基于Bert和卷積神經網絡的人物關系抽取研究
2021-10-15 10:38:56杜慧祥楊文忠石義樂柴亞闖王麗花
東北師大學報(自然科學版) 2021年3期
杜慧祥,楊文忠,石義樂,柴亞闖,王麗花
(1.新疆大學軟件學院,新疆 烏魯木齊 830002;2.新疆大學信息科學與工程學院,新疆 烏魯木齊 830002)
0 引言
隨著互聯網數據爆炸式的增長,各種半結構化數據與非結構化數據也在不斷增多.如何從半結構化數據與非結構化數據中提取有效的結構化信息,是當前信息抽取領域的一個研究熱點和難點.信息抽取作為自然語言處理領域中的一個重要的研究子領域,近年來受到了國內外研究學者的不斷研究,其中實體關系抽取技術是信息抽取中的一個關鍵技術,也是構建知識圖譜的重要技術之一,其主要的研究目的是從包含實體對以及包含某種語義關系的句子中提取出所需要的關鍵信息.目前實體關系抽取技術主要分為有監督的、半監督的、無監督的、開放領域的、基于遠程監督的、基于深度學習的等6類方法.有監督的關系抽取又分為基于特征向量的方法和基于核函數[1]的方法.基于特征向量的方法是從包含關系的句子中,選擇該句的上下文中包含的詞法、語法和句法等特征來構造特征向量,進一步通過計算特征向量的相似度來訓練實體關系抽取模型,最后完成關系抽取.基于核函數的方法也是比較常用的一種方法,文獻[2]采用淺層解析樹核與SVM、投票感知器相結合的算法從非結構化的文本中抽取人-從屬關系和組織-位置關系.文獻[3]通過擴展前人工作,提出依賴樹核,通過計算依賴樹核的相似度來進行實體關系抽取,實驗結果表明,基于依賴樹核的方法比基于“詞袋”核的效果有較大的提高.
有監督的實體關系抽取方法雖然在一定程度上提高了關系抽取的效率,但是需要人工標注大量的語料,因此有人提出了半監督的實體關系抽取方法.半監督的實體關系抽取最先提出的是Bootstrapping方法[4],該方法首先人工設定若干種子實例,然后迭代從數據中抽取關系對應的關系模板和更多的實例.半監督實體關系抽取技術可以減少人工標注數據的語料,但是該方法需要人工構建高質量的初始種子集,且該方法不可避免地會引入噪聲和語義漂移現象.
在面對大規模語料的時候,有監督和半監督的關系抽取方法往往不能預測到所有位置的實體關系類型,因此人們提出了基于聚類方法的無監督關系抽取.無監督的實體關系抽取在無標注的數據集中利用聚類算法將上下文中出現的實體對相似度高的聚為一類,用包含特定意義的詞來表示這種關系.無監督的實體關系抽取方法不需要人工預先定義的關系類型,但其聚類的閾值確定相對較難,且目前基于無監督的實體關系抽取方法沒有統一的評價指標.
基于開放領域的實體關系抽取方法,是為了構建某領域的語料庫時減少人工的參與,該方法在不需要任何人工標注的情況下,通過與外部大型知識庫(如DBpedia、YAGO、FreeBase等)將完整的、高質量的實體關系實例與大規模的訓練數據對齊來獲得大量的訓練數據.基于遠程監督的關系抽取方法也是為了減少人工參與標注數據集而被提出來的.文獻[5]首次提出基于遠程監督的實體關系抽取方法,該方法假設兩個實體間如果存在某種關系,那么在整個語料庫中包含這兩個實體的句子都存在這種關系.該方法在一定程度上減少了對標注數據集的依賴,但其也帶來了數據噪聲和錯誤傳播的問題.
近年來,隨著深度學習的快速發展,將深度學習的方法應用到實體關系抽取中得到了大量研究學者的關注.文獻[6]提出將遞歸神經網絡與矩陣向量表示相結合的模型,該模型可以學習任意長度的短語和句子的向量表示,但是忽略了實體對之間的位置信息以及其他的特征信息;文獻[7]利用卷積神經網絡的方法進行實體關系抽取,采用詞向量和位置向量作為卷積神經網絡的輸入,通過卷積層、池化層和非線性層得到句子的表示;文獻[8]針對捕獲句子中重要信息不明確的問題提出了基于注意力機制的雙向長短期記憶神經網絡(ATT-BILSTM).
目前在關系抽取領域中主要針對的是英文,但近年來隨著深度學習技術的廣泛使用,對中文關系抽取的研究也有了一定的進展,文獻[9]提出一種基于自注意的多特征實體關系提取方法,該方法充分考慮了詞匯、句法、語義和位置的特征,并利用基于自注意機制的雙向長短期記憶網絡預測實體之間關系;中文關系抽取任務中的數據稀疏和噪聲傳播問題一直是研究的難點,文獻[10]提出一種將位置特征、最短依存等特征融合起來,并提升關鍵特征的權重,改善了噪聲傳播的問題;文獻[11]提出一種多通道的卷積神經網絡用來解決單一詞向量表征能力的問題,該模型利用不同的詞向量作為輸入語句,然后傳輸到模型的不同通道中,最后利用卷積神經網絡提取特征,利用Softmax分類器完成關系分類.以上方法大多數是采用早期預訓練方法詞嵌入(Word Embedding)進行向量表示,詞嵌入的方法是2003年最早提出的[12],該方法利用了詞分布表示考慮了上下文之間的相似度.2013年谷歌公司的研究人員發布了Word2vec工具包,該工具包包含了Skip-Gram模型和CBOW模型[13],兩個模型能夠獲取文本之間相似性,但只考慮了文本中的局部信息而忽略了全局信息.2018年Google發布了Bert預訓練模型[14],該模型通過充分的對詞和句進行提取,能夠得到動態編碼詞向量捕獲更長距離的依賴,在2018年10月底公布了Bert在11項NLP任務中的表現,Bert取得了較好的結果.因此本文在Bert預訓練模型下,提出了Bert-BiGRU-CNN的網絡模型進行人物關系抽取.該網絡模型首先通過Bert預訓練模型獲取包含上下文語義信息的詞向量,然后利用雙向門控循環單元(BiGRU)和卷積神經網絡(CNN)提取上下文相關特征進行學習,最后通過全連接層利用Softmax進行關系分類.
1 模型介紹
本文提出的Bert-BiGRU-CNN模型如圖1所示,其主要結構:(1)Bert層.利用Bert預訓練模型獲取包含上下文語義信息的詞向量.(2)BiGRU層.獲取上下文的文本特征.(3)CNN層.進一步獲取文本的局部特征.(4)輸出層.利用Softmax分類器進行關系分類.
1.1 Bert層
大多數模型采用的都是2018年Google公司的研究人員提出了Bert預訓練模型,該模型在自然語言處理領域得到了廣泛的好評,隨后Google公司公開了Bert預訓練模型在11項自然語言處理任務中取得的效果,肯定了Bert預訓練模型的學術價值.Bert預訓練模型主要包含輸入層和多層Transformer編碼層,其基本結構圖如圖2所示.Bert的輸入層是通過詞向量(Token Embeddings)、段向量(Segment Embeddings)和位置向量(Position Embedings)3個部分求和組成,且給句子的句首句尾分別增加了[CLS]和[SEP]標志位.Transformer編碼層是文獻[15]提出來的,包含了多個結構相同的編碼器和解碼器,從編碼器輸入的句子會通過一個自注意力(Self-Attention)層,然后傳輸到前饋神經網絡(Feed-Forward Neural Network)中,解碼器中除了包含這兩層之外,在這兩層之間多了一個注意力層,以此來關注與輸入句子中相關的部分.Bert預訓練模型的提出與傳統的Word2vec、Glove預訓練模型相比,Bert能夠充分考慮詞上下文的信息,獲得更精確的詞向量.本文采用Google公開的預訓練好的中文模型“Bert-Base,Chinese”獲取句子向量并作為模型的輸入.

圖1 Bert-BiGRU-CNN模型結構
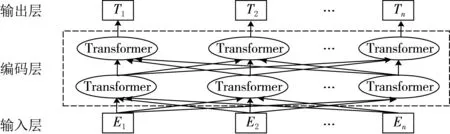
圖2 Bert模型結構
1.2 BiGRU層
循環神經網絡(Recurrent Neural Network)是一種處理序列數據的神經網絡,其每個時刻的預測結果不僅依賴當前時刻的輸入,還依賴于所有之前時刻的中間結果.由于每次輸入都依賴之前的所有輸入,所以存在梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)的問題.文獻[16]為了解決這個問題提出了LSTM(Long Short-Term Memory)網絡.LSTM網絡中包含輸入門、遺忘門和輸出門.輸入門用來控制當前狀態哪些信息應該保存到內部狀態中;遺忘門用來控制過去狀態中包含的信息是否應該刪除;輸出門用來控制當前內部狀態下的多少信息需要傳輸到外部狀態中.GRU網絡是LSTM網絡的一種簡化模型,GRU神經網絡[17]與長短期記憶網絡(LSTM)相比,GRU網絡將LSTM中的輸入門與遺忘門替換為單一的更新門,更新門能夠決定從各個狀態中保留信息或者刪除信息,除此之外GRU網絡中還包含重置門,重置門是用來控制候選狀態的計算是否與上一狀態有依賴關系.GRU網絡的具體計算公式為:
zt=σ(Wzxt+Uzht-1);
(1)
rt=σ(Wtxt+Utht-1);
(2)
(3)
(4)
其中:WZ,Wt,W,Uz,Ut,U表示權重矩陣;zt,rt分別表示為更新門與重置門;tanh表示激活函數;xt表示當前時刻的數據輸入;ht-1表示上一時刻的輸出;·表示矩陣點乘.
1.3 CNN層
卷積神經網絡(CNN)作為圖像領域的一種經典網絡模型,近年來被廣泛應用到自然語言處理領域中.本文在雙向門限循環單元層之后加入了卷積神經網絡來進一步獲取語義的局部特征.主要由輸入層、卷積層、池化層、全連接層、輸出層5個部分構成.
(1) 輸入層.將雙向門限循環單元(BiGRU)的輸出作為輸入.
(2) 卷積層.卷積運算包含一個卷積核w∈Rh×k,該濾波器被應用于h字的窗口產生一個新的特征.例如,特征ci是從詞xi:i+h-1窗口產生的,公式為
ci=f(w·xi:i+h-1+b).
(5)
其中:b是一個偏置項,f是一個非線性函數,如雙曲正切等.·表示矩陣之間的點乘,將卷積核應用到句子{x1:h,x2:h+1,…,xn-h+1:n}中生成特征圖
c=[c1,c2,c3,…,cn-h+1].
(6)
(3) 池化層.池化層不僅能夠降維,還能保留特征和防止過擬合的現象發生.本文采用最大池化對卷積層之后得到的句子局部特征進行下采樣,獲得局部最優值
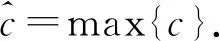
(7)
(4) 輸出層.通過卷積神經網絡層進一步獲取局部特征,輸出層采用Softmax分類器作為最后關系分類.
本文利用雙向門限循環單元(BiGRU)層的輸出作為卷積神經網絡的輸入層,通過卷積層進一步獲取語義的局部特征,池化層采用Max-Pool(最大值池化)來降低語義特征維度,減少了模型的參數,保證了卷積層的輸出上獲得一個定長的全連接層的輸入.最后采用全連接層利用Softmax分類器進行分類.
2 實驗部分
2.1 數據集和實驗設置
目前有關中文人物關系抽取的公開數據集比較少,因此本文通過在線知識庫復旦大學知識工廠實驗室研發的大規模通用領域結構化百科CN-DBpedia來獲取實體對,CN-DBpedia中的數據主要從百度百科、互動百科、中文維基百科等網站的頁面文本中獲取.將確定好的實體對利用爬蟲技術在新浪、百度百科、互動百科等網站頁面中獲取包含實體對的句子,通過人工整理后,構建出了人物關系數據集.該數據集包含了14類人物關系,10 155條實例數據,數據格式為〈實體1 實體2 關系類別、包含實體1和實體2的句子〉.實驗采用隨機的方法將人物關系數據集中的8 124條實例數據作為訓練集,2 031條實例數據作為測試集.每種關系類別的數量如表1所示,數據格式示例如表2所示.
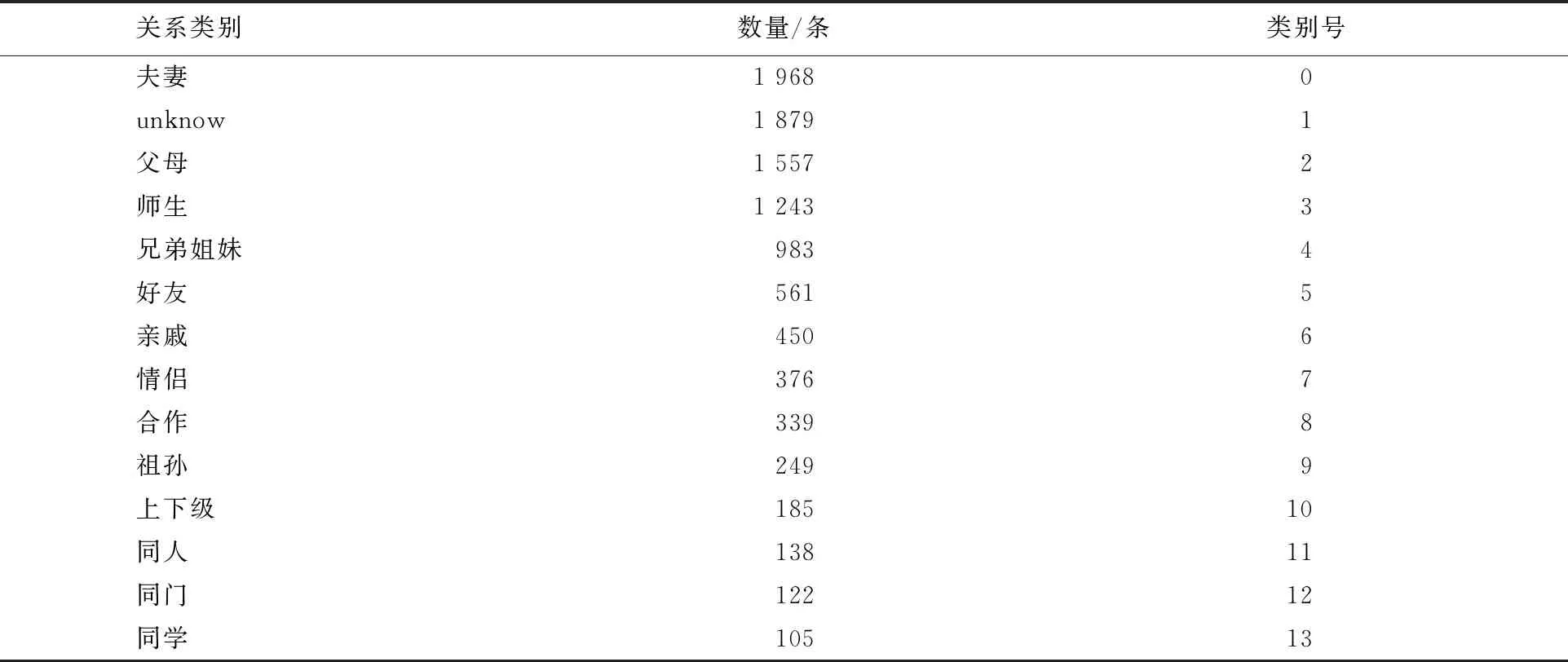
表1 關系類別數量
其中關系類別中“unknow”表示除表中13種關系以外的關系,“同人”表示同一個人不同的名字.

表2 數據示例
實驗參數設置如表3所示.

表3 實驗參數
2.2 實驗方法和評價指標
為了驗證本文提出的模型在中文關系抽取數據集上的效果,以Bert預訓練模型作為基線,分別在Bert預訓練模型下加入雙向門限循環單元網絡與注意力機制的結合、雙向門限循環單元網絡與卷積神經網絡的結合、僅加入雙向門限循環單元網絡、僅加入卷積神經網絡,利用這種模型在同一數據集進行訓練.實驗結果的評價方法采用宏精確率(P宏)、宏召回率(R宏)和F1宏值.公式如下:

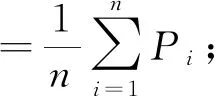
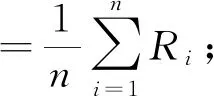
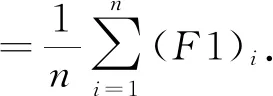
2.3 實驗對比設置
在人物關系抽取實驗中設置了以下幾組對比實驗,包括以Bert作為基線任務的單一的模型和組合的模型的對比:
(1) Baseline:采用Bert預訓練模型作為基線模型.
(2) Bert-BiGRU:在Bert預訓練模型下加入雙向門限循環單元網絡.
(3) Bert-CNN:在Bert預訓練模型下加入卷積神經網絡.
(4) Bert-BiGRU-ATT:在Bert預訓練模型下,加入雙向門限循環單元網絡和注意力機制網絡.
(5) Bert-BiGRU-CNN:在Bert預訓練模型下,加入雙向門限循環單元網絡和卷積神經網絡.
2.4 實驗結果和分析
為了驗證在Bert預訓練模型下加入雙向門限循環單元網絡和卷積神經網絡在人物關系抽取模型上的效果,利用表3設置的參數進行實驗,各個模型的實驗效果對比如表4所示.
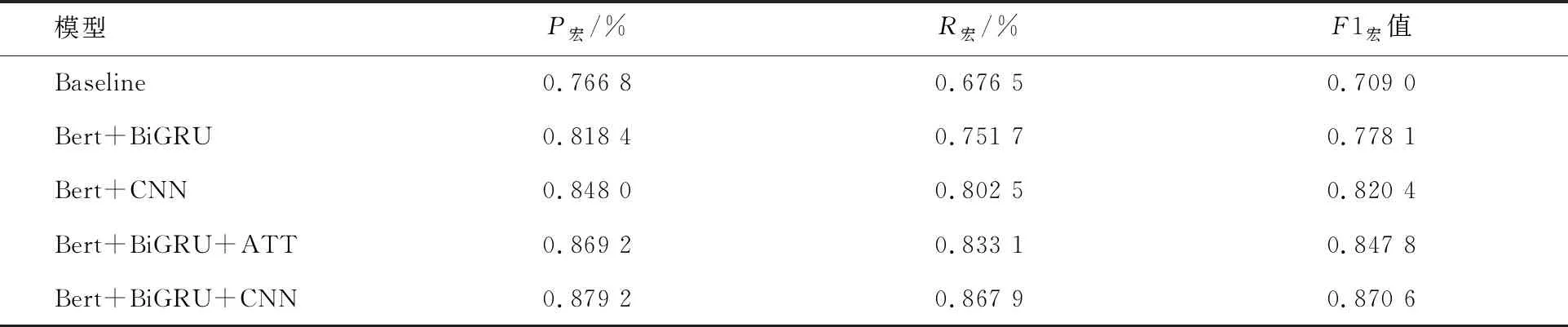
表4 不同模型的實驗對比
通過表4對比發現在以Bert作為基線任務中,P宏為76.68%,R宏為67.65%;在基于Bert預訓練模型的基礎上,僅加入雙向門限循環單元網絡(BiGRU)的模型P宏為81.84%,R宏為75.17%;僅加入卷積神經網絡模型(CNN)的P宏為84.80%,R宏為81.84%;加入雙向門限循環單元和注意力機制的網絡模型P宏為86.92%,R宏為83.31%;加入雙向門限循環單元和卷積神經網絡的模型P宏為87.92%,R宏為86.79%.無論從P宏、R宏還是F1宏值上來看,在Bert預訓練模型下加入雙向門限循環單元網絡與注意力機制的網絡模型要優于僅有雙向門限循環單元網絡的模型和僅加入卷積神經網絡的模型,加入雙向門限循環單元網絡與卷積神經網絡的模型獲得了最高的P宏、R宏和F1宏值.由此可以證明,在Bert預訓練模型下,加入雙向門限循環單元網絡和卷積神經網絡的模型可以進一步提高在人物關系抽取數據集上關系抽取的準確性.
3 結束語
本文通過在Bert預訓練模型下,提出一種將雙向門限循環單元網絡與卷積神經網絡相結合的網絡模型,利用Bert預訓練模型獲取文本的詞向量,采用雙向門限循環單元和卷積神經網絡來提取局部語義特征,實現人物關系的抽取分類.本文提出的Bert-BiGRU-CNN模型在構造的人物關系抽取數據集與其他模型相比取得了最好的實驗效果,但是本文未考慮更細粒度的關系分類,如師生關系中誰是老師,誰是學生.因此下一步的研究是將充分考慮細粒度的人物關系抽取.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
