基于分段注意力匹配網絡的跨領域少樣本關系分類
2021-10-12 04:53:12戴尚峰孫承杰單麗莉劉秉權
中文信息學報 2021年8期
戴尚峰,孫承杰,單麗莉,林 磊,劉秉權
(哈爾濱工業大學 計算機科學與技術學院,黑龍江 哈爾濱 150001)
0 引言
關系分類是自然語言處理中重要的研究內容,目的是從給定的句子中判斷兩個實體的關系類型。現有的關系分類任務多依賴于人工標注語料,不僅花費大量的人力和物力,而且由于標注成本高,存在著標注語料匱乏問題。遠程監督的方法使用知識庫對文本進行啟發式標注,部分解決了標注語料匱乏問題,但是遠程監督獲得的語料存在噪聲,并且知識庫中的長尾分布問題在語料中同樣存在,因此少樣本關系分類任務被提出。在少樣本關系分類任務中,模型需要在未訓練過的關系類型上僅用極少數據進行關系分類。然而,在實際應用中,測試數據通常與訓練數據來自不同的領域,這會導致模型在同領域測試數據上表現較好,而在不同領域測試數據上效果較差。針對上述問題,本文就跨領域少樣本關系分類任務進行研究,模型需要進一步在不同領域的測試數據上進行少樣本關系分類。
在當前的少樣本關系分類方法中,以句子級別表示為主,這類方法首先編碼句子向量,然后使用不同算法進行聚合和少樣本關系分類,如Prototypical Network[1]、Graph Neural Network[2]等,但是預測性能均差強人意。這是因為基于句子級別表示的方法往往難以精確地通過一個向量表示句子信息,而基于單詞級別表示的方法,可以更為細粒度地表示文本信息,如多層次匹配聚合網絡MLMAN[3],在少樣本關系分類任務FewRel 1.0[4]上取得了較好的效果。基于文本相似度計算的方法可以降低領域差異性帶來的影響,文獻[5]構建了跨領域測試數據集的少樣本關系分類任務FewRel 2.0,并提出了BERT-PAIR方法,使用BERT[6]模型計算句子間單詞的交互信息,通過計算文本相似度選出與查詢實例(query instance)最相似的支持集合(support set),在FewRel 2.0領域適應任務中,取得了該任務基線模型中的最好效果。
本文提出了模型PAMN(Piecewise Attention Matching Network),在BERT-PAIR[5]的基礎上進一步融合句子相似度計算方法,針對關系抽取問題,將句子分段進行匹配,能夠更準確地計算關系實例間的相似度。PAMN在編碼層使用BERT[6]模型,將句子根據實體位置分為三段,針對段長分布的跨領域差異性,使用動態段長進行段長領域自適應,在句子匹配層使用基于分段注意力機制的句子相似度計算方法,PAMN取得了目前FewRel 2.0領域適應任務測評榜單上的最好效果。
1 相關工作
近年來,基于度量的方法在少樣本學習任務中被廣泛研究。基于度量的方法使用映射函數對查詢實例和支持集合進行映射,并對映射后的向量通過度量函數分類。Prototypical Network[1]將查詢實例和支持集合中的實例映射到同一空間,使用支持集合中實例向量的中心來表示該支持集合向量,距離查詢實例向量最近的支持集合向量為查詢實例所屬的類別;Siamese Network[7]使用孿生結構對查詢實例和支持集合中的實例進行編碼,并使用距離度量函數衡量距離的遠近;Matching Network[8]引入了注意力機制和外部記憶,使模型可以更好地融合支持集合的特征;Graph Neural Network[2]加強了實例間的信息交互,將查詢實例向量和所有支持集合中的實例向量置于圖中,通過圖神經網絡進行向量的交互和更新;Induction Network[9]則通過動態路由的方式對支持集合中的實例特征進行聚合。由于少樣本關系分類任務屬于少樣本學習任務中的一種,上述提到的少樣本學習方法都可以遷移到少樣本關系分類任務中,但需要將編碼方式針對關系分類實例進行更改。
對于少樣本關系分類任務,研究人員提出了更具有針對性的方法。基于預訓練的方法通過針對性預訓練來加強模型對關系分類任務的預先理解,Soares等[10]認為相同的實體對中存在著相似的關系類型,并基于這個假設使用大量無監督數據進行預訓練,取得了當時FewRel 1.0少樣本關系分類任務測評榜單上的最好效果。基于句子相似度計算的少樣本關系分類方法屬于少樣本學習中基于度量的方法,可以減少模型在對句子編碼時損失的特征,有較好的領域適應性,多層次匹配聚合網絡MLMAN[3]使用基于單詞級別與實例級別的注意力機制對查詢實例和支持集合進行多層次匹配聚合;BERT-PAIR[5]方法使用BERT[6]模型計算句子相似度,取與查詢實例相似度最高的支持集合為查詢實例的預測類別,取得了當時FewRel 2.0領域適應任務基線模型中的最好效果,證明了基于句子相似度計算的跨領域少樣本關系分類模型的有效性。
2 問題定義
在少樣本關系分類任務中,由于訓練集與測試集沒有關系類型交集,在測試集上進行預測時,對于給定的待分類查詢實例(query instance),通過N個支持集合(support set)來表示N種關系類型,每個支持集合中有K個相同關系的實例。判斷查詢實例屬于給定支持集合中的哪一個,這樣一次預測稱為一次NwayKshot分類。在訓練集中我們以同樣的方式進行數據構建,通過訓練來提升模型在測試集中的效果。
我們將關系類型實例表示為(x,e1,e2,r),其中,x為該實例的句子,e1、e2分別為該句子中的頭實體和尾實體,r為e1、e2間存在的的關系類型;N個支持集合表示為S={Si={sij=(xij,ei,j,1,ei,j,2,ri)|j=1,…,K}|i=1,…,N},sij表示支持集合Si中的第j個實例;待分類關系類型的查詢實例表示為q=(x,e1,e2,rt),t∈{1,…,N},t為需要進行預測的類別。表1列舉了FewRel 1.0數據集中一次3 way 2 shot少樣本關系分類,我們需要判斷查詢實例中的實體(Anjani Putra,harsha)的關系類型與哪一個支持集合(S1,S2,S3)中的實體關系類型相同。
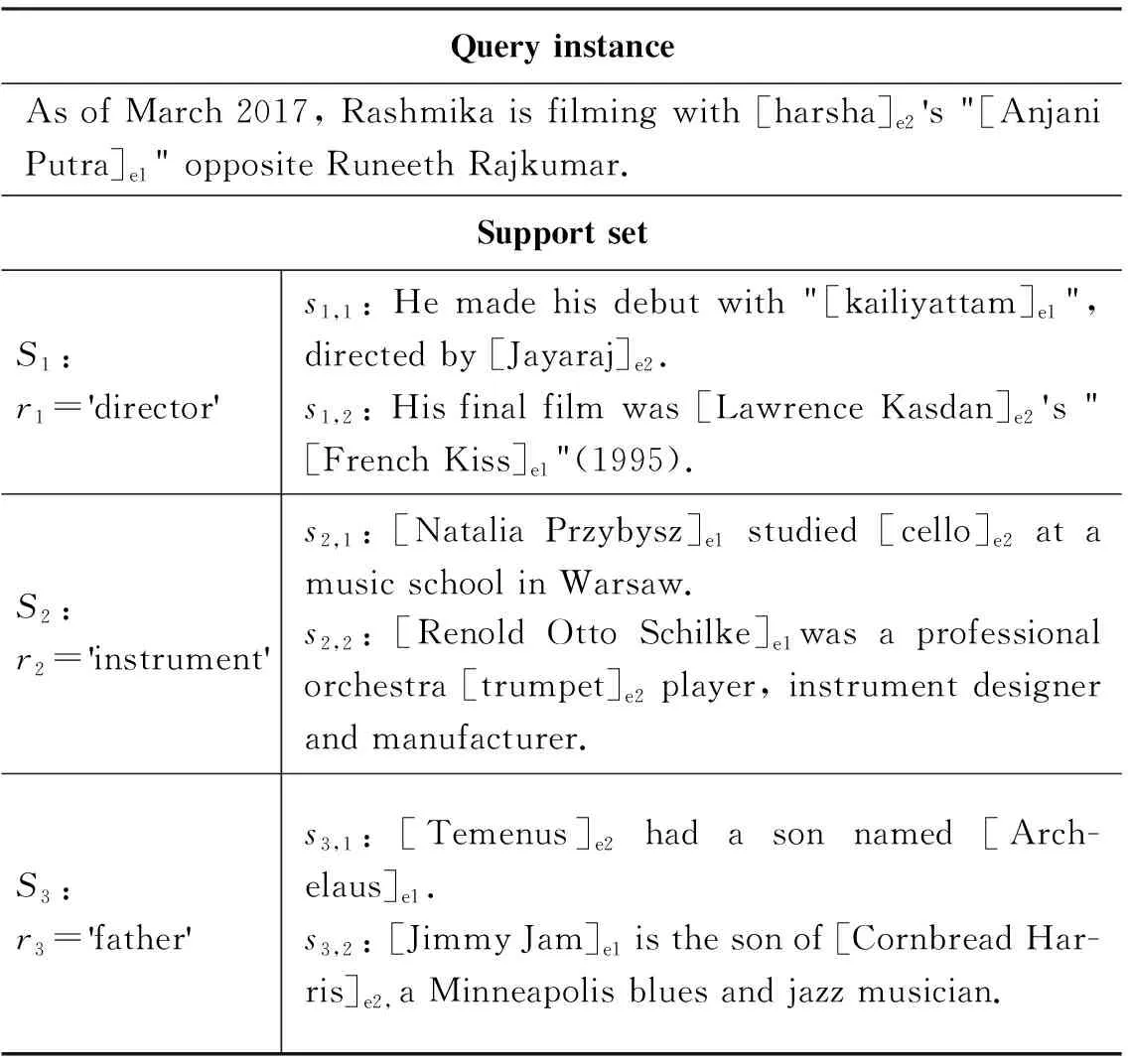
表1 FewRel 1.0數據集 3 way 2 shot例子
3 分段注意力匹配網絡(PAMN)
3.1 模型總體架構
在少樣本關系分類任務中,對于給定的查詢實例q=(x,e1,e2,rt),t∈{1,…,N}與N個支持集合S={Si={sij=(xij,ei,j,1,ei,j,2,ri)|j=1,…,K}|i=1,…,N}。我們通過句子相似度計算的方式來計算查詢實例和支持集合的相似度。首先,我們計算查詢實例q和第i個支持集合Si中第j個實例sij的相似度simij,并取均值Simi=mean(simij),j∈{1,…,K}作為q與Si的相似度,最后取t=argmax(Simi)作為預測類別。在計算simij時經過編碼層和句子匹配層。編碼層使用預訓練模型BERT[6]對q與sij進行單詞級別的編碼,句子匹配層使用分段注意力機制計算編碼后的q與sij的相似度simij。分段注意力匹配網絡PAMN結構如圖1所示。
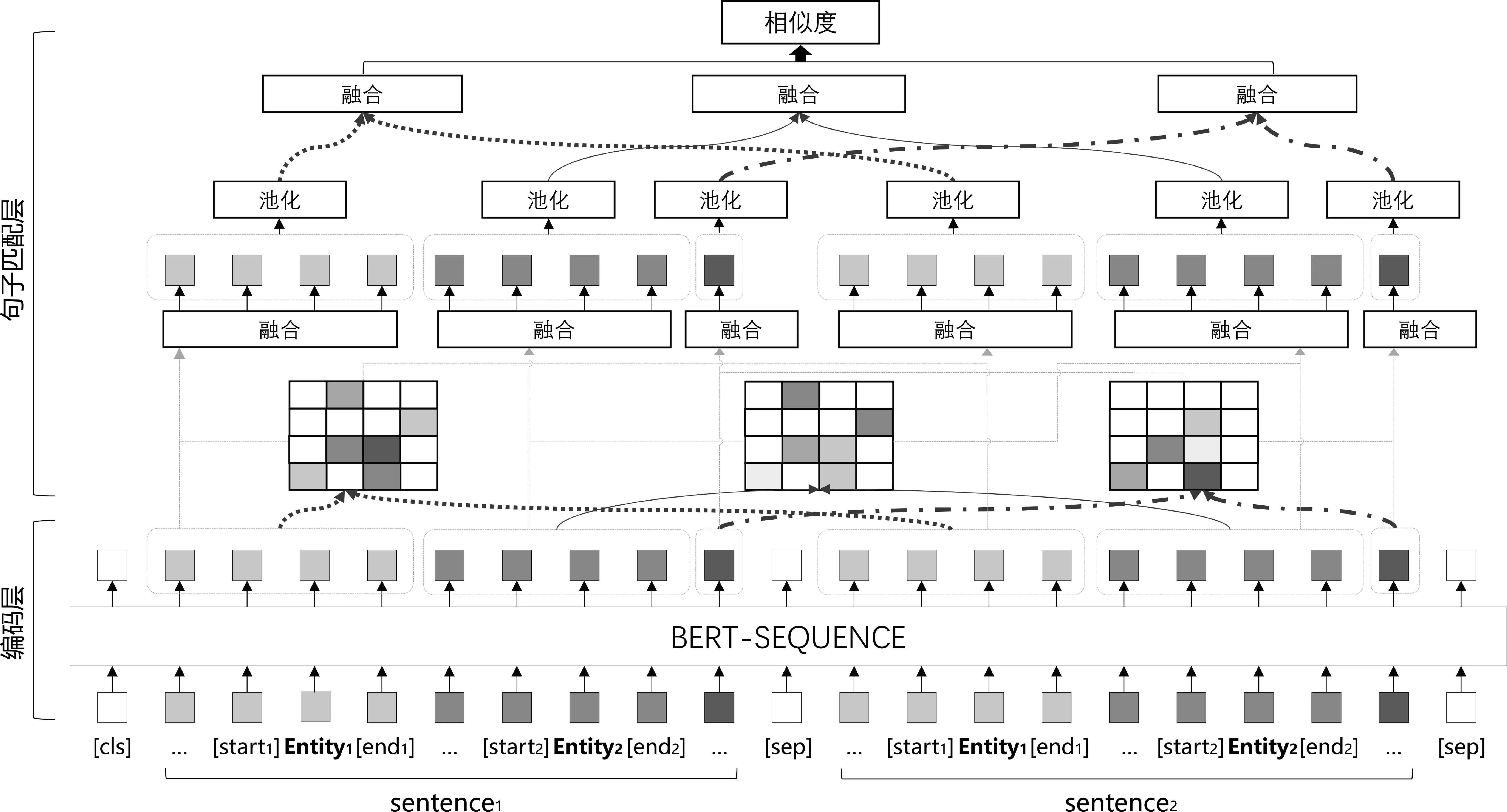
圖1 分段注意力匹配網絡PAMN結構
3.2 編碼層
在計算支持集合Si中的第j個實例sij與查詢實例q相似度時,我們使用預訓練語言模型BERT[6](BERT for sequence classification)對sij、q進行編碼,輸入BERT的句子對編碼方式與BERT-PAIR[5]相同。句中的頭實體、尾實體周圍分別使用
特殊符號[e1,start]、[e1,end]、[e2,start]、[e2,end]進行標識,將兩個句子分別表示為如下序列(頭實體在前,尾實體在后),如式(1)、式(2)所示。
其中,sentence1、sentence2表示sij和q構成待匹配的句子對,m為經過填補或截取后的固定句長,w1,1、w1,m分別表示sentence1的第一個和最后一個單詞。輸入BERT之前,在句子對前面加入BERT中的[cls]符號,中間和末尾加入[sep]符號,拼接如式(3)所示。
(3)
使用BERT中的segment_label對兩個句子中的單詞進行區分,如式(4)所示。
(4)
將input_sequence和每個單詞的segment_la-bel轉化為詞向量和segment_label向量,對應位置相加后輸入BERT,得到sentence1、sentence2對應的單詞向量序列v1∈Rm×d、v2∈Rm×d,m為句長,d為BERT輸出單詞向量的維度。與PCNN[11]類似,將向量v1,v2按照兩個實體結束符位置e1,end,e2,end分為三段,并使用動態段長m1,n,m2,n(見3.5節)進行填補或截斷,得到:v1,n∈Rm1,n×d,v2,n∈Rm2,n×d,n∈{1,2,3}。我們認為對應段間的相似單詞更具有針對性,并且可以減少跨段的無意義相似單詞對于句子相似度計算的影響,接下來,在句子匹配層,我們將通過分段注意力機制計算sentence1與sentence2的句間相似度。
3.3 句子匹配層
對于3.2節得到的段矩陣v1,n∈Rm1,n×d,v2,n∈Rm2,n×d,n∈{1,2,3},在句子匹配層使用分段注意力機制計算句間相似度,對于對應段[v1,n,v2,n],首先分別將v1,n和v2,n輸入全連接層,并使用tanh激活函數,如式(5)、式(6)所示。
分段注意力機制中,我們認為對應段間單詞的相似度更有意義,使用矩陣乘法得到對應段注意力矩陣Mn,其中,Mn,i,j表示sentence1第n段的第i個單詞v′1,n,i和sentence2第n段的第j個單詞v′2,n,j的相似度,i∈{1,…,m1,n},j∈{1,…,m2,n},如式(7)所示。
Mn,i,j=(v′1,n,i)Tv′2,n,j
(7)
使用交叉注意力獲取對應段中的相似特征表示。對于sentence1中第n段sentence1,n的每個單詞向量的相似特征,使用sentence2的對應段sentence2,n中單詞向量的加權和來表示,sentence2,n中每個單詞向量的相似特征以同樣的方式通過sentence1,n表示,加權權重為對應段注意力矩陣Mn中的單詞相似度。
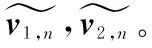
接下來,將對應段的特征表示進行融合,如式(16)所示。
mn=tanh([v1,n,max;v1,n,avg;v2,n,max;v2,n,avg]W5+b5)
(16)
對于所有對應段使用上述相同的操作,不同段的全連接層使用不同參數(全連接層參數為W1~W15和b1~b15,其中,W1~W5、b1~b5為第一段參數;W6~W10、b6~b10為第二段參數;W11~W15、b11~b15為第三段參數),得到m1,m2,m3,拼接得到m,如式(17)所示。
m=[m1;m2;m3]
(17)
最后經過全連接層將m映射為1維向量,即表示sentence1與sentence2(sij與q)的句間相似度,如式(18)所示。
simij=(tanh(mW16+b16))W17+b17
(18)
3.4 預測方法與損失函數
在預測階段,根據查詢實例q與支持集合Si中每個實例sij的相似度simij的均值,表示q與Si整體的相似度Simi=mean(simij),j∈{1,…,K}。取相似度最大的支持集合St的下標t=argmax(Simi),i∈{1,…,N}作為預測標簽。使用交叉熵損失函數計算預測相似度Simi與標簽yi間的損失值,如式(19)、式(20)所示。
3.5 段長分布與動態段長
在實驗階段,我們發現雖然FewRel 1.0訓練集、FewRel 1.0驗證集與FewRel 2.0驗證集(數據集介紹見4.1節)均沒有關系類型交集,但是由于FewRel 2.0驗證集領域不同,導致它與其他兩個數據集句長分布差異較大(經過BERT Tokenizer[6]處理后的句長),我們統計了三個數據集的句長均值、標準差,以及句子根據實體分為三段后不同段的段長均值和標準差,如圖2所示。
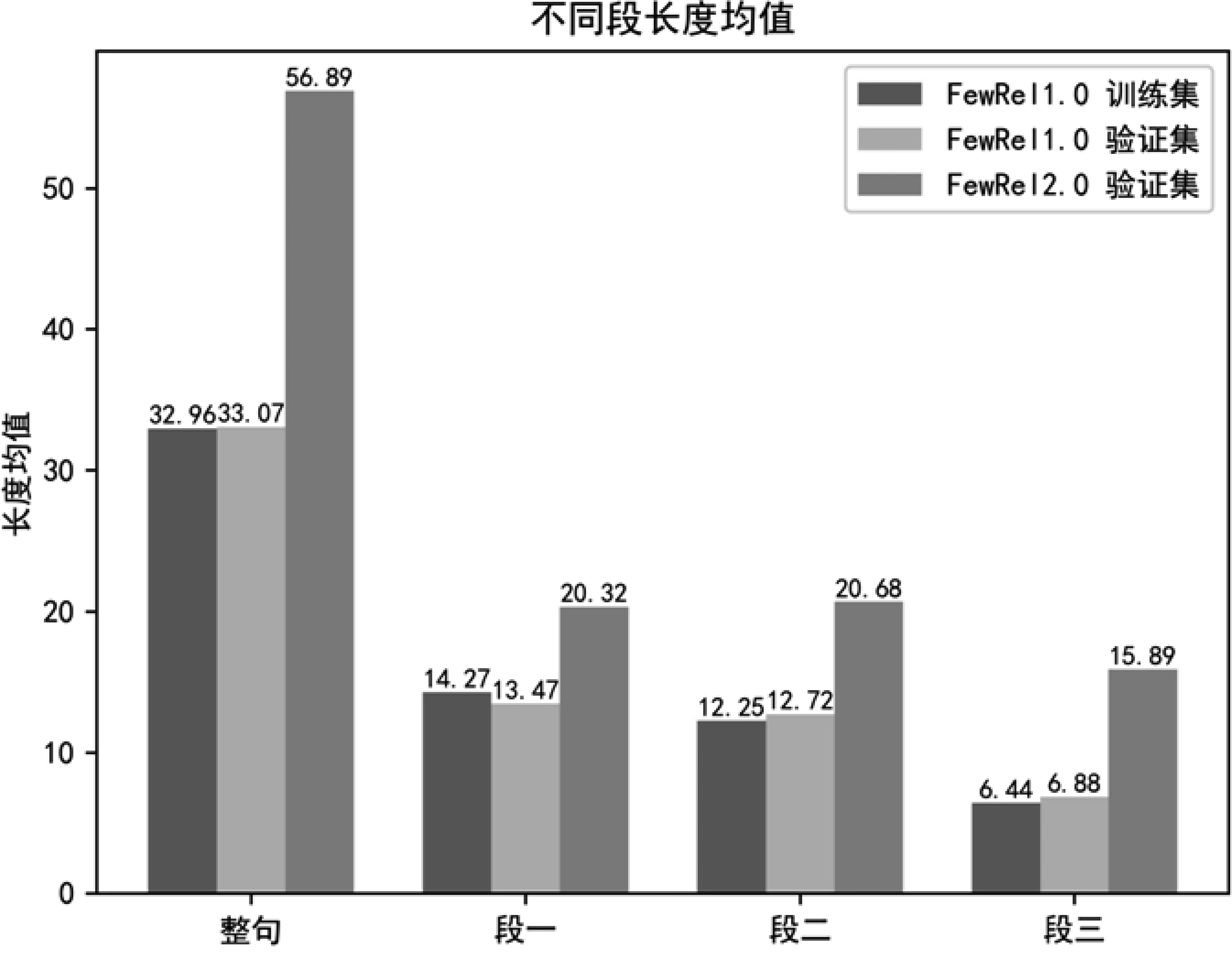
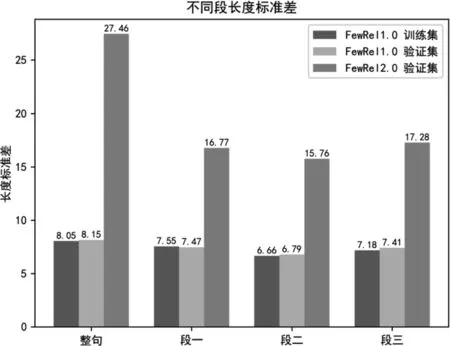
圖2 FewRel1.0訓練集、驗證集和FewRel 2.0驗證集不同段的長度均值、標準差
從圖2可以看出,段長分布存在著較大的跨領域差異性,無論是句長還是每一段的段長,FewRel 2.0驗證集都存在長度較長且標準差較大的問題,我們使用動態段長實現領域適應。首先,輸入BERT的句子對長度從訓練集的115(單句長m=56,加上頭部的[cls]與中間和尾部的[sep]標識符后,句長由(115)修改為驗證集的243(單句長m=120),同時,在NwayKshot分類時共有Q×N×K(Q為預測的Query數目)個句子對,在分段進行填補或截斷時,我們將長度設置為Q×N×K個句子對中該段段長均值的1.5倍,如式(21)所示。
(21)
其中,1≤i≤Q×N×K,1≤n≤3,m1,n,m2,n分別表示第i個句子對中第一個句子sentencei,1與第二個句子sentencei,2每段的動態段長,leni,1,n,leni,2,n表示sentencei,1與sentencei,2根據實體分為三段后每段的長度,這樣每次NwayKshot分類時動態段長會根據段長均值進行自適應,使得填補或截斷后的段長可以覆蓋大部分段長,同時不會變得過長或過短,當我們在不同領域數據集上進行實驗時,段長會根據領域進行自適應。
4 實驗
4.1 數據集
我們的訓練集為FewRel 1.0訓練集,共有64種關系類型,每類有700個關系實例;驗證集為FewRel 1.0驗證集和FewRel 2.0領域適應任務驗證集,其中,FewRel 1.0驗證集有16種關系類型,每類有700個關系實例,FewRel 2.0驗證集共有10種關系類型,每類有100個關系實例;測試集由Few-Rel 2.0領域適應任務測評提供,共有15種關系類型,每類有100個關系實例,其中,訓練集、驗證集、測試集沒有關系類型交集,最后我們將驗證集上效果最好的模型提交到FewRel 2.0領域適應任務測評中,得到測試集結果。
4.2 數據構建
在訓練與測試時,均需要將數據構建為少樣本NwayKshot分類數據,構建算法如表2所示。
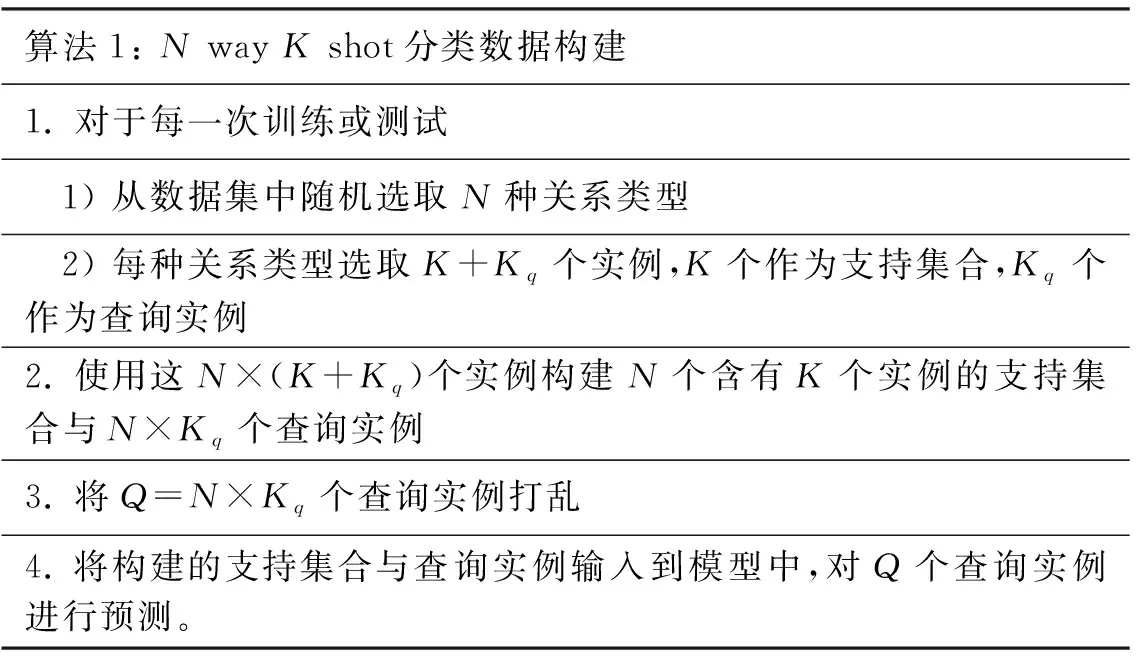
表2 N way K shot 分類數據構建算法
4.3 訓練細節與參數設置
我們的模型在5 way 5 shot上進行訓練,在5 way 1 shot(5-1)、5 way 5 shot(5-5)、10 way 1 shot(10-1)、10 way 5 shot(10-5)上進行驗證和測試,通過分類準確率來評估模型性能。
由于每次NwayKshot分類數據構建使用隨機抽樣的方式,為了能夠充分地學習訓練集信息,使得訓練集的每個數據都經過模型訓練,我們將訓練次數設置為30 000次,同時每訓練1 000次,使用驗證集對模型進行驗證,驗證次數設置為1 000次,并保存驗證集準確率最高的模型參數。設置較高的驗證頻率是因為模型擬合速度較快,為了保存模型領域適應性最好的參數,需要在整個訓練期間保持較高的驗證頻率,防止得到的模型參數過擬合。訓練完成后,為了準確評估模型在驗證集上的效果,使用被保存的模型參數在驗證集上進行5 000次驗證,把得到的準確率作為驗證集評估結果。
我們使用BERTbase參數對BERT模型進行參數初始化,對BERT之外的參數使用Xavier[12]進行初始化,學習率設置為10-5,優化器使用Adamw[13],同時在BERT模型后以0.2的概率對單詞序列向量進行dropout,防止模型對數據過擬合。BERT模型輸出維度d為768,全連接層W1~W15輸出維度為460,W16、W17輸出維度分別為230和1。
4.4 實驗結果
我們在FewRel 2.0領域適應任務測評中提交模型,與FewRel 2.0論文中的模型Proto(BERT)、Proto-ADV(CNN)、BERT-PAIR進行對比,結果如表3所示。
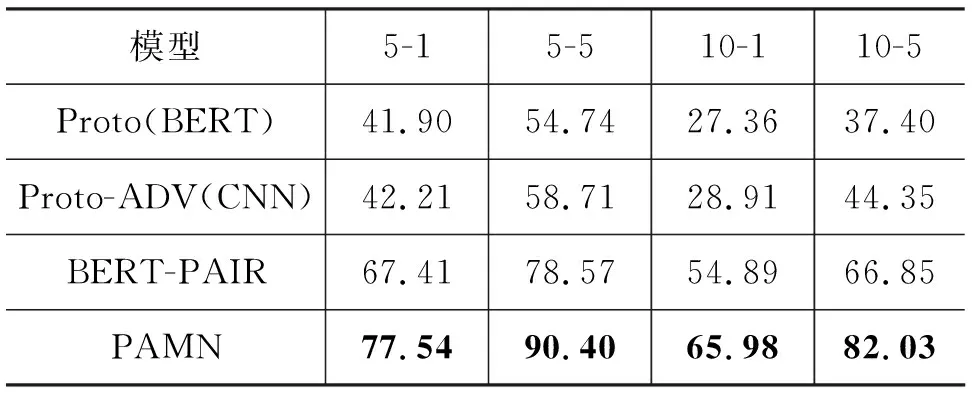
表3 不同模型在FewRel 2.0測試集上的準確率 (單位: %)
PAMN在FewRel 2.0領域適應任務測評中取得了當前榜單上的最好效果,相較于FewRel 2.0領域適應測評中最好的模型BERT-PAIR,準確率提升超過10個百分點,證明了PAMN在領域適應任務中的有效性。同時我們將在dropout=0.1時訓練的模型提交到FewRel 1.0測評中,并與FewRel 1.0測評中效果最好的模型BERT-PAIR、MLMAN進行對比,由于MTB[10]使用了大量額外數據對實體關系預測進行針對性預訓練,所以這里不與MTB進行比較,實驗結果如表4所示。
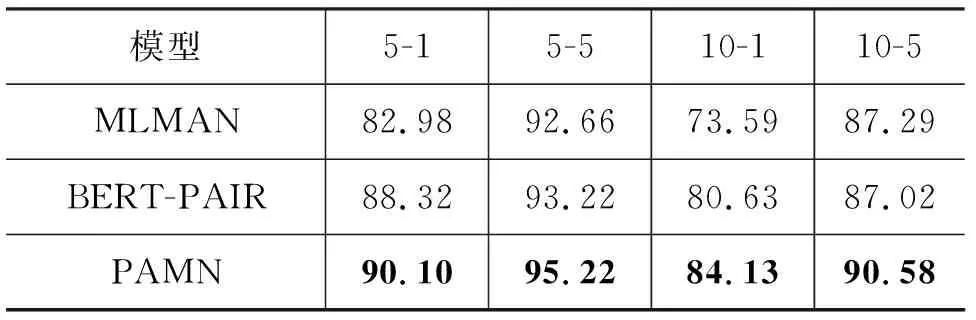
表4 不同模型在FewRel 1.0測試集上的準確率 (單位: %)
由于FewRel 1.0偏向于特定領域,我們沒有針對FewRel 1.0對PAMN進行過多調整,僅調低dropout,降低模型的泛化性,與BERT-PAIR[5]模型相比,PAMN在FewRel 1.0任務上同樣有著2至3個百分點的提升。
4.5 對比實驗
為了分析PAMN中各部分結構對于模型的影響。我們在FewRel 2.0驗證集上設置了兩組對比實驗。對比實驗中的標準模型將句子分為三段,并使用非孿生結構的PAMN。第一組實驗研究分段注意力機制對模型的影響,我們分別使用不將句子分段的PAMN,將句子分為四段(第四段為整個句子)的PAMN與標準模型進行比較。第二組實驗研究孿生結構對模型的影響,孿生結構有著較好的泛化性,我們將網絡結構調整為孿生結構,即對兩個句子的對應段使用共享參數的全連接網絡,與標準模型進行比較。
第一組實驗研究分段注意力機制對模型的影響,其中分三段為標準模型,在FewRel 2.0驗證集上的結果如表5所示。
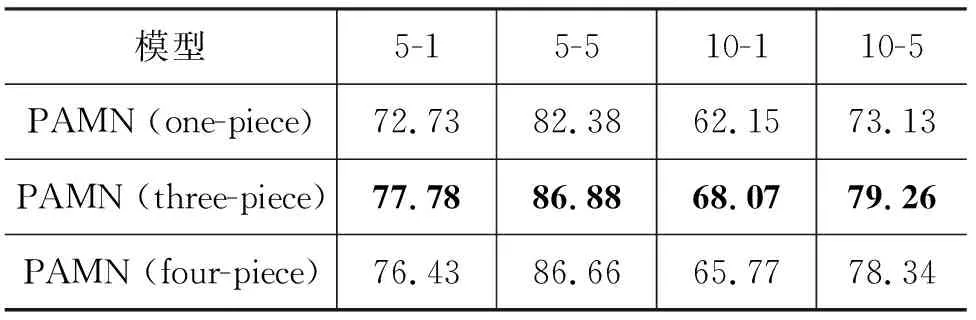
表5 不同分段數模型在FewRel 2.0驗證集上的準確率 (單位: %)
從表5可以看出,將整個句子分為三段比不分段效果要好,分析原因可能有: ①在少樣本關系分類問題中,同一關系分類實例,不同段各司其職,表達不同的內容,段與段間的表達方式、數據分布存在較大差異。PAMN模型的分段匹配結構,能夠更精準地利用每一段的語義信息。②不同關系分類實例間分布差異較大(句長標準差大),相較于匹配長度較長、句式復雜的整句,PAMN匹配長度更短、句式簡單且分布波動較小(標準差小)的段,可以獲得更好的匹配結果。下面的句1和句2即為一對關系分類匹配實例:
句1: [CHKT]e1is a Canadian radio station, airing at 1430 AM in [Toronto]e2,Ontario.
句2: [WSFF]e1is licensed to [Vinton, Virginia]e2, serving Metro Roanoke.
根據實體位置進行分段后,“[CHKT]e1”和“[WSFF]e1”為第一段,“is a Canadian radio station, airing at 1430 AM in [Toronto]e2”和“is licensed to [Vinton, Virginia]e2”為第二段,“,Ontario”和“,serving Metro Roanoke”為第三段,對應段之間存在著較強的匹配關系,符合模型匹配時的期望。
但是不分段時可以額外匹配到兩個句子中不同段間單詞的相似特征,這部分特征是將句子分為三段時所缺少的。將句子分為四段(第四段為整個句子)相當于在三段的基礎上加入了整個句子不同段間相似單詞的特征,既考慮了相同段間的特征,又考慮了不同段間的特征,但是實驗結果卻表明,分為四段比分為三段模型準確率要低,這說明引入不同段間的特征反而影響了模型的表現,我們認為這是因為不同段間特征中噪聲較多,即無意義的相似特征較多,導致真正能對文本匹配起作用的特征混在噪聲中,因而無法起到預期的作用。
第二組實驗研究孿生結構對模型的影響,其中,非孿生結構為標準模型,在FewRel 2.0驗證集上的結果如表6所示。
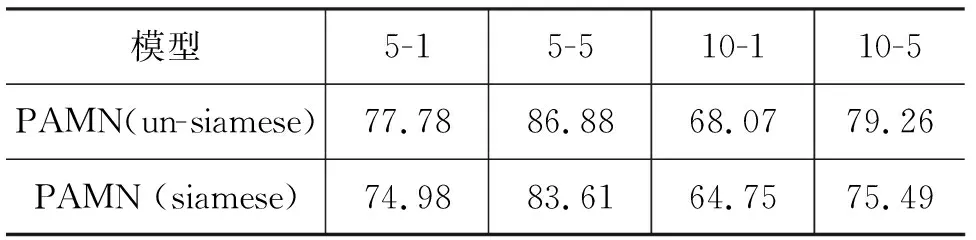
表6 非孿生與孿生結構模型在FewRel 2.0驗證集上的準確率 (單位: %)
在孿生結構測試部分,不同模型性能差異非常大,使用非孿生結構時效果較好,而使用孿生結構時效果較差,我們認為使用相同的參數對向量進行映射會導致向量相似度增加,向量的部分特征會被減弱,導致在句子匹配層誤差增加,模型性能降低。
5 總結
本文提出了基于分段注意力機制的跨領域少樣本關系分類方法PAMN,通過句子相似度計算的方法計算查詢實例和支持集合實例間的相似度,具有良好的領域適應性,同時針對關系分類實例使用分段注意力機制進行分段匹配,使得模型可以更準確地計算關系分類實例間的句子相似度,最后針對不同領域間段長分布差異的問題,使用動態段長進行段長領域自適應。PAMN取得了目前FewRel 2.0領域適應測評榜單的最好效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
