σ表示Sigmoid函數;W和U表示要學習的權重。
分析以上公式:


4) 式(4)中重置門信號rt會判定ht-1對結果ht的重要性,如果ht-1和新的記憶計算不相關,那么重置門就可以完全地消除過去隱藏狀態的信息。
在每一個時間步t的處理過程中,經過GRU處理得到的激活值ht會輸入到多模態層與稠密詞向量wt、圖像特征I進行加融合[17],公式如下:
mt=g2(Vw·wt+Vr·ht+VI·I)
(5)
式中:m代表各個特征在多模態層融合后得到的特征向量;V代表要學習的權重;g2(·)為雙曲正切函數[18]。
(6)
2.2 卷積注意力模塊CBAM的使用
2.2.1卷積注意力模塊
注意力機制本質上是模仿人類觀察物品的方式。通常來說,當人在看一幅圖片時,除了從整體把握一幅圖片之外,也會更加關注圖片的某個局部信息,例如局部桌子的位置、商品的種類等。人類正是利用了一系列局部瞥見并選擇性地聚焦于顯著部分,所以能夠更好地捕捉視覺信息。注意力機制其實包含兩方面內容:(1) 決定整段輸入的哪個部分需要更加關注;(2) 從關鍵的部分進行特征提取,得到重要的信息,因此它的核心目標就是從眾多信息中選擇出對當前任務目標更關鍵的信息。
CBAM是一種用于前饋卷積神經網絡的簡單而有效的注意力模塊,該模塊包含了通道注意力模塊和空間注意力模塊兩個子模塊,當給定一個中間特征圖時,特征圖會分別沿著CBAM中的通道和空間兩個維度依次推斷出注意力權重,然后與原特征圖相乘來對特征進行自適應調整。其中通道注意力模塊用來關注什么樣的特征是有意義的,可以對一些無意義的通道進行過濾得到優化的特征,而空間注意力模塊則用來關注哪里的特征是有意義的。通過兩個子模塊的協調作用,特征F轉化為更具表現力的特征F*。作為一種輕量級的通用模塊,CBAM可以無縫地集成到任何 CNN 結構中,開銷可以忽略不計,并且可以與CNN一起進行端到端的訓練。
2.2.2在VGG-16中引入CBAM
本文方法中的提取圖像特征部分將CBAM模塊加入到了VGG-16結構中,在VGG-16的3個14×14×512的卷積層之間分別引入了一次CBAM模塊,結構如圖3所示。
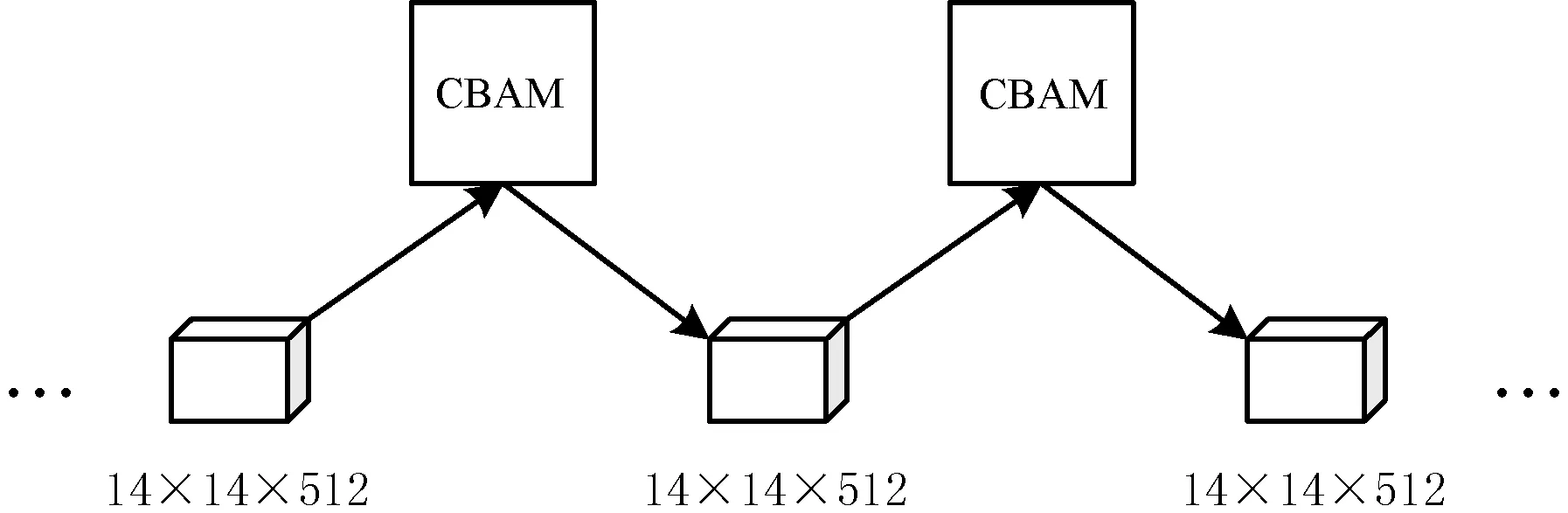
圖3 在VGG-16中引入CBAM
本文方法中引入CBAM模塊的VGG-16使用了兩次CBAM注意力模塊來對圖像進行自適應調整。每一次自適應調整,CBAM依據給定的中間特征映射F∈RC×H×W作為輸入,其中:C表示圖像特征的通道數;H和W分別表示圖像特征的高和寬。依照式(7)推斷出一個一維通道注意力圖譜Mc∈RC×1×1,然后按照式(8)對原特征F與Mc進行張量乘積得到通道注意力特征F′,緊接著根據式(9)獲得一個二維的空間注意力圖譜Ms∈R1×H×W,最后根據式(10)將空間注意力映射圖譜Ms乘以特征F′得到原特征F的最終自適應特征F″。該過程如圖4所示。

圖4 VGG-16中的CBAM
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=
(7)

F′=Mc(F)?F
(8)
Ms(F′)=σ(f7×7([AvgPool(F′);MaxPool(F′)]))=
(9)
式中:f7×7表示表示卷積核大小為7×7的卷積運算。
F″=Ms(F′)?F′
(10)
2.3 模型訓練
圖像提取部分使用預訓練過的包含了CBAM的VGG-16網絡,利用對數似然成本函數來訓練本文模型,對數似然成本函數與訓練集中相應圖片的參考句的困惑度有關,困惑度則是評價語言模型的一個標準尺度,一條句子w1:L的困惑度計算公式如下:
(11)
式中:L代表句子的長度;log2PPL(w1:L|I)表示圖片I對應的句子w1:n-1的困惑度;P(wn|w1:n-1,I)表示給定圖片I和單詞序列w1:n-1時生成單詞wn的概率。訓練模型選取的成本函數是由訓練集給定上下文和相應圖片得到的預測詞的平均對數似然函數加上正則化項得到的,公式如下:
(12)
式中:Ns表示訓練集中句子的數目;N表示訓練集中所有單詞的數目;Li表示第i個句子的長度;λθ表示要學習的權重;θ代表模型的參數。使用反向傳播算法訓練模型,訓練目標是最小化該成本函數,即在訓練集上使用該模型最大化生成句子的概率。
基于改進的多模態神經網絡圖像描述方法如算法1所示。
算法1基于改進的多模態神經網絡圖像描述方法
輸入:MSCOCO圖像數據集,文本數據集。
輸出:圖像描述文本。
對于數據集中的圖像及其對應的參考句采取如下步驟:
Step1使用引入了CBAM注意力模塊的VGG-16網絡提取圖像特征I。
Step2經過兩層詞嵌入對單詞編碼得到稠密詞向量wt。
Step3將詞向量wt,前一層GRU隱含層ht-1,輸入下一層GRU,計算ht。
Step4對wt、ht、I進行加融合。
Step5通過損失函數計算損失,反饋調整參數。
Step6返回Step2,直到輸出為
Step7返回圖像描述文本。
3 實 驗
3.1 實驗環境和數據
實驗使用的硬件設施為一臺具有型號為i7-7800X的主頻為3.5 GHz、睿頻為4 GHz的六核十二線程Intel CPU,以及一塊CUDA核心數為3 584、顯存容量為11 GB的NVIDIA GTX 1080TI的GPU的電腦。軟件方面使用64位的Linux操作系統,采用了GPU 版本的TensorFlow深度學習框架,安裝了NVIDIA CUDA8.0工具包以及cuDNN-v5.1深度學習庫,并基于Python2.7版本的PyCharm開發環境進行實驗。
本文采用的數據集為MSCOCO2014[19]數據集。MSCOCO數據集是由微軟團隊提出的用于圖像識別、圖像語義分割和圖像描述的大規模數據集,該數據集的目標是通過將對象識別問題放在更廣泛的場景理解問題的背景下,提高對象識別的技術水平,同時對于提到圖像描述的準確性也具有深刻意義。為了能夠與原算法形成鮮明對比,突出本文改進后算法的優越性,文中使用的數據集采用了與文獻[4]中一樣的MSCOCO數據集,并將該數據集劃分為包含82 783幅圖像的訓練集和包含40 504幅圖像的驗證集。對于每一幅圖像,都有對應的5個參考描述句子。進行實驗時,從驗證集中分別隨機選取4 000幅圖像進行驗證,以及1 000幅圖像進行測試。
進行實驗前,對數據集進行進一步的了解,通過對數據集進行分析可知,數據集中圖像參考句的單詞數目大多集中在9個單詞到16個單詞之間,分析結果如圖5所示。所以在實驗中使用句子長度小于等于16個單詞的參考句來構建單詞表,這樣可以使模型生成的句子更具代表性。
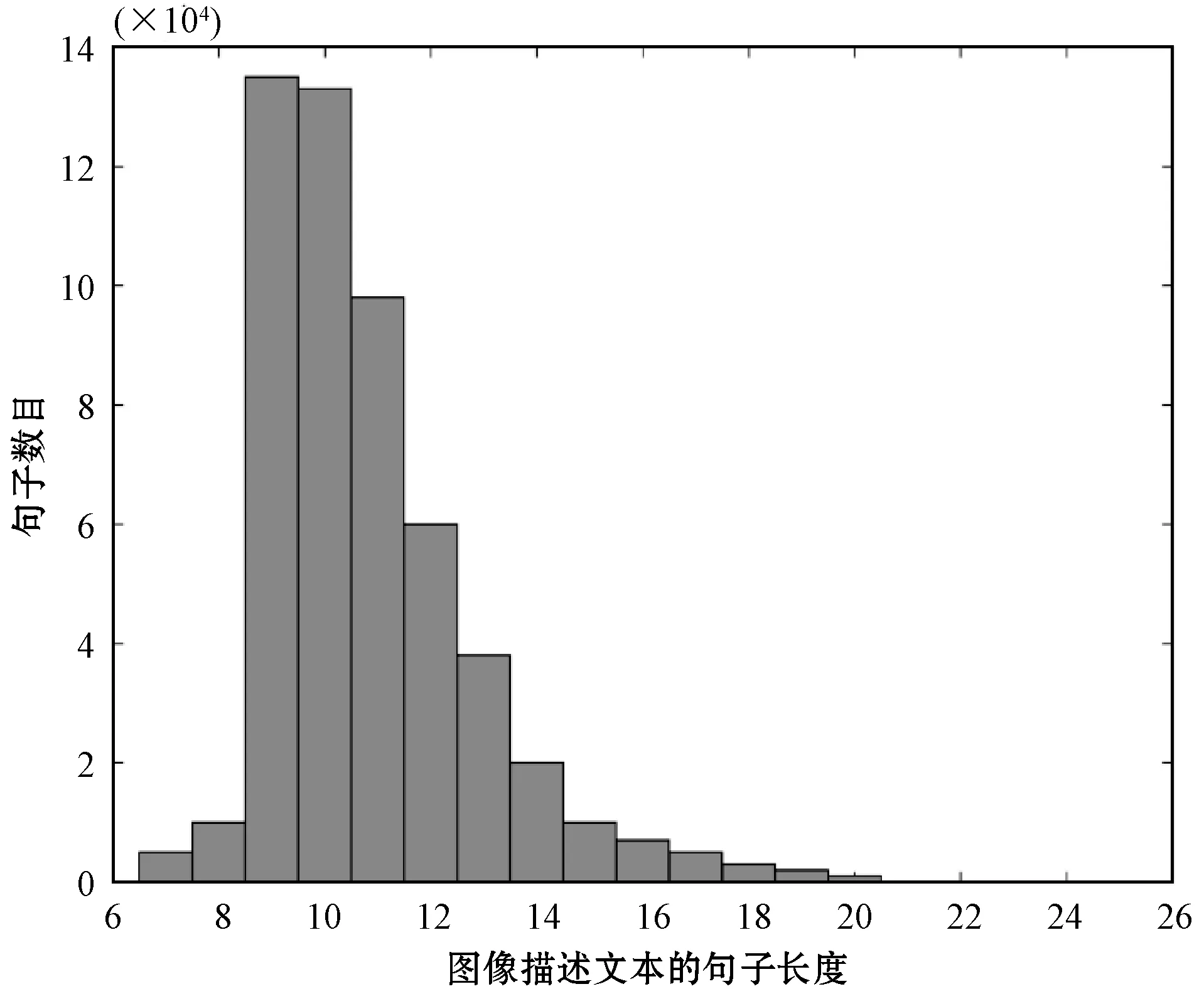
圖5 數據集中參考句的長度分布
3.2 實驗方法及參數設置
為了驗證本文方法的有效性,實驗中對本文方法和M-RNN、谷歌的NIC、DeepVS[20]、文獻[13]提出的卷積模型,以及CNN+CNN等模型進行了實驗對比,使用BLEU[21]、METEOR[22]和CIDEr[23]三種指標來衡量圖像描述文本的質量。并且采用了人工主觀抽檢的方式對改進方法和原方法生成的圖像描述文本進行評價分析。同時為了證明CBAM注意力機制對圖像特征產生了積極影響,使用梯度加權的類激活映射(Gradient-weighted Class Activation Mapping ,Grad-CAM)[24]算法對圖像特征進行了可視化對比。
在訓練之前,使用MSCOCO數據集中的參考句構建單詞表,本文選取句子長度小于等于16個單詞的參考句來構建單詞表,最終確定的單詞表大小為13 691。實驗中采用反向傳播算法對模型進行訓練,將初始學習率設置為1.0,學習衰減率設置為0.85,批大小設置為100,在訓練集上總共迭代50次。并且在訓練時,采用dropout正則化方法,按一定概率使詞嵌入層、循環神經網絡層和多模態層中的某些神經網絡單元隨機失活來預防過擬合的發生,本文實驗中dropout值設為0.5。
3.3 實驗結果及分析
圖6對比了本文方法、M-RNN、NIC在MSCOCO2014數據集上的困惑度曲線,展示了三種方法復雜度隨迭代次數的變化,在第50個迭代時,M-RNN的復雜度達到最小12.38,本文方法的復雜度達到最小12.17,NIC的復雜度達到最小12.08。
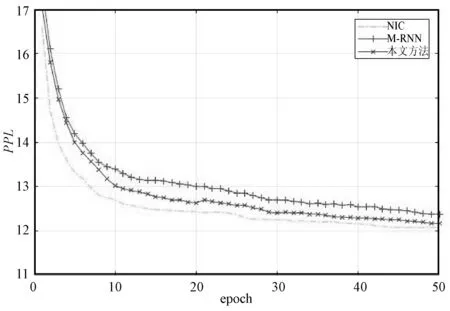
圖6 MSCOCO2014數據集上訓練結果對比
表1使用BLEU-1、BLEU-4、METEOR、CIDEr等評價標準,給出了不同圖像描述模型在MSCOCO驗證集上的得分情況,其中B@1和B@4為BLEU-1得分和BLEU-4得分。可以看出,本文方法的各項得分均高于其他方法,反映出本文方法具有一定的優越性。

表1 不同圖像描述生成模型得分對比結果
圖7為從MSCOCO測試集中選取的幾種不同類型的圖片,使用這些圖片對比了本文改進方法和原方法M-RNN生成的圖像描述句子。圖7(a)M-RNN生成的描述為an elephant is standing in a field,本文方法生成的描述為an elephant is standing in a grassy area;圖7(b)M-RNN生成的描述為a stop sign on the side of the road,本文方法生成的描述為a stop sign on the corner of a street;圖7(c)M-RNN生成的描述為a yellow bus driving down a street,本文方法生成的描述為a yellow bus driving down a street next to a building;圖7(d)M-RNN生成的描述為a group of people in a kitchen,本文方法生成的描述為a group of people standing around a kitchen preparing food;圖7(e)M-RNN生成的描述為a display case with lots of food,本文方法生成的描述為a display case filled with lots of different donuts;圖7(f)M-RNN生成的描述為a baseball player holding a bat,本文方法生成的描述為a baseball player holding a bat at a ball on a field。可以看出雖然兩種方法描述結果相近,但是本文方法描述更加準確,且可以描述出圖像中更加細微的部分。比如,對于圖7(e),M-RNN只是描述了圖中有很多食物“lots of food”,而本文方法生成的句子中“lots of different donuts”不僅描述出食物是甜甜圈,還描述出甜甜圈種類多樣。

(a) 動物類圖像 (b) 環境類圖像
圖8是使用Grad-CAM可視化圖像特征的實驗對比,對比了VGG-16和VGG-16+CBAM的特征區域以及真實類別的Softmax得分P,可視化結果能夠反映特征對結果的貢獻程度。通過Grad-CAM算法的覆蓋圖層可以看出VGG-16+CBAM覆蓋的目標對象區域優于VGG-16網絡,這說明CBAM注意力機制能夠使VGG-16更好地利用目標區域信息并從中聚合特征,同時,也相應提高了目標的分類分數。

P=0.787 32 P=0.898 387
4 結 語
針對當前圖像描述方法描述性能不佳、缺失語義信息,以及模型結構與圖像特征之間語義信息關聯性不足的問題,提出基于改進的多模態神經網絡圖像描述方法。該方法利用GRU型循環神經網絡中的“門”操作在一定程度上解決了普通RNN在復雜模型下由于梯度消失而導致的缺少長期記憶的問題,引入CBAM注意力機制使得模型在提取圖像特征時關注圖像的關鍵部分,從而得到內容更加詳實、信息關聯度更高的圖像描述句子。通過在MSCOCO數據集上進行的實驗驗證本文方法具有良好的性能。隨著自然語言處理與圖像處理理論的日趨完善,在未來工作中,將納入新的方法、技術來探索它們對圖像描述任務的影響。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
語文知識(2014年1期)2014-02-28 21:59:13
