基于模式匹配的交通微博文本位置信息提取模型
2021-10-18 00:36:56譚永濱,侯夢飛,張志軍,李小龍,程朋根*,章澤之
地理與地理信息科學 2021年5期
譚 永 濱,侯 夢 飛,張 志 軍,李 小 龍,程 朋 根*,章 澤 之
(1.東華理工大學測繪工程學院,江西 南昌330013;2.天津市測繪地理信息研究中心,天津 300381)
0 引言
及時獲取有效的路況信息是實現(xiàn)智能交通服務(wù)的重要前提,其中道路的擁堵情況是路線智能規(guī)劃的重要影響因素。目前道路擁堵信息的采集方式有基于路口傳感器的實時監(jiān)測、結(jié)合手機地圖軟件的浮動車采集等,上述方式雖能較準確分析擁堵信息,但受限于傳感器鋪設(shè)位置、擁堵情況語義不明等原因,無法及時獲取道路突發(fā)擁堵信息。作為當前主流的互聯(lián)網(wǎng)信息分享方式,微博已成為交通信息及時發(fā)布的重要渠道,從中提取路況信息可作為目前采集方式的重要補充[1,2]。位置是道路擁堵信息的重要組成,如何準確有效地從微博文本中提取位置信息是實現(xiàn)路線智能規(guī)劃的基礎(chǔ)之一。
線性參照方法(Linear Reference Methods,LRM)利用與已知點的距離或方向,確定線性要素任意未知點位置[3],是交通事件文本中常用的位置表達方法。LRM包括參照地理實體與空間關(guān)系兩個基本元素,元素間的關(guān)聯(lián)狀態(tài)常用具有指示作用的空間關(guān)系詞描述[4,5],表達模式的定義則隱含于位置文本的句法結(jié)構(gòu)中[6]。其中,地理實體識別及提取方法有利用已有地名庫或詞典的地理命名實體提取方法[7,8]、基于機器學習或規(guī)則庫的參照地名提取方法[9-11]、通過提取隱含的方位關(guān)系[12]或距離關(guān)系[13]進一步提高定位準確性的方法等[14,15]。針對空間關(guān)系的提取方法主要包括基于模式匹配及機器學習兩類算法。前者利用匹配算法識別與待抽取文本相同或相近的位置表達模式,進而抽取文本中蘊含的位置信息[16,17],對于中文文本的空間關(guān)系主要采用受限句法模式識別抽取空間關(guān)系角色[18],在語料標注的基礎(chǔ)上實現(xiàn)空間關(guān)系的形式化表達及抽取[19,20],其對模式變化較小文本的信息提取效率較高,但需提前建立模式庫;后者則利用與空間關(guān)系描述相關(guān)的詞語或語法[21],結(jié)合條件隨機場、支持向量機、隱馬爾可夫模型等算法構(gòu)建分類器,識別不同的空間關(guān)系角色[22],進而提取文本中的空間關(guān)系[23,24],該類方法能有效避開模式匹配算法中位置表達模式缺失的問題,適用于模式多樣的信息提取,但依賴大量已標注的語料庫。
雖然交通微博文本中位置的描述形式多樣,但權(quán)威用戶發(fā)布的交通微博文本主要基于線性參照方法描述位置信息,該描述模式較規(guī)律,如“八一大橋東向西上橋處發(fā)生兩車剮蹭”“目前皇崗路梅隴人行天橋路段南往北方向出現(xiàn)擁堵的情況”等。因此,針對交通信息及時性的實際需求,可采用模式匹配法快速有效地提取微博文本中的位置信息。空間特征詞的角色(定位起點、終止方向等)是文本位置表達模式的重要組成部分,主要指空間特征詞在位置表達模式中的作用。基于上述角色屬性,可將文本位置表達模式的匹配表達為空間特征詞在不同角色間的跳轉(zhuǎn),而有限狀態(tài)機(Finite State Machine,F(xiàn)SM)是解決狀態(tài)(或?qū)ο?跳轉(zhuǎn)問題的模型。因此,本文面向交通領(lǐng)域,基于線性參照方法的特點構(gòu)建文本位置表達模式,并將特征詞角色映射為有限狀態(tài)機中的狀態(tài),利用狀態(tài)轉(zhuǎn)移規(guī)則實現(xiàn)微博文本中位置表達模式快速匹配,據(jù)此提出基于有限狀態(tài)機的位置信息提取模型,以期實現(xiàn)交通微博文本中位置信息結(jié)構(gòu)化。
1 交通微博文本位置信息提取模型
本文構(gòu)建的交通微博文本位置信息提取模型實現(xiàn)流程(圖1)為:1)基于線性參照方法(LRM)的位置表達模式庫構(gòu)建。基于LRM表達的位置信息是微博文本描述交通信息的重要部分。首先分析交通微博文本中位置表達的句法特征,進而基于空間特征詞及其在句法中的角色構(gòu)建位置表達模式,并基于Trie搜索樹結(jié)構(gòu)實現(xiàn)模式的統(tǒng)一形式化表達。2)基于有限狀態(tài)機(FSM)的交通微博文本位置信息提取。將交通微博文本位置轉(zhuǎn)換為空間特征詞及其詞性的文本詞對象集合,同時結(jié)合位置表達模式庫建立與FSM元素的映射,依據(jù)FSM狀態(tài)轉(zhuǎn)移函數(shù)匹配出微博文本中合適的位置表達模式,實現(xiàn)位置信息的快速準確提取。

圖1 交通微博文本中位置信息提取模型流程Fig.1 Flowchart for the model of location information extraction from traffic microblog text
1.1 基于LRM的位置表達模式庫構(gòu)建
(1)LRM位置基本表達形式分析。交通事件中的位置表達通常以交通路網(wǎng)為基礎(chǔ),先以橋梁、道路、路口、POI等點狀與(或)線狀地理實體為參照物實現(xiàn)初步定位,再結(jié)合方位關(guān)系與(或)距離關(guān)系定位至參照物附近的具體點位或路段。本文分析交通微博文本中位置表達的句法特征,基于LRM構(gòu)建微博文本位置信息的基本表達形式(表1)。其中,定位線指各道路或橋梁等線狀地理實體,常作為主參照對象;定位點通常指兩條道路交叉口、某路段起始路口等點狀地理實體,常作為輔助參照對象。
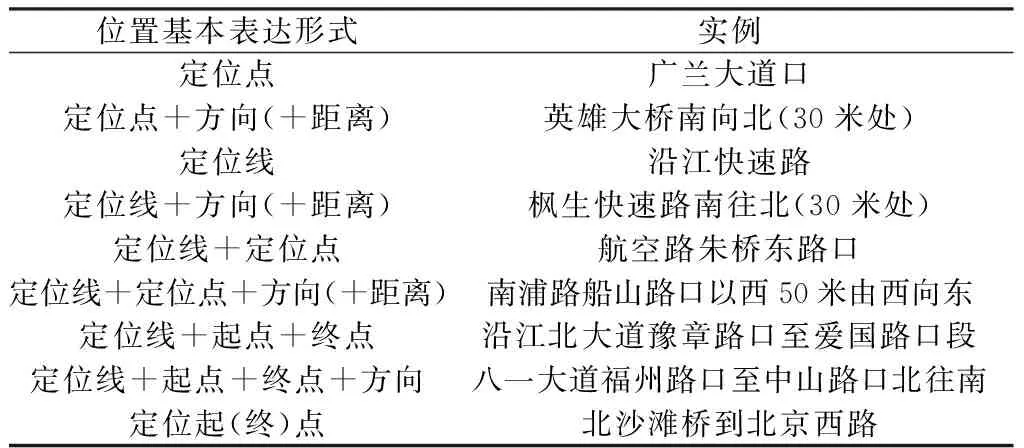
表1 交通微博文本位置信息的基本表達形式Table 1 Basic expression patterns of location information in traffic microblog texts
(2)文本位置表達模式定義。位置表達模式是文本位置信息識別和提取的基礎(chǔ),描述了空間特征詞的詞性及其在位置表達模式中的角色。本文將表達模式定義為由多個空間特征詞對象(e= {pos/role},pos、role分別為空間特征詞的詞性和角色屬性)組成的序列,即LocPattern= {e1,e2,…,en}。除采用語料庫已人工標注的詞性代碼外,本文針對交通微博文本的特征,進一步擴充詞性庫(表2),用于標注路橋名稱詞、附屬定位詞、POI名稱、特殊限定詞等特征詞,并定義文本位置表達中常見的空間特征詞角色屬性(表3),描述不同特征詞在位置表達模式中的作用。

表2 交通文本空間特征詞詞性及代碼Table 2 Part-of-speech and code of spatial words in traffic texts
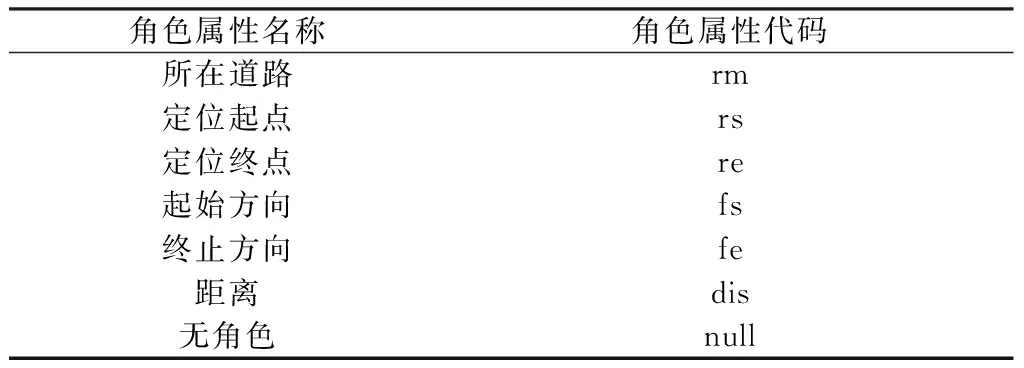
表3 空間特征詞角色屬性Table 3 Role attributes of spatial words
本文以交通微博文本位置的基本表達形式(表1)為基礎(chǔ),結(jié)合空間特征詞之間由介詞等指示詞連接成的實體關(guān)系,建立12種核心位置表達模式(表4)。為避免因表達模式庫不完整導(dǎo)致特征詞提取失敗等問題,本文在各核心模式的空間特征詞對象前后,增加附屬定位詞或特殊限定詞,以擴展位置表達模式庫。例如,在模式“{nsr/rm,f/fs,nsr/rs}”中增加附屬定位詞(ndrs),擴展為“{nsr/rm,ndrs/null,f/fs,nsr/rs,ndrs/null}”,可提取“龍觀快速輔道北行白石山隧道出口”中的“輔道”信息。最終,本文共采用30種位置表達模式提取位置信息。

表4 核心位置表達模式及示例Table 4 Core location expression patterns and examples
(3)基于Trie搜索樹的位置表達模式庫構(gòu)建。通過分析位置表達模式的特征發(fā)現(xiàn),各模式序列的起始部分均存在一定長度的相同序列項。Trie搜索樹是一種用于快速檢索的多叉樹結(jié)構(gòu),其特點是利用樹結(jié)構(gòu)中的公共祖先節(jié)點降低查詢時間開銷,提高效率[25]。本文采用Trie搜索樹結(jié)構(gòu)化位置表達模式,利用各位置表達模式的相同序列項減少查詢時間,提高位置表達模式的匹配效率。針對Trie搜索樹結(jié)構(gòu)的存儲特點,對基于Trie搜索樹的位置表達模式庫構(gòu)建如下約束:1)位置表達模式中的空間特征詞對象表達為Trie搜索樹中的節(jié)點,每個節(jié)點包含特征詞詞性pos和角色屬性role;2)位置表達模式庫結(jié)構(gòu)僅有一個不包含任何值的根節(jié)點(root);3)各位置表達模式的相同特征詞只存儲一次;4)位置表達模式對應(yīng)自root節(jié)點向下跳轉(zhuǎn)的路徑,即ei+1為ei的子節(jié)點,模式末位特征詞的節(jié)點標記為終止節(jié)點。圖2為基于Trie搜索樹結(jié)構(gòu)的核心位置表達模式庫,其中每個深色節(jié)點均代表一個位置表達模式的終止節(jié)點,其可能是其他模式的中間節(jié)點;root節(jié)點與每個終止節(jié)點間的路徑均對應(yīng)一個位置表達模式。如模式{nsr/rm,nsr/rs,f/fs,p/null,f/fe}可表示為圖中粗箭頭形成的路徑,其中節(jié)點{nsr/rs}既是該模式的中間節(jié)點,又是模式{nsr/rm,nsr/rs}的終止節(jié)點。

圖2 基于Trie搜索樹表達的核心位置表達模式庫Fig.2 Trie tree structure of core location expression patterns
1.2 基于FSM的交通微博文本位置信息提取
(1)位置表達模式庫與FSM元素映射。FSM是用于描述有限個狀態(tài)及各狀態(tài)之間轉(zhuǎn)移和動作等行為的數(shù)學模型[26],其五元組結(jié)構(gòu)表達為M={V,S,s0,σ,F}。將位置表達模式庫的Trie搜索樹結(jié)構(gòu)表達為FSM模型,二者的映射關(guān)系如表5所示。其中空間特征詞對象的角色屬性映射為FSM中的狀態(tài),詞性作為觸發(fā)狀態(tài)轉(zhuǎn)移的關(guān)鍵詞;依據(jù)各樹節(jié)點的先后順序,將Trie搜索樹結(jié)構(gòu)表達為空間特征詞轉(zhuǎn)移規(guī)則表,即狀態(tài)轉(zhuǎn)移規(guī)則表(部分示例見表6),表中每行的規(guī)則表示當前狀態(tài)(角色)在遇到不同詞性的特征詞對象時,可能發(fā)生的幾種狀態(tài)轉(zhuǎn)移(角色關(guān)聯(lián))情況,包括下一狀態(tài)、不可跳轉(zhuǎn)等;狀態(tài)轉(zhuǎn)移函數(shù)sj=T(si,pos)是利用狀態(tài)轉(zhuǎn)移規(guī)則實現(xiàn)狀態(tài)間的跳轉(zhuǎn),即假定當前狀態(tài)為si,若遇到詞性為pos的文本詞對象,則會觸發(fā)從當前狀態(tài)si跳轉(zhuǎn)到sj。

表5 FSM五元組元素與位置表達模式庫的映射關(guān)系Table 5 Mapping between elements of FSM and location expression patterns
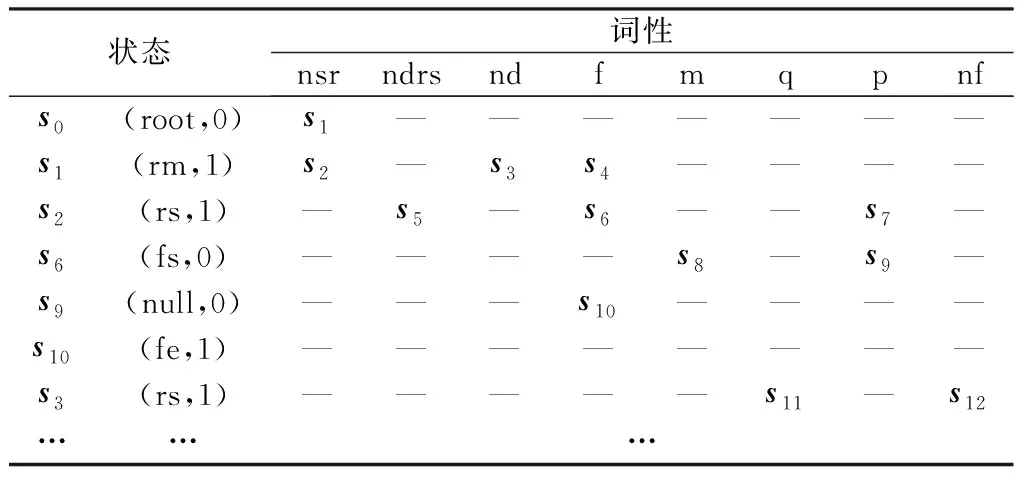
表6 空間特征詞轉(zhuǎn)移規(guī)則示例Table 6 Some examples of transfer rules among spatial words
(2)微博文本中位置信息提取。經(jīng)過預(yù)處理后,先將微博文本轉(zhuǎn)換為包含詞語及其詞性的文本詞對象序列V。位置表達模型的匹配算法是實現(xiàn)位置信息提取的核心部分,該匹配算法(圖3)基于文本詞對象的詞性,利用狀態(tài)轉(zhuǎn)移函數(shù)提取狀態(tài)轉(zhuǎn)移路徑,匹配出與微博文本合適的位置表達模式,并建立與文本詞對象序列對應(yīng)的角色屬性序列,最終實現(xiàn)微博文本位置信息提取。基本步驟包括:1)建立狀態(tài)堆棧SA及狀態(tài)—詞關(guān)系映射S-V。根據(jù)狀態(tài)轉(zhuǎn)移函數(shù),判斷在當前狀態(tài)sc下,文本詞對象vi的詞性posi是否能觸發(fā)狀態(tài)的跳轉(zhuǎn),如果可跳轉(zhuǎn),則將sc跳轉(zhuǎn)到下一狀態(tài)snext,同時記錄snext至狀態(tài)堆棧SA以及vi與狀態(tài)snext的映射關(guān)系表S-V中,若記錄的是第一個狀態(tài)則定義為ss,接著重復(fù)步驟1),處理下一個文本詞對象vi+1;若不可跳轉(zhuǎn),則執(zhí)行步驟2)。2)構(gòu)建候選位置模式集合PA。判斷已記錄的狀態(tài)堆棧SA中是否存在終止狀態(tài),若存在則將該終止狀態(tài)定義為se,并建立ss與se間的“狀態(tài)轉(zhuǎn)移路徑”,作為候選位置模式存儲在PA中;否則重置當前狀態(tài)sc為初始狀態(tài)s0,處理下一個文本詞對象vi+1。3)結(jié)構(gòu)化位置信息提取。當所有文本詞對象遍歷完成后,選擇PA中序列最長的候選位置模式,并基于狀態(tài)—詞關(guān)系映射S-V提取該序列中每個狀態(tài)對應(yīng)的詞語,完成微博文本的位置信息提取。
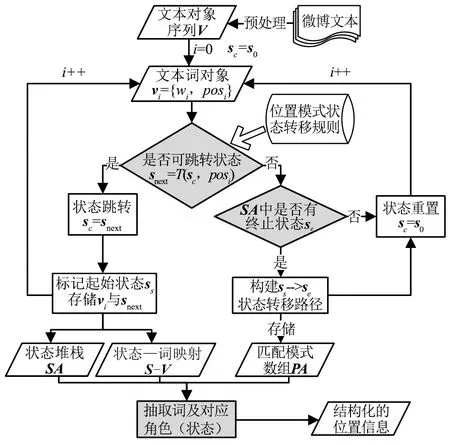
圖3 基于FSM的位置信息提取算法流程Fig.3 Flowchart of location information extraction based on FSM
2 模型評價與分析
2.1 實驗數(shù)據(jù)及預(yù)處理
本文利用Python自動爬取新浪微博文本,構(gòu)建實驗數(shù)據(jù)集,利用Java設(shè)計工具提取微博文本位置信息,位置表達模式存儲于MySql數(shù)據(jù)庫中;實驗硬件環(huán)境為Windows 10操作系統(tǒng),處理器為雙核Intel(R) Core(TM) i5-4210M CPU @ 2.60 Hz,內(nèi)存為8 G。
實驗爬取了“南昌路況信息”“廣州實時路況”“深圳路況播報”為主題的共10 162條微博文本,利用正則表達式清理表達情感的表情符號(如“[怒]、[開心]”等);去除夾雜英文字母表示的詞語簡寫、微博賬戶名、過短微博等;結(jié)合分隔符號(句號或分號)將同時描述多個交通事件的微博文本拆分為多個單一事件的短文本;基于城市POI數(shù)據(jù)擴展地名詞典,以提高交通位置信息中空間特征詞的分詞及詞性標注的準確度,最終共提取有效微博文本9 799條。最后,利用自然語言處理工具HanLP(https://github.com/hankcs/HanLP/tree/1.x)對微博文本進行分詞及詞性標注,并人工標注出微博文本中包含的位置信息,作為實驗結(jié)果的驗證數(shù)據(jù)。
2.2 位置信息提取實例
以微博文本“在北環(huán)大道龍珠立交西往東方向發(fā)生擁堵”的位置信息提取為例,闡述其位置模式匹配及角色提取的全過程(圖4)。1)首先對微博文本進行預(yù)處理,獲得文本對象序列V={“在”“北環(huán)大道”“龍珠立交”“西”“往”“東”“方向”“發(fā)生”“擁堵”};2)遍歷所有文本對象,以表6中的狀態(tài)轉(zhuǎn)移規(guī)則為基礎(chǔ),實現(xiàn)文本對象驅(qū)動的狀態(tài)(角色)跳轉(zhuǎn),在每次跳轉(zhuǎn)后記錄狀態(tài)(SA)及其與詞語間關(guān)聯(lián)(S-V),并基于SA構(gòu)建候選匹配模式集合(PA);3)遍歷結(jié)束后,結(jié)合PA與S-V得到各文本對象的角色屬性;4)從微博文本“在北環(huán)大道龍珠立交西往東方向發(fā)生擁堵”中提取出北環(huán)大道(所在道路)、龍珠立交(定位起點)、西(起始方向)、東(終止方向)等位置信息。
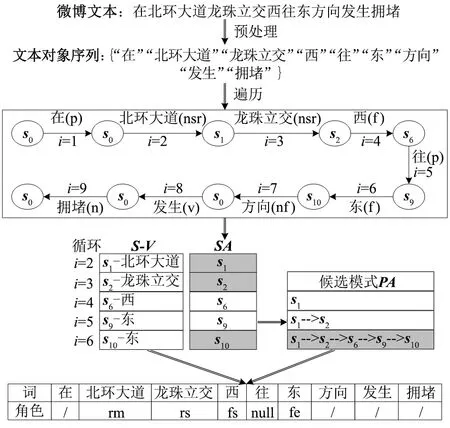
圖4 文本實例中位置信息提取過程Fig.4 Example of location information extraction from traffic microblog text
2.3 模型精度評價
(1)位置提取精度評價。本文從9 799條微博文本中提取出16 966個位置。通過比對人工標注檢查結(jié)果,發(fā)現(xiàn)正確識別位置15 177個,錯誤識別位置1 789個,未能識別位置2 294個,處理時長約7.53 s。部分微博文本及提取的位置信息如表7所示,可以看出,提取結(jié)果較準確地描述了交通事件的發(fā)生位置,包括參照物、起點、終點、起始方向、終止方向與距離等信息,而且總體提取耗時較短,效率較高。通過分析提取結(jié)果發(fā)現(xiàn),大部分錯誤及未能識別位置的微博文本主要采用單一的“所在道路”或“POI”位置表達模式,此類模式可利用信息較少,極易因未登錄地名、道路名或POI名簡(縮)寫等而產(chǎn)生錯誤提取或無法識別,如微博文本“南海大道深大門口路段北往南方向”中“深大門口”的縮寫地名無法被正確提取而產(chǎn)生識別錯誤。此外,少部分微博文本由于參照物或附屬定位詞切分或識別失敗,造成這些道路或POI無法被準確識別,進而導(dǎo)致其位置表達模式無法與模式庫中的相匹配,致使信息提取失敗或提取不完整等。例如“公常路圳美江嚇路段往東莞方向”中的“圳美江嚇路段”,因語句錯誤切分而導(dǎo)致識別錯誤。

表7 交通微博示例數(shù)據(jù)及位置信息提取結(jié)果Table 7 Examples of traffic microblog text and its location information extraction results
本文利用準確率、召回率與F1值對模型的提取精度進行定量評價(圖5),可以看出,南昌與廣州的路況微博文本中位置提取效果較好,準確率均在90%左右,深圳的提取效果略差(約為83%),總體結(jié)果準確率和召回率都達85%以上。通過對比發(fā)現(xiàn),南昌與廣州的微博文本中位置表達相對直接,描述交通事件的干擾信息較少,因此位置信息提取效果較好;而深圳路況微博文本中存在簡寫地名或地名庫中不存在的小地名等情況,導(dǎo)致部分地名匹配失敗,影響模式匹配結(jié)果,提取效果較差。
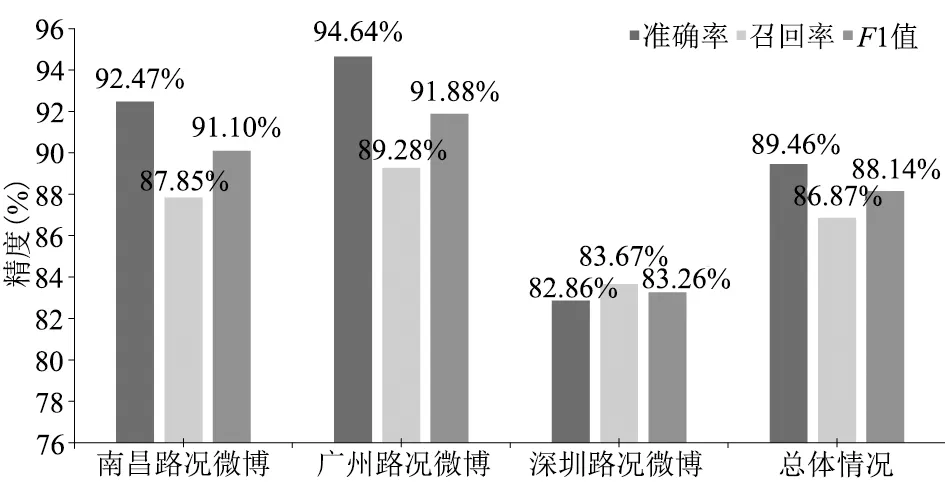
圖5 位置元素提取結(jié)果評價Fig.5 Evaluation of location element extraction results
(2)位置表達模式統(tǒng)計分析。為分析交通事件文本位置表達模式的分布情況,本文統(tǒng)計所有正確提取位置信息的表達模式,累計數(shù)量排名前10的位置表達模式如表8所示。1)按表達模式統(tǒng)計發(fā)現(xiàn),交通事件的文本位置表達多采用“參照位置(道路或POI)+空間關(guān)系”的模式(占比約50%),包括只有起始方向、起始與終止方向等情況,此類模式能更準確地描述位置;其次結(jié)合POI的位置表達模式約占38%,包括POI、POI+方向組合等,此類模式利用人們對POI位置的初步印象可實現(xiàn)快速的粗略定位。2)按不同城市統(tǒng)計發(fā)現(xiàn),由于各城市發(fā)布的微博數(shù)量、重點交通事件類型等方面的差異較大,各城市主要采用的位置表達模式也有較大不同。南昌發(fā)布的交通微博多采用“所在道路”模式(約占54%),廣州多采用“所在道路+POI+方向”模式(約占54%),深圳則多采用“所在道路+路段+方向”模式(約占41%)。
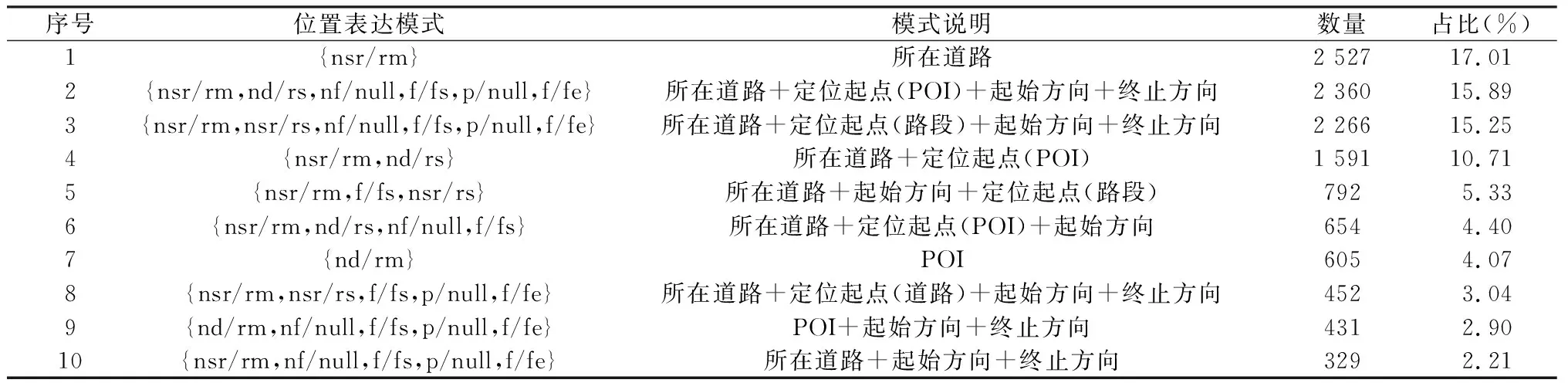
表8 累計數(shù)量排名前10位的位置表達模式Table 8 Location expression patterns of top 10 in cumulative quantity
3 結(jié)語
快速提取有效的位置信息是實現(xiàn)文本位置空間化的基礎(chǔ)。本文以交通微博文本為對象,提出一種基于有限狀態(tài)機的位置信息識別與提取模型。該模型基于線性參照方法構(gòu)建位置表達模式庫,并將模式庫表達為Trie搜索樹,利用有限狀態(tài)機匹配微博文本中位置表達模式,識別并提取微博文本中的位置信息,最后以南昌、廣州與深圳的微博文本為實驗數(shù)據(jù)進行模型驗證。結(jié)果表明,該模型能有效識別并提取微博文本中的位置信息,綜合準確率達89.46%,召回率達86.87%;通過分析錯誤提取結(jié)果,發(fā)現(xiàn)未登錄地名與模式不確定性是造成識別錯誤的主要原因。未來將主動吸收和識別外部開放地名詞典或句法知識等,嘗試結(jié)合語義分析方法,加強對位置表達中各要素及其空間關(guān)系等語義的理解,提高分詞和詞性標注的效果,進而提高位置信息提取的準確性。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32

- 地理與地理信息科學的其它文章
- 省際入境與國內(nèi)旅游流網(wǎng)絡(luò)結(jié)構(gòu)特征及比較分析
- 長江經(jīng)濟帶旅游產(chǎn)業(yè)—區(qū)域經(jīng)濟—生態(tài)環(huán)境系統(tǒng)空間錯位及影響因素研究
- 環(huán)渤海地區(qū)包容性綠色增長效率的空間關(guān)聯(lián)網(wǎng)絡(luò)結(jié)構(gòu)及其影響因素
- 供給側(cè)改革視角下京津冀工業(yè)能源強度及其影響因素研究
- 中國環(huán)境犯罪的空間分布特征與機制
- 跨江發(fā)展下濱江新區(qū)用地擴展過程與驅(qū)動機制
——以南昌紅谷灘新區(qū)為例