矩陣SVD分解在大學生體育成績方面的指導作用研究
2021-09-21 08:36:42周紅波
合肥師范學院學報 2021年3期
周紅波
(北京工業大學 體育教學部,北京 100124)
1 問題的提出
在信息爆炸的大數據時代,處理海量數據并從中獲得有用信息是所有領域的共同需求。大量的高維數據給人們利用帶來了許多困難。(1)維數災難:要讓智能系統有足夠的學習能力,需要樣本個數至少比樣本維數高出一個數量級。然而當樣本維數過高時,人們很難收集到足夠的樣本;(2)算法失效:高維數據的運算可能使得運算得次數幾何級數增長,從而導致算法失效。要解決這些問題,如何對高維數據進行降維顯得尤其重要。
由于矩陣SVD分解(Singular Value Decomposition,奇異值分解)具有全局最優的數據重構能力,且具有轉置不變性、位移不變性、旋轉不變性和鏡像變換不變性等重要性質,因此,在眾多研究領域都被作為非常有效的降維方法。其中PCA(Principal Components Analysis,主成分分析)方法又稱Karhunen-Loeve變換或Hotelling變換,它是以矩陣SVD分解為基礎的有效特征提取方法之一。
對于任意m×n矩陣,想要將其對角化,SVD分解是一個很好的選擇。下文首先介紹矩陣的SVD分解。
定義1.1[2]設A為n×n方陣,α為一非零向量,若存在常數λ使Aα=λα成立,則稱λ為A的一個特征值,α為A的對應于特征值λ的特征向量。
對于任意的n×n對稱矩陣必可以由其特征值與特征向量對角化[2],而對于非對稱的m×n矩陣A,可以考慮ATA,由于其必定為n×n的對稱矩陣,從而可以對角化。
設A為m×n的矩陣,令v1,v2,…,vn為ATA的單位正交的特征向量,對應的特征值分別為λ1,λ2,…,λn,則有:
即ATA所有特征值均非負,從而可以將其由小到大重新排序,排序后使得特征值滿足:
λ1≥λ2≥…≥λn≥0。
定義1.2[3]矩陣A的奇異值是ATA的特征值的平方根,記為σ1,σ2,…,σn。
定理1.1[3]設A是的m×n的矩陣,那么存在一個m×m的正交矩陣U和一個n×n的正交矩陣V使得A=UΣVT,其中Σ=diag{σ1,σ2,…,σr,0…,0}為一對角陣,r為矩陣A的秩。其中,矩陣U和V分別稱為A的左奇異向量矩陣與右奇異向量矩陣,且不由A唯一確定。
2 SVD分解的應用—CPA分析
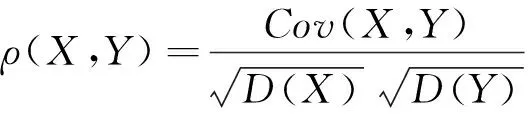
主成分分析的具體方法是對變量的協方差矩陣或相關系數矩陣求奇異值和奇異向量,從下面的定理將看到,對應最大奇異值的奇異向量,其方向正是協方差矩陣變異最大的方向,依次類推,第二大奇異值對應的奇異向量,是與第一個特征奇異正交、且能最大程度解釋數據剩余變異的方向,而每個奇異值的大小則能夠衡量各方向上變異的程度。
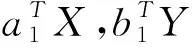

關于上述定義,容易得到:
(1)規范性條件D(αTX)=D(βTY)=1不影響ρ(αTX,βTY)的最大值。
若ΣX,ΣY,ΣXY分別表示隨機向量
X=(X1,…,Xp1)T∈Rp1,
Y=(Y1,…,Yp2)T∈Rp2
的方差矩陣及X與Y間的協方差矩陣為兩個隨機向量,且滿足ΣX,ΣY>0,則下述定理表明典型相關方向、典型相關變量、典型相關系數是存在的。
有關主成分分析理論上有如下結論。
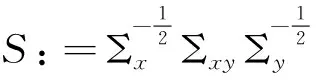
其中U=(u1,…,up1)∈Op1,V=(v1,…,vp2)∈Op2分別為S左、右奇異矩陣,r為S的秩,則
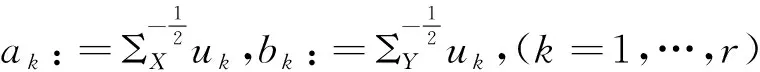

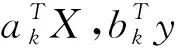
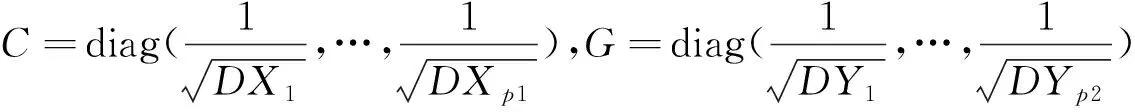
X*=C(X-μ1),Y*=G(Y-μ2)則有
下述定理表明,從相關矩陣出發,一方面可以求出標準化之后的隨機向量X*,Y*間的典型相關方向、典型相關系數、典型相關變量。另一方面,也可以據此推出標準化之前X,Y的典型相關方向、典型相關系數、典型相關變量。
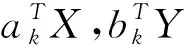
3 實例分析
例3.1某班有20名學生,設X1:平均每周鍛煉的時間,X2:平均每周玩游戲的時間,X3:平均起床是晚于7:30的時間,Y1:體育課成績大于90分,Y2:體育課成績小于75分。目標是研究鍛煉時間、玩游戲時間、起床時間與體育課成績之間的關系。
數據分析如下的矩陣計算將由Matlab具體實現[4-5]。
根據所測數據計算隨機變量X1X2X3Y1Y2之間相關系數矩陣為
R=

從而令
進一步,求得S的奇異值分解為
S:=UΔVT=
因此,典型相關方向構成的矩陣為
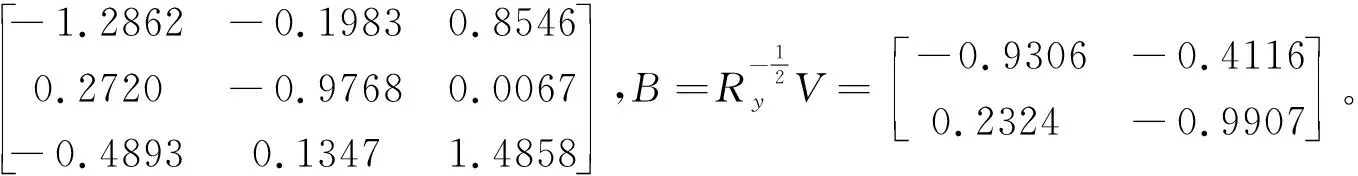
(1)由S的表達式看出:第一對典型變量V1,W1的相關系數為0.8549,說明相關性非常顯著。且第一對典型相關變量V1,W1的表達式為:
V1=-1.2862X1+0.2720X2-0.4893X3,W1=-0.9306Y1+0.2324Y2。
從上述表達式中可以看出:X1和X2的系數絕對值分別最大且符號相同,這表明每周鍛煉時間越長體育成績越優秀。
(2)第二對典型變量V2,W2的相關系數為0.6732, 說明相關性比較顯著。且第二對典型相關變量V2,W2的表達式為:
V2=-0.1983X1-0.9768X2+0.1347X3,W2=-0.4116Y1-0.9907Y2。
由于V2,W2表達式中X2和Y2系數絕對值最大且符號相同,表明玩游戲時間越長體育課成績不及格的可能性越大。
例3.2為了解家庭的情況與學生成績之間的關系,為此調查了20個學生。假設X1:體育測試成績,X2:體育課成績,Y1:在校月支出(百元),Y2:來自城市(1表示來自一線城市、2表示來自二線城市、3表示來自三線城市、4來自農村),Y3: 家庭的年收入(萬元)。
數據分析如下的矩陣計算由Matlab實現[4-5]。根據所測數據計算隨機變量X1,X2,Y1,Y2,Y3之間相關系數矩陣為
由上述矩陣R可計算:

從而,
進一步, 矩陣S的奇異值分解為
S:=UΔVT=
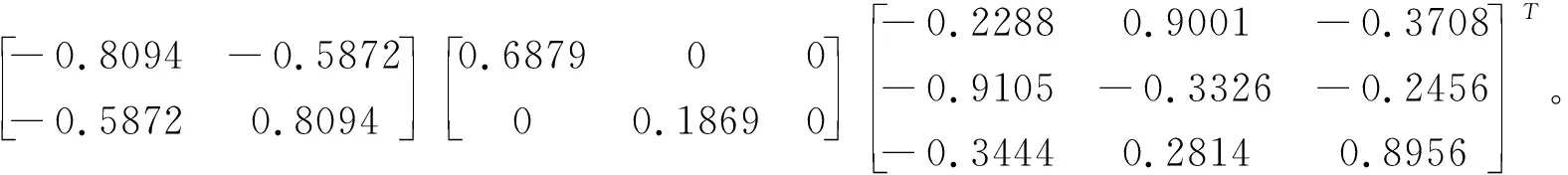
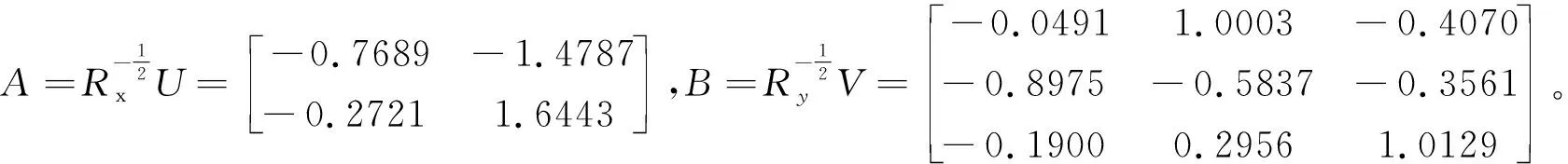
(1)由S的表達式可看出:第一對典型變量V1,W1的相關系數為0.6879, 相關性較顯著.另外,第一對典型相關變量V1,W1的表達式為
V1=0.7689X1+0.2721X2,W1=0.0491Y1+0.8975Y2+0.1900Y3。
從上述表達式可以看出:X1和Y2的系數的絕對值在第一對典型變量V1,W1的系數很大,而且符號是一樣的,說明家庭年收入較高者,體育測試成績相對較好。這可能由于體育測試成績主要側重考察學生的耐力、力量等方面,而不是有關某些技巧。
(2)由于第二對典型相關變量V2,W2的相關系數為0.1869,說明變量間相關性幾乎沒有。
4 結語
矩陣的SVD分解具有全局最優意義上的數據處理能力,主要體現在兩個方面:一是SVD分解可以有效提取信息的主要部分,即能達到降維目的又可以最大限度地保證原始數據的完整性;二是SVD分解無任何參數限制,在計算過程中不需要進行干預,這樣得到的結果僅與數據相關而與用戶獨立。
鑒于上述優點,本文基于矩陣SVD分解,利用PCA分析方法,把理論結果與實際案例相結合,分析有關因素在大學生體育成績中的作用,所得結果對實際教學具有一定的指導作用。
猜你喜歡
計算機應用(2022年2期)2022-03-01 12:33:42
計算機應用(2022年1期)2022-02-26 06:57:42
計算機應用(2021年4期)2021-04-20 14:06:36
計算機應用(2021年3期)2021-03-18 13:44:48
計算機應用(2021年1期)2021-01-21 03:22:38
甘肅教育(2020年2期)2020-11-25 00:50:04
少兒美術(快樂歷史地理)(2018年2期)2018-09-25 02:47:54
河南理工大學學報(社會科學版)(2016年1期)2017-01-15 13:52:23
中國科技信息(2016年20期)2016-12-08 06:39:48
學苑創造·A版(2016年9期)2016-10-10 11:14:12
