基于Storm非合作博弈調度的ETL研究
2021-10-28 01:03:24馬海旭馮欣王貴磊孫開蔚
長春理工大學學報(自然科學版) 2021年5期
關鍵詞:系統
馬海旭,馮欣,王貴磊,孫開蔚
(長春理工大學 計算機科學技術學院,長春 130022)
新技術的廣泛使用產生了大量數據。例如,Twitter[1]上的微博數量每一分鐘超過10萬條。數據價值隨著時間的流逝而減少并具有實時性、易失性等特點。目前發展較為成熟的Ma‐pReduce框架,本質上是批數據處理,而純流式數據處理框架Storm能夠有效地解決實時流處理問題。利用Storm構建ETL(Extract-Translation-Load)處理系統,本文針對ETL流程提取和轉換階段存在的問題展開研究。
變更數據捕獲作為ETL流程實時處理的關鍵。文獻[2]提出一種新的細粒度并行化/分發方法,對源數據進行分區并行處理,通過快照對比捕獲變更數據。文獻[3]提出了一種能夠實時地為應用程序提供信息的ETL框架,該框架無需創建數據倉庫便可對現有存儲庫進行分析。針對特定環境需求,文獻[4]對ETL體系結構進行了優化,以滿足實時感知并捕獲數據。實時ETL關鍵在于提升數據捕獲性能,針對變更數據捕獲延遲問題,在快照對比捕獲變更算法基礎上,提出了變更數據標記捕獲算法,該算法對源端變更數據置標志位,實驗結果表明,降低了ETL系統捕獲變更數據時間開銷。
數據中間處理作為ETL流程的重要步驟,采用Storm作為ETL過程數據處理框架,但Storm默認采用輪詢調度策略,存在通信開銷大和負載失衡等問題,降低了系統數據處理性能。調度的關鍵任務是尋找最優解,文獻[5]在生產調度中利用遺傳算法提出了優化策略。Storm系統調度的目的是降低網絡通信開銷、系統處理延遲以及負載均衡。文獻[6]提出了在Storm環境下離線和在線的兩種自適應調度算法,在線調度算法根據實時監測節點負載及集群通信負載制定調度策略,彌補了離線調度的不足,對于復雜的拓撲容易陷入局部最優。熊安萍等人[7]引入拓撲熱邊的概念,該算法是將高頻熱邊關聯的任務對遷移到同一工作節點,但該算法只考慮優化拓撲內部高頻熱邊通信的任務。魯亮等人[8]提出了基于權重的任務調度算法,設計了邊權增益模型,將任務移動到邊權增益值較大的節點上。但存在一個工作節點負載過度低于其余節點的問題。劉粟等人[9]提出了基于拓撲結構的任務調度策略,將拓撲中度最大的組件對應的線程優先移動到CPU資源充足的節點上,但將任務盡可能移動到某個節點的同時必定影響集群負載均衡。文獻[10]提出并實現了一種自適應在線調度方案,解決了在不發生擁塞的情況下處理波動負載,利用Cgroup實現了資源隔離,減輕了資源爭用帶來的性能干擾。王林等人[11]利用蟻群算法在NP-hard問題上的優勢結合Storm本身拓撲特點,提出改進蟻群算法優化Storm任務調度,但算法易出現局部最優解。針對Storm默認調度算法以及相關研究不足,本文提出了非合作博弈Storm調度算法,構造博弈函數,充分考慮任務負載以及通信開銷,將任務調度到合適的工作節點。實驗結果表明,相對于Storm默認調度算法以及文獻[6]的在線調度算法,提出的算法在通信開銷、負載均衡以及系統延遲方面均有所改進。
1 ETL數據捕獲
ETL作為構建數據倉庫的核心部件,捕獲數據又作為ETL的關鍵一步,企業組織要求零延遲捕獲數據以支持決策系統。變更數據捕獲(CDC)是ETL流程中數據捕獲(E)步驟的關鍵。當變更數據捕獲流程發現源數據庫端有數據發生變化時,數據捕獲系統將提取并處理這些數據以刷新數據倉庫(DW)。其余數據(不受更改影響)將被拒絕,因為它已被加載到DW中。
1.1 標記變更捕獲
關于ETL的功能流程,在文獻[2]中作者詳細闡述了基于快照對比的變更數據捕獲(CDC)。針對快照對比無法低延遲捕獲變更數據的要求,本文提出了變更數據標記捕獲算法。
提出的新方法需要由特殊的源數據庫端(標記變更數據)和捕獲變更數據階段共同完成。首先需要為源表設置標記位F,數據庫插入、更新、刪除操作標記位F分別對應1、2、3。表1為表2的快照。表2中標記位F=1、2、3的元組分別各有2個,表示源表插入2個元組,更新2個元組,刪除2個元組,只是刪除操作并沒有立即執行,便于捕獲階段提前發現刪除數據。待操作結束,需清零所有標記位。捕獲變更數據和源數據庫操作可同時執行,CDC階段無需逐條元組對比來捕獲變更數據,只是增加了源數據庫端的負擔。

表1 前一時刻表STpv

表2 當前表ST
1.2 標記捕獲算法
為了降低ETL流程再次發現并捕獲變更數據帶來的系統時間開銷,采取在源端標記變更的數據元組,從而減輕提取變更數據的壓力。具體變更數據標記捕獲算法如下:

算法1描述了改進后的CDC功能。第一行表示在數據源端對變更的數據做標記,對插入、更新、刪除對應記錄的標記位分別置1、2、3。依次讀取tuple,如果tuple.F=1,則表示插入操作;如果tuple.F=2,則表示更新操作;如果tuple.F=3,則表示刪除操作。
1.3 快照捕獲思想
設tuple1和tuple2分別是存儲在源數據庫表ST和該表對應的快照表STpv中的兩個元組。如果tuple1和tuple2滿足式(1)和式(2),這意味著它們無變化(CRC,循環冗余校驗)。tuple1應該被CDC進程拒絕,因為沒有發生任何更改。如果僅滿足式(1),表示tuple1已受到更改的影響,由CDC進程提取為UPDATE。如果滿足式(3),則這表示tuple1為新插入元組,由CDC進程提取為INSERT。如果滿足式(4),表示tuple2為已刪除元組,由CDC進程提取為DELETE。

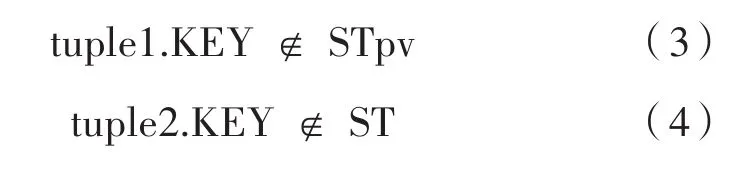
1.4 捕獲實驗分析
實驗機器配有intel-Core i7-9700K CPU@3.6 GHZ x8處理器,8 GB RAM,40GB可用硬盤空間。機器安裝CentOS-7.0 64系統,使用Mysql-7.6.10數據庫和IDEA2018.2編輯器。采用高級語言Java編程語言,運行環境采用JDK 64位。
針對快照對比捕獲變更數據算法與變更數據標記捕獲算法對于發現并提取變更記錄的性能優劣問題,本文利用單機模式及小規模數據,研究這兩種算法捕獲變更數據差異。采用簡單的字母序列,來分析兩種算法捕獲數據表中變化的數據記錄。
對比兩種方法在不同記錄數下捕獲變更數據耗時,分別向Mysql數據庫中加載不同數量的消息記錄(每條消息記錄包含20個字母型字段),執行插入更新刪除數據庫變更操作,記錄被捕獲到的變更消息記錄。實驗結果如圖1所示,變更數據標記捕獲方法捕獲到變更數據消耗的時間相比快照對比方法捕獲到變更數據消耗的時間降低了22.6%。
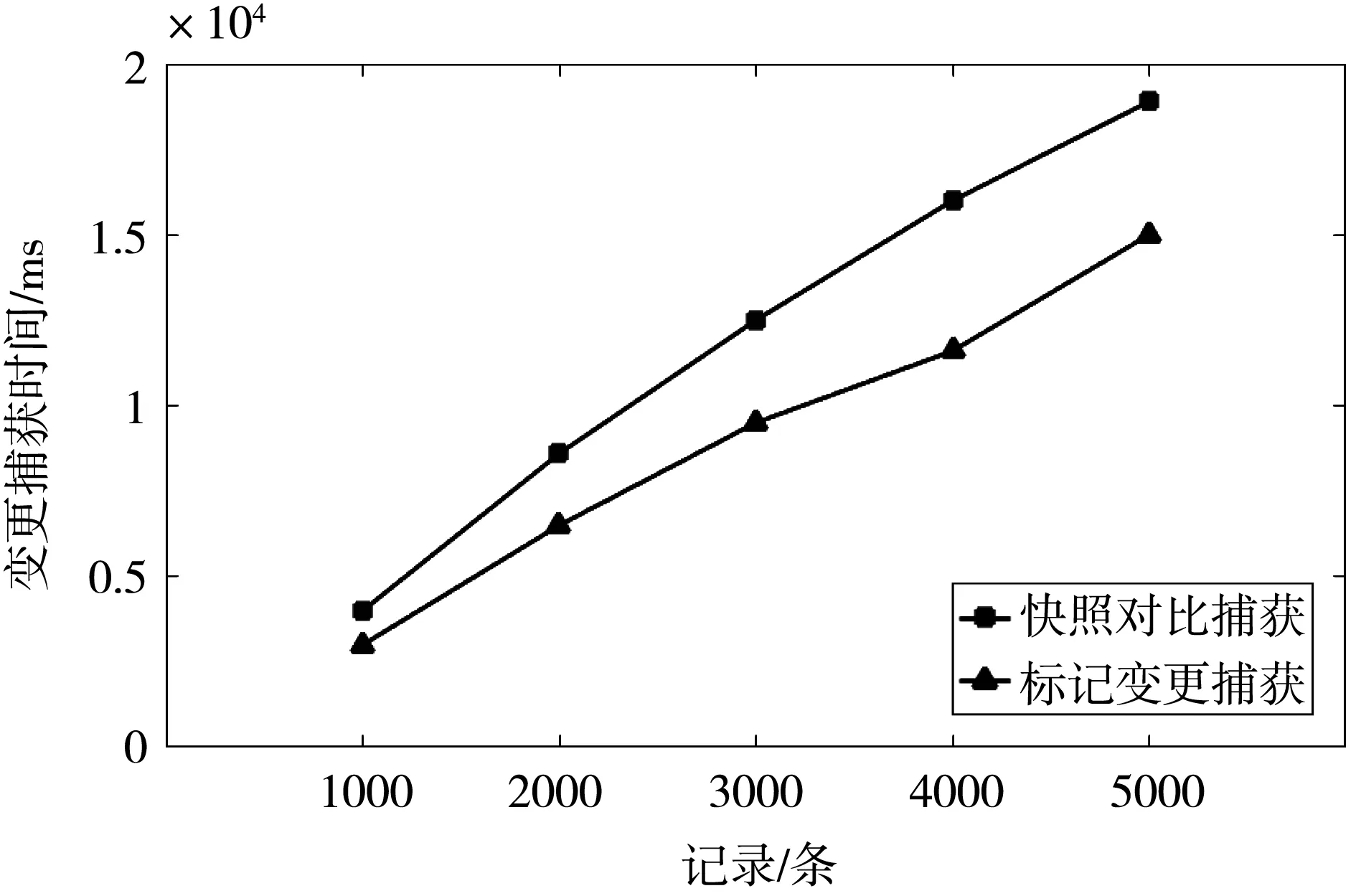
圖1 記錄數對變更捕獲的影響
對比兩種方法在不同字段數下捕獲變更數據。分別向Mysql數據庫中載入不同字段數(字母型)的消息記錄(每種字段數均有2 000條記錄),執行三種數據變更操作,記錄被捕獲到的變更消息記錄。實驗結果如圖2所示,變更數據標記捕獲方法捕獲變更數據消耗的時間相比快照對比方法降低了23.1%。

圖2 字段數對變更捕獲的影響
實驗表明,在單機模式下,面對小數據量,變更數據標記捕獲方法在捕獲變更數據方面要優于通過快照對比捕獲變更數據的方法。
2 Storm博弈調度
2.1 Storm調度分析
Storm調度算法默認采用輪詢算法,對空閑slot按端口號升序排序,將運行任務的executor輪詢部署到已排序的slot上,集群最后一個節點負載明顯低于其余各節點。默認輪詢的調度算法存在負載失衡的問題。默認調度只是簡單的將實例化的executor輪詢分發到各節點,集群上各工作節點間存在大量的網絡通信開銷。如圖3所示,拓撲由組件Spout,Bolt_1和Bolt_2實例的任務組成。

圖3 拓撲結構圖
如圖4所示,顯而易見,部署到集群中的拓撲,任務之間均為網絡通信。數據通過網絡傳輸消耗的時間遠大于計算機內部進程間或進程內部的數據傳輸延遲,因此,降低拓撲網絡間數據通信開銷,提高節點內部數據通信量,可有效提升Storm數據處理性能。
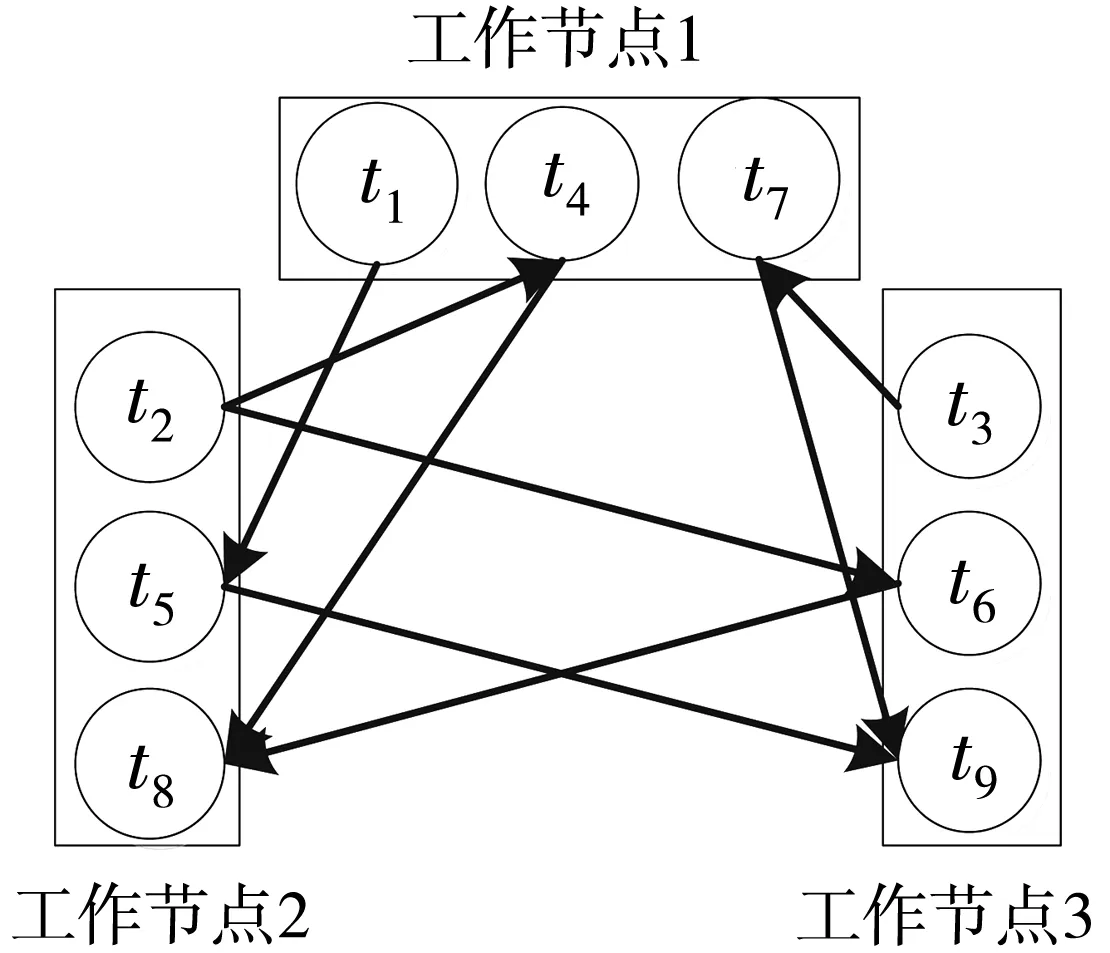
圖4 拓撲部署圖
2.2 調度思想
調度優化思想闡述。本文假定的拓撲簡化模型如圖5所示,集群配置了3個節點,每個節點僅配置一個slot。任務分配情況如圖5所示,拓撲模型中任務t1和t2與任務t5傳輸的數據量遠大于任務t4與任務t5之間的傳輸量,任務t6在節點2上無通信傳輸而與t8有通信往來,將任務t5從節點2轉移到節點1上,任務t6從節點2轉移到節點3上,可有效降低節點間通信開銷,提升集群的負載均衡性,如圖6所示。
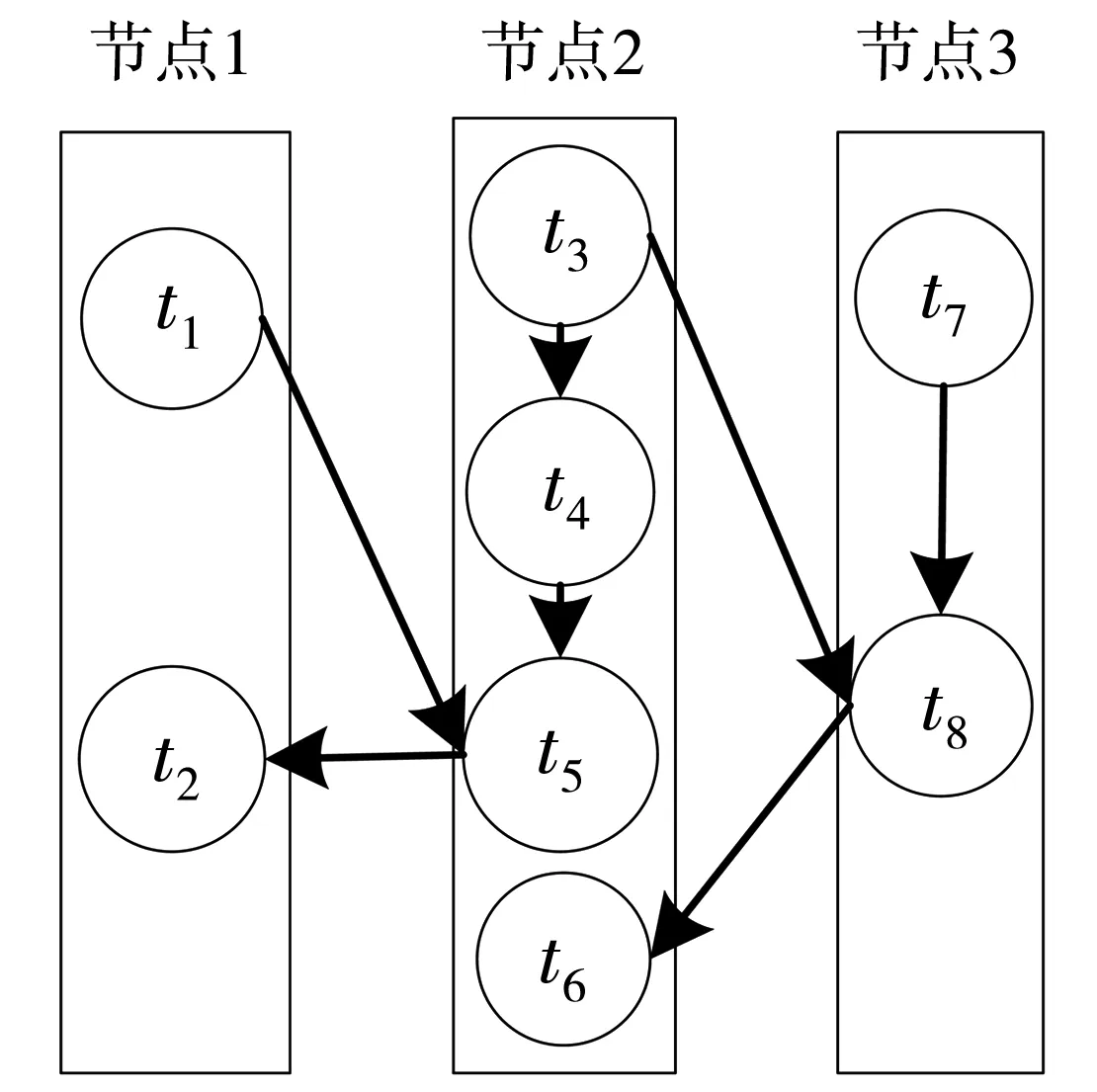
圖5 未優化拓撲
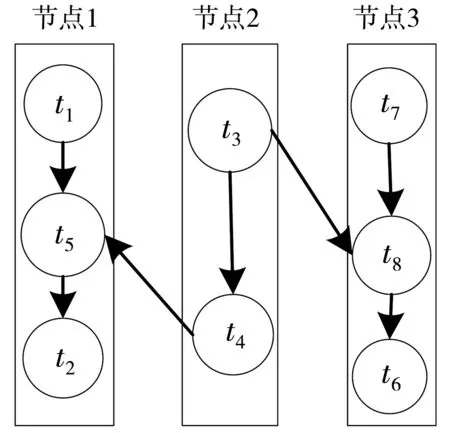
圖6 已優化拓撲
2.3 相關定義
在Storm調度中,應考慮節點內部通信量最大(由數據傳輸總量固定,則節點間通信量最小)的同時兼顧集群負載均衡性,引入收益函數(博弈函數)求解系統調度的最優解。為了降低網絡通信,一個節點部署一個slot[8]。針對上述模型,作出如下定義:
定義F為節點內部數據傳輸總量,如下:

其中,S為集群slot集合(一個節點部署一個slot);Tk為第k個slot內部任務集合;rij為任務i到任務j的數據流;Skrij為第k個 slot內部數據流rij。

其中,N為節點集合;nk為節點Wnk為節點的CPU負載;Mnk為節點的內存負載。
定義θ和η分別為工作節點的CPU和內存負載標準差,如式(9)、式(10)所示:
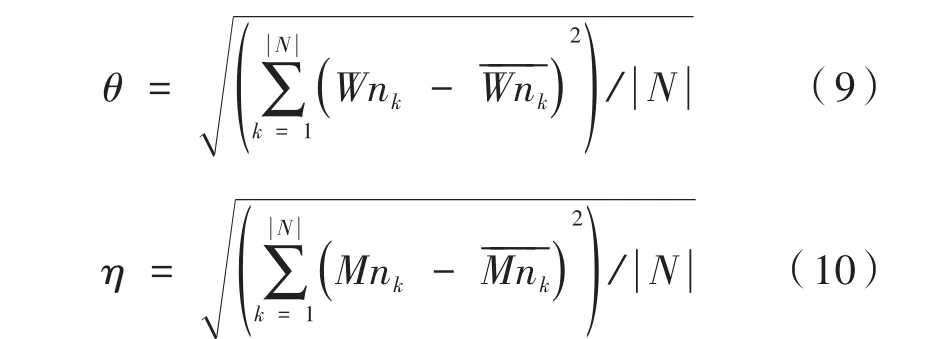
定義g為集群的CPU和內存負載標準差加權之和,如下:

其中,λ為θ的權重;γ為η的權重;通常λ≥γ,主要考慮CPU負載對系統的影響。
調度優化問題可以轉化為滿足式(12)、式(13)、式(14)的條件下收益函數u的最大值問題。

2.4 博弈建模
構建Storm拓撲控制的非合作博弈模型,其中博弈模型的博弈局中人或稱博弈參與者為調度系統中的任務;參與者的策略為當其他參與者策略保持不變時改變自己的調度策略來最大化自身以及系統整體效用,將博弈參與者的所有可用策略構成一個策略集合,如下:

被稱為一個調度策略向量;當博弈參與者使用上述策略時對應得到非合作博弈函數如下:

根據納什均衡點的定義,當構造的Storm任務調度控制模型經過博弈達到納什均衡時,即可認為系統收益已達到穩態,沒有任一任務可以通過僅改變自身調度策略來提高自身以及系統的整體效用。
定義 策略集合 σt=[σt,1,σt,2,σt,3,...,σt,n]是提出的多任務資源分配博弈模型的納什均衡點的充分必要條件,滿足式(17):

接下來首先根據文獻[12]中Boyd S提出的納什均衡存在性定理Ⅱ證明所提出模型納什均衡點的存在性。
定理 構造的任務調度控制非合作博弈模型存在納什均衡點。
證明 由于Storm任務調度優化過程中集群節點內部通信量逐漸增加并趨于平穩,故邊界條件(13)是歐式空間上的一個非空有界閉凸集,然而只需證明邊界條件(14)滿足納什均衡存在性定理Ⅱ中規定的條件:
假設所有任務都分配給一個slot,那么必存在一個常量μ,使(m ax) Wnk< μ,根據式(9),θ≤(m ax) Wnk(1 ≤k≤n),同理根據式(10),η ≤(m ax) Mnk(1 ≤k≤n),而g=λθ+γη,又由于調度的不斷優化,負載標準差逐漸減小并趨于平穩,故g是歐式空間上的一個非空有界閉凹集。綜上所述,收益函數u為有界閉凸集。拓撲任務調度的收益函數u存在最大值,因此構建的Storm集群拓撲調度博弈模型中存在納什均衡點。
2.5 算法設計
本算法執行的前提是監控集群的運行狀態,其中包括拓撲中任務間的數據流量和集群中各節點的CPU消耗量以及內存的使用量。在獲取節點內部任務間最大通信量的同時考慮負載均衡。因此在非合作博弈算法的設計過程中,當用戶提交拓撲后系統會先執行默認調度算法,并當集群上各工作節點中的拓撲任務運行穩定后,采集并存儲節點內任務間數據流以及節點的CPU負載和內存負載。結束后,則執行博弈算法對任務進行重新調度。在Storm拓撲運行中,若出現集群上各節點CPU負載持續不均,即在指定持續時間間隔內,集群中各個工作節點的CPU負載最大值與最小值之差大于設定閾值,則再次觸發博弈調度算法,具體算法如下,具體參數如下所示。


上述算法基于采集默認調度信息,然后判斷是否觸發博弈調度。若初始調度集群節點任務數失衡,則重復初始化。隨后遍歷每個節點中的所有任務,分別移動到不同的節點,記錄最優的收益值。迭代M次,若最優值沒有改變,即為最優值。此調度算法的關鍵在于,未獨立開來考慮減少集群上的網絡間的通信開銷與節點間的負載均衡,而是將節點內的數據通信與集群資源的負載均衡有機結合到一起,從自適應的角度出發,通過迭代的方法,使集群收益最大化,從而得出最優的調度策略。
3 ETL流程優化
改進后的ETL流程如圖7所示,源數據庫在變更數據時標記相關數據,便于ETL系統捕獲變更,這樣捕獲變更可以有效節省后期因遍歷數據帶來的時間開銷。基于非合作博弈調度的Storm系統負責提取、處理,并加載數據到數據倉庫。本文提出的改進算法構建了實時GS-M-ETL數據處理流程。
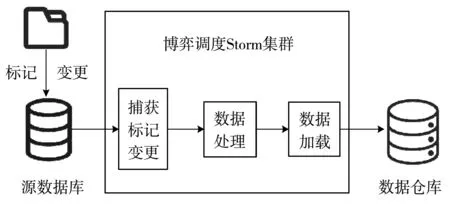
圖7 ETL數據處理優化圖
ETL流程中數據提取和處理轉換是影響系統性能的重要因素,其中數據提取是關鍵部分。數據捕獲采用變更標記捕獲算法(CDMC),根據源數據庫端變更的數據記錄,提取相關的變更數據。數據處理采用基于非合作博弈調度的Storm(Game-Sorm)分布式流處理系統。
4 實驗結果與分析
4.1 實驗環境
測試環境是由13臺PC搭建的Storm-1.2.2集群。每臺機器都配有intel-Core i7-9700K CPU@3.6 GHZ x8處理器,8 GB RAM,40 GB可用硬盤空間。機器均安裝CentOS-7.0 64系統,并通過LAN中的交換式以太網1 Gbit進行互連。其中3個節點共同運行Zookeeper-3.4.10集群和kafka-2.2.0集群,Nimbus、進程UI和數據庫Mysql-7.6.10運行在其中1個節點上。其余10個節點運行Su‐pervisor守護進程。
4.2 實驗方案
實驗使用Storm框架提供的可插拔的自定義任務調度器Pluggable Scheduler,該調度器是專為開發人員設計的。利用自行實現的負載監控器Lead Monitor來采集拓撲運行時對應executor的一些關鍵數據,包括executor負載、worker node負載、executor間通信量等,并且Load Monitor以dae‐mon進程方式在后臺運行。此外,本實驗選擇Ganglia[13]作為 Storm 集群監控工具,利用 Ganglia提供的數據來輔助實驗結果的分析。為驗證非合作博弈調度算法Game-Storm的有效性,本文同時部署了Storm框架默認調度算法(Default Scheduler)和Storm框架自適應在線調度算法(Online Scheduler)[6],算 法 Online-Storm 在 每 個節點配置2個slot,相關參數參照如表3所示。
表3列出了Game-Storm調度算法的各項參數配置。實驗參數是通過若干次實驗并經過微調后確定的理想值,具體參數需要根據實際運行情況進行人為調整。實驗設置10個工作節點和10個工作進程,即每個工作節點上僅部署一個工作進程,這樣可有效降低工作節點內部進程間通信開銷,與本文非合作博弈調度算法描述相符。

表3 Game-Storm參數配置
本文提出的算法調度必須在運行時執行,以便使分配適應集群中負載的變化。圖8展示了需在Storm體系結構中集成在線調度模塊。圖中描述的負載監控器運行在每臺機器上,負責采集工作節點的各項性能參數(如節點間通信量,CPU和內存消耗量),并將負載數據存入數據庫中。調度生成器模塊從數據庫中讀取負載信息,生成調度策略。可以定期檢查監控數據,并運行自定義調度程序,判斷是否可以部署新的更有效的調度策略。

圖8 改進的Storm系統框圖
圖8展示了Storm集群負載監視模塊,該監控模塊負責在拓撲運行一定的時間窗口內,采集并計算拓撲任務占用工作節點CPU負載信息,以及拓撲任務之間的通信量大小,具體系統監控及數據采集方案如下:
由于Storm系統中的一個拓撲任務運行于工作進程的一個工作線程中,因此為了獲取拓撲任務在執行過程中對工作節點CPU、內存資源的占用量,還有各對拓撲任務在單位時間內傳輸的信息量,需實時追蹤拓撲任務對應的工作線程ID及其相關聯的所有工作線程。利用線程所在工作節點的CPU主頻與該線程占用的CPU時間的乘積來表示線程占用的CPU資源大小。ThreadMXBean類的 getThreadCpuTime(long id)方法可以獲取線程id占用的CPU時間。
各對線程間通信速率以及線程占用的內存大小,需要統計各線程收發總的元組數以及元組的傳輸時間,線程間的通信速率由線程收發數據差與對應時間窗容量的商求得,線程執行期間占用的內存量由單位時間內接受的元組數與發送的元組數之差決定。具體實現:在每個Spout/Bolt源中添加任務監控器。在具體的每個任務中必須通知其線程ID以在特定Java進程中運行。對于每一個Spout/Bolt,添加一個全局變量:

為了評估本文提出的Game-Storm-ETL平臺,本文提供了一個ETL過程示例。開發了一個數據生成器程序來生成源數據,產生了1×109個元組,每個元組包含20個字母型字段。ETL過程為按如下方式處理數據。數據集載入Kafka(top‐ic=3,partitions=12)消息序列數據庫,數據載入過程存在更新與刪除操作。數據儲存在消息中間件Kafka中,Storm從Kafka中讀取數據,經處理后加載到Mysql數據庫中。
4.3 實驗結果
實驗對比優化前后(Default調度算法、On‐line-Storm調度算法和改進后的Game-Storm調度算法)的Storm系統在節點間網絡通信量和集群負載均衡兩個方面的性能,以及對比了改進后的ETL系統數據處理延遲與原ETL系統數據處理延遲。實驗結果如下:
如圖9所示,實驗開始任務分配遵循Storm系統默認的調度算法,首先執行默認調度算法,待Storm系統運行趨于穩定后,集群上節點間通信的數據流大小平均值約為119 372 tuple/s。由于在第85 s時系統出現持續70 s的觀測周期內集群上工作節點的CPU負載的最大值與最小值之差大于20%,因此,再次觸發了調度,在第115 s處重調度已結束,節點間通信量持續增長。隨著時間的推移節點間通信量趨于平穩。

圖9 三種節點間通信算法的比較
Game-Storm調度算法和Online-Storm調度算法在節點間數據流大小平均值分別為80 337 tuple/s和90 961 tuple/s,相比Storm默認調度算法分別降低了32.5%和23.2%。
圖10顯示的是三種調度算法下集群CPU負載情況。默認的調度算法CPU最大負載超過了60%,且最大最小CPU負載差也大于20%,所以在線算法與本文提出的算法都會被觸發。默認調度CPU負載標準差高達9.57,重調度后,在線調度算法和Game-Storm調度算法的負載標準差分別為3.51和3.25。

圖10 三種CPU負載平衡算法的比較
如圖11所示,變更數據標記捕獲算法與Game-Storm調度算法構建的系統(GS-M-ETL)使得ETL性能得到了提升。待Game-Storm調度結束,且系統運行趨于平穩,ETL過程時延相比于未改進的變更數據捕獲方法與默認調度算法下的ETL系統,系統時延降低了29.5%左右。提出的基于非合作博弈的調度算法使Storm系統在降低網絡通信量以及負載均衡方面的性能得到了提升。同時,與提出的變更數據標記捕獲方法結合,降低了ETL過程數據處理延遲,提升了ETL系統性能。
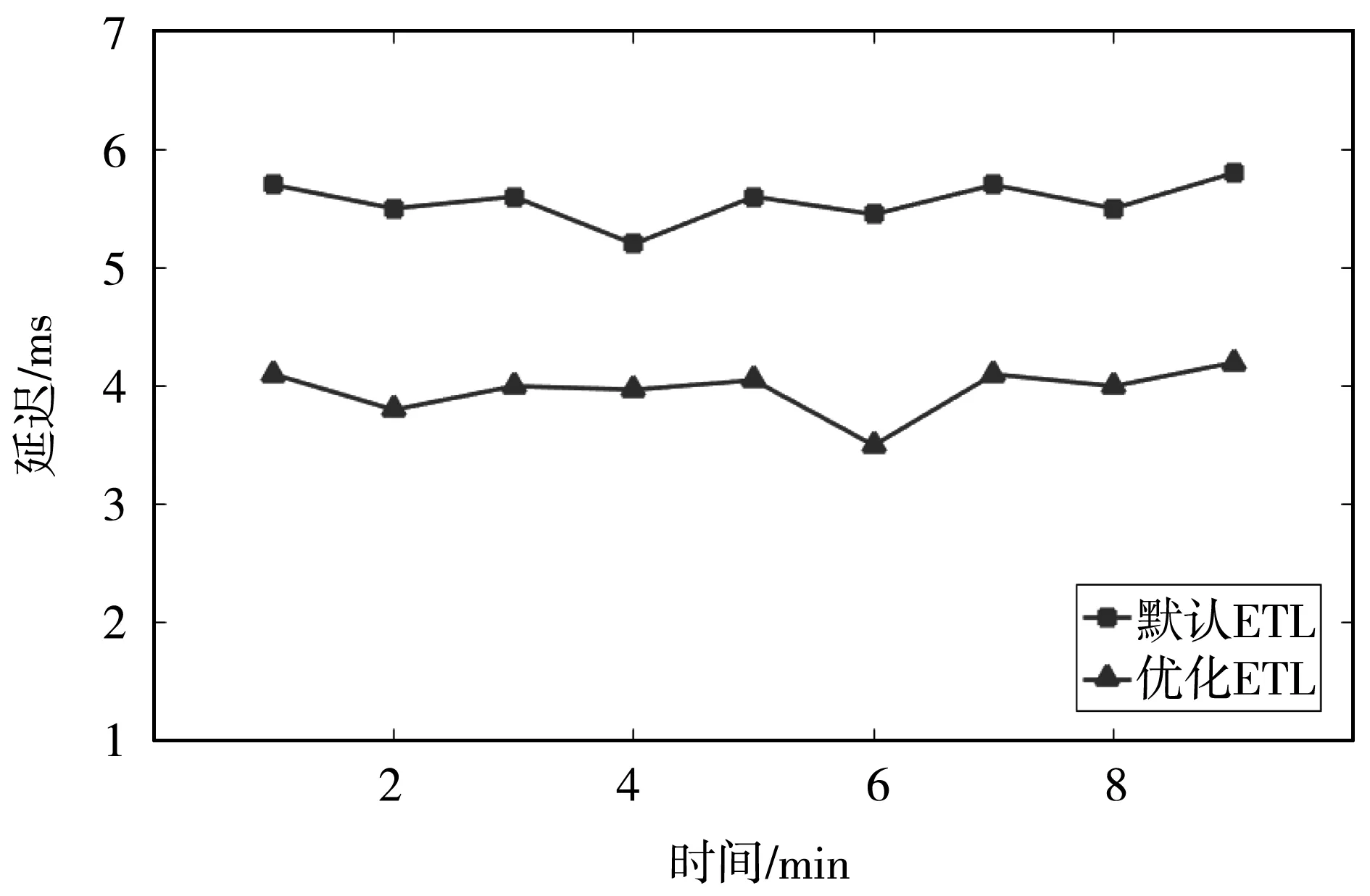
圖11 ETL系統處理延遲對比
利用Ganglia對集群負載進行監控。從Ganglia監控改進后的調度系統得到的數據來看,Storm集群各工作節點CPU、內存等使用率都較為均衡,沒有節點負載過重,集群整體負載較為均衡。
5 結論
本文提出了變更數據標記捕獲算法,相對于傳統基于快照對比捕獲算法,在變更數據捕獲方面性能得到了提升。Storm作為實時ETL流處理框架,默認采用輪詢調度算法,節點網絡通信開銷和集群負載均衡存在優化空間。本文提出了非合作博弈的Storm調度,實驗證明集群網絡通信開銷和負載均衡得到了優化。二者的改進,使得ETL流程的整體性能得到了提升。Storm調度尚未考慮網絡帶寬問題以及未曾考慮I/O傳輸接口等硬件資源的影響,希望未來這些問題可以得到解決。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
