結合用戶長短期興趣的深度強化學習推薦方法
2021-10-12 04:52:56閻世宏馬為之劉奕群馬少平
中文信息學報 2021年8期
閻世宏,馬為之,張 敏,劉奕群,馬少平
(清華大學 計算機系 北京信息科學與技術國家研究中心,北京 100084)
0 引言
隨著信息技術的快速發展,互聯網中的信息總量激增與用戶有限的認知能力間的矛盾構成了嚴重的信息過載問題。推薦系統作為一種個性化服務,能夠向用戶主動推薦其感興趣的信息、商品等(以下統稱“物品”)來緩解信息過載問題。近年來,推薦系統已被廣泛應用于電子商務、電影音樂、新聞推薦、社交網絡等多個場景。
在推薦系統研究中,如何準確刻畫用戶興趣是最重要的一步。在真實場景下,用戶興趣是非常復雜且多變的。一方面,用戶會有長期的偏好與興趣,在相當長的一段時間內保持穩定。另一方面,用戶在一個時間段內可能對部分內容更感興趣,隨著時間推移產生實時的需求與興趣點。因此,從長期與短期兩個角度學習用戶的潛在興趣對提高推薦系統的性能非常重要。
深度強化學習(DRL)[1-2]自提出以來在多種具有挑戰性的連續決策場景中展現出巨大優勢。在推薦場景中,深度強化學習能夠實時學習用戶的潛在興趣,并且能夠交互式地更新用戶的潛在興趣表示與推薦策略。除此之外,深度強化學習還有很強的長期連續決策能力,能夠考慮未來推薦過程中累計的效益。近年來,強化學習的工作在推薦領域中得到應用并被重視,獲得了良好的效果。
然而,我們注意到在現有的基于深度強化學習推薦方法中,絕大部分方法過于強調短期內的用戶興趣,對長期穩定的用戶興趣學習不足。例如,DRN方法[3]使用用戶在不同時間段內點擊新聞的特征統計信息來表示用戶狀態,進而學習用戶的短期興趣;Deep Page方法[4]與DEERS方法[5]通過門控循環單元(GRU)從用戶最近的交互歷史序列中學習用戶的短期興趣;在FeedRec方法[6]利用分層的長短時記憶網絡(LSTM)從用戶最近的交互記錄序列以及停留時間等附加信息中學習用戶的短期興趣。盡管這些方法能夠很好地學習用戶的短期興趣,但由于缺乏對用戶長期興趣的學習,可能會陷入用戶實時的興趣點中,導致嚴重的有偏推薦,使得給用戶推薦的內容最終集中于很小的興趣點,難以滿足用戶的真實信息需求。
針對這一問題,本文研究了如何在深度強化學習中同時學習用戶的長期興趣與短期興趣,并提出了一個可以應用于深度Q網絡(Deep Q-Network)及其后續變種的Q-網絡框架(Long andShort-term Preference Learning Framework based on DeepReinforcementLearning, LSRL)。該框架使用協同過濾技術[7]學習用戶的長期興趣,并利用門控循環單元(GRU)[8]從用戶近期的正反饋和負反饋交互行為中得到用戶的短期興趣,再結合兩個模塊學習到的信息對用戶的反饋做出預測,最后生成面向用戶的推薦結果。
本文的主要貢獻是: ①提出在深度強化學習的推薦方法中應當引入用戶長期興趣,從而更精準地建模用戶興趣; ② 提出了基于深度強化學習的LSRL框架,實現了結合用戶的長期興趣與短期興趣的模型; ③在真實數據集的實驗表明,LSRL框架在歸一化折損累計增益(NDCG)與命中率(Hit Ratio)上比其他基線模型有顯著提升。
本文的組織結構如下:第1節形式化地定義了推薦任務并介紹LSRL框架的結構與訓練方法;第2節給出實驗設置,分析實驗結果并探究不同因素對模型性能的影響;第3節介紹本文相關工作;第4節總結本文工作并展望未來的研究思路。
1 LSRL框架
在本節中,首先定義本文研究的推薦任務,然后介紹LSRL框架的結構與訓練方法, 最后對比LSRL框架與其他基于深度強化學習方法的異同。
1.1 任務定義
本文將推薦過程視為推薦系統選擇待推薦物品與用戶給出對推薦物品的反饋的交互序列,并建模該交互序列為馬爾可夫決策過程(MDP),最大化推薦過程中的長期累積獎勵。建模后的馬爾可夫決策過程(MDP)包含形如(S,A,R,P,γ)的五元組,五元組中每個元素的定義如下:
(1)狀態空間S: 時刻t下狀態st∈S的定義是用戶在時刻t之前最后N個正反饋交互記錄與最后N個負反饋交互記錄分別構成的序列,如果不足N個則使用虛擬物品補全。其中,N是模型超參數。
(2)動作空間A: 時刻t下狀態at∈A的定義是推薦系統在時刻t時推薦給用戶的項目。
(3)獎勵空間R: 時刻t下狀態rt∈R的定義是用戶在時刻t的反饋對應的即時獎勵值。本文中獎勵值取值范圍為{0,1}:如果用戶給出正反饋,則rt=1;如果用戶給出負反饋,則rt=0。
(4)狀態轉移P: 時刻t下狀態轉移被定義為形如(st,at,rt,st+1)的四元組。
(5)衰減因子γ: 衰減因子γ的定義是每間隔一個時間步長,即時獎勵值衰減到原值的γ倍。
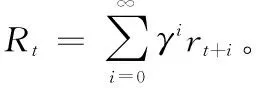
1.2 框架結構
LSRL框架基于深度Q網絡(DQN)[1]算法,本節首先簡要介紹DQN算法并指出LSRL相對于DQN的主要改進,然后詳細描述LSRL框架的結構。
1.2.1 深度Q網絡(DQN)
深度Q網絡是一種基于價值優化的深度強化學習算法。該算法通過學習狀態—動作值函數Q(s,a)(以下簡稱“值函數”)來估計推薦系統在狀態s下向用戶推薦項目a的長期累積獎勵。最優值函數Q*(s,a)是最佳推薦策略π*對應的值函數。
根據強化學習的假設,最優值函數Q*(s,a)應該遵循Bellman方程,如式(1)所示。
深度Q網絡的損失函數L(θ)定義為:
其中,在計算Qtarget時,需要使用上一訓練周期的參數θ—來降低訓練的不穩定性,通常使用兩個結構相同的Q-網絡并定期同步參數來實現。
深度Q網絡的訓練過程如圖1所示,帶底紋的兩個框代表兩個結構相同的Q-網絡,LSRL框架重新設計了該部分來同時學習用戶的長期興趣與短期興趣表示。
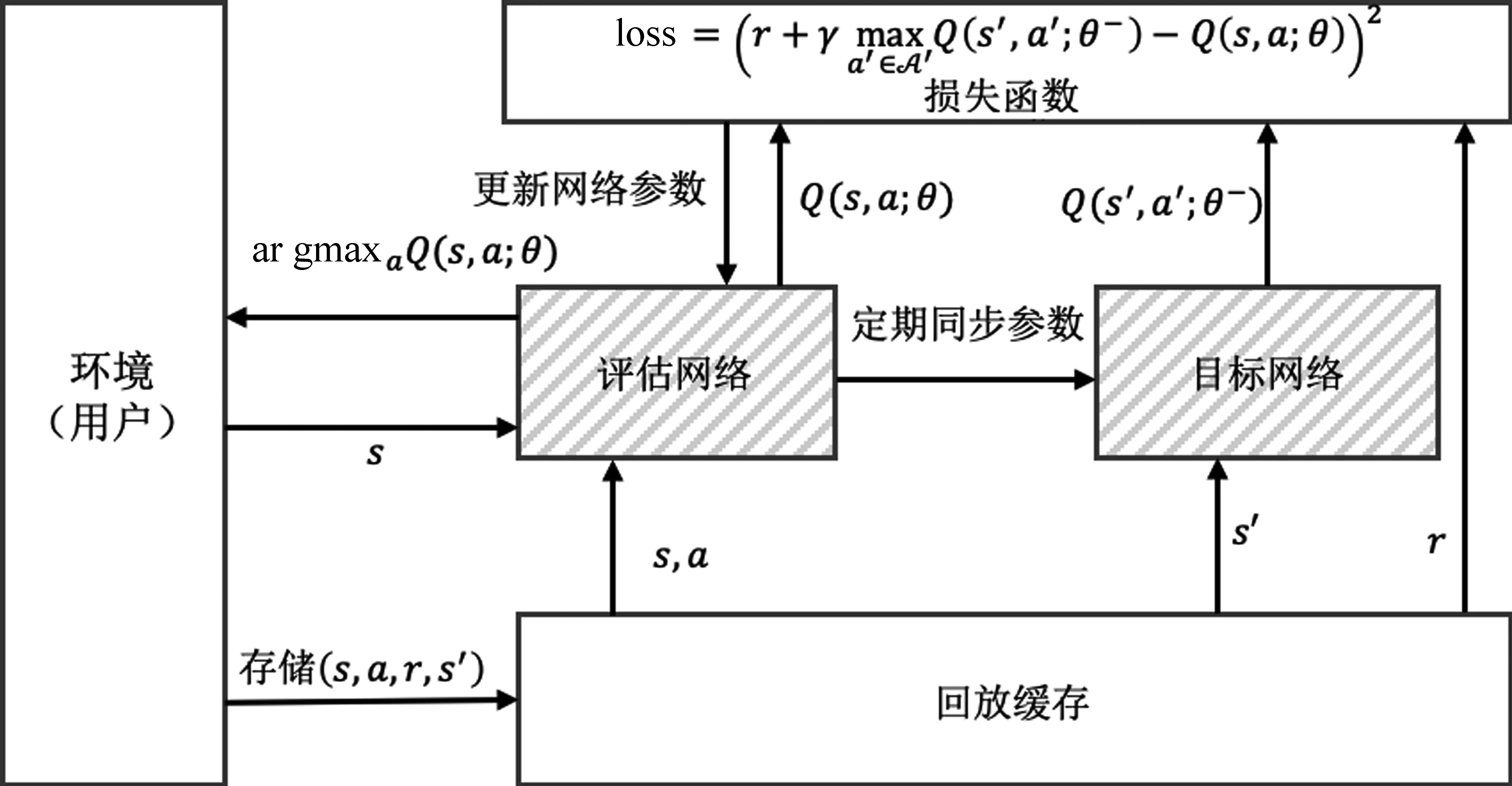
圖1 深度Q網絡的訓練過程
1.2.2 LSRL框架
LSRL框架分為長期興趣模塊、短期興趣模塊與預測模塊。Zhao等人的工作[5]指出負反饋交互行為能夠提高深度強化學習推薦方法的推薦準確度,因此在短期興趣模塊我們令其同時學習正反饋交互序列與負反饋交互序列中隱含的用戶短期興趣。LSRL框架結構如圖2所示。
1.2.3 長期興趣模塊
圖2中左側部分為長期興趣模塊。用戶的長期興趣是使用基于協同過濾的方法學習的,用戶的向量表示在學習過程中利用所有的交互歷史信息,能夠代表用戶長期的興趣偏好特征。最底層為嵌入層,用戶u與待推薦物品i分別通過用戶嵌入層與物品嵌入層,得到用戶向量表示pu與物品向量表示qi。與傳統的協同過濾方法[9-10]做內積運算不同,為了更好地學習用戶向量表示pu與物品向量表示qi之間的交互,LSRL模型選擇使用與He等人工作[7]中類似的多層感知機(MLP)結構。拼接pu、qi兩個向量作為第一層向量,并在該層向量后添加多層隱藏層。長期興趣模塊的形式化如式(4)所示。
其中,Wk、bk、ak是第k層隱藏層的權重矩陣、偏置矩陣與激活函數。根據測試,激活函數設置為線性整流函數(ReLU)[11]。最后,得到長期興趣模塊的輸出vlongL。
1.2.4 短期興趣模塊
圖2右側部分為短期興趣模塊。在短期興趣模塊中,對正反饋交互歷史序列的處理與負反饋交互歷史序列的處理是類似的,這里只介紹對正反饋交互序列的處理。用戶的最近N個正反饋交互記錄{i1,i2,…,iN}組成正反饋交互序列。為了降低模型復雜度與參數數量, 正反饋交互歷史 序列與負反饋交互歷史系列與待推薦物品共享同一個物品嵌入層。正反饋交互序列經過物品嵌入層后得到物品表示向量序列{qi1,qi2,…,qiN}。Hidasi等人的工作[12]指出:門控循環單元(GRU)[8]在推薦任務中學習序列信息能力通常優于長短時記憶網絡(LSTM)[13],且計算量更低。因此LSRL框架使用門控循環單元(GRU)從正反饋交互歷史序列中學習用戶的短期興趣。門控循環單元(GRU)引入了更新門控zn與重置門控rn控制循環神經網絡的記憶能力,具體計算如式(5)~式(8)所示。
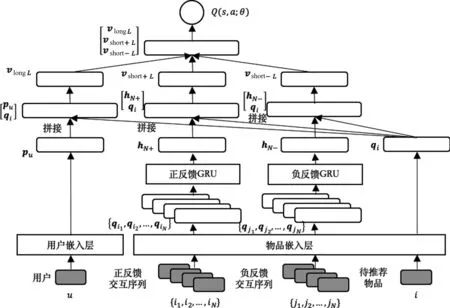
圖2 LSRL框架結構
LSRL框架使用GRU的最后一個隱層向量hN+作為正反饋交互序列的向量表示。與長期興趣模塊類似,將正反饋交互序列的向量表示hN+與待推薦物品向量qi拼接作為多層感知機(MLP)的輸入vshort+1,經過多個隱層后,得到短期興趣模塊的正反饋輸出vshort+L。
LSRL框架使用結構相同但是參數不同的門控循環單元(GRU)與多層感知機(MLP),從用戶的最近N個負反饋交互記錄{j1,j2,…,jN}組成負反饋交互序列中得到短期興趣模塊的負反饋輸出vshort-L。
1.2.5 預測模塊
預測模塊的作用是利用長期興趣模塊與短期興趣模塊的輸出,計算當前用戶正反饋交互序列與負反饋交互序列(狀態)與待推薦物品(動作)間的值函數Q(s,a)。
因為在長期興趣模塊與短期興趣模塊內部用戶興趣向量都與待推薦物品向量間通過多層感知機(MLP)進行了充分的交互,所以預測模塊的結構比較簡單。首先拼接長期興趣模塊的輸出vlongL與短期興趣模塊的輸出vshort+L、vshort-L,接下來通過多層感知機(MLP)得到最終輸出Q(s,a)。
1.3 參數學習
如1.2節所述,LSRL框架通過重新設計深度Q網絡(DQN)中Q網絡的結構來同時學習用戶的長期興趣與短期興趣,即只更改了值函數Q(s,a)的計算方式。因此,我們可以繼續沿用深度Q網絡模型的損失函數與訓練方法。
由于真實場景中的狀態空間S與動作空間A通常規模巨大,式(2)中的期望值難以直接計算。實際訓練中通常采用小批量梯度下降方法 (Mini-Batch Gradient Descent),隨機選取小批量狀態轉移過程集合P,然后計算該集合上的期望值,并使用Adam優化器優化模型參數。
深度Q網絡(DQN)中使用深度網絡擬合值函數Q(s,a),這通常會導致模型訓練不穩定。為了降低模型訓練難度,用戶嵌入層與物品嵌入層使用預訓練向量初始化,并在之后的訓練過程中保持固定,不再隨反向傳播更新。經過對比測試,選擇概率矩陣分解(PMF)方法[9]并使用二分類交叉熵(Binary Cross Entropy)損失函數訓練得到的嵌入層權重。除此之外,為了限制模型表達能力,穩定訓練過程并防止過擬合現象,LSRL框架在損失函數中引入L2正則化項。
算法1中給出了LSRL框架的訓練方法。

算法1:LSRL框架訓練方法1:初始化回放緩存D2: 隨機初始化評估網絡參數并設置預訓練嵌入層權重,同步評估網絡參數到目標網絡3:對每一個會話(Session)循環:4: 根據用戶之前的會話初始化狀態s05: 對每一個推薦項目循環:6: 從離線數據中觀察狀態、動作、反饋7: 根據反饋更新狀態8: 存儲狀態轉移(st,at,rt,st+1)到回放緩存D中9: 從回放緩存中采樣小批量狀態轉移集合P10: 在小批量狀態轉移集合P上最小化損失函數L(θ)11: 更新評估網絡模型參數12: 如果距離上次同步達到一定時間:13: 同步評估網絡參數到目標網絡14: 結束條件判斷15: 結束循環16:結束循環
2 實驗
2.1 實驗設置
2.1.1 數據集
MovieLens[14]: MovieLens是一個被廣泛使用的電影評分數據集,包含不同規模的評分記錄。本文選取MovieLens-100K、MovieLens-1M與MovieLens-10M三個規模的數據集,數據集的統計數據見表1。每一條評分記錄包括用戶與物品的序號、用戶對電影的評分與評分的確切時間。用戶對電影的評分范圍是1-5分,本文認為小于等于3分為負反饋,大于3分為正反饋。數據集中每個用戶交互數量均大于等于20。
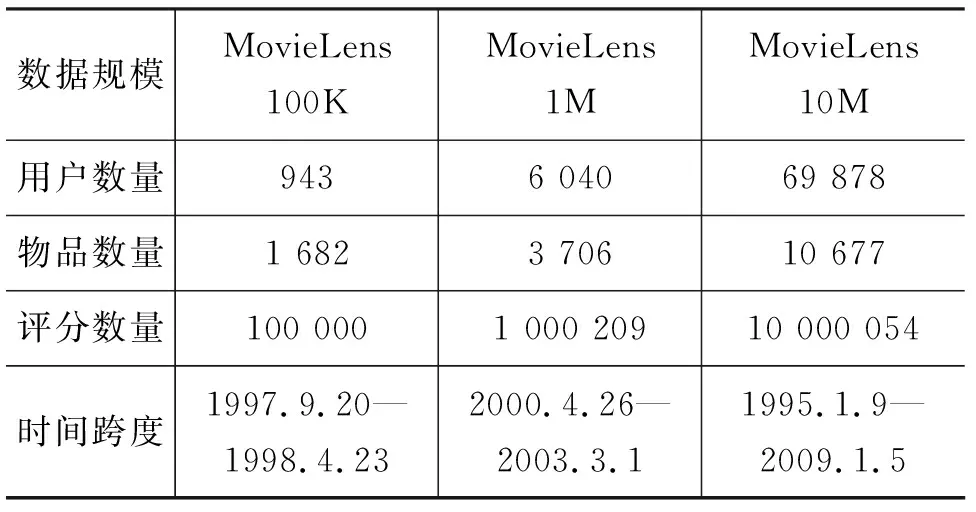
表1 數據集概況
對每一個用戶u,根據評分時間信息確定用戶交互記錄序列Su。將Su以如下方式劃分[15]:①用戶最后一次正反饋交互記錄用于測試,舍棄該記錄之后的負反饋交互記錄; ②用戶倒數第二次正反饋交互記錄用于驗證,舍棄驗證記錄與測試記錄間的負反饋交互記錄; ③所有剩余交互記錄用于訓練。測試集的交互序列輸入中包含驗證集的交互記錄。對于驗證集與測試集中的每一個正反饋記錄,分別隨機從物品集合中抽樣出該用戶沒有交互過的99個物品作為負例,構成長度為100的候選物品集合。為了公平比較,在訓練過程前采樣出候選物品集合,并應用于所有模型的驗證與測試過程。
2.1.2 基線方法
為了測試提出的LSRL模型的性能,選取了三組方法作為基線方法。
不考慮用戶交互記錄時間序列的推薦方法:
(1)PMF[9]:概率矩陣分解方法,是一種隱向量方法。將用戶交互矩陣分解為低秩的用戶隱矩陣與物品隱矩陣的乘積,從概率角度解釋矩陣分解過程。PMF只考慮存在記錄的用戶—物品對。
(2)SVD++[10]:SVD++改進了概率矩陣分解方法,結合隱向量方法與鄰域方法的優勢,在預測函數中考慮用戶所有隱式交互行為。
(3)NCF[7]:神經協同過濾方法,結合深度神經網絡與協同過濾方法,使用多層感知機(MLP)學習用戶—物品交互信息。
基于用戶交互記錄時間序列的推薦方法:
(4)GRU4Rec[12];首個應用循環神經網絡(RNN)的推薦方法,使用門控循環單元(GRU)從短期的會話數據中刻畫序列信息,并提出新的排序損失函數。
(5)SASRec[16]:利用自注意力機制(Self-Attention Mechanism)學習用戶交互序列的方法,從相對較短的序列中學習歷史交互過的物品間的相關性并預測下一個物品。
基于深度強化學習的推薦方法:
(6)DQN[1];深度Q網絡,首個結合深度神經網絡的基于價值優化的強化學習方法,使用神經網絡擬合狀態—動作值函數。
(7)DEERS[5]:首個同時從正反饋交互序列與負反饋交互序列中建模用戶狀態的基于深度強化學習的推薦方法。
表2中比較了LSRL框架與所有基線方法的異同。
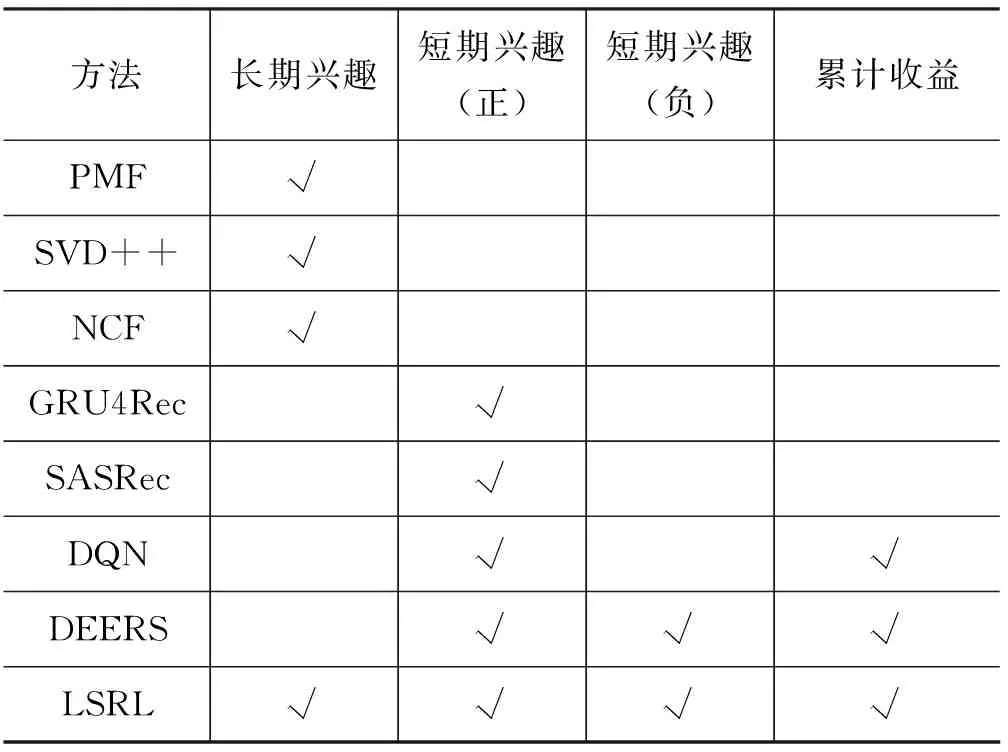
表2 基線方法與LSRL框架比較
2.1.3 評價指標
在驗證與測試階段,對每個候選物品集合,排序其中的物品。為了評價排序后的推薦列表質量,我們選擇命中率(Hit Ratio, HR)與歸一化折損累計增益(Normalized Discounted Cumulative Gain, NDCG)作為評價指標。
如果使用a表示某個候選物品集合中用戶給出過正反饋的唯一物品的序號,xi表示排序后推薦列表里第i個物品的序號,那么推薦列表前k個物品的命中率(HR)可以通過式(9)計算:
其中,I(xi=a)是指示函數,如果第i個物品是用戶給出過正反饋的物品,返回1,否則返回0。命中率(HR)衡量了用戶給出過正反饋的物品是否在推薦列表的前k個物品中。為了衡量該物品的位置,首先計算折損累計增益(DCG),如式(10)所示。
然后我們計算正反饋物品處于第一位的推薦列表的DCG并令其為理想折損累計增益(IDCG),則歸一化折損累計增益(NDCG)可以通過式(11)計算:
對驗證集或測試集中的每一個候選物品集合計算排序后推薦列表的評價指標,并匯報所有候選物品集合的平均值。
2.1.4 實現細節(1)實驗代碼在如下鏈接:https://github.com/THUyansh/LSRL
我們使用PyTorch實現了所有的推薦方法,并使用Adam優化器學習模型參數,直至驗證集上NDCG@10評價指標連續20輪次不再提升,最大訓練輪次為100。對于每一種推薦方法,我們應用驗證集上NDCG@10最高的輪次對應的模型參數在測試集上測試。每個推薦方法使用不同的隨機種子重復運行5次,并匯報5次試驗結果的平均值。
為了公平地對比不同的推薦方法,批量大小均設置為256,嵌入層維度均設置為64。特別地,所有基于深度強化學習的推薦方法,衰減因子γ設置為0.9。其他的超參數被設置為推薦方法論文作者的推薦值,或者根據驗證集上NDCG@10的結果來選擇。
2.2 實驗結果
表3~表5展示了LSRL框架與所有其他基線方法在不同數據集上的實驗結果。其中,粗體的實驗結果表示在該規模數據集下所有推薦方法中最高的評價指標值,標注下劃線的實驗結果表示在該規模數據集下所有基線方法中最高的評價指標值;標注“*”符號的實驗結果標明該結果在雙側t檢驗中比基線方法的最佳結果有顯著性的提升。顯著性檢驗中p<0.01。
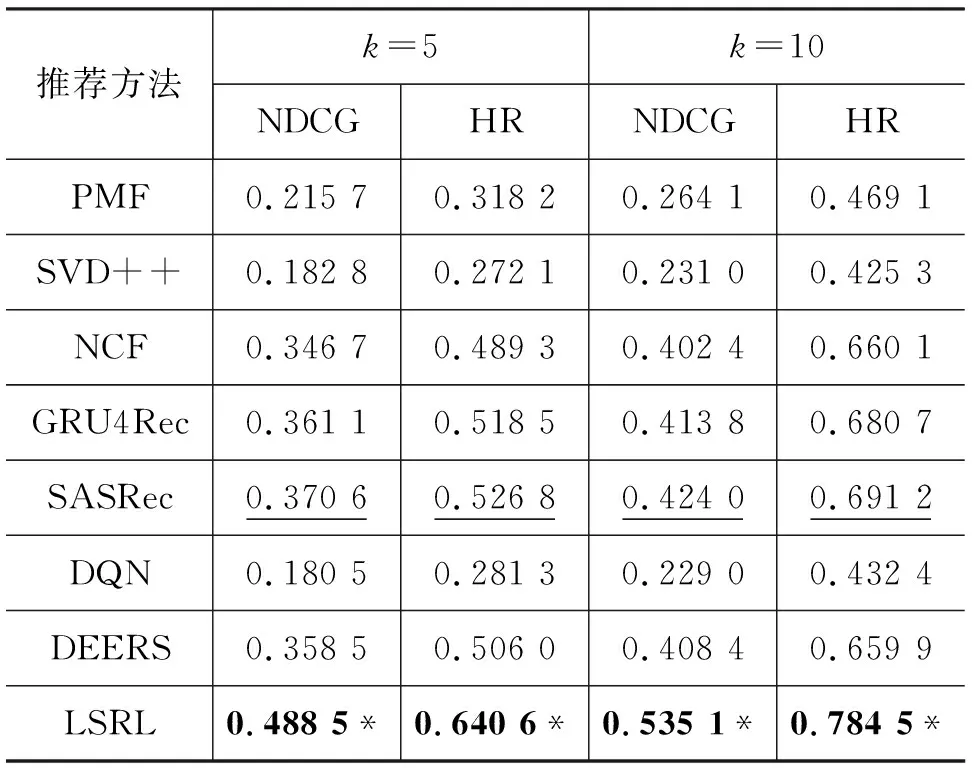
表3 MovieLens-100K實驗結果

表4 MovieLens-1M實驗結果
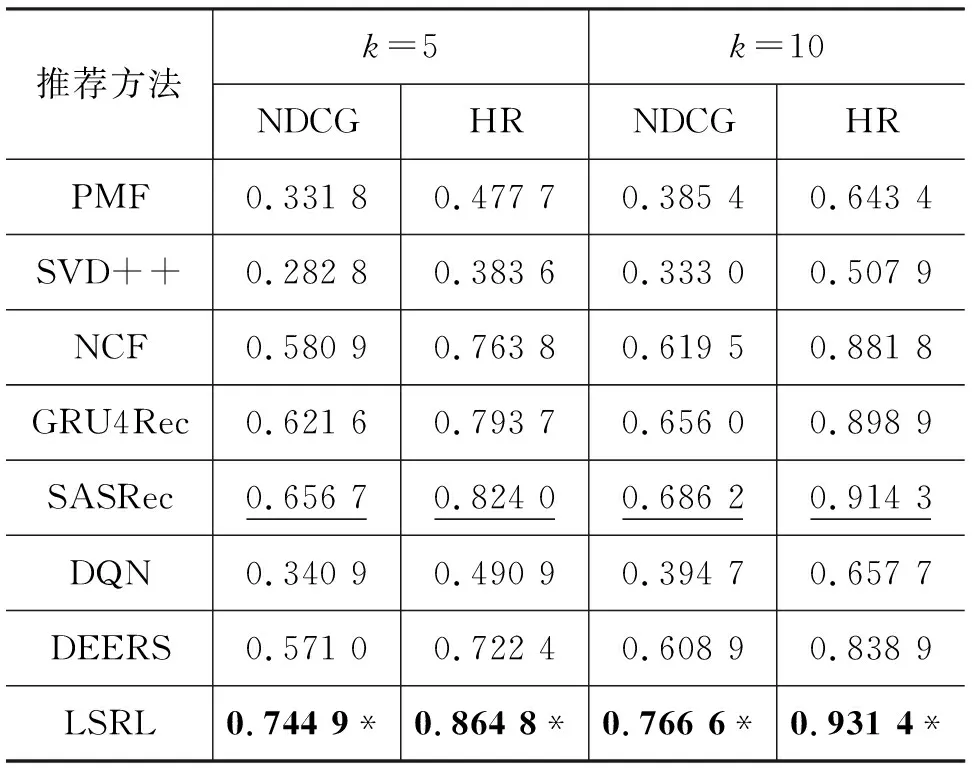
表5 MovieLens-10M實驗結果
在不同規模的數據集上,每種推薦方法的表現都有所差異。
在不考慮用戶交互記錄時間序列的推薦方法中,NCF方法在三個規模的數據集上都獲取了最佳表現。這表明NCF方法在結合了深度神經網絡之后,模型的表達能力比PMF與SVD++方法中的內積運算更強,能夠從訓練數據中學習出更多的信息。
所有基于用戶交互記錄時間序列的推薦方法的表現都比不考慮用戶交互記錄時間序列的推薦方法好。其中,SASRec方法在三個數據集上的表現始終是所有基線模型中最優的。這說明了建模用戶短期興趣可以幫助推薦系統更準確地推薦物品。
基于深度強化學習的三個推薦方法效果差異較大。DQN方法的表現與基礎的PMF模型類似。DEERS方法的表現要顯著好于DQN方法,這驗證了在深度強化學習中引入用戶負反饋交互信息是有效的。LSRL方法的表現明顯優于DEERS方法,這證明融合用戶長期興趣與短期興趣能夠顯著提高推薦系統的性能。
綜合所有基線模型,LSRL方法只在MovieLens-1M數據集上的HR評價指標上沒有獲得最佳數值,比SASRec方法稍差。這可能是因為MovieLens-1M數據集的數據特征與其他兩個數據集不同,橫向比較三個數據集上不同方法的實驗結果,發現只有MovieLens-1M數據集上基于時間序列建模用戶短期興趣的推薦方法與能夠同時建模用戶長期興趣與短期興趣的LSRL方法非常接近,這說明該數據集中用戶興趣以短期興趣為主導因素,LSRL方法中的長期興趣模塊會引入一定程度的噪音,使得命中率(HR)指標稍差。但在NDCG評價指標上,LSRL方法依然優于SASRec方法,根據兩個評價指標的計算方式可以發現,在推薦列表排序能力上,LSRL方法更有優勢,更傾向于將用戶感興趣的物品排序到靠近列表頭部的位置。LSRL方法在其他所有評價指標上都相對所有基線模型有顯著性的提升,表現出了良好的排序能力與推薦準確性。
2.3 消融實驗與分析
為了驗證LSRL框架中強調兩個因素(用戶長期興趣與短期興趣)對框架推薦效果的影響,我們進行了消融實驗,分別保留長期興趣模塊、短期興趣模塊(正反饋)與短期興趣模塊(負反饋)中的一個或幾個模塊,在MovieLens-100K與MovieLens-1M數據集上測試推薦效果。表6直觀地給出不同模型使用的信息。

表6 消融實驗中使用的模型
消融實驗的結果如表7所示,表中只匯報NDCG@10的結果。其中,LSRL-P方法在三個數據集上都顯著優于SRL-P方法,LSRL方法也顯著優于SRL方法,這表明無論短期興趣模塊是否引入用戶的負反饋交互序列,融合長期興趣模塊都會提高推薦準確度。而LSRL-P方法與LSRL方法比LRL方法有更好的表現,說明短期興趣模塊同樣重要。

表7 消融實驗結果
3 相關工作
3.1 推薦系統中的用戶興趣建模
在推薦系統研究中,準確刻畫用戶興趣是非常重要的。隨著推薦系統的發展,建模用戶興趣的方式也在不斷變化。用戶興趣建模方式大概可以分為三種:只建模用戶長期興趣、只建模用戶短期興趣與同時建模用戶長期興趣與短期興趣。
只建模用戶長期興趣的代表性推薦方法有矩陣分解(Matrix Factorization, MF)方法與其變種[9-10]。矩陣分解方法將用戶交互矩陣分解為低秩的用戶隱矩陣與物品隱矩陣,通過訓練學習出一個固定的用戶隱向量來表達用戶興趣。在預測時,由于用戶向量表示固定不變,矩陣分解方法無法通過用戶實時的交互行為來推薦項目。
只建模用戶短期興趣的代表性推薦方法是僅利用用戶最近交互行為的模型。Covington等人的工作[17]利用平均池化(Average Pool)的方法從無序的用戶交互行為中學習用戶興趣。Hidasi等人提出的GRU4Rec模型[12]使用門控循環單元(GRU)從有序的用戶交互行為序列中建模用戶短期興趣。Zhou等人提出的DIN模型[18]利用注意力機制(Attention Mechanism)計算不同用戶交互行為的權重,獲得了比平均池化方法更好的表現。Kang等人提出的SASRec方法[16]使用自注意力(Self-Attention Mechanism)從有序的交互行為中挖掘用戶興趣。這些推薦方法的共同特點是利用用戶最近的交互行為進行推薦,容易受用戶實時的興趣點影響,難以給用戶推薦更全面的物品列表。
除此之外,部分推薦方法可以同時建模用戶的長期興趣與短期興趣。An等人提出的LSTUR模型[19]提出兩種方式融合用戶興趣并進行新聞推薦:使用用戶嵌入向量初始化循環神經網絡的隱藏層;將用戶嵌入向量與循環神經網絡的輸出拼接。Hu等人提出的GNewsRec模型[20]結合了注意力機制與圖神經網絡用于新聞推薦。Wu等人提出的LSPL模型[21]結合了注意力機制與循環神經網絡。
3.2 基于深度強化學習的推薦方法
近年來強化學習算法在推薦領域中受到重視,一些基于深度強化學習的方法被提出。這些方法將用戶歷史交互行為視為環境狀態,將推薦物品視為動作用戶,根據模型訓練方式的不同可以分為兩類:基于價值優化的算法與基于策略優化的算法。
基于價值優化的算法在訓練中學習狀態—動作值函數Q(s,a),在所有的候選動作中選出當前用戶狀態下具有最大Q值的待推薦物品推薦給用戶。 Mnih等人提出的深度Q網絡模型(Deep Q-Network, DQN)[1],首次結合深度學習技術到強化學習中,使用深度網絡擬合狀態-動作值函數,并引入經驗回放技術與目標網絡技術穩定的訓練過程。 Zheng等人提出的DRN模型[3],將DQN應用到新聞推薦場景中,將用戶在不同時間段內瀏覽新聞的統計信息作為用戶狀態,并引入用戶活躍度信息。Zhao等人提出的DEERS模型[5],利用門控循環單元(GRU)同時從用戶正反饋與負反饋歷史交互序列中建模用戶短期興趣,并提出了引入成對排序正則化項的損失函數。Zou等人提出的FeedRec模型[6]使用分層的長短時記憶網絡(LSTM)從用戶的點擊、停留、重新訪問等多種行為中建模用戶短期興趣,并提出了一些新技術穩定深度強化學習訓練中的不確定性。
基于策略優化的算法在訓練中學習推薦策略,輸入用戶當前狀態后,推薦策略輸出待推薦的物品。Zhao等人提出的DeepPage模型[4]擴展了深度確定性策略梯度模型(DDPG)[22],并研究了推薦一個頁面的物品的排序優化方法。
以上絕大多數方法僅使用循環神經網絡(RNN)等方法學習用戶的短期興趣,忽略了用戶的長期興趣,導致對用戶的興趣建模存在不足。因此我們在LSRL框架中引入了用戶長期興趣,從而更精準地建模用戶興趣。
4 結語
本文提出了基于深度強化學習的LSRL框架,成功地引入了用戶長期興趣,更加準確地建模用戶興趣。具體地,LSRL框架使用協同過濾技術(CF)與循環神經網絡(RNN)分別建模用戶長期興趣與短期興趣,并設計了新的Q-網絡融合不同模塊學習到的信息。在多個真實數據集上的實驗結果表明,我們提出的LSRL框架能夠實現同時學習用戶的長期興趣與短期興趣,并比所有的基線推薦方法在不同的評價指標上有顯著的性能提升。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
