基于深度Q-學習和粒子群優化的僵尸檢測算法*
2021-10-08 13:55:06任勇軍
計算機與數字工程 2021年9期
顧 偉 任勇軍
(南京信息工程大學計算機與軟件學院 南京 210044)
1 引言
活躍于社交網絡平臺的社交機器人(Social Bot,SB)實質是一個自動計算機程序[1]。這些SBs可分為僵尸SB、干擾SB和誠意SB。這些惡意SBs也稱為僵尸攻擊,它們分布于垃圾郵件、釣魚網。干擾SBs用于操控在線評論和評分,進而干擾用戶的行為[2]。而誠意SBs正常地發布產品消息、新聞資信。
現有多種檢測在線社交網絡上的僵尸[3~4]算法。然而,僵尸會動態地改變其行為,進而避免檢測。目前主要有基于機器學習、基于眾包(Crowdsourcing)和基于社會圖譜的僵尸檢測算法。
基于機器學習的檢測算法通過考慮多項特征數據,從SBs中分離合法的SB。文獻[5]提出基于隨機森林分類器的BotorNot檢測算法。文獻[6]采用了基于深度Q-學習的僵尸檢測算法。
基于眾包的檢測算法是利用專家庫構建評判標準,進而對SB進行分類。例如,文獻[7]針對2000個賬戶數據,并基于10個專家評判,建立分類標準。
基于社會圖譜的檢測算法是采用社會網絡圖譜對SB進行分類。目前,有基于用戶間的社會信任關系和基于中心測量和圖拓撲兩種類型。文獻[8]采用基于Sybil隨機-漫步的方法檢測Sybil用戶,其中不信任用戶的分數最低,而合法用戶的分數最高。文獻[9]采用了基于中心測量的算法,并提出了基于神經網絡、隨機森林和決策樹分類器。
在傳統的Q-學習算法中,所有學習動作均需計算其Q值。因此,Q-學習算法的收斂速度很慢,增加了存儲所有動作的Q-值的空間。
為此,提出基于深度Q-學習和粒子群優化的僵尸檢測(Deep Q-Learning and Particle Swarm Optimization-based Bot Detection,DQL-PSO)算法。利用粒子群算法優化Q-學習,進而獲取最優的學習動作序列。仿真結果表明,提出的DQL-PSO算法提高了檢測算法的收斂速度,并提高了檢測僵尸的準確性。
2 網絡模型
引用如圖1所示的網絡架構。每個粒子代表一個狀態,并且每個粒子有n個序列的學習動作,且每個序列對應一個Q值。在隨機環境中,先計算每個粒子的適度值。再依據適度值,更新學習動作的局部和全局最優序列。因此,通過載入新的粒子,更新迭代,進而優化性能。
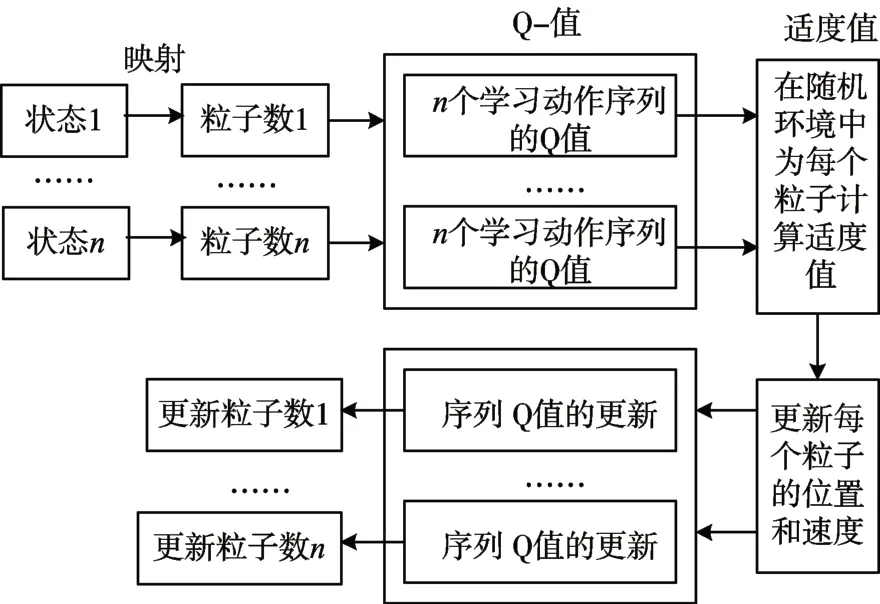
圖1 網絡框架
3 DQL-PSO算法
3.1 基于PSO的Q函數的更新
DQL-PSO算法利用粒子群優化(Particle Swarm Optimization,PSO)對Q函數進行更新。將僵尸的檢測問題轉化為優化問題,提高檢測性能。
令S={s1,s2,…}和LA={α1,α2,…}分別表示狀態集和學習動作集。每個用戶行為關聯了狀態和學習動作,再依據用戶行為,對用戶進行獎勵。
引用文獻[12]的定義,令st和令αt分別表示當前的狀態和動作。令表示下一個狀態。在時間t獲取了獎勵rt。據此,定義狀態轉換函數:
通過優化學習動作序列,進而最大化累加獎勵R。用fst(A)表示優化后的動作序列的適度函數:fst(A)=R(st,A)。而。
當在時刻t執行動作αt,位于狀態st的學習代理就得到獎勵rt。DQL-PSO算法的根本目的就是最大化累加獎勵,決策最優的動作集序列。因此,對適度函數fst(A)進行更新:
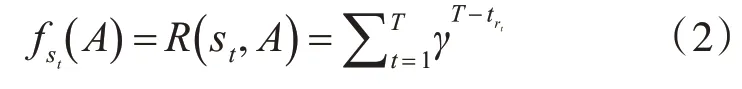
式中:T表示在每個學習時期內總的學習動作數。rt表示第t個動作的當前獎勵。而γ表示折扣因子,且γ∈(0,1)。
針對SB檢測問題,用動作集序列A={αt,αt+1,…}表示粒子位置;用狀態轉換率表示粒子速度。并且通過比較適度函數決定每個學習代理的局部最優解和所有學習代理的全局最優解。
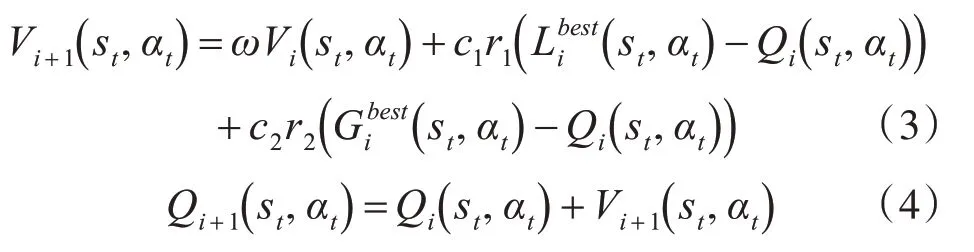
式中:ω、c1和c2分別代表權重系統。而r1、r2為隨機數,且在0~1之間。Qi(st,αt)表示第i個粒子在狀態st所選擇的動作αt所形成的Q-值。而表示由第i個粒子決策的局部最優Q值。Gbest(st,αt)表示由所有粒子決策的全局最優Q值。
3.2 檢測步驟
DQL-PSO算法的檢測步驟如算法1所示。每個用戶的執行步驟:
1)依據式(2)計算累加獎勵R;
2)依據最優的學習動作集A,計算局部和全局最優Q值;
3)再依據式(3)和式(4)更新速度和Q值。
重復上述過程,直到達到迭代次數。
Algorithm 1
Parameters:
R:Cumulative reward for Q-valueQ(s,α)

具體而言,首先對Qi(s,α)以及Vi(st,αt)進行初始化。并以狀態s1進行學習。然后,代理在時刻t執行動作αt獲取當前獎勵rt以及下一個相應的狀態,并緩存經歷值。
再依據式(2)計算獎勵值Ri,再更新粒子的局部最優位置。若Ri小于或者=-1,就將當前位置作為局部最優位置,并將當前Q值作為局部最優Q值,如式(5)所示:
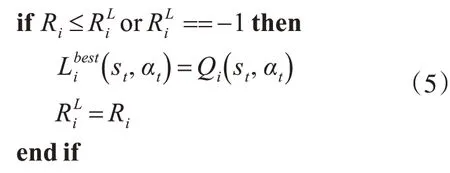
將所有粒子中具有最高Q值的位置作為全局最優解,如式(6)所示:
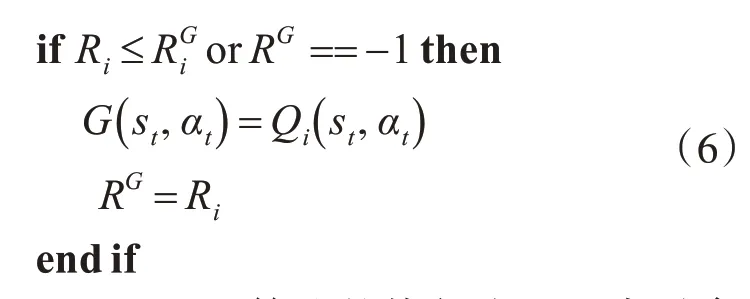
圖2給了DQL-PSO算法的執行流程。先對參數進行初始,再評估每個粒子的適度值。然后,再選擇局部最優和全局最優值。隨后,依據局部和全局最優值更新每個粒子的位置和速度。并進行迭代,若達到迭代次數,就停止迭代。
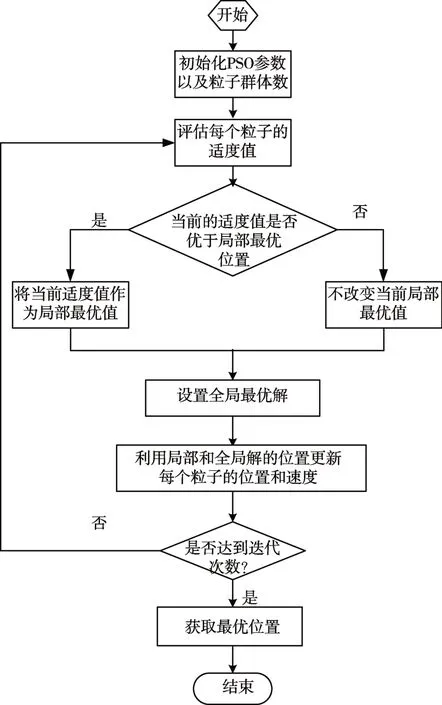
圖2 DQL-PSO算法的執行流程
4 性能仿真
為了更好地分析DQL-PSO算法的性能,選擇文獻[10]的用戶群數據庫(User Popularity Dataset,UPD)作為實驗數據。其中用戶數為453853,合法用戶數為476,僵尸個數為320。最大的迭代次數為30。其余的仿真參數如表1所示。
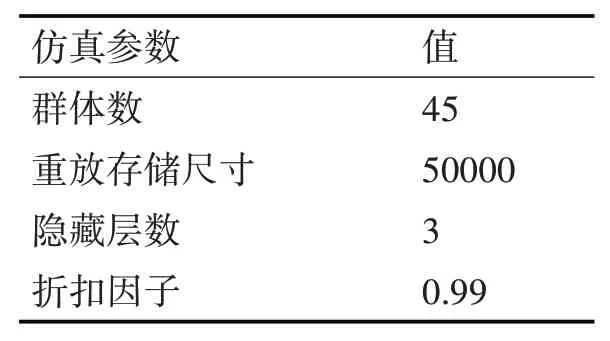
表1 仿真參數
選擇文獻[11]提出的同步策略的PSO算法(Heterogeneous Strategy PSO,HS-PSO)和文獻[6]提出的自適應深度Q-學習的(Adaptive Deep Q-learning,ADQL)算法作為參照。主要比較它們的達到最優狀態的動作序列數(以下簡稱為最優-動作序列數)、準確率Pprecision和重放率PRecall。
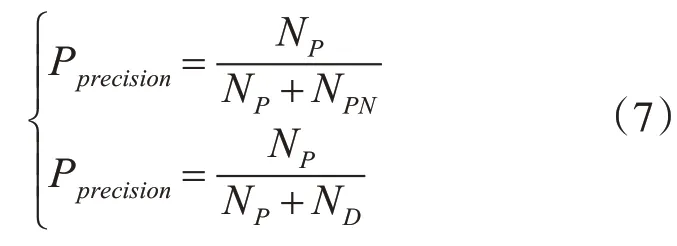
式中:NP表示正確地將僵尸評判為僵尸的數量。而ND表示錯誤地將SB評判為合法的SB的數量。而NPN表示將合法用戶評判為僵尸的數量。
4.1 最優-動作序列數
首先,分析在不同迭代次數下的DQL-PSO算法的最優-動作序列數,如圖3所示。圖3記錄了30次的迭代次數。
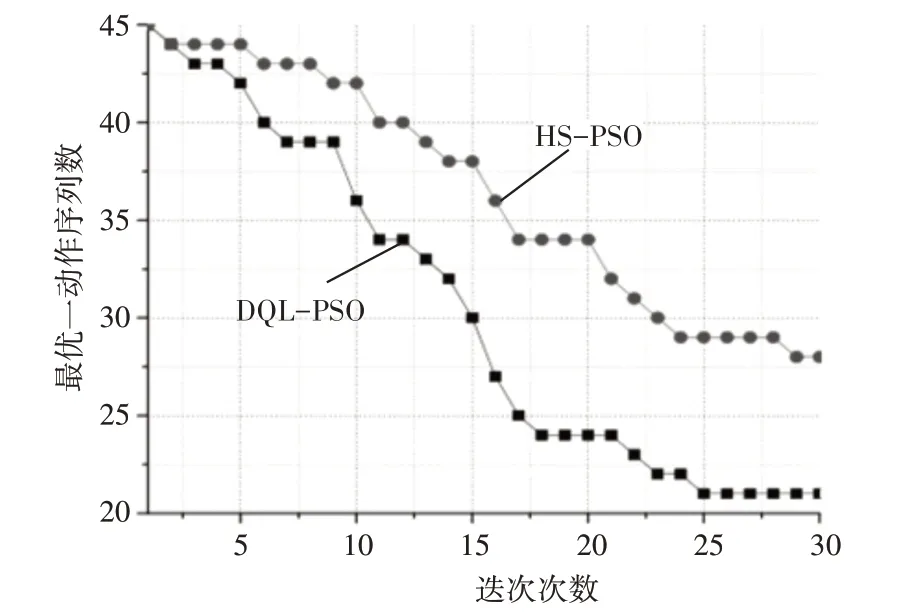
圖3 最優-動作序列數
從圖3可知,相比于HS-PSO算法,提出的DQL-PSO算法在同等的迭代次數環境下,所需的學習動作數少,降低了最優-動作序列數。例如,迭代次數為25次時,HS-PSO算法的最優-動作序列數達到約28.5,而DQL-PSO算法的最優-動作序列數低至22。
4.2 準確率
圖4顯示了在不同學習時期下ADQL和DQL-PSO算法的準確率。圖4反映了兩項信息:1)收斂性;2)準確值。從收斂角度,DQL-PSO算法的性能優于ADQL算法。DQL-PSO算法未到300個學習時期收斂,并收斂于95%。而ADQL算法約在350個學習時期收斂。從準確值角度,DQL-PSO算法的準確值也優于ADQL算法。DQL-PSO算法的準確值收斂于95%,而ADQL算法的準確值收斂于約92%。
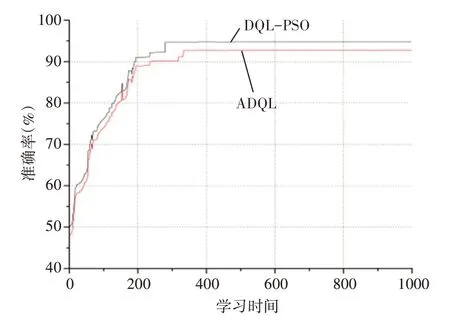
圖4 準確率
4.3 重回率
最后,分析DQL-PSO算法和ADQL算法的重回率,如圖5所示。相比于ADQL算法,提出的DQL-PSO算法的重回率得到提升。例如,ADQL算法的合法用戶的重回率約93%,而DQL-PSO算法的重回率約95%。
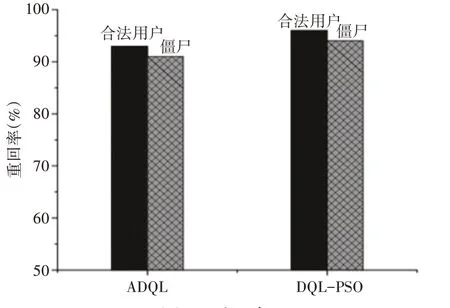
圖5 重回率
5 結語
在深度Q-學習算法中,學習代理依據更新Q-值自動學習。此外,通過有效選擇更新策略可以快速地收斂。本文采用DQL-PSO算法檢測僵尸。利用粒子群優化算法更新Q函數。并利用局部最優Q值和全局最優Q值更新Q值。
利用UPD數據庫進行分析,并與HS-PSO和ADQL算法進行比較,仿真結果表明,提出的DQL-PSO算法能達到95%的檢測準確率和93%的重回率。相比于HS-PSO算法,DQL-PSO算法提升了收斂速度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
