基于文章和近答案句信息的問題生成模型
2021-10-12 04:53:02劉瑞芳劉欣瑜陳泓宇
中文信息學報 2021年8期
石 航,劉瑞芳,劉欣瑜,陳泓宇
(北京郵電大學 人工智能學院,北京 100876)
0 引言
問題生成(Question Generation, QG)是指對給定的一段文本,生成一個合理的問題。問題生成的一個潛在應用在教育領域[1]。也可以在問答系統和聊天機器人,例如,Siri、Alexa、Cortana、小愛、小度等中幫助它們啟動對話和繼續對話[2]。在問答系統(Question Answering, QA)領域,Zhu等[3]利用問題生成系統自動生成大量的問題答案對來提升機器閱讀理解系統的F1值。Sultan等[4]闡述問題生成的多樣性對QA的重要性。
目前,學者們對問題生成任務已經展開了大量的研究,主要分為基于規則的問題生成、基于深度神經網絡的問題生成以及基于預訓練語義模型的問題生成。
基于規則的問題生成,例如,Heilman等[5]和Mannem等[6]使用嚴格的啟發式規則或基于模板的方法。但是,這些方法嚴重依賴于人工生成規則,不易被其他領域采用,有時生成的句子也不如人類表達那樣流暢。近年來,一種基于序列到序列框架的端到端的神經網絡在問題生成任務中被普遍采用。其中編碼器將帶有語義特征(例如,命名實體識別(Named Entity Recognition, NER)標簽)的文章或句子進行編碼,解碼器利用編碼器生成的語義表示生成問題。Du等[7]使用一個或兩個包含答案的句子作為問題生成模型的輸入,而Zhao等[8]使用整篇文章作為編碼器的輸入。譚紅葉等[9]使用答案及其上下文信息進行問題生成。不管輸入是一兩個句子還是整篇文章,都只能捕獲到一個層次和答案相關的信息,從而導致生成非理想的問題。Jia等[10]將釋義知識整合到問題生成中生成問題。Kriangchaivech等[11]基于Transform的結構在問題生成任務上取得了很大的進展。Dong等[12]提出了一種新的預訓練模型UNILM,通過訓練序列到序列的語言模型(Language Model, LM)實現問題生成。但是這種方法需要大量的數據,而且模型參數太多,需要大量的算力進行訓練。
本文主要解決針對給定文本中的指定內容提問的問題生成任務,即生成的問題是可以根據原文用目標答案來回答的問題。為了從句子級別和全文信息中捕獲與答案相關的語義信息,我們提出一種新的多輸入序列到序列框架,框架的編碼器同時輸入全文信息和答案上下文信息。因為文章常常能提供比句子更豐富的內容,Zhao等[8]發現在SQuAD數據集[13]中有20%的問題需要依賴文章級別的長文本信息,使用全文信息可以提升問題生成的BLEU_4值。Liu等[14]比較訓練集每個訓練樣本中復制的單詞與答案之間的句法依賴距離和順序單詞距離的分布,發現答案詞與被復制詞之間的平均距離分布為10.23。整篇文章能夠幫助提高生成問題的質量,但是一般與答案相關的信息主要來自它的上下文,我們把包含答案及其前后十個詞的上下文信息稱為近答案句子。本文結合這兩個層次的信息來提升生成問題的質量。
在問答系統中,給定一篇文章和一個問題,我們可以在文中找到一個獨一無二的答案。但是對于問題生成任務,在一篇文中指定一部分內容作為答案,我們可以有多種方式來對其進行提問,即問題生成是一對多的任務。因此如何評估一個問題是不是好問題,我們不僅需要將生成的問題和人工生成的源問題進行對比,也需要判斷這個問題是否是針對文中答案內容進行提問的。本文通過問題的可回答率來評估問題和答案的相關程度。本文采用BERT-base-uncased[15]預訓練模型訓練一個問答系統,將測試集中的源問題替換成系統生成的問題,然后根據問答系統的回答情況評判問題的可回答率。以下是本文的主要貢獻:
(1) 本文提出了近答案句子的概念。基線系統通常是輸入包含答案的整個句子,而數據中與要提問的答案相關的信息不一定和它在同一個句子,而是與其位置相近的詞,這些詞也可能和答案是跨句子的。所以近答案句子可以提供更多與答案相關的信息,同時減少了噪聲。
(2) 本文提出了一種新的端到端的模型框架。傳統端到端框架的編碼端輸入是一個序列,輸出到解碼端解碼生成句子。本文輸入兩個序列,通過多層次的注意力機制編碼后獲得更豐富的語義表示,然后輸出到解碼端解碼生成問題。
(3) 問題生成是一對多的任務,傳統的評估方法只能將生成的問題和參考問題進行對比評判,對于問題類型出錯的懲罰不大,也不能包容更多的可能性。本文把一個問答系統作為判別器,根據問答系統的回答情況評估生成問題的可回答率,以此來評價問題的質量。
1 相關工作
目前,問題生成技術的研究方法一般分為三種,第一種是基于規則的方法,即將陳述句轉化進行問題生成;第二種是基于端到端的編碼—解碼結構的神經網絡問題生成方法;第三種是借助預訓練模型的強語義表示進行問題生成任務。
為了在創建問答系統和對話系統的大規模數據集中減少人工標注的工作量,自動生成問題是非常重要的。大多數早期的自動問題生成都是基于規則的,例如,將人名替換成“誰”,根據語法調整語句可以產生大量問題。Heilman等[4]依據制定的規則將簡化后的陳述句轉化成問題,然后通過邏輯斯蒂回歸對生成的問題進行重排序。然而這些方法非常依賴人為設置的規則,所以不能很好地拓展到其他領域,遷移性較差,有時生成的句子不能像人類的語言那樣流暢。
受益于SQuAD數據集的三元組(文章、問題、答案)和端到端的神經網絡模型,摒棄了大量規則制定的工作,并生成了更高質量、更流暢的問題句子。Du等[7]第一次嘗試了基于注意力機制的序列到序列模型,利用神經網絡的方法使得問題的得分在自動評估和人工評價中都超過了基于規則的方法。Zhou等[16]在模型中充分利用答案位置特征和詞匯實體特征,并引入復制機制解決生成詞表外的詞,進一步提升了神經網絡在問題生成任務中的BLEU_4和ROUGE_L值。Zhao等[8]提出門控注意力機制,增強編碼端的語義表示能力,結合最大輸出指針復制機制,改進了神經網絡對長文本作為輸入表現不佳的現象。Kim等[17]提出分離答案的序列到序列模型,幫助模型捕獲答案相關的信息。
隨著BERT[15]預訓練模型在自然語言處理中的廣泛應用,最近Dong等[12]提出了統一語言模型UNILM。借助大量的訓練數據和復雜的網絡結構,設計了一種序列到序列的語言模型訓練方法,讓模型在端到端的任務上獲得了很大的進步,大大提升了問題生成的質量。但對實驗條件要求比較高,很難遷移到一般機器中運行。
神經網絡模型有著比基于規則方法更好的效果和遷移性,比預訓練模型更具有可實現性和可拓展性。因此,本文采用編碼—解碼的框架研究問題生成任務。并在預訓練模型UNILM上做了對比實驗,證明本文提出的近答案句子信息對提高問題生成的質量是有效的。
2 問題生成模型和方法
2.1 模型架構
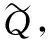
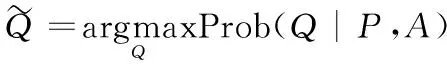
(1)
本文模型的整體架構如圖1所示,模型左邊是編碼端,主要包括三層,右邊是解碼端。
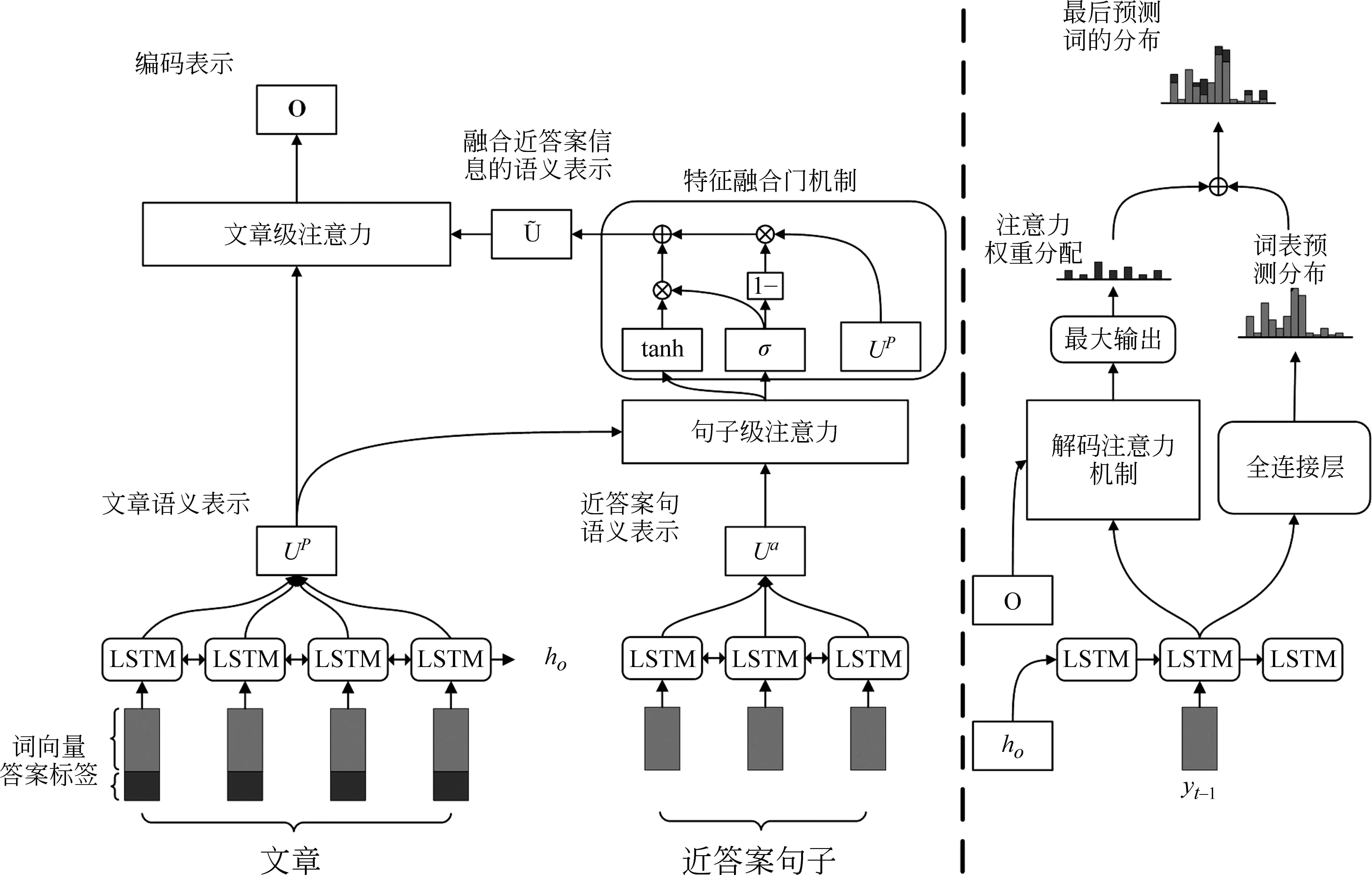
圖1 模型總體框架
2.2 多序列輸入編碼層
其中,ut表示Bi-LSTM第t步的隱藏層,et表示預訓練的詞向量編碼,mt代表答案的位置信息編碼。通過編碼層后得到文章的語義表示UP和近答案句子的語義表示Ua。
2.3 句子級別的注意力機制層
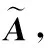
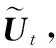
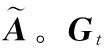
2.4 文章級別的注意力機制層
這一層在得到了融合近答案語義信息的文章表示后。受益于Wang[18]提出的自對準注意力在長文本中的優勢,本文采用了自注意力融合機制對文章表示做進一步的信息融合,最終得到兩層語義信息的編碼表示O,如式(9)~式(11)所示。
2.5 解碼層
在解碼階段,首先將編碼器的最后一個隱藏狀態作為解碼器的初始化隱藏狀態。第t步解碼根據t-1步的解碼單詞和隱藏狀態作為輸入,通過LSTM獲得解碼器隱藏狀態st。將st做線性變化后利用softmax預測詞表里每個單詞的概率Pvocab如式(12)~式(14)所示。
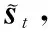
考慮到輸入的是整篇文章,某些詞在文章中出現的次數比較多,最后的注意力權值相加后會導致一些不重要的詞分得的權重比較高,從而影響生成問題的質量。本文采用了最大輸出的注意力復制機制,即在對注意力權值的計算中對同一個詞只選最大權值作為最后的權重分配,如式(18)所示。
(18)
將式(14)中的sgt換成sct獲得復制分數Pcopy(w),最后得分由生成得分和復制得分相加得到P(w),如式(19)所示。
P(w)=Pvocab(w)+Pcopy(w)
(19)
3 實驗結果與分析
3.1 數據集
本文提出的多層次注意力端到端的神經網絡模型在SQuAD數據集上進行了實驗,該數據集利用眾包的方式生成,其中每個問題的答案來自對應文章的一段文本,共有超過100k個問題和536篇維基百科的文章。實驗依據整篇文章和包含答案前后10個詞的句子來進行問題生成,輸入包括整篇文章和近答案句子以及答案的位置信息。輸出是人工提出的問題。我們數據集的分割方式參照Zhao[8]來劃分訓練集、驗證集和測試集。
3.2 實驗設置
我們從訓練集中收集詞表并保存前45 000頻次的詞,其他的用特殊字符@UNK代替。我們使用的GloVe[19]預訓練詞向量來將每個單詞初始化為300維的向量。在編碼和解碼中,我們都使用了兩層雙向LSTM,隱藏單元的大小為600,兩層中間設置丟棄率為0.3。對答案的位置信息編碼維度是3。對于模型的優化算法,我們采用隨機梯度下降(Stochastic Gradient Descent, SGD)進行更新參數,初始學習率是為0.1,從第八輪訓練開始每兩輪學習率減半,批量(Batch Size)的大小為32。在解碼過程中,Beam search設置為10。我們使用谷歌的BERT-base-uncased[15]訓練QA模型。
3.3 基線系統
本文采用了4個基線系統進行比較:
(1)Seq2Seq+Attention[7]: 該模型使用基于全局注意力機制的RNN編碼器—解碼器框架來生成問題。
(2)NQG++[16]: 該模型第一次引入了注意力機制和復制機制在序列到序列框架中,并在編碼端增加了豐富的特征信息。
(3)s2s-a-at-mcp-gsa[8]: 該模型在編碼端引入門注意力機制,在解碼端采用了最大輸出指針網絡,并且能處理長文本作為輸入的問題生成。
(4)ASs2s[17]: 該模型提出答案分開的序列到序列模型,并指出原文中哪些潛在詞在生成問題時可以用來替代目標答案。
3.4 評價指標
實驗結果采用的評價標準有BLEU值[20]、METEOR值[21]、ROUGE_L[22]。BLEU是自動翻譯常用的評估方法,通過統計生成的句子和標準句子之間匹配片段個數來評價生成句子的充分性和流暢性,METEOR則是依據評價指標中的召回率的意義提出的評估方法,計算對應生成句子和標準句子之間的準確率和召回率的調和平均,ROUGE_L通過使用基于最長公共子序列的統計量來衡量生成句子和標準句子中出現的數量。此外,我們訓練了一個QA模型,通過QA模型評估生成問題的可回答率來評估問題的質量。
3.5 實驗結果和分析
通過實驗對比,我們的模型對比基線系統的問題生成各項指標都有明顯的提升。如表1所示,表中w/o表示在基線的情況下減少一層結構,par.代表文章級別的注意力機制,tag.代表答案的位置編碼信息。從實驗結果來看,Seq2Seq + Attention模型在問題生成任務中有一個不錯的表現。NQG++模型在編碼端增加一些答案的特征信息,增加復制機制去處理小概率出現的詞采用預訓練的詞向量后,生成問題的BLEU_4值提升了1.01%。而s2s-a-at-mcp-gsa 模型提出的門控注意力機制能夠很好地對長文本的輸入進行一個語義編碼表示,解決了長文本作為輸入在問題生成任務中的挑戰,不管是以長文本作為輸入還是句子作為輸入,都取得了歷史最好的效果。ASs2s模型相比于NQG++,可以看出分離出答案的有用信息對問題生成的各項指標也有明顯的提升。
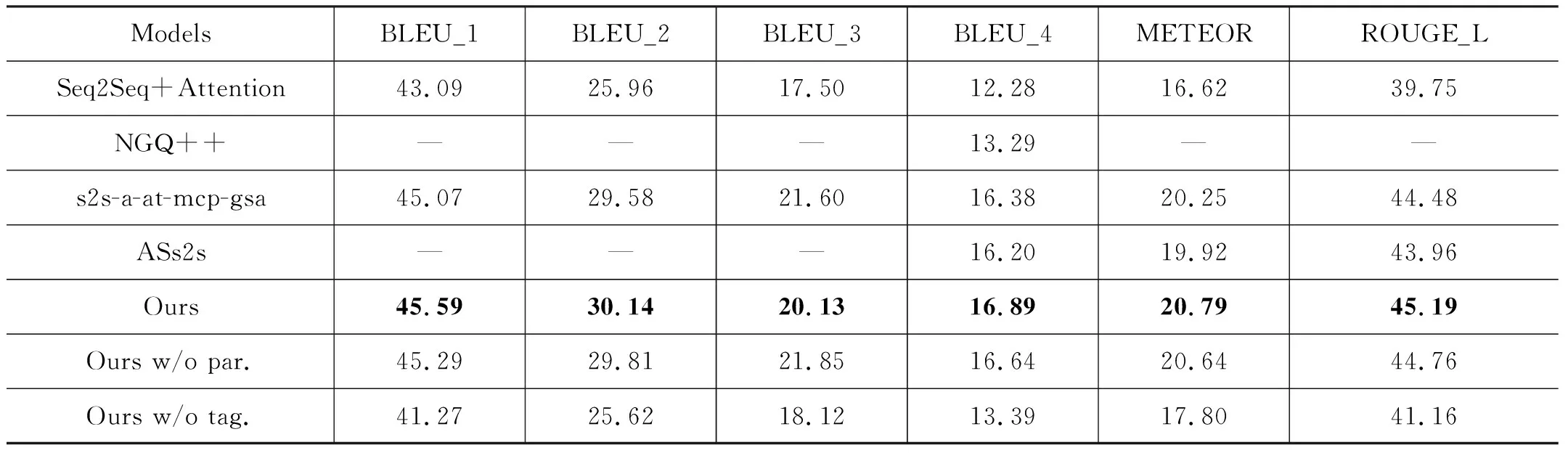
表1 問題生成結果 (單位: %)
本文和s2s-a-at-mcp-gsa一樣,都以長文本作為輸入生成問題。但是因為我們多層次地結合了全文信息和近答案句子信息,最后問題生成的各項指標達到了最好的效果。為了進一步印證多層次的語義編碼,本文在編碼端器端減少了一層文章自注意力機制,結果的指標有小幅下降,但是仍然比s2s-a-at-mcp-gsa 要好,說明全文的層次信息有助于答案的理解和問題生成,全文的自注意力機制可以捕獲到全文中對答案有用的信息,而減少了答案的位置信息時性能下降明顯,因為系統不知道要提問的對象具體是什么,但是由于結合了近答案句子信息,也能取得比Seq2Seq + Attention更好的效果。通過兩個消融實驗證明多層次的語義信息可以輔助提升問題生成任務的性能。
問題生成的任務是: 根據給定的文章,將文章中的一部分作為答案來進行提問。這是一對多的問題,因為針對同一部分內容提問,我們可以從不同的角度來提出風格不同的問題。而傳統的評估方法都是將系統生成的問題和數據集中人為生成的參考問題來進行比較,進而評估問題生成的質量。這種方法對一個系統生成的可以用給定的答案來回答,但對于與參考問題不一樣的問題是不公平的。因此,本文評估生成問題可回答率時,先訓練一個問答系統,用訓練好的問答系統來判斷生成問題的可回答率。
BERT-base-uncased在不同的訓練集和測試集上的表現如表2所示。用原始數據集時BERT-base-uncased的F1得分是88.61,EM得分是81.33。本文將我們的系統和Zhao[8]的系統進行了對比,首先將驗證集中的所有問題用兩個系統生成的問題替換,然后讓訓練好的QA系統來回答替換后的問題。最后我們系統的F1得分是73.38,可回答率是82.81%(73.38/88.61),結果都比Zhao[8]的系統高,表明我們系統生成的問題不僅在流暢度和精確率上比基線系統更好,而且生成的問題和指定的答案之間的匹配度也是更高的,生成的問題和答案相關度更高。

表2 BERT-base-uncased的結果
換而言之,我們系統生成的問題可以作為大規模生成數據集提供給QA模型訓練。為了驗證這一點,本文還將訓練集的問題換成系統生成的問題。結果BERT-base-uncased在SQuAD測試集中的F1得分是79.24,這已經超過了經典QA神經網絡模型BiDAF[23]的F1得分77.32。
本文從實驗結果中分析了本文系統和基線系統的差別,并且也參照了人工提問的源問題。具體例子如表3所示,其中,下劃線部分是要提問的答案,括號部分是近答案句子信息。通過對比發現,我們多層次注意力機制的問題生成模型整體結果相比于基線系統要更接近人類生成的問題。例1中,由于和答案相關的信息在近答案句中,本文生成的問題很接近參考問題。而基線系統由于長文本的輸入帶來的噪聲導致生成的問題把注意力分散到更遠的信息,復制生成了更多和答案不相關的詞。例2中,我們系統能夠根據近答案的語義信息捕獲到時態上的細節信息,而基線系統不能捕獲這些細節信息。例3中,我們生成的問題中有1 758的信息,這一信息近答案句中沒有,是由長文本提供的,我們的系統和基線系統也都能捕獲到全文中距離答案相對較遠的信息以輔助提升生成問題的質量。但是我們要提問的詞是一個數量,基線系統生成的問題則是一個“什么”類型的問題,這個問題明顯不是一個好的問題,但是這種情況在之前的BLEU或者ROUGE_L的評估方法上是不能體現出來的,因此評估一個問題的可回答率也是評估問題質量一個重要指標。

表3 分別由本文模型和基線模型生成問題樣本
最后,為了驗證本文提出的近答案句的可靠性,我們在統一語言模型UNILM上進行了對比實驗。我們利用Dong等[12]提供的unilm-v1中問題生成任務的unilmv1-base-cased參數進行微調實驗。我們在輸入中近答案句子的前后增加兩個分隔符,如圖2所示,實驗結果如表4所示。

圖2 近答案句輸入圖
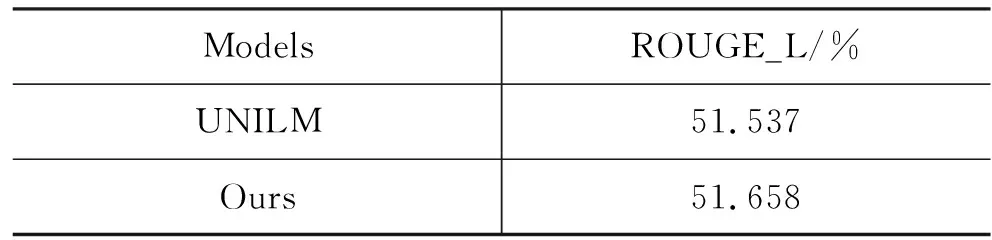
表4 UNILM的結果
實驗結果顯示,增加了近答案句子信息特征后,問題生成的ROUGE_L值相比UNILM提升了0.121%,說明我們提出的近答案句子對問題生成任務的性能提升有效果。我們進一步對比了本文基于神經網絡模型和UNILM的問題生成時間。實驗結果如表5所示。

表5 生成問題時間結果
我們對比生成5 285個問題,Batch Size為1,不同Beam search大小的結果。實驗結果顯示,Beam search為1時,本文模型的生成問題的時間是UNILM的9.03%。當Beam search為10時,本文模型的生成問題的時間是UNILM的25.46%。可見,本文模型要比UNILM輕量很多,能夠更好地遷移到更小設備或者百毫秒級響應的需求中。
4 總結與展望
本文提出了一種多輸入多層次注意力機制的序列到序列框架的神經網絡模型,用于解決在問題生成任務中神經網絡系統無法有效結合文章和答案句信息的問題。本文通過句子級別的注意力機制和文章級別的注意力機制融合文章信息和近答案句子信息,獲得語義信息更豐富且更注意答案的編碼表示,提升了模型對答案的語義理解。本文還提出一種新的評估方法,根據生成問題的可回答率評判問題與答案的相關程度。
雖然本文模型在BLEU等指標上取得了較好結果,但問題生成是一個一對多的任務,在問題多樣性上還沒有很好的評價方法,未來我們會對此做進一步的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
