中小企業財務預警與信用評分研究
2021-11-09 21:22:51張鈺
經濟研究導刊 2021年30期
關鍵詞:中小企業
張鈺


摘 要:根據中小板市場998家企業的財務指標數據構建財務預警與信用評分指標體系,運用相關性與機器學習決策樹對指標進行二次篩選,并通過邏輯回歸計算各樣本的信用分值,再根據模型評估和實證結果可以推知:邏輯模型對中小企業具有較好的財務預警能力,能夠準確衡量企業信用風險水平。同時可發現,存貨周轉率等12個財務指標是衡量中小企業信用風險的重要指標。
關鍵詞:信用評分;中小企業;邏輯回歸;財務預警
中圖分類號:F276.3? ? ? ? 文獻標志碼:A? ? ? 文章編號:1673-291X(2021)30-0063-03
引言
隨著我國從經濟體量到經濟發展質量的轉變,中小企業成為我國經濟發展的重要推動力量,在我國的經濟發展中,逐漸出現了企業體系中資金配置的兩極分化,這是我國異于他國的金融體系框架所導致的。但從根本上來說,中小企業發展最主要的問題是其自身財務狀況導致的融資難問題,中小企業的資金規模、技術、產品、服務都嚴重制約了其發展,且自有資金相對匱乏。此外,易受到外界多種因素的影響,在內部管理、決策水平、風險控制等方面的能力也較為薄弱,管理的風險也相對較高,從而使得中小企業發展受到各個方面的制約,導致其經營風險、管理風險、信用風險不斷加大。
在我國經濟發展改革和經濟體系轉變的過程中,中小企業要想扮演好自身的角色,要想有效地提高自身的經營能力和財務能力,要想有效地從根本上或者是一定程度地解決中小企業的融資問題,最重要的是解決企業信用風險量化問題和建立良好的財務預警體系,從根本上解決金融機構和市場主體對中小企業投資信心的問題。為較好地解決市場外部環境和中小企業與銀行之間的信息不對稱的問題,本文旨在建立一套健全的財務指標體系,較為準確地衡量中小企業的信用風險,并形成評分卡。
一、文獻綜述
在對于中小企業信用指標體系的研究中,我國許多學者都致力于尋找最合理的方法來衡量企業風險。如于善麗和遲國泰(2017)通過Fisherscore值建立了服務業小企業債信評價體系,并對1 077家企業的數據進行實證分析;孟斌等(2019)根據組合系數構建建筑企業信用評價模型,研究表明,與單一賦權結果相比,組合賦權模型特異度和靈敏度更高;遲國泰等(2019)利用1 814家工業企業的貸款數據實證分析了其所建立的小型工業企業債信評級模型,結果表明,該指標體系能夠顯著區分該類企業的違約狀態;張傳新和王光偉(2012)運用Logit模型實證分析基于主成分的信用風險體系的有效性;郭林(2020)用兩階段邏輯回歸構建了敏感性更強、判別力更大的信用評價指標體系,并使用3 111個小企業的信貸數據實證分析了其指標體系的有效性等。
為建立較為準確的指標體系,本文基于企業財務指標,構建指標體系,運用隨機森林和決策樹篩選指標變量,并建立邏輯回歸判別指標模型,最后得出信用分值。
二、指標變量選擇和數據處理
(一)特征變量選擇和數據預處理
本文選擇了六大類共19個財務指標,具體包括營運能力指標、償債能力指標、盈利能力指標、財務杠桿指標、流動性指標以及發展能力指標。這六大類指標都是與企業信用風險的高低有著較高的相關性的。本文數據來源于同花順網站中小板市場中988家公司的財務指標數據,其中ST企業違約風險為1,非ST違約風險為0。而后對數據樣本進行了描述性統計和初步的處理。
(二)缺失值與異常值處理
從下頁表1可知,樣本數據缺失嚴重,且樣本量為988個,所以本文采用眾數、均值、隨機森林模型來填補樣本缺失值,對于較為重要的特征變量,可根據樣本其他特征變量,用隨機森林模型預測缺失特征的值來補充樣本。此外,通過箱線圖尋找異常值并剔除,所得樣本數為491個。
三、特征變量篩選
(一)相關性檢驗
根據數據的初步處理,得到491個樣本,19個特征變量,由于本文所采用的數據為財務指標數據,數據指標中可能存在多重共線性,所以本文可根據變量之間的相關系數,初步剔除相關性較強的指標,將相關系數大于0.5的指標進行剔除,共刪除流動資產周轉率、速動比率、權益負債比、凈資產收益率、成本費用利潤率等5個指標。
(二)決策樹深度篩選特征變量
決策樹是一個通過樹狀結構模擬人進行決策的過程的方法,根節點后的每個分枝代表一個新的決策事件,而每個葉子代表一個最終判定所屬的類別。而決策事件的多少即為深度,不同的深度確定不同特征的重要性,本文基于改變決策樹深度(max_depth=3-20)以確定特征變量對信用違約的貢獻程度,從而得出存貨周轉率、資產現金率、流動比率等12個特征。
四、邏輯回歸模型與評估
(一)特征變量分箱,計算WOE
要得出企業的信用分值,首先要知道每一特征在不同區間上所對應的分值,即分箱,根據特征變量的取值,將不同樣本分成不同的區間。本文為簡化算法,特將每一個特征變量等距分成5個區間,即5個箱子,且區間長度相同,并將區間擴展到正無窮和負無窮。此外,為計算各箱的WOE值,必須保證每個箱中標簽均包含0和1,將無0和1的箱子與上一箱子合并,直到箱子中均含0和1為止。在每一個特征分箱后的每一個箱,將WOE計算完畢后,將其映射到數據樣本中,進行模型判別。
(二)邏輯回歸函數
將上述樣本數帶入邏輯回歸函數,回歸結果顯示,截距-3.12895206,特征變量系數為-0.290402、-0.5816、0.19818等12個系數。
(三)模型評估
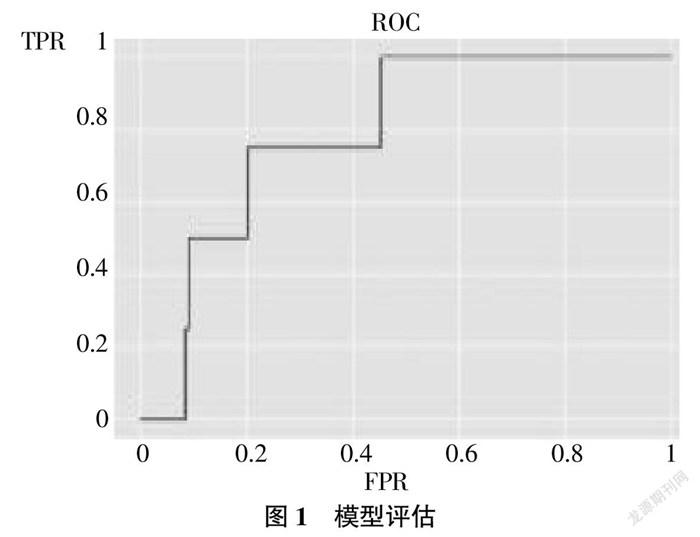
基于該模型為機器學習所訓練的模型,應檢驗其模型的好壞。準確度等于預測值與真實值相同的個數比上預測樣本數,根據模型結果顯出正確度為96.6%,從準確得分來說,該模型具有較好的預測能力,但是由于樣本的不均衡,如果更想知道的是模型對于信用風險較大企業的預測能力,那么應該選擇ROC曲線,其能較好地評估這一能力。ROC曲線是在不同命中和不同錯誤率下所繪制而成的。AUC指ROC曲線下方的面積,面積越大,模型效果越好。一般來說,AUC值大于0.75就意味著可以接受模型,大于0.85就表示模型效果好。圖1中,AUC值為0.79,說明模型可以接受。
猜你喜歡
中國市場(2016年36期)2016-10-19 03:48:15
中國市場(2016年35期)2016-10-19 02:42:20
中國市場(2016年33期)2016-10-18 14:16:18
中國市場(2016年33期)2016-10-18 14:09:48
中國市場(2016年33期)2016-10-18 13:12:09
商(2016年27期)2016-10-17 06:18:53
商(2016年27期)2016-10-17 06:06:44
商(2016年27期)2016-10-17 04:13:28
大眾理財顧問(2016年9期)2016-10-11 17:07:50
大眾理財顧問(2016年9期)2016-10-11 17:01:33
