基于MFO-SVR的球磨機出粉量估算
2021-11-07 14:43:42陸金桂
合肥工業大學學報(自然科學版) 2021年10期
宋 宇, 陸金桂
(南京工業大學 機械與動力工程學院,江蘇 南京 211816)
0 引 言
在整個火力發電過程中,球磨機是必不可少的輔助設備,它將煤塊磨制成煤粉,使其充分燃燒。因為球磨機運行特性復雜,各參數之間耦合現象嚴重,導致球磨機出粉量難以直接測量,也難以使用簡單的數學模型進行精確的間接測量,所以在最優工況不明確的情況下,工作人員常常使球磨機在低負荷區運行,大大降低了出粉量,同時還增加了能耗。因此,尋找合適的方法解決球磨機出粉量的測量問題變得極為重要。
在實際生產中,需要采取一些間接的方法進行測量。在間接測量中,目前采用的差壓法、功率法、噪聲法、軸承振動法、油壓法、氣壓差動法、應變法等方法都是依靠單一變量來表征存煤量進而得到球磨機的出粉量,但是通過這些方法得到的球磨機出粉量的誤差比較大。近年來,隨著測量技術的發展與完善,基于多變量的軟測量方法被逐漸應用于測量領域[1-3]。其基本思想是以數據驅動為基礎,構建易測量的變量與那些難測量的變量之間的數學關系模型,通過測量那些可測量的變量來間接測量那些難測量的變量。常見的軟測量建模方法有基于黑箱理論的神經網絡法[4-5]以及支持向量回歸機(support vector regression,SVR)法[6-7]。
人工神經網絡具有很強的魯棒性和容錯性,可以擬合所有復雜的非線性關系,且有一定的學習能力和自適應性,因此可以用來預測球磨機的出粉量。文獻[8]以最優拉丁超立方法選取的數據作為訓練樣本,建立了球磨機出粉量的BP神經網絡估算模型,降低了估算誤差,提高了泛化性; 文獻[9]借助機理分析和混沌信息處理計算,建立了球磨機出粉量的軟測量模型,對球磨機出粉量進行了較為精確的估算; 文獻[10]提出了一種基于Takagi-Sugeno型模糊規則的火電廠球磨機出粉量預測方法,提高了電廠效率。但是球磨出粉量的神經網絡模型由于存在以下缺點,導致使用結果并不理想。
(1) 神經網絡模型的參數都是人為設定的,通過試湊法經過微調得到一組最優參數,這需要做大量的試驗,增加了時間成本。
(2) 神經網絡模型的訓練以傳統統計學為基礎,基于經驗風險最小化原則。這需要無窮多的樣本數據支撐,實際上訓練樣本是有限的,因此導致了網絡的泛化性差,預測精度不高。
(3) 神經網絡采用逆梯度法調整權、閾值,經常陷入局部最優解。當網絡層數過多時還會出現“梯度消失”現象。
相比于神經網絡而言,SVR的訓練以統計學理論為基礎,基于結構風險最小化原則。SVR的復雜程度僅取決于支持向量的個數,主要針對小樣本情況,并且從本質上避免了從歸納到演繹的過程,可以比較準確地預測出球磨機出粉量。文獻[11]結合球磨機的機理對影響球磨機出粉量的主要因素進行分析,選擇合適的輔助變量,建立了球磨機出粉量的SVR模型,得到了較為精確的預測結果;文獻[12]結合混沌灰熵分析理論,建立了球磨機出粉量的GECA-ε-SVR模型,對球磨機出粉量進行了精確的估算。
雖然球磨機的SVR模型有諸多優點,但是懲罰因子C以及核函數系數g影響著SVR的預測精度,并且它們很難確定。目前確定C和g的方法有k折交叉算法[12]、網格搜索法[13]、模擬退火(simulated annealing,SA)[14]、粒子群優化(particle swarm optimization,PSO)算法[15]、遺傳算法(genetic algorithm,GA)[16]。前兩者是非智能優化算法,搜尋的結果都不太準確,很難確定較優的參數。后三者屬于智能優化算法,SA是個體優化算法,雖然在統計上能100%找到全局最優解,但是計算復雜;PSO和GA是群體優化算法,理論上群體優化算法要好于個體優化算法。PSO計算簡單,操作方便,但隨著迭代次數的增加種群多樣性降低,且易陷入局部最優解;GA雖然保證了種群多樣性,但計算量大,計算結果不穩定,易陷入局部解。相比而言,飛蛾火焰優化(moth-flame optimization,MFO)算法[17-19]計算簡單,能較好地平衡局部搜索能力和全局搜索能力。因此本文嘗試著使用MFO算法來確定球磨機出粉量SVR模型的參數,對球磨機出粉量進行精確估算。
本文首先介紹了MFO算法的原理,并將MFO算法和SVR相結合建立了球磨機出粉量的MFO-SVR模型。將球磨機出粉量的MFO-SVR模型和PSO-SVR模型、GA-SVR模型進行對比,驗證了MFO-SVR模型具有較優越的預測能力以及較好的泛化性。
1 MFO算法
1.1 算法原型
飛蛾撲火優化算法的靈感來源于“飛蛾撲火”這一生物行為。“飛蛾撲火”并不是飛蛾的自殺行為,而是由飛蛾本身具有的橫向定位機制引起的,如圖1所示。在這種方法中,由于飛蛾離月球很遠,飛蛾通過保持與月球的固定角度來飛行,可以保證飛蛾在一條直線上長距離飛行。

圖1 橫向定位機制
當飛蛾看到人造光源時,它們試圖與光線保持一個相似的角度直線飛行。但是,這樣的光線比月球的光線距離近很多,因此保持與光源相似的角度會導致飛蛾無用或致命的螺旋飛行路徑,飛蛾最終會向光源收斂,如圖2所示。

圖2 “飛蛾撲火”生物行為
1.2 算法原理
在MFO算法中,假設候選解是飛蛾,問題的變量是飛蛾在空間中的位置。因此,通過改變其位置向量,飛蛾可以在一維、二維、三維或超維空間中飛行。
因為MFO算法是基于種群的算法,所以用矩陣M表示飛蛾的集合,即
(1)
其中:n為飛蛾種群數目;d為待求變量的維度;mi,j可以通過使用隨機分布來給出,即
mi,j=[bu(i)-bl(i)]rand()+bl(i)
(2)
其中:mi,j為矩陣M第i行第j列的值;bu(i)、bl(i)分別為第i個飛蛾位置的上限和下限;rand()為在區間[0,1]中生成的均勻分布隨機數。
對于所有飛蛾種群,還假設有一個數組OM用于存儲相應的適應度值,即
OM=[OM1OM2…OMn]T
(3)
火焰是算法中的另一個關鍵因素,類似于飛蛾矩陣M,火焰矩陣用F表示,火焰的適應度值用數組OF表示,即
(4)
OF=[OF1OF2…OFn]T
(5)
在MFO算法中,飛蛾矩陣M表示在算法搜索過程中執行移動變化的實際主體,而火焰F代表著經過飛蛾M搜索之后到目前為止所得到的最優解。因此,如果得到了一個更好的解,就會保證每只飛蛾在該最優值的附近進行搜索,以免錯過任何最優解。
MFO算法計算過程可以描述如下:
MFO=(I,P,T)
(6)
I用于產生一個初始隨機飛蛾群,并且計算相應的適應度函數值。該模型可以表示為:
I:φ→{M,OM}
(7)
P代表飛蛾在空間范圍內的搜索原理;飛蛾矩陣M輸入P中,輸出更新之后的矩陣M′,即
P:M→M′
(8)
若算法達到了設置的停止條件,則T的值為真;若不滿足,則T的值為假。表示為:
T:M→{true,false}
(9)
綜上所述,當I函數初始化之后,P函數進行迭代更新,運行直至T函數返回為真,則算法運行結束,一般流程框架如下:
M=I()
WhileT(M) is equal to false
M=P(M);
end
在初始化飛蛾的種群數、位置以及確定了適應度函數之后,飛蛾種群的更新機制為如下螺旋線:
Mi=S(Mi,Fi)=Dieb tcos(2πt)+Fj
(10)
其中:Mi為第i個飛蛾;Fj為第j個火焰;S為螺旋函數;Di=|Mi-Fj|為第i個飛蛾距第j個火焰的距離;b為定義對數螺旋形狀的常數;t為[-1,1]中的隨機數。控制飛蛾與火焰的距離,對數螺旋線如圖3所示。
圖3中,t越小,飛蛾離火焰越近,通過改變t,飛蛾可以到達火焰周圍的位置,增強了算法的局部尋優能力。

圖3 對數螺旋線
為了避免所獲得的解為局部最優值的情況,在每次迭代更新列表后,火焰根據它們的適應度數值大小排序,然后飛蛾更新它們相對于火焰的位置。
采用計算公式使火焰數量在迭代過程中不斷減少,即
(11)
其中:l為當前迭代次數;N為最大火焰數目,lmax為最大迭代次數;round表示取整。
P函數的執行步驟如下:
用(11)式計算更新火焰的數量
計算飛蛾的適應度函數值
if迭代次數為1
F=sort(M);
OF=sort(OM);
else
F=sort(Mt-1,Mt);
OF=sort(OMt-1,OMt);
end
fori=1:n
forj=1:d
計算飛蛾與相應火焰之間的距離Di=|Mi-Fj|;
采用(10)式更新飛蛾與相應火焰之間的距離M(i,j);
end
end
綜上所述,執行P函數直到T函數返回ture。P函數終止后,最佳飛蛾作為獲得的最佳近似值返回。
2 MFO-SVR算法
用SVR預測球磨機出粉量等價于求解合適的懲罰因子C以及RBF核函數系數gamma,為了提高球磨機出粉量的預測精度,使用MFO算法來確定參數C和gamma,算法流程如下。
(1) 設置參數。飛蛾和火焰的數目n=60,最大迭代次數lmax=100,變量的維度d=2,飛蛾位置的上限bu=[30,100],下限bl=[-30,-100]。
(2) 飛蛾位置初始化。在搜索空間內隨機生成飛蛾位置,M(i,:)=[mi,1mi,2]=[gC],迭代次數l=1。其中,M(i,:)為飛蛾矩陣M的第i行的行向量。
(3) 計算適應度值。將mi,1和mi,2輸入SVR模型中以進行球磨機出粉量的預測。根據預測結果,可以計算出適應度函數的相應值。本文采用平均絕對百分比誤差(mean absolute percentage error,MAPE)為適應度函數,計算公式為:
(12)
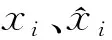
(4) 將飛蛾位置按適應度值從小到大排序,賦給火焰。
(5) 飛蛾圍繞火焰按(10)式,更新其位置。其中:b=1;t為[-1,1]中的隨機數。
(6) 記錄當前最優火焰適應度值。
(7) 根據(11)式減少火焰數量,l=l+1。
(8) 判斷是否達到最大迭代次數,若達到則輸出最優火焰位置和其適應度值,否則轉到步驟(4)。
球磨機出粉量的MFO-SVR算法流程如圖4所示。

圖4 球磨機出粉量的MFO-SVR算法流程
3 計算實例
3.1 數據獲取
本文的研究對象為重慶某電廠1#球磨機,由于球磨機結構復雜,其磨煤過程被許多因素所干擾,同時這些因素之間的關系又具有高度的非線性特點,通過數據服務器SCADA,從電廠DCS數據庫中采集時發現球磨機現場測點較多,采集的數據也較為復雜,在現場工作人員的幫助下,采集了該球磨機1 d的運行數據,剔除了一些異常樣本,最終采用系統抽樣從中篩選了500組樣本數據,見表1所列。
對上述數據進行歸一化處理,即
(13)

隨機選取450組作為訓練樣本,其余50組作為測試樣本,分別建立球磨機出粉量的MFO-SVR、PSO-SVR、GA-SVR模型。

表1 球磨機樣本數據
3.2 參數設置
(1) MFO-SVR算法。飛蛾和火焰的數目n=60,最大迭代次數lmax=100,變量的維度d=2,對數螺旋線參數b=1,SVR的不敏感系數ε=0.001,g∈[0,30],C∈[0,100]。
(2) PSO-SVR算法。種群的規模n=60,最大迭代次數為lmax=100,變量的維度d=2,學習因子c1=c2=1.78,慣性權重ω=0.7,SVR的不敏感系數ε=0.001,g∈[0,30],C∈[0,100]。
(3) GA-SVR算法。種群的規模n=60,最大迭代次數為lmax=200,交叉概率Pc=0.6,變異概率Pr=0.01,SVR的不敏感系數ε=0.001,g∈[0,30],C∈[0,100]。
3.3 實驗結果與分析
根據球磨機的3個主要的平衡方程[20],選擇對球磨機出粉量貢獻度大的進出口差壓、出口風粉壓力、出口風粉溫度、進口一次風量、進口一次風壓、進口一次風溫、電流等因素作為輸入,以球磨機出粉量為輸出,建立了球磨機出粉量的MFO-SVR、PSO-SVR、GA-SVR模型,其預測結果如圖5、圖6所示。


圖6 MFO-SVR算法迭代曲線
從圖5可以看出:GA-SVR模型的兩端有發散的跡象,預測值和實際值的走向趨勢相反,說明GA-SVR模型的泛化性能不好,而MFO-SVR、PSO-SVR模型兩端的預測值和實際值走向趨勢相同,表明具有較好的泛化性能。
從圖6可以看出:在前5次迭代時MAPE下降得比較快,這是由于MFO算法充分發揮了前期較強的全局搜索能力;第6次~第18次迭代期間,雖然MAPE下降的速度變慢,但是也勻速下降,這是由于MFO后期發揮了較強的局部搜索能力,在第18次迭代時鎖定了全局最優解。由此可以看出MFO算法能較好地平衡局部搜索能力和全局搜索能力。
為了驗證模型的泛化能力和尋優精度,本文將平均絕對誤差(mean absolute error,MAE)、MAPE、均方根誤差(root mean square error,RMSE)和決定系數(R-square,R2)4個統計學檢驗數據作為模型的評價指標。
MAE的計算公式為:
(14)
MAPE的計算公式為:
(15)
RMSE的計算公式為:
(16)
R2的計算公式為:
(17)
其中:xi、yi分別為實際值和估算值;n為數據樣本的個數。
球磨機出粉量軟測量模型誤差見表2所列。

表2 球磨機出粉量軟測量模型誤差
從表2可以看出:前3項誤差評判指標,球磨機出粉量的MFO-SVR模型最低,PSO-SVR模型其次,GA-SVR模型最高;MFO-SVR模型的平方相關系數R2比其他算法的更接近于1,其次是PSO-SVR模型的,GA-SVR模型的離1最遠。這表明球磨機出粉量的MFO-SVR模型具有較好的預測精度和較優的泛化能力,PSO-SVR模型次之,GA-SVR模型最差,與前面預測結果分析相吻合。
4 結 論
(1) 本文借助軟測量技術,以進出口差壓、出口風粉壓力、出口風粉溫度、進口一次風量、進口一次風壓、進口一次風溫、電流等因素作為輸入,以球磨機出粉量為輸出,建立了球磨機出粉量的MFO-SVR模型,解決了球磨機出粉量的測量問題。
(2) 將所建立的球磨機出粉量的MFO-SVR模型,與其PSO-SVR模型、GA-SVR模型的預測結果進行對比,結果顯示MFO-SVR模型的MAE、MAPE、RMSE比其他2個模型低,分別為2.172 4%、3.300 2%、2.848%,其平方相關系數也更接近于1,表明了球磨機出粉量的MFO-SVR模型具有較好的預測精度和較優的泛化能力,更適合球磨機出粉量的軟測量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中學生數理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
數學小靈通(1-2年級)(2017年10期)2017-11-08 08:39:45
光學精密工程(2016年6期)2016-11-07 09:07:19
少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
核科學與工程(2015年4期)2015-09-26 11:59:03
