IB網上CPU-GPU異構超算平臺容器性能評估及優化
2021-09-26 10:42:52王憲賀
計算機工程與應用 2021年18期
關鍵詞:進程
胡 鶴,趙 毅,王憲賀
中國科學院 計算機網絡信息中心,北京100190
傳統HPC負載具有強環境依賴的特點,所需的軟件堆棧通常很復雜,涉及編譯器、通信中間件及數學庫。容器技術的產生帶來不同依賴環境下應用程序的可移植性。為支持智能業務的機器學習負載,超算平臺均采用CPU+GPU的混合架構[1],有往容器遷移演進的趨勢,確保開發環境的可移植性及訓練的可復制性。美國橡樹嶺國家實驗室的著名超級計算機SUMMIT提供了容器服務[2]。NERSC開發了類似Docker的Linux容器技術OpenShift來提高其HPC系統的靈活性和可用性[3]。天河二號實踐了基于容器的HPC/大數據處理,優化了超算環境的公共服務能力與模式,優化用戶應用體驗[4]。
在并行應用程序中,影響性能的因素主要包括計算、通信以及I/O模式等。因此,相關研究對容器性能和裸機性能進行比對,以此來評估不同超算應用程序移植到容器中的適用性,并評估各種影響計算效率的因素。Felter等人在IBM研究報告[5]中指出,Docker的性能表現優于幾乎所有測試場景中的虛擬化性能,但Docker分層文件存儲方式會產生一定的I/O性能損耗,在網絡密集型工作負載時,其本身的NAT會帶來較大開銷。GPU方面,文獻[6]評估了機器學習應用在GPU上的訓練效率,以證明容器化部署對機器學習的效率開銷不大。通信方面,文獻[7]對比同樣進程數量但容器個數及容器內部進程數不同的情況下,NPB基準測試程序測試結果的變化,證明HPC工作負載會影響容器間的通信性能。I/O方面,文獻[8]對容器的I/O性能競爭進行深入的討論和實驗分析,分析了I/O各項指標隨容器數量的變化趨勢,提出通過動態限制過載容器I/O強度從而提高容器系統I/O性能。
以上研究均為針對影響高性能計算應用各方面I/O、通信等進行性能對比,但并未利用分析結果,提出在HPC上進行容器應用部署及優化的合理化建議,使容器應用性能最大化。本文執行全面的基準測試,分析容器虛擬化解決方案下集群各項性能表現,包括I/O、并行通信及GPU加速性能,并根據不同應用的特點提出系統設置的合理化建議,為管理員及應用研發人員提高應用性能提供參考。
1 測試環境配置
測試是基于中國科技云基礎設施“人工智能計算及數據服務應用平臺”進行的,數據傳輸使用計算存儲網絡為56 Gb/s FDR Infiniband高速網絡,每個節點都配有兩個Intel Xeon E5-2650處理器(每個具有12個內核,頻率為2.40 GHz),256 GB RAM。每個節點配有8塊Tesla P100 GPU卡。使用具有Linux內核3.10.0的64位CentOS 7.6來執行所有測試,并行環境部署了OpenMPI1.6.5版。
采用NVIDIA提供的支持GPU的Docker鏡像作為基礎鏡像,該鏡像能夠發現宿主機驅動文件以及GPU設備,并且將這些掛載到來自Docker守護進程的請求中,以此來支持Docker GPU的使用[9]。按照文獻[10]的操作對容器使用IB進行適配,將Docker默認的網絡地址設置成IB卡的地址,在容器內部安裝配置ssh做進程啟動。為了保持一致性,容器和宿主機具有相同的軟件堆棧并為比較使用容器內部MPI庫及宿主機MPI庫兩者不同的性能表現,在容器內及容器外分別部署MPI庫,配置了相同的MPI版本,如圖1所示。為衡量Docker運行時的性能,以及衡量硬件在容器內虛擬化后相應的系統開銷,本文使用基準測試程序分別針對文件系統I/O性能、并行通信性能與GPU計算性能進行測試。
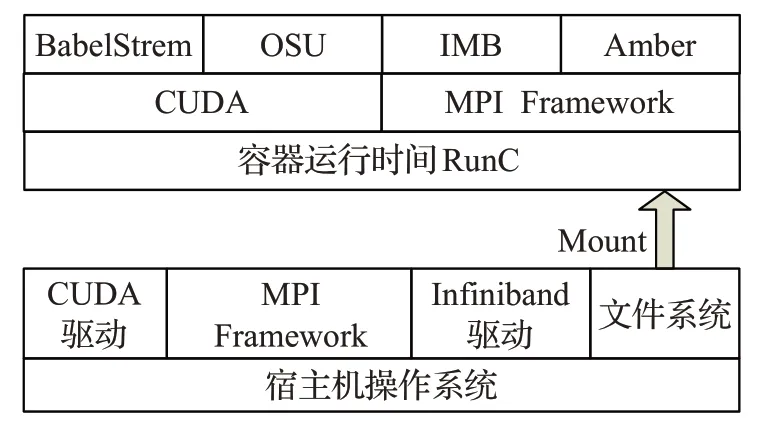
圖1 測試鏡像軟件棧Fig.1 Software stack of host and container
2 測試結果與性能評估
2.1 文件系統讀寫性能
為面向宿主機和容器分析分布式集群文件系統的讀寫性能,選取IOR[11]作為測試工具進行性能分析。IOR(Interleaved or Random)是一種常用的文件系統基準測試應用程序,旨在測量POSIX和MPI-IO級別的并行I/O性能,特別適用于評估并行文件系統的性能。
測試使用2個節點,每節點12核心,每進程生成5 GB數據進行讀寫操作。測試兩種使用場景:
(1)主機上啟動一個容器,容器內啟動多個進程;
(2)主機上啟動多個容器,每容器啟動一個進程。
場景1測試IO讀寫帶寬隨進程數的變化趨勢如圖2。
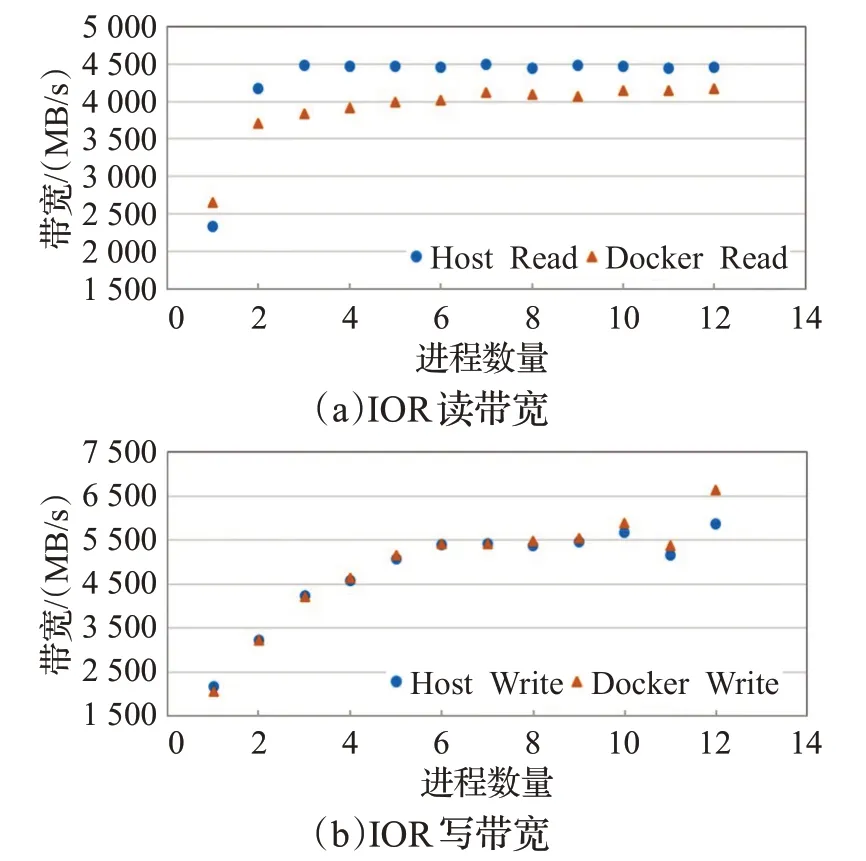
圖2 IOR讀寫帶寬隨進程數變化趨勢Fig.2 IOR read-write bandwidth trend with the number of processes
從圖2可以看出容器的性能基本與宿主機性能保持一致,最大開銷為8%。因此,容器采用bind mount的方式,使用宿主機的存儲,文件系統I/O開銷僅比宿主機多占用容器系統軟件棧,性能差距不大。
使每個容器產生同樣的I/O負載進行場景2測試,隨容器數量的增長,I/O性能的變化如圖3所示。當容器數量為13時,IOR程序異常終止。讀寫帶寬呈類冪函數的下降趨勢。
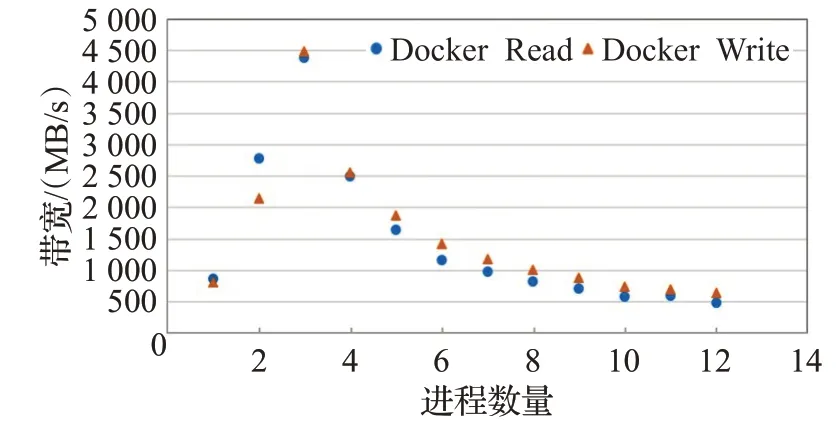
圖3 IOR讀寫帶寬隨容器數變化趨勢Fig.3 IOR read-write bandwidth trend with the number of containers
因此當宿主機上容器個數增多,對I/O密集型應用而言,各容器之間會搶占系統資源,導致整體I/O性能下降。原因是Docker容器技術本身沒有提供良好的容器I/O管理機制,無法保證容器之間的I/O隔離性,降低主機上容器之間的I/O性能影響。因此在實際應用中研發和部署中,應設法降低容器間I/O性能的影響。
2.2 通信性能
該測試的目的是比較容器間通信與物理機間通信,衡量容器MPI并行通信的性能開銷。在進行MPI通信性能對比之前,通過InfiniBand設備廠商Mellanox提供的基準測試工具測試InfiniBand網卡帶寬和網絡延遲[12]。得到兩臺測試宿主機的帶寬約為50 Gb/s,接近理論值。用qperf[13]測試IB網針對基于TCP或UDP的通信性能,得出容器間的帶寬約為11.12 Gb/s,約為IB網絡帶寬的25%。
使用廣泛使用的MPI庫的帶寬及延時基準OSU[14]測試容器的并行通信性能開銷,并比較兩種方案——使用容器MPI庫及宿主機MPI庫兩者的不同。在不同宿主機上各啟動一個容器進行測試,帶寬結果的比較如圖4所示。采用宿主機MPI宿主機和容器通信的峰值帶寬分別為6 694 MB/s以及5 887 MB/s,Docker容器與宿主機相比在并行通信方面有約為10%的開銷;而使用容器內部的MPI,帶寬僅為使用宿主機帶寬的約25%。
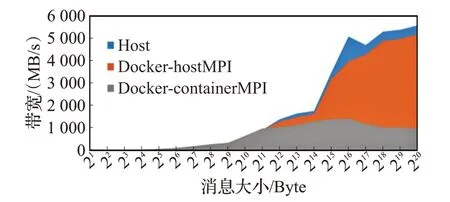
圖4 MPI點對點通信帶寬Fig.4 MPI Point-to-Point communication performance
延遲結果的比較如表1所示,使用宿主機MPI,容器延遲比宿主機延遲高6%,而使用容器內部MPI相比使用主機MPI延遲多了2.8倍。

表1 MPI點對點通信延遲Table 1 MPI point-to-point communication latency
使用容器MPI比使用主機MPI開銷大的原因,是由于容器中不能識別IB卡,通信只能通過IB卡生成的虛擬網橋進行,產生了系統CPU和內存開銷而造成的。
為評估其他MPI常見函數的延遲情況,使用基準測試程序IMB[15],利用宿主機的MPI庫,選擇四種常見的集合通信方式bcast、allgather、allreduce及alltoall進行宿主機和容器的集合通信性能測試。對比兩種情況的測試結果:(1)每臺宿主機啟動20進程;(2)每臺宿主機啟動一個容器,容器內啟動20進程。
測試結果如圖5所示,顯示常見的四種MPI庫函數容器與主機的延遲差值隨數據包大小的變化趨勢。在實驗中發現,容器并行通信性能與宿主機接近,但隨著消息包增大通信延遲差距增大。
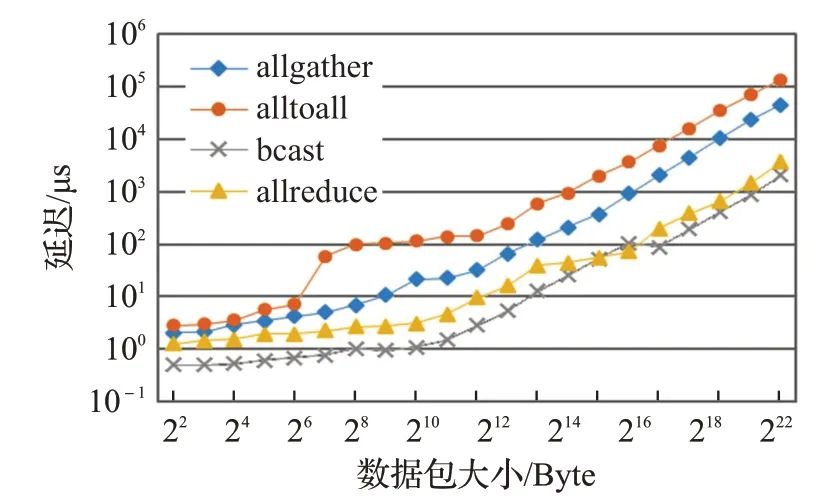
圖5 IMB集合通信性能(40進程)Fig.5 Collective communication performance with 40 processes
2.3 GPU計算性能
本文采用了安裝好GPU驅動的開源版本Docker鏡像nvidia-docker,可以在容器中能夠直接訪問GPU資源。之后如需支持不同版本的開發框架,只需在容器中安裝cuda toolkit即可。這種方式可以使同一個GPU硬件驅動支持不同CUDA版本,解決用戶CUDA版本多樣化需求。使用ResNet-50[16]模型通過深度學習框架TensorFlow[17]進行了性能評估。在所有測試中均使用ILSVRC2012[18]數據集。測試結果如圖6所示。
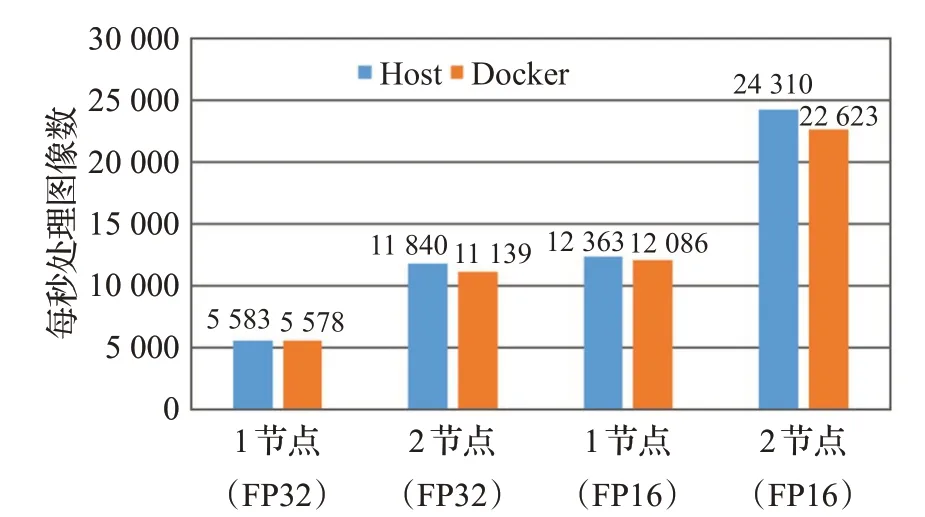
圖6 ImageNet圖像處理吞吐量Fig.6 ImageNet image processing throughput
使用AI訓練和推理模型對宿主機和容器進行測試的結果表明,在采用多個容器的情況下,容器能夠以近線性方式向上擴展。容器與宿主機性能接近,最大開銷約為7%。通過查看GPU利用率,所有容器的GPU達到了飽和狀態,使用容器進行訓練可充分利用GPU的性能。
3 容器應用優化建議
測試結果表明,Docker可以很好地支持GPU、Infiniband等硬件,能夠在超算領域帶來更好的可移植性。在I/O、通信、GPU計算能力方面,Docker帶來的開銷可以忽略。通過以上實驗結果分析,提出應用程序在進行容器配置采用如下建議。
3.1 容器IO優化
I/O方面通過bind mount的形式與宿主機共享文件系統,將存儲盤掛載到容器,減少文件分層存儲方式帶來的I/O性能損耗。
對于I/O密集型應用,減少宿主機上啟動容器的個數,避免同一時間多容器同時進行I/O操作。減少宿主機上容器的I/O爭用。而容器內部,通過MPI或OpenMP等實現對并發、同步、數據讀寫的支持,完成I/O的編排。
3.2 容器通信優化
建議使用宿主機的MPI庫,發揮平臺IB網RDMA傳輸特性帶來的優勢。因容器內部對Infiniband的支持問題,使用宿主機MPI約為使用容器MPI性能的四倍。實現時將宿主機文件系統中的MPI庫文件映射到容器中,在并行通信時選擇宿主機的MPI庫。
使用宿主機MPI,容器并行通信性能與宿主機接近,但隨著消息包增大通信延遲差距增大。故對于通信負載較高的通信密集型應用程序,使用容器會給通信性能帶來一定開銷。
3.3 充分利用容器可移植性
用英偉達的鏡像作為基礎進行配置,也可以選擇在自身鏡像中安裝nvidia-docker-plugin的方式支持GPU。容器中可以識別GPU卡,因此可以在容器內部安裝與宿主機不同的CUDA版本,實現對不同應用軟件的兼容。系統管理員可以準備裝有不同應用版本的容器鏡像,放入容器倉庫中方便用戶下載,使用戶集中精力于模型和算法,而不是應用環境配置。
3.4 進行容器安全設置
在Docker設計之初安全性是無關緊要的,用戶可以使用root用戶掛載主機文件目錄,還可以用root權限訪問主機上的其他容器,而造成系統破壞或數據泄露。在容器使用時,系統管理員需設置好訪問控制策略,盡量使用戶獨占節點,避免用戶的容器被其他用戶以root權限訪問。另外,保護好宿主機的MPI目錄,掛載單獨的分區,并設置為只讀。
4 結束語
容器可以解決HPC領域開發環境的一系列問題,帶來應用程序跨平臺的可移植性。本文評估超算環境下Docker容器的性能表現,從計算、I/O、通信三方面,通過基準軟件衡量容器本身開銷。在測試中觀察到的容器總體性能開銷是可以容忍的。具體使用時,應盡量使用宿主機的文件系統及MPI庫,盡量減少并發容器的個數,發揮計算網絡性能并減少文件系統開銷。另外提出了增加容器隔離性、安全性,及可管理性的相關設置。本文尚未針對大規模應用使用容器進行相關實驗和結果分析,需要在今后的工作中進一步深入。
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
