基于結構與細節(jié)層分解的暗光照圖像增強模型
2021-11-07 14:43:38汪雷宇郝世杰
合肥工業(yè)大學學報(自然科學版) 2021年10期
汪雷宇, 韓 徐, 郝世杰
(合肥工業(yè)大學 計算機與信息學院,安徽 合肥 230601)
隨著成像設備的發(fā)展,相機的分辨率、曝光時間等性能都有極大改善,拍攝出來的圖像可以得到很好的質量。但由于拍攝環(huán)境的復雜性,常常導致圖像視覺效果并不理想。例如,由于暗光和逆光等情況,圖像對比度較低,圖像細節(jié)被黑暗隱藏,降低了圖像的視覺質量,也為各種后續(xù)處理任務帶來了不利影響。因此,研究圖像暗光增強方法,提高圖像內容可視度,具有重要的研究價值。
基于暗光增強深度網絡[1]在重構圖像時難以生成完整的細節(jié),從而導致增強結果略顯模糊。為解決這一問題,本文從Retinex理論[2]中得到了啟發(fā)。根據(jù)Retinex理論,一張圖像S可以視作光照圖像L和反射率圖像R的乘積。其中:光照圖像L反映了拍攝環(huán)境下的光照分布情況;反射率圖像R表示物體的反射性質圖像,即圖像場景的內在屬性,光照的改變不會對反射率圖像R產生影響。
暗光增強的根本任務是對光照層進行改變,這一任務在理論上不會改變物體表面的紋理細節(jié)。而基于深度網絡的方法[1]在試圖重構圖像時,不但要估計出成像場景中新的光照分布,還要重構出所有的圖像細節(jié)。而后者對于暗光增強任務而言,是完全沒有必要的。基于上述分析,本文提出了一種分而治之的思路:根據(jù)圖像分解的方法,將圖像的結構層(base layer)和細節(jié)層(detail layer)進行分離,其中結構層才是光照衰變的根本原因,因此本文利用深度學習技術對結構層進行增強處理,而細節(jié)層基本保持不變。基于上述思路,本文提出了一種基于圖像分解的光照增強模型,通過一種邊緣保留濾波器來有效分解彩色圖像明度層,得到細節(jié)層和結構層信息;結構層通過光照增強模塊進行處理,增強后的結果經過圖像組合和顏色空間變換得到最終的結果,其模型結構如圖1所示。基于上述思路,本文能夠在增強圖像對比度的同時能夠很好地保持圖像的細節(jié)信息,確保了增強后圖像的視覺質量。
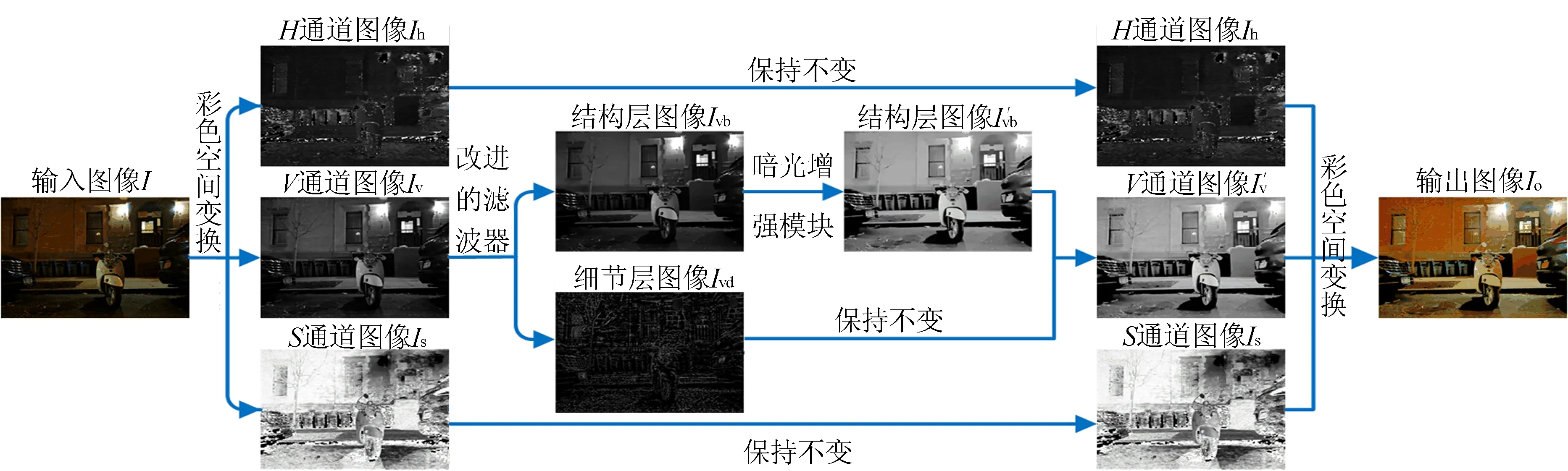
圖1 本文模型的模型結構示意圖
為便于展示,圖1中細節(jié)層圖像Ivd為增強10倍的效果圖。
1 相關工作
1.1 Retinex相關算法
Retinex是一種常用的建立在科學實驗和科學分析基礎上的圖像增強方法,通過幾十年的不斷發(fā)展,從單尺度Retinex算法[2](single-scale retinex, SSR)改進成多尺度加權平均的Retinex算法[3](multi-scale retinex, MSR),再發(fā)展成帶彩色恢復的多尺度Retinex算法(multi-scale retinex with color restoration, MSRCR);相比較而言,MSR在實現(xiàn)圖像動態(tài)范圍的壓縮同時保持了較好的色感。但SSR和MSR都普遍存在偏色的問題,為了改善此問題,MSRCR在MSR的基礎上,加入了色彩恢復因子C來調節(jié)由于圖像局部區(qū)域對比度增強而導致顏色失真的缺陷。此外,在Retinex的基礎上還提出了簡化的Retinex 模型[4],通過在R、G和B通道中找到最大值來分別估計每個像素的照度,然后對照度圖進行完善來達到增強的效果。
1.2 基于融合的方法
在基于融合算法對圖像進行暗光增強方面,可以從單張輸入圖像得到增強后的結果。文獻[5]首先通過Retinex理論得到圖像的原始亮度分量,然后設法得到全局亮度增強的亮度分量和局部對比度增強的亮度分量,最后通過拉普拉斯金字塔對上述3種亮度分量進行融合,得到增強后的亮度分量。另外,也可以從多張輸入圖像得到增強后的結果。文獻[6]在擁有多張相同場景但不同曝光程度圖像的情況下,通過設置權重矩陣,給曝光良好的像素分配較大的權重值,給曝光不足的像素分配較小的權重值,通過融合這些不同曝光程度的圖像得到曝光程度良好的圖像。
1.3 基于深度學習的方法
文獻[7]提出了堆疊稀疏去噪自動編碼器(stacked sparse denoising autoencoder,SSDA)網絡模型。在此基礎上,文獻[1]提出了一種基于端到端的暗光增強深度網絡(deep autoencoder approach to natural low-light image enhancement,LLNet)。
LLNet圖像增強算法的訓練數(shù)據(jù)為成對圖像,包括暗光圖像和正常光照圖像,整個網絡通過堆疊多層的稀疏降噪編碼器,學習到暗光圖像的深層特征,然后通過對應的稀疏降噪解碼器對深層特征進行解碼重構;在重構的過程中,需要盡可能地保證重構后的圖像能夠接近正常光照圖像,但是該算法在重構圖像時難以生成完整的細節(jié),從而導致增強結果略顯模糊。
受Retinex理論的啟發(fā),并結合卷積神經網絡技術,文獻[8]提出了RetinexNet模型,它采用兩階段式先分解后增強的步驟。在第1階段,對圖像進行解耦,得到光照圖和反射圖;在第2階段,對前面得到的光照圖進行增強,增強后的光照圖和原來的反射圖相乘得到增強結果。
目前基于深學習的圖像暗光增強工作主要有以下2點局限性:
(1) 成對的訓練數(shù)據(jù)難以獲取,這使得深度神經網絡的訓練變的十分困難。
(2) 很難設計得到一種端到端的神經網絡結構。
針對成對的訓練圖像難以獲取這個問題,研究人員通過不同的方法進行嘗試。一方面,可以在現(xiàn)有圖像的基礎上通過技術處理得到相對應的圖像;例如文獻[9-11]均采用了該種方法,雖然效果很好,但是得到的圖像仍然無法完美地模擬真實情況。另一方面,技術人員利用成像技術得到更加自然的圖像對。文獻[12]提出了SID(see-in-the-dark)數(shù)據(jù)集,通過控制曝光時間得到自然的圖像序列,效果顯著,但時間和精力花費較大。由于成對的訓練圖像難以獲取,部分研究人員轉向了對訓練集要求相對較低的無監(jiān)督學習模式。在文獻[13]中,不需要輸入-輸出圖像對,只需要一組“好”圖像(用于輸出圖像的真實值)和一組想要增強的“壞”圖像(用于輸入圖像)就可以完成EnlightenGAN模型的訓練,對數(shù)據(jù)集的要求大大降低。
2 本文方法
2.1 本文框架
借助于LLNet網絡,本文提出了一種基于結構與細節(jié)層分解的暗光照圖像增強模型,利用邊緣保持濾波器將圖像結構層和細節(jié)層進行分解,利用自編碼器網絡處理圖像結構層,對圖像細節(jié)層加以保留。
首先將原始彩色圖像I由RGB彩色模型空間轉換到HSV彩色模型空間,提取出H、S和V通道分量,并表示為Ihsv={Ih,Is,Iv}。
然后通過保邊緣濾波器對V通道分量Iv進行分層處理,得到相對應的V通道細節(jié)層分量Ivd和V通道結構層分量Ivb;緊接著將V通道結構層分量Ivb通過光照增強模塊進行亮度增強,得到V通道結構層分量Ivb的增強圖像Ivb′,并將得到的增強圖像Ivb′和V通道細節(jié)層分量Ivd重新組合,得到V通道的增強圖像Iv′。
最后將三通道分量{Ih,Is,Iv′}融合得到Ihsv′并由HSV彩色模型空間轉換到RGB彩色模型空間,獲得最終的輸出圖像Io。
2.2 改進的保邊緣濾波器
在模型中,為實現(xiàn)高效的圖像結構-細節(jié)分解,提出了一種改進的保邊緣濾波器。通過構建總變分模型,并設計了基于快速傅里葉變換的計算方法。本節(jié)重點描述改進的保邊緣濾波器相關部分的工作。
濾波器的損失函數(shù)表示為:
(1)
L=lgS,
其中:S為輸出圖像;L為輸入圖像;下標V表示V通道分量;λ為正則化參數(shù),用來平衡前后兩項的系數(shù);γ為分母比例參數(shù);為離散微分,在本文中,它包括有水平方向x和垂直方向y;Ω為r×r大小規(guī)模的局部圖像塊。在(1)式中,第1項考慮了初始圖像IV與輸出圖像S之間的保真度,它使得平滑的S與輸入Iv之間的差最小;第2項考慮了結構感知平滑度,使S的偏導數(shù)最小。
(1)式可表示成如下最小化問題,即
(2)
L=lgS,
其中:W為平滑權重;λ為正則化參數(shù);S為S上的離散微分,可分為X方向和Y方向。
(2)式可以通過交替方向最小化(alternating direction method of multipliers,ADMM)技術來有效地解決。
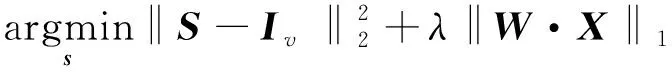
s.t.X=S
(3)
(3)式的增強拉格朗日函數(shù)可以表示如下:

(4)
其中:〈·,·〉為2個矩陣的內積運算;ρ為正罰標量;Y為拉格朗日乘數(shù)。(4)式中存在S、X、W、ρ和Y共5個未知變量。通過ADMM方法對(4)式中的未知變量進行迭代求解。
對于未知變量S:

(5)
對(5)式進行求導,得到:
2(S-Iv)+ρk-1DT(DS-Xk-1)+
DTYk-1=0
(6)
其中:D為輸入圖像的微分運算結果,可分為Dx和Dy,分別代表輸入圖像在X和Y方向上的微分運算結果。
對(6)式進行化簡,可得:
(7)
對(7)式直接進行求解,可得:
(8)
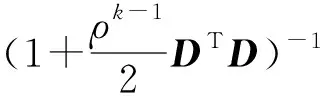
(9)
進而可以得到(10)式,即
Sk=
(10)
其中:F表示傅里葉變換;F-1表示傅里葉逆變換;F*表示共軛傅里葉變換。
對于X有:
(11)
由(11)式可得:
(12)
其中,Jα(x)=sgn(x)max(|x|-α,0)。
同理,對于W、ρ和Y,有
(13)
ρk=ηρk-1, (η>1)
(14)
Yk=Xk-1+ρk-1(Sk-Xk)
(15)
其中,Lk-1=lgSk-1。
通過上述運算,得到關于輸入圖像Iv的平滑結果S,即圖像的結構層信息Ivb。
2.3 光照增強模塊
光照增強模塊借助深度學習技術,使用文獻[1]中的LLNet網絡為主體框架,構成了encoder-decoder形式,該模塊的輸入為結構層圖像Ivb,輸出為增強圖像Ivb′。
模塊由3層去噪自編碼器(denoising autoencoder,DA)構成,具體的節(jié)點數(shù)為:輸入為17×17像素的塊圖像,即289個輸入單元;后面的隱藏單元數(shù)分別為867、578、289、578、867;最后為輸出單元,輸出單元具有與輸入相同的尺寸,即289。其中,第1層DA有867個隱藏單元;第2層DA有578個隱藏單元;第3層DA有289個隱藏單元,通過最小化重建圖像和正常光照圖像之間的均方誤差達到訓練效果。整個訓練過程包括預訓練和微調2個階段。在預訓練階段,每個DA層都通過誤差反向傳播進行訓練,以最小化稀疏正則化重建損失,其損失函數(shù)為:
(16)

在通過預訓練對權重進行初始化之后,使用誤差反向傳播算法對整個預訓練網絡進行微調,最小化給定的損失函數(shù)為:
(17)
其中:L為DA層的數(shù)量;W(l)為堆疊神經網絡的第l層的權重矩陣。
3 實驗部分
3.1 實驗說明
在本文模型中,暗光增強模塊通過Python 2.7、Theano 1.0.3版本實現(xiàn),其余部分均通過Matlab代碼使用3.4 GHz CPU和8 G RAM的計算機實現(xiàn)。
在建筑給排水的部署實施過程中,難免會遇到各種困難。因為各個建筑物的設計不同,所以對應的給排水設計也應該不同。建筑給排水設計人員應該參照建筑的施工設計圖紙,然后進行實地考察,再設計給排水施工圖紙。在設計施工圖紙的過程中,設計人員要認真負責,足夠自信,并且要嚴格遵守國家關于建筑工程施工的法律法規(guī)。設計完圖之后,要進行相應的模擬測試。模擬測試要根據(jù)施工的環(huán)境特點,設置對應的模擬實驗環(huán)境,爭取在最大程度上保證模擬測試環(huán)境與真實施工環(huán)境相一致,這樣才能保證測試結果的可信度。測試完畢后,設計人員需要根據(jù)測試結果,對設計圖紙進行相應的修改,使其達到最佳的效果。
通過收集暗光增強領域的常用測試圖像和在現(xiàn)實生活中拍攝得到的圖像作為本文中的測試圖像,它們包含各種場景和亮度條件。本文的模型配置參數(shù)如下:濾波器的參數(shù)有k、r、λ和γ,k和r在本文中為固定參數(shù),k=10,r=3。其中:k為圖像處理過程中的迭代次數(shù);r為濾波半徑;λ為正則化參數(shù);γ為分母比例參數(shù)。λ和γ在本文中存在多個數(shù)值,通過不同的數(shù)值作對比實驗,借此確定最終的選值。
訓練數(shù)據(jù)方面,通過訓練數(shù)據(jù)生成方法(伽馬校正和添加高斯噪聲)來模擬低光環(huán)境,從而得到成對的訓練數(shù)據(jù)用于訓練模型。每對訓練數(shù)據(jù)包括正常光照圖像和相對應的模擬低光環(huán)境下生成的暗光圖像。
對198對訓練圖像對進行分塊處理,每張圖像得到2 500個圖像塊,最終得到495 000對圖像塊,其中60%作為訓練集,20%作為驗證集,20%作為測試集。
在預訓練階段,每層的迭代次數(shù)為30次;在微調階段,設置的迭代次數(shù)為2 000次,在迭代到470次左右時驗證集損失達到最小。
3.2 對比實驗
本小節(jié)的對比實驗分為2個部分:
(1) 驗證改進的保邊緣濾波器的有效性。一方面對濾波器的參數(shù)變化帶來的影響做直觀的對比實驗;另一方面為了觀察改進的保邊緣濾波器對輸出結果的影響,通過采用不同參數(shù)配置的模型做直觀的結果對比。
濾波器參數(shù)λ、γ調整的對比效果如圖2、圖3所示。由圖2、圖3可以看出,改進的濾波器有2個參數(shù)影響對圖像的處理效果,分別為λ和γ。具體來說,通過固定其中一個參數(shù),然后改變另外一個參數(shù)來查看對濾波結果的影響。

圖2 λ=0.01,濾波器參數(shù)γ調整的對比效果

圖3 γ=0.6,濾波器參數(shù)λ調整的對比效果
不同參數(shù)的濾波器對最終效果的影響(k=10,r=3)如圖4所示。圖4中:第1行為原始圖像和經過不同參數(shù)模型處理后得到的圖像;第2行為部分區(qū)域放大圖;第3行為對應參數(shù)模型提取的結構層圖像。

圖4 不同參數(shù)的濾波器對最終效果的影響
從圖2~圖4可以看出,隨著λ和γ不斷增大,濾波器對圖像結構層的提取趨向于平滑,能夠得到更全面的細節(jié)層信息,但是結構層趨于平滑的程度越大,暗光增強模塊在重構過程中的偽影效果就越嚴重,從圖4的第2行可以明顯看出。鑒于此,在后面的模型選擇中,參數(shù)定為k=10,r=3,λ=0.01,γ=0.6。
本文選定濾波器參數(shù)為k=10,r=3,λ=0.01,γ=0.6的模型,并將其與一些經典的暗光增強模型進行對比,包括基于深度神經網絡的模型[1,8]、基于直方圖的模型[14]和基于簡化的Retinex的模型[15],上述模型的方法均為開源,文中關于上述模型的參數(shù)使用的均是開源代碼中的默認值。
基于上述模型和本文模型給出了增強的結果展示如圖5和圖6所示,并逐一與本文模型進行對比,可以得到以下觀察結果。

圖5 多種暗光增強模型的效果對比

圖6 多種暗光增強模型的效果對比(局部放大)
文獻[1]在圖像的暗光增強方面效果比較顯著,但是圖像的紋理細節(jié)部分存在比較明顯的丟失,圖像整體偏向于模糊,圖6中的屋角放大區(qū)域可以很明顯地看到細節(jié)信息的丟失。文獻[8]在保留細節(jié)方面優(yōu)于文獻[1],但經過文獻[8]處理后的圖像在圖像風格上存在著較大的改變,偏向于過度增強整個圖像場景,圖像風格趨于動漫化。文獻[14]的處理效果在細節(jié)的保留方面具有很大的優(yōu)勢,但是在主要目的暗光增強方面卻存在著較大的欠缺,該模型的增強效果收效甚微。文獻[15]的結果在圖像的輪廓部分出現(xiàn)一些偽影效果,圖像的輪廓鮮明突出,圖像風格發(fā)生變化,影響視覺展示。
另外,圖6的天空放大區(qū)域,文獻[8]和文獻[15]的結果存在著明顯的偽影現(xiàn)象,文獻[1]、文獻[14]和本文模型基本不存在偽影問題。
本文模型是基于文獻[1]中的LLNet網絡模型發(fā)展而來,其初衷是為了更好地保留增強圖像的細節(jié)信息。針對這一部分,文中對本文模型和LLNet[1]網絡模型做了相對應的對比實驗,如圖7所示,可以很明顯地得到以下2點結論:
(1) 在紋理細節(jié)方面,由于改進的濾波器的作用,本文能夠在增強圖像對比度的同時很好地保持圖像的細節(jié)信息,使得增強圖像在細節(jié)方面更加豐富,給人更好的視覺效果,確保了增強后圖像的視覺質量。
(2) 在暗光增強方面,本文模型的增強效果略優(yōu)于LLNet[1]網絡模型,整體的效果更加的明亮。

圖7 本文模型與LLNet的效果比較
為了進行模型間的量化對比,對文獻[1]、文獻[8]、文獻[14]、文獻[15]和本文模型進行打分評定。對比實驗選用了31張圖像,打分人數(shù)為10人,分數(shù)區(qū)間為1~5分,其中1分代表圖像展示效果最差,5分代表圖像展示效果最好,分數(shù)為整數(shù),對模型的分數(shù)進行平均,得到最終評分。在圖像評分過程中,僅僅提供如下打分規(guī)則:① 對比增強后圖像的亮度與原始圖像相比是否有提高;② 增強后圖像的整體灰度分布是否合理;③ 增強后的圖像是否引入外來噪聲,破壞了圖像的自然效果。
具體評分結果見表1所列。

表1 不同模型增強圖像評分結果
由表1可知,相比較其他4種模型,本文模型在整體效果上有較大的優(yōu)勢,說明了本文模型的適用性和有效性。
4 結 論
本文基于 LLNet[1]網絡模型,提出了一種基于結構與細節(jié)層分解的暗光照圖像增強模型,該模型對各種照明條件均具有魯棒性,在不同類型的照明條件下都能很好地工作,有效地避免了過度增強或增強不足的情況。相比于傳統(tǒng)的基于自編碼器網絡的方法,本文模型可以在有效改善暗光圖片的可視度前提下,仍能很好地保持圖像的細節(jié)信息,提高了圖像的豐富度。在后續(xù)的工作中,計劃在一個統(tǒng)一的框架中實現(xiàn)細節(jié)增強和低光增強的任務,或者參考文獻[16]的手段嘗試將暗光增強技術融入到目標檢測任務中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
家庭影院技術(2020年10期)2020-12-14 07:53:50
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小學生優(yōu)秀作文(低年級)(2018年10期)2018-10-13 01:56:50
小學生優(yōu)秀作文(低年級)(2018年6期)2018-05-19 01:54:35
Coco薇(2016年10期)2016-11-29 19:59:58
光學精密工程(2016年6期)2016-11-07 09:07:19
山東青年(2016年1期)2016-02-28 14:25:30
核科學與工程(2015年4期)2015-09-26 11:59:03
