基于社交網絡信息的用戶抑郁癥傾向識別
2021-10-21 03:46:34劉定平張雪燕
統計理論與實踐 2021年9期
關鍵詞:用戶
劉定平 張雪燕
(河南財經政法大學統計與大數據學院,河南鄭州450046)
一、引言
抑郁癥是常見疾病,由此產生的心理障礙會對人體產生較大影響,輕癥者會減弱對學習和工作的興趣,導致學習能力和工作效率降低;重癥者可能會喪失生活的動力,甚至萌生自殘、自殺念頭。根據世界衛生組織2019年底發布的報告,抑郁癥的發病率僅次于世界第一大嚴重的缺血性心臟病,在世界排名前十位的使人喪失勞動能力的疾病中,抑郁癥甚至名列首位,這無疑成為社會安定的巨大隱患。截至目前,全球已有超過2.64億抑郁癥患者,每年自殺身亡者高達80萬人。其中,中國的抑郁癥患者達9000萬,占比超過全球抑郁癥患者總數的34%。由于抑郁癥患者的病恥感以及大眾對抑郁癥的污名化,使這種敏感性疾病的識別率僅為21%,在僅有的已識別的患者中,主動接受干預和治療者更是少之又少。這是抑郁癥診療和研究面臨的主要障礙,也是當前亟待解決的問題。
隨著社交網絡的迅速發展,在社交平臺上分享情緒逐漸成為年輕人熱衷的新潮流,其中不乏大量的抑郁癥患者。作為深受國民喜愛的微博社交平臺,是大量用戶發表言論和與人互動的場所,微博平臺每天都充斥著豐富的信息動態,深入挖掘抑郁用戶在微博平臺的網絡軌跡,無疑為抑郁癥的識別提供了新的思路。
二、文獻綜述
對于抑郁癥的檢測,最直接的方式莫過于早期的心理量表測評,劉芳宜(2012)等將漢密爾抑郁量表、Zung抑郁自評量表以及羅馬心理社會警報問卷三種心理測評量表應用于受試者的問卷調查,根據受試者對問題的回答情況判定其抑郁與否。
此外,也有相當一部分學者從生物學角度出發,通過抑郁癥患者的腦網絡信號(沈瀟童,2020)、面部動態特征(安昳,2020)以及眼部動態特征(袁一方,2020)提取相關信息,構建抑郁癥識別分類模型。上述方式對于主動參與抑郁癥檢測的患者群體固然有效,但面對龐大的畏于主動就醫的抑郁癥傾向群體卻顯不足。國外學者首先提出通過社交網絡媒介進行抑郁癥傾向識別,William(2015)以抑郁癥患者的Twitter文本為數據集,通過建立主題模型對抑郁癥患者和非抑郁癥患者的語言信號進行分析。目前國內的研究多基于社交網絡平臺微博的數據,Li Genghao(2020)提出一種構建抑郁癥領域詞匯的有效方法,該詞匯包含豐富的語言特征,可以幫助識別潛在患有抑郁癥的社交媒體用戶。方振宇(2017)基于微博用戶的文本信息,采用基于擴展的抑郁詞典的特征統計法以及基于詞向量構建用戶向量的方法,通過深度學習工具word2vec訓練對抑郁用戶和非抑郁用戶進行識別。
觀察發現,學者對社交網絡用戶的抑郁癥識別大多立足于用戶的語言特征,通過文本挖掘技術進行情感分析,進而達到分類目的。然而用戶的個人信息以及與他人互動的相關特征似乎被學者忽略,本文通過抑郁癥患者在微博平臺的多方面表現,對抑郁癥患者進行表征提取,確定特征向量后,從構建抑郁指標體系和統計識別模型兩個角度出發,開展社交網絡用戶抑郁癥傾向識別研究。
三、抑郁癥的表征
(一)數據獲取
本文數據均基于微博爬蟲技術,通過提取用戶相關信息,建立抑郁用戶與非抑郁用戶數據集。微博平臺為有共同興趣的人提供一個交流的社區并命名為“××超話”,本案例測試集中抑郁用戶的選取將從“抑郁癥超話”社區入手(見圖1),該社區設立初衷是探討抑郁癥的預防以及為抑郁癥患者提供治療過程的分享平臺,越來越多有抑郁傾向用戶將該社區當作樹洞宣泄自己的情緒。超話建立至今,擁有27.2萬粉絲,發帖量達65.7萬,閱讀量超23.7億,足見抑郁癥群體的龐大。

圖1 新浪微博抑郁癥超話社區
通過對該社區帖子的爬取,初步獲取抑郁用戶的ID、性別、年齡、所在地、關注數以及粉絲數等基本信息。通過數據預處理,剔除性別、年齡及所在地有缺失的用戶,最終定位到50名抑郁用戶。由于抑郁癥為長期存在的疾病,因此在對抑郁用戶的微博內容進行抓取時將時間設定為1年,起止時間為2020年1月1日至2021年1月1日。對于非抑郁用戶的選取,則采取在搜索欄里輸入積極情感詞匯的方式進行定位。為與抑郁用戶的數據集進行匹配,非抑郁用戶同樣進行篩選后定位到50名,并對其相應時段的微博文本進行抓取。
(二)特征提取
1.抑郁用戶畫像分析
(1)個人信息
微博用戶的資料欄包括個人基本信息、聯系信息、職業信息、教育信息以及標簽信息,結合數據的完整性和有效性,本文選定基本信息中的性別、年齡、所在地3個指標作為研究對象,其中年齡指標由資料欄中的生日信息推算求得。獲取到相關數據后,針對抑郁用戶、非抑郁用戶在上述指標的表現差異進行對比分析。
性別特征。分別計算男性、女性用戶中有抑郁傾向和無抑郁傾向的比例得到圖2所示結果,直觀看,女性群體中有抑郁傾向用戶占比高達61.54%,男性用戶中有抑郁傾向的僅占28.57%,這一特點與流行病學相關研究結論一致。流行病學研究表明,女性抑郁癥患病率通常是男性的兩倍,究其原因,除了性別差異帶來的大腦功能差異外,生理原因是女性更容易得抑郁癥的重要因素。與男性相比,女性更容易產生敏感和不穩定情緒,因此在遇到挫折時受到的影響更大,進而容易引發抑郁。
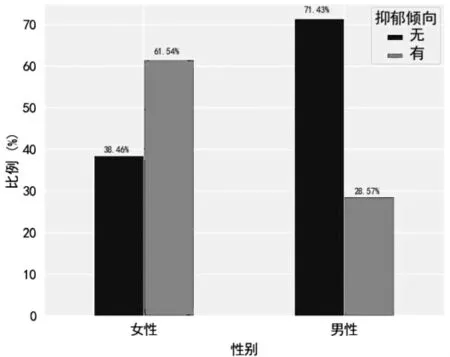
圖2 抑郁癥傾向的性別差異
年齡特征。觀察抑郁用戶的年齡分布圖(見圖3)可以發現,抑郁用戶的年齡近似服從正態分布,并集中在20歲左右的大學生群體,最低年齡為15歲,發病呈顯著低齡化。研究表明,大學生群體面臨的來自同齡人的競爭更為激烈,這同時給他們帶來多方面的壓力。據《2020中國大學生健康調查報告》顯示,將近90%的大學生在最近一年內產生過心里困擾,產生誘因比例計算如表1。

圖3 抑郁用戶年齡分布圖

表1 大學生心理困擾誘因
由表1可知,大學生的心理困擾包括學業、人際關系和工作規劃,其中學業壓力是最令大學生不安的因素。學業成績是衡量學生優秀與否的重要指標,因此落后的恐懼心理時常縈繞;其次是人際關系和性格問題,大學時期的人際交往比以前更為復雜。除與同學交往外,還有來自社團和學生工作的老師,如何正確處理這些關系是大學生需要思考的問題。倘若這些困擾和焦慮不能得到及時排解,勢必導致大學生長期處于負性情緒之下,增加患抑郁癥的概率。
地區特征。抑郁用戶在我國東南部地區的分布較為突出,尤其是廣東省、上海市、山東省和浙江省,中部地區次之,西北、西南和東北部地區幾乎沒有涵蓋入內。這與我國經濟發展的空間分布特征極為相似,經濟高速發展的地域生活節奏較快,高壓強迫下的群體易擁有持續緊繃的狀態,出現錯誤導致的打擊也隨之嚴重放大,引發患病。
(2)與人交往
作為社交工具的微博平臺給用戶提供了多種溝通交流方式,用戶可以關注自己感興趣的博主,點贊、評論和轉發喜歡的微博內容,同時粉絲數也會隨著活躍度的提高而增加。為考察抑郁用戶與非抑郁用戶在與人溝通交往方面的差異,對爬取的用戶微博進行獲贊數、轉發數和評論數統計,同時記錄用戶的微博關注數和粉絲數,得到表2所示結果。
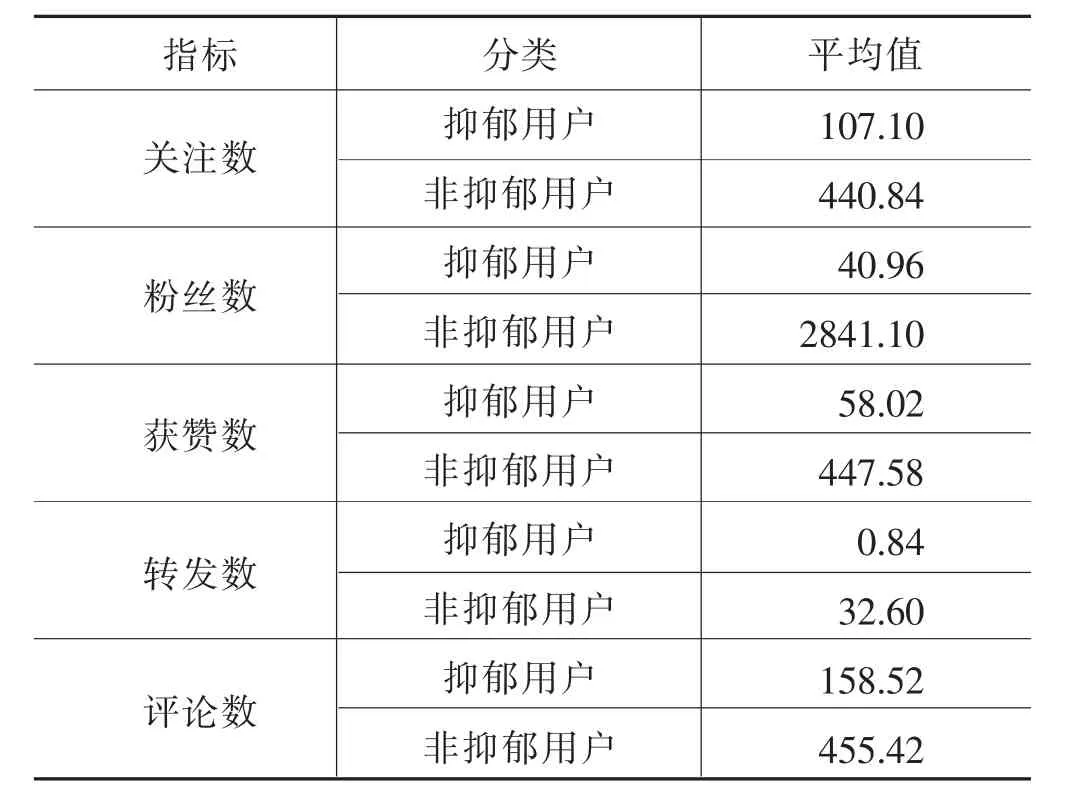
表2 抑郁用戶與非抑郁用戶與人交往方面的差異
通過抑郁用戶和非抑郁用戶在關注數、粉絲數、獲贊數、轉發數和評論數的對比數據,可以清楚感知到抑郁用戶在與人交往方面存在的缺失。很多抑郁癥患者習慣于把自己的感受放在內心世界,不愿抽離出自己營造的幻想,躲在自認為的保護圈中難以自拔。當他們過多關注自身的情緒卻不愿與人傾訴排解時,勢必會引起一些不必要的負性思維。
2.抑郁用戶微博內容信息提取
(1)發博時間
整理爬取的抑郁用戶微博時發現,許多用戶發博時間為凌晨12點之后,將抑郁用戶和非抑郁用戶的發博時間匯總成圖4所示的折線圖,對比二者一天內發博頻率可知,抑郁用戶在0:00-6:00為發博活躍度較高的時段,第二個小高峰在18:00-24:00,相比之下非抑郁用戶的活躍時段多集中在18:00-24:00,在0:00-6:00幾乎沒有分布。結合抑郁癥患者的相關癥狀不難理解,抑郁癥患者典型癥狀之一為失眠,多方面壓力導致的焦慮使患者產生睡眠障礙,加之不愿與人溝通交往,抑郁情緒難以排解,只能把社交平臺當作樹洞加以宣泄。因此,統計0:00-6:00之間微博用戶的發博率是區分抑郁用戶和非抑郁用戶的重要指標。
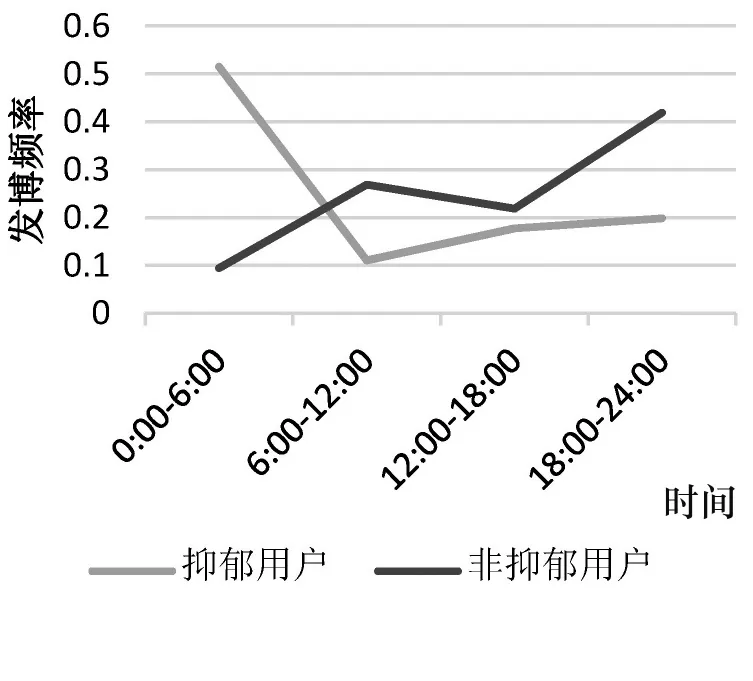
圖4 抑郁用戶與非抑郁用戶發博時間差異
(2)微博文本

圖5 抑郁用戶詞云圖

圖6 非抑郁用戶詞云圖
對比抑郁用戶和非抑郁用戶微博內容詞云圖,初步發現抑郁用戶微博關鍵詞多為言辭偏激的負性詞匯,包括“抑郁癥”“失眠”“好累”“想死”等,除此之外,一些第一人稱表述詞如“我”“自己”也有較高的詞頻,這與抑郁癥患者對自身關注度較高有著密不可分的聯系。非抑郁用戶的關鍵詞詞性多為中性或積極情感詞,極少數為消極情緒詞。因此通過計算用戶微博內容中具有區分性的詞匯的頻率,以期找出判斷抑郁與否的重要指標。
關鍵種子詞提取。種子詞是可以代表特定領域的詞。為了在抑郁和非抑郁數據集中提取關鍵種子詞,我們利用了算法,這是一種廣泛應用于自然語言處理的特征提取算法。它的基本思想是,如果某個詞在一篇文檔中出現的頻率高,并且在語料庫中其他文檔中很少出現,則認為這個詞具有很好的類別區分能力。Salton和Yu首先提出了算法,Salton等證明了該算法在信息檢索中的有效性。詞頻(Termfrequency,TF)是指一個字或詞在一個文檔中出現的次數,而逆文檔頻率(inverse document frequency,IDF)是指一個詞在所有文檔中出現的頻率,衡量的是該詞在整個語料庫中的特異性。
TF和IDF的計算公式如下:

其中ni,j是文檔 j中詞匯i的數目,k是文檔j中的詞匯數,D是文檔的大小,DF(i)是出現過詞匯i的文檔數。TF-IDF計算公式如下:

直觀來看,TF-IDF的計算表達的含義是一個給定的詞在語料庫中的重要性和特殊性,TF-IDF值越高,對某一特殊領域的代表性越強。分別從某抑郁用戶與某非抑郁用戶的微博內容中計算出的TF-IDF值如表3、表4所示。

表3 某抑郁用戶關鍵詞詞頻
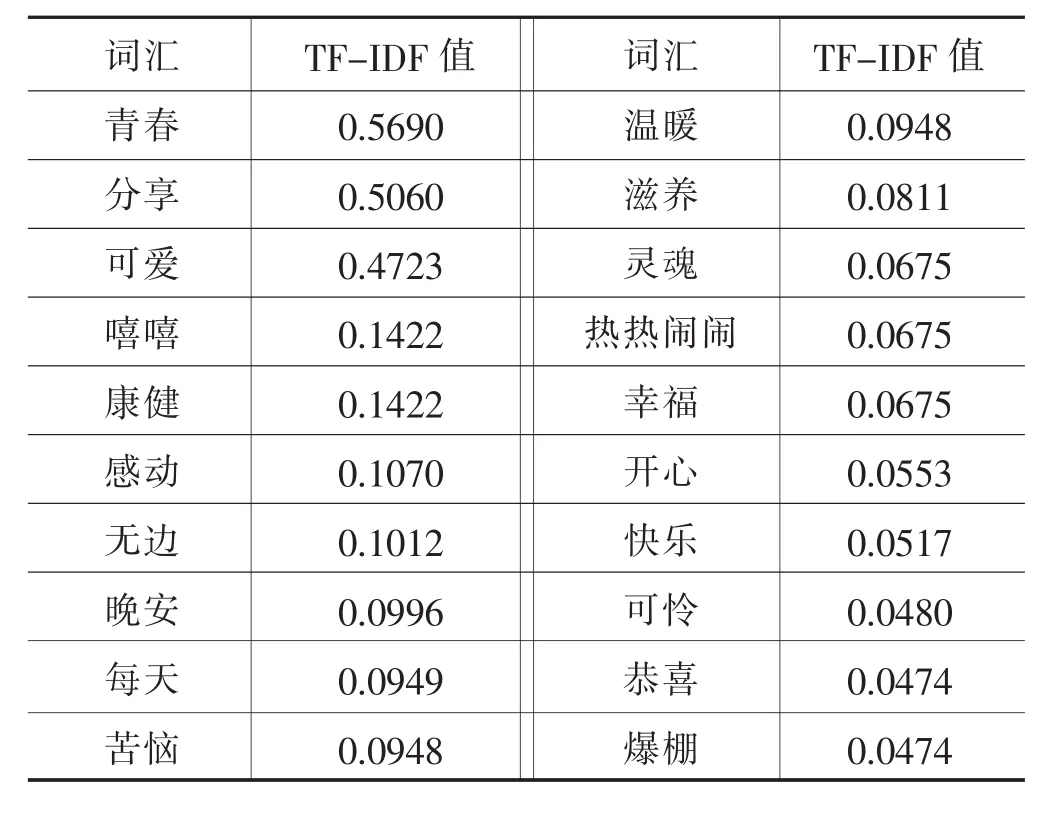
表4 某非抑郁用戶關鍵詞詞頻
指標提煉。通過對抑郁用戶和非抑郁用戶微博文本的信息提取,發現抑郁用戶在第一人稱詞匯的使用上較為頻繁,因此將文本中出現頻率較高的“我”與“自己”兩個關鍵詞的詞頻進行加總,作為“第一人稱使用頻率”指標用于下文的分類特征。針對抑郁用戶文本中負性詞匯較多這一特性,傳統的只含有正向情感詞和負向情感詞的情感詞典難以將抑郁用戶與非抑郁用戶區分開來,因此本文選用對外經貿大學與美國紐約哥倫比亞大學聯合實驗項目建立的抑郁詞典作為匹配基準,將用戶微博文本中出現頻率最高的前20個抑郁詞匯的詞頻進行加總,作為“抑郁詞匯使用頻率”這一特征變量。
四、抑郁癥的識別
(一)分類模型指標確立
通過對抑郁用戶與非抑郁用戶在社交網絡上的不同表現,對抑郁用戶的識別有了初步的認知,而對抑郁用戶與非抑郁用戶在個人信息、與人交往以及微博內容3個方面的信息進行提取和分析后,得到表5所示的11個特征變量,其中“所在地”屬于分類型變量,若與性別做相同的啞變量處理,會增加特征變量矩陣的稀疏性,因此用所在地2020年GDP數據代替“所在地”指標下的分類數據,將其轉化成數值型變量納入統計識別模型。本文在對微博用戶進行抑郁癥傾向識別過程中擬從統計指標體系法和機器學習法兩種思路展開。

表5 特征變量篩選
(二)分類模型方法選擇
1.指標體系法
指標體系法將與研究對象密切相關的指標納入綜合評價,計算綜合指數設定閾值,對目標變量進行劃分。本文選用Topsis距離綜合評價法對社交網絡用戶抑郁癥傾向指數進行測算,其基本原理是通過檢測評價對象與正負理想解之間的加權歐式距離,得出評價對象與正理想解的接近程度,以此作為各評價對象優劣的依據,若評價對象最靠近正理想解同時又最遠離負理想解,則為最優。其中正理想解是一種設想的最好解,其各指標值都達到各評價指標的最優值。負理想解是一種設想的最壞解,其各指標值都達到各評價指標的最差值。在對微博用戶抑郁傾向值進行測算時,通過建立指標體系對各指標數據進行處理,確定指標權重后計算抑郁癥傾向指數,進而對抑郁用戶和非抑郁用戶進行區分。實施過程如下:
為排除各評價指標之間因數量級和量綱的不一致性所帶來的影響,首先需要對指標數值進行標準化處理得到x'ij,通過熵權法計算出各指標權重wj后構建加權矩陣:

通過各指標權重計算(表6)可以發現,與人交往方面的指標對抑郁癥用戶影響最為顯著,社交平臺本就是用戶溝通交流的重要渠道,時常使用社交平臺但鮮有互動信息的用戶顯然值得關注。此外,個人信息方面的指標對抑郁癥用戶的影響效果高于微博內容,表明在抑郁癥識別模型中僅考慮微博用戶的文本信息遠遠不夠,需加入個人信息以及與人交往環節的相關指標綜合考量。

表6 特征變量權重計算結果
最終測算出的用戶抑郁癥傾向值如表7所示。觀察抑郁傾向值計算結果可以發現,抑郁用戶的傾向值大多高于0.3,非抑郁用戶的傾向值大多低于0.3,因此猜測閾值集中在0.3附近。
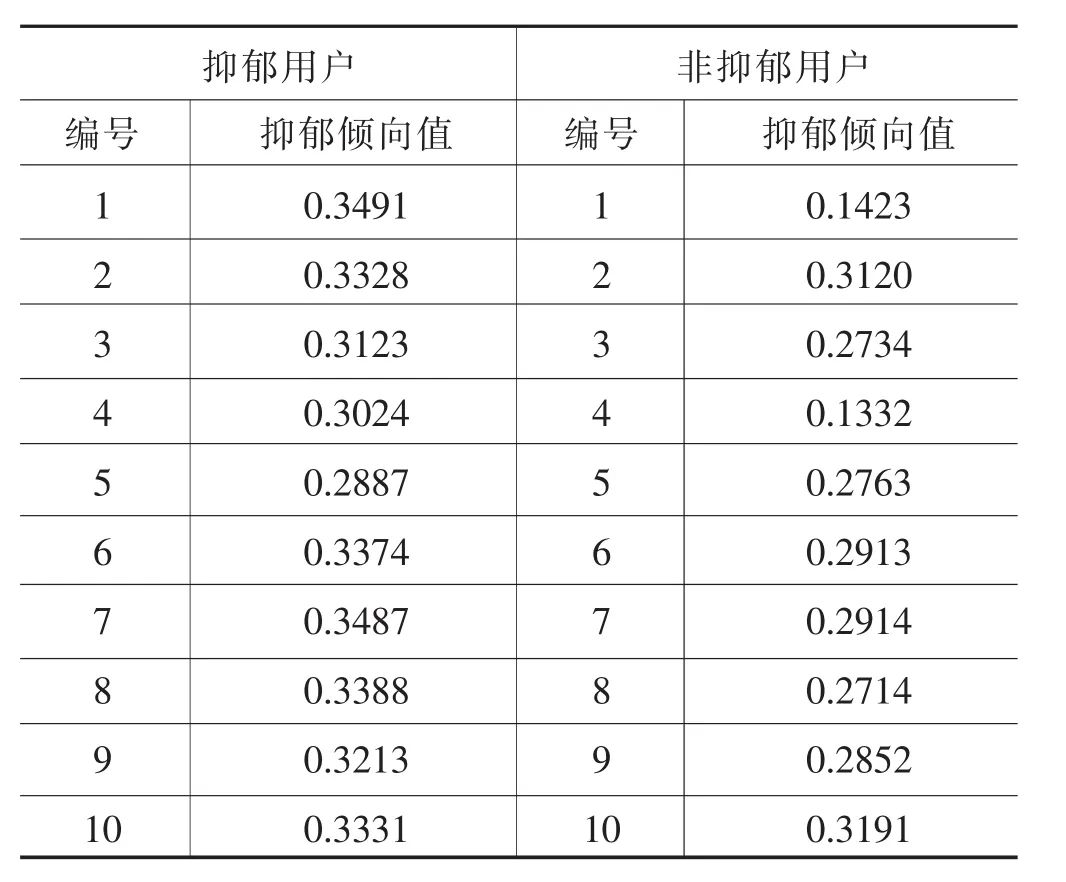
表7 部分抑郁用戶與非抑郁用戶抑郁癥傾向值測算結果
分別選取閾值為0.2、0.3和0.4進行準確率測度。這里準確率的計算公式為:

其中TP為將正類預測為正類數,TN為將負類預測為負類數,FP為將負類預測為正類數,FN為將正類預測為負類數。因此準確率的測度同時包括正確預測為抑郁用戶和正確預測為非抑郁用戶的概率。通過對不同閾值的設定發現,當閾值設置為0.3時,預測準確率最高,因此將其作為抑郁用戶和非抑郁用戶的傾向值分水嶺,若抑郁傾向值高于0.3,則認為該用戶具有抑郁癥傾向,若抑郁傾向值低于0.3,則認為該用戶不具有抑郁癥傾向。

表8 不同閾值下準確率測算
2.機器學習分類法
運用機器學習法建立分類器對抑郁用戶進行識別時,初步擬采用單個學習器分類,分別是K近鄰、支持向量機、樸素貝葉斯和決策樹算法,通過觀察準確率的表現可以發現,樸素貝葉斯分類器相較其余三個分類器效果較好,但準確率相較距離綜合評價法略顯不足,為了提高分類器算法性能,采用集成學習的方式繼續研究。
集成學習通過建立多個學習器來完成學習任務,以期達到“博采眾長”的效果。當許多弱學習器被正確組合時,能得到更精確、魯棒性更好的學習器。Xgboost極端梯度提升算法是一種常用的集成學習算法,將多個決策樹結合起來形成一個強大的學習系統。CART(回歸分類)樹通過加性模型得到組合,進而做出共同的決策。XGBoost的結構如圖7所示。

圖7 XGBoost結構示意圖
盡管在一些如圖像、文本等的非結構數據的預測問題中,人工神經網絡的表現較優,但在處理中小型結構數據或表格數據時,基于決策樹的算法略勝一籌。XGBoost算法借助梯度提升(Gradient Boost)框架,在不斷添加樹的同時,通過共享屬性以生長樹。每次添加一棵樹實際上就是學習一個新的函數來適應上一次預測的殘差部分。事實上,根據樣本的特征會在每棵樹的相應葉節點上得到一個得分。最后只需將每棵樹的相應得分相加,就可以得到樣本的預測值,預測函數見式(9)。

其中,wq(x)為葉子節點q的分數,(x)為其中一棵回歸樹。
XGBoost目標函數由兩部分構成,第一部分用來衡量預測值和真實值之間的差距,也即損失函數,一般為均方差函數。另一部分是正則化項,與樹的復雜度有關,同樣包含兩部分,T表示葉子結點的個數,w表示葉子節點的分數。γ可以控制葉子結點的個數,λ可以控制葉子節點的分數不會過大,防止過擬合。目標函數定義如下:
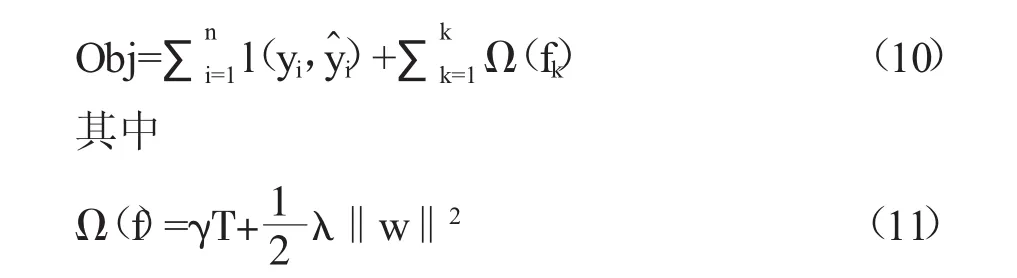
為使目標函數最小,XGBoost對損失函數進行了二階泰勒展開,經過改寫后得到最優的樹結構:
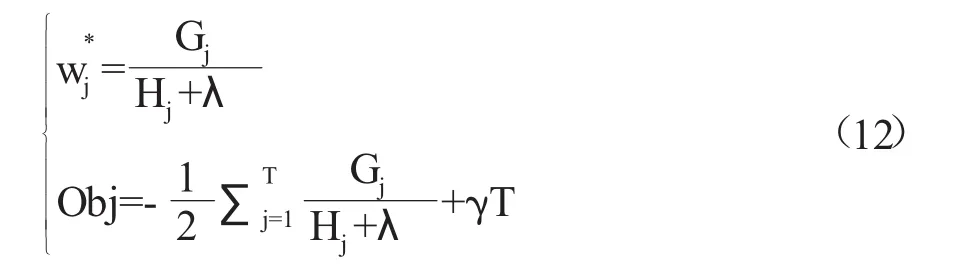
經計算可對每個用戶進行得分評價,分類時采用機器學習默認閾值0.5進行分割,部分用戶分類結果如表9所示。
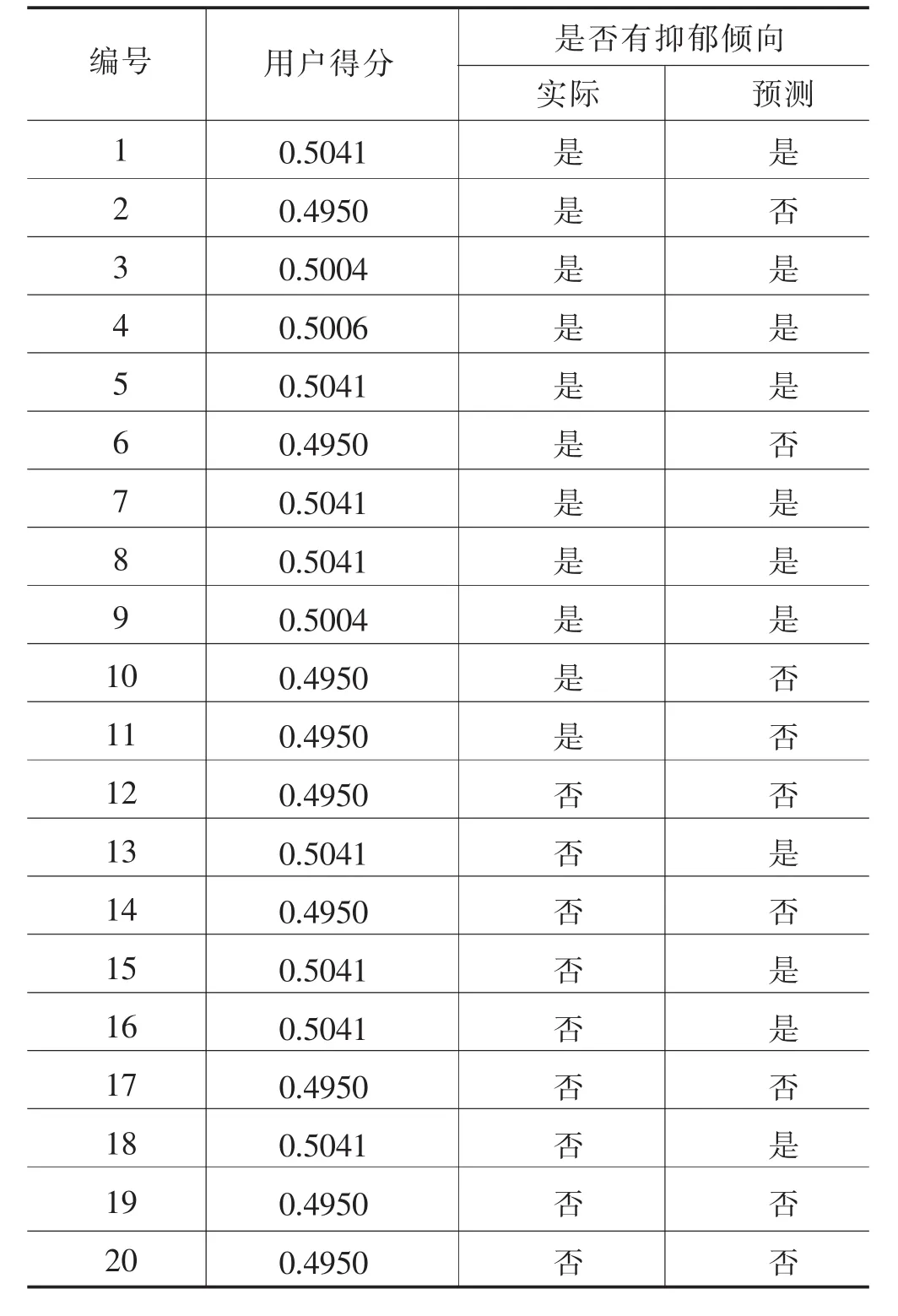
表9 XGBoost集成學習器分類結果
與單個學習器以及TOPSIS距離綜合評價法計算結果相比,XGBoost算法在準確率的計算上有顯著提升(見表 10)。
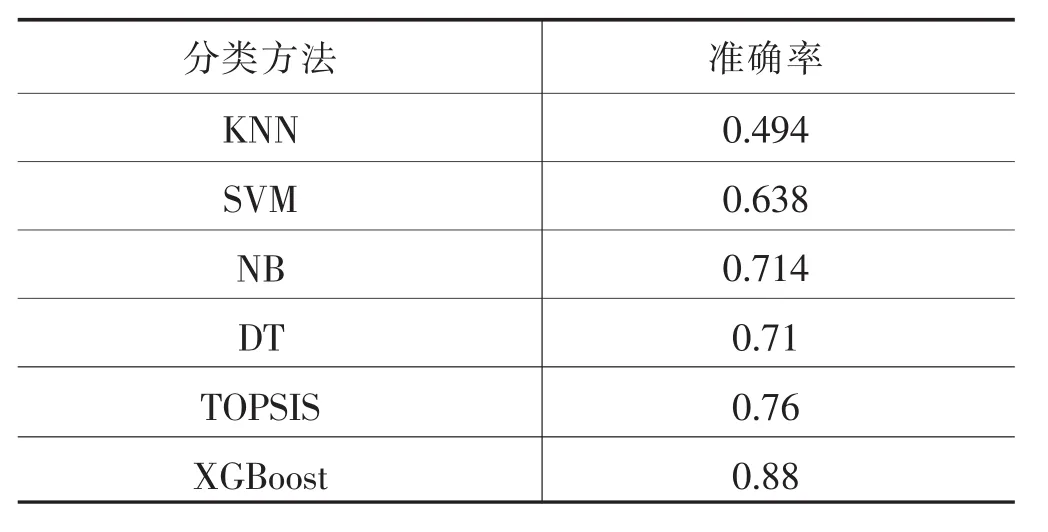
表10 各分類方法準確率對比
同時,XGBoost模型對影響抑郁癥傾向的重要特征進行篩選,最終得到6個對抑郁癥傾向影響較為顯著的變量,重要程度依次為第一人稱使用頻率、轉發數、抑郁傾向詞使用頻率、獲贊數、0:00-6:00發博率和年齡(見圖8)。
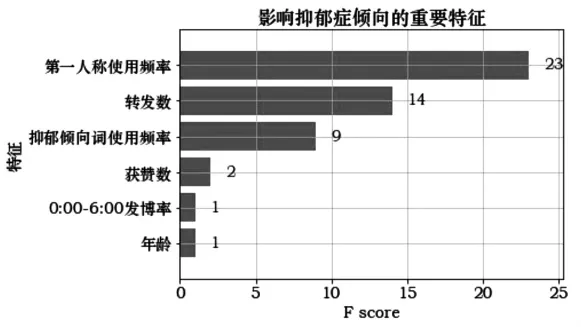
圖8 影響抑郁癥傾向的重要特征篩選
五、結論
學者利用社交網絡信息進行抑郁癥識別研究時,充分利用到用戶的微博文本特征進行深入挖掘。而本文在此基礎上,增加用戶個人信息和與人交往方面的考量。通過對抑郁癥傾向用戶在個人信息、與人交往以及微博內容相關變量的提取,初步勾勒出抑郁用戶的行為特征。研究發現,抑郁用戶多集中于經濟較為發達地區的女性大學生群體,因此可以充分利用信息公開透明的網絡世界,監測此類群體的“危險發言”,必要時采取行動進行救援。荷蘭阿姆斯特丹自由大學人工智能終身教授黃智生在2019年AI科學前沿大會演講時,首次向公眾展示了樹洞計劃:通過智能機器人監控社交媒體并實時發布自殺監控通報,隨后組織樹洞救援團根據監控通報采取自殺救助行動。盡管相關技術有待完善,但充分利用人工智能對抑郁癥患者進行心理疏導,無疑是人類精神文明建設的高階。
本文建立抑郁癥識別模型時,分別從傳統指標體系法與機器學習分類法兩個角度展開,由準確率看,機器學習中集成算法的分類效果顯著高于傳統統計指標體系法,但在特征變量重要性的分析上,XGBoost只篩選出6個影響較為突出的因素,且集中在微博內容方面的相關指標,而TOPSIS距離綜合評價法計算出的各變量的權重側重于與人交往方面,個人信息次之,這從一定程度上印證了運用社交網絡信息進行抑郁癥識別時加入二者相關信息的必要性。因此建立模型時不應單純追求準確率,應根據研究主題深入探究相關變量的影響效果,定性分析與定量分析相結合。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
